Proposal for the Thai Script Root Zone LGR
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SEASSI Khmer Beginning Syllabus Languages and Cultures of Asia
SEASSI Khmer Beginning Syllabus Languages and Cultures of Asia 307/008 is a year-long equivalent (two-semester) sequence designed to bring students up to “survival level” in standard spoken and written Khmer. Class will mostly consist of activities in which Khmer must be used to accomplish specific tasks relevant to the topical matter of the Unit, thus giving practical experience in using and hearing Khmer. There will also be lectures (in English) on various cultural and grammatical issues in Khmer, with a focus on how these issues relate to English and American culture). There will be lectures on the writing system and on common pronunciation problems as well. There will also be lots of “focused listening” practice, games, and songs. A playful and creative approach will be encouraged in the learning and practice of all four skills (speaking,Property listening, reading and writing) in Khmer, as well as Khmer culture. CORUSE REQUIREMENTS: Students will be evaluated according to the following criteria: 1. Overall Class Participation: 20% 2. Completion of homework/assignments: 30% 3. Quizzes: 20% 4. Mid-term exam (written and oral): 10% 5. Final exam (written and oral): 10% 6. Individual/group project: 10% NOTE: 1. Participation: Participation will be graded based on the following criteria: a. 4-5 well-prepared; engage to and fully participate in the classroom activities b. 2-3 present, but relatively passive of c. 1 significantly late (30 minutes after the class begins) or considerably disturb the class including using your phones. The use of phones, laptops and other gadgets in the classroom is limited to instruction or learning purposes. -

Absorption of Arabic Words in Malay Language
ABSORPTION OF ARABIC WORDS IN MALAY LANGUAGE Noor Azlina Zaidan a, Muhammad Azhar Zailaini b, Wail Muin Ismail c a,b,c Faculty of Education, University of Malaya, Kuala Lumpur, Malaysia. b Corresponding author: [email protected] Available at http://www.ssrn.com/link/OIDA-Intl-Journal-Sustainable-Dev.html ISSN 1923-6654 (print) ISSN 1923-6662 (online). Ontario International Development Agency, Canada. © Authours et al Abstract: Malaysia is a developing country in South-East Asia. As a dynamic and developing country economically, cultural and education, Malaysia borrows a lot of languages such as Portuguese, Netherland, Chinese, English and Arabic. Arabic itself a Quranic language is used in Muslim’s everyday (especially) spiritual life. This research analyzes the classification of Arabic borrowed words (after this “loanword”) in Malay language based on theory of typology. The objectives of the study were to identify the Arabic loanwords (after this “the words”) in Malay language (after this “recipient language”) in premier Malay language dictionary, “Kamus Dewan” by the abbreviation “Ar” (Arab) as etymology of the words, to get the percentage of words which commonly used in current Malay speaking and writing. Also it attempted to calculate the percentage of both types of words which were fully absorbed in Malay language as model language (Arabic) and which words have undergone some changes by identifying the phonemic elements in the words. The analysis to the words will be done based on Jawi writing (“Jawi” is a term of Arab alphabet with some phoneme additions in Malay language) which has been applied in Malay language since Islamization in Malay Archipelago in early 14 th century when Arabs came to trade and spread Islam religion. -
Mon-Khmer Studies Volume 41
Mon-Khmer Studies VOLUME 42 The journal of Austroasiatic languages and cultures Established 1964 Copyright for these papers vested in the authors Released under Creative Commons Attribution License Volume 42 Editors: Paul Sidwell Brian Migliazza ISSN: 0147-5207 Website: http://mksjournal.org Published in 2013 by: Mahidol University (Thailand) SIL International (USA) Contents Papers (Peer reviewed) K. S. NAGARAJA, Paul SIDWELL, Simon GREENHILL A Lexicostatistical Study of the Khasian Languages: Khasi, Pnar, Lyngngam, and War 1-11 Michelle MILLER A Description of Kmhmu’ Lao Script-Based Orthography 12-25 Elizabeth HALL A phonological description of Muak Sa-aak 26-39 YANIN Sawanakunanon Segment timing in certain Austroasiatic languages: implications for typological classification 40-53 Narinthorn Sombatnan BEHR A comparison between the vowel systems and the acoustic characteristics of vowels in Thai Mon and BurmeseMon: a tendency towards different language types 54-80 P. K. CHOUDHARY Tense, Aspect and Modals in Ho 81-88 NGUYỄN Anh-Thư T. and John C. L. INGRAM Perception of prominence patterns in Vietnamese disyllabic words 89-101 Peter NORQUEST A revised inventory of Proto Austronesian consonants: Kra-Dai and Austroasiatic Evidence 102-126 Charles Thomas TEBOW II and Sigrid LEW A phonological description of Western Bru, Sakon Nakhorn variety, Thailand 127-139 Notes, Reviews, Data-Papers Jonathan SCHMUTZ The Ta’oi Language and People i-xiii Darren C. GORDON A selective Palaungic linguistic bibliography xiv-xxxiii Nathaniel CHEESEMAN, Jennifer -

Language Policy and Bilingual Education in Thailand: Reconciling the Past, Anticipating the Future1
LEARN Journal: Language Education and Acquisition Research Network Journal, Volume 12, Issue 1, January 2019 Language Policy and Bilingual Education in Thailand: Reconciling the Past, Anticipating the Future1 Thom Huebner San José State University, USA [email protected] Abstract Despite a century-old narrative as a monolingual country with quaint regional dialects, Thailand is in fact a country of vast linguistic diversity, where a population of approximately 60 million speak more than 70 languages representing five distinct language families (Luangthongkum, 2007; Premsrirat, 2011; Smalley, 1994), the result of a history of migration, cultural contact and annexation (Sridhar, 1996). However, more and more of the country’s linguistic resources are being recognized and employed to deal with both the centrifugal force of globalization and the centripetal force of economic and political unrest. Using Edwards’ (1992) sociopolitical typology of minority language situations and a comparative case study method, the current paper examines two minority language situations (Ferguson, 1991), one in the South and one in the Northeast, and describes how education reforms are attempting to address the economic and social challenges in each. Keywords: Language Policy, Bilingual Education, the Thai Context Background Since the early Twentieth Century, as a part of a larger effort at nation-building and creation of a sense of “Thai-ness.” (Howard, 2012; Laungaramsri, 2003; Simpson & Thammasathien, 2007), the Thai government has pursued a policy of monolingualism, establishing as the standard, official and national language a variety of Thai based on the dialect spoken in the central plains by ethnic Thais (Spolsky, 2004). In the official narrative presented to the outside world, Thais descended monoethnic and monocultural, from Southern China, bringing their language with them, which, in contact with indigenous languages, borrowed vocabulary. -

The Puzzling Absence of Ethnicity-Based Political Cleavages in Northeastern Thailand
Proud to be Thai: The Puzzling Absence of Ethnicity- Based Political Cleavages in Northeastern Thailand Jacob I. Ricks Abstract Underneath the veneer of a homogenous state-approved Thai ethnicity, Thailand is home to a heterogeneous population. Only about one-third of Thailand’s inhabitants speak the national language as their mother tongue; multiple alternate ethnolinguistic groups comprise the remainder of the population, with the Lao in the northeast, often called Isan people, being the largest at 28 percent of the population. Ethnic divisions closely align with areas of political party strength: the Thai Rak Thai Party and its subsequent incarnations have enjoyed strong support from Isan people and Khammuang speakers in the north while the Democrat Party dominates among the Thai- and Paktay-speaking people of the central plains and the south. Despite this confluence of ethnicity and political party support, we see very little mobilization along ethnic cleavages. Why? I argue that ethnic mobilization remains minimal because of the large-scale public acceptance and embrace of the government-approved Thai identity. Even among the country’s most disadvantaged, such as Isan people, support is still strong for “Thai-ness.” Most inhabitants of Thailand espouse the mantra that to Copyright (c) Pacific Affairs. All rights reserved. be Thai is superior to being labelled as part of an alternate ethnic group. I demonstrate this through the application of large-scale survey data as well as a set of interviews with self-identified Isan people. The findings suggest that the Thai state has successfully inculcated a sense of national identity Delivered by Ingenta to IP: 192.168.39.151 on: Sat, 25 Sep 2021 22:54:19 among the Isan people and that ethnic mobilization is hindered by ardent nationalism. -

SC22/WG20 N896 L2/01-476 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale De Normalisation
SC22/WG20 N896 L2/01-476 Universal multiple-octet coded character set International organization for standardization Organisation internationale de normalisation Title: Ordering rules for Khmer Source: Kent Karlsson Date: 2001-12-19 Status: Expert contribution Document type: Working group document Action: For consideration by the UTC and JTC 1/SC 22/WG 20 1 Introduction The Khmer script in Unicode/10646 uses conjoining characters, just like the Indic scripts and Hangul. An alternative that is suitable (and much more elegant) for Khmer, but not for Indic scripts, would have been to have combining- below (and sometimes a bit to the side) consonants and combining-below independent vowels, similar to the combining-above Latin letters recently encoded, as well as how Tibetan is handled. However that is not the chosen solution, which instead uses a combining character (COENG) that makes characters conjoin (glue) like it is done for Indic (Brahmic) scripts and like Hangul Jamo, though the latter does not have a separate gluer character. In the Khmer script, using the COENG based approach, the words are formed from orthographic syllables, where an orthographic syllable has the following structure [add ligation control?]: Khmer-syllable ::= (K H)* K M* where K is a Khmer consonant (most with an inherent vowel that is pronounced only if there is no consonant, independent vowel, or dependent vowel following it in the orthographic syllable) or a Khmer independent vowel, H is the invisible Khmer conjoint former COENG, M is a combining character (including COENG, though that would be a misspelling), in particular a combining Khmer vowel (noted A below) or modifier sign. -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

Schwa Deletion: Investigating Improved Approach for Text-To-IPA System for Shiri Guru Granth Sahib
ISSN (Online) 2278-1021 ISSN (Print) 2319-5940 International Journal of Advanced Research in Computer and Communication Engineering Vol. 4, Issue 4, April 2015 Schwa Deletion: Investigating Improved Approach for Text-to-IPA System for Shiri Guru Granth Sahib Sandeep Kaur1, Dr. Amitoj Singh2 Pursuing M.E, CSE, Chitkara University, India 1 Associate Director, CSE, Chitkara University , India 2 Abstract: Punjabi (Omniglot) is an interesting language for more than one reasons. This is the only living Indo- Europen language which is a fully tonal language. Punjabi language is an abugida writing system, with each consonant having an inherent vowel, SCHWA sound. This sound is modifiable using vowel symbols attached to consonant bearing the vowel. Shri Guru Granth Sahib is a voluminous text of 1430 pages with 511,874 words, 1,720,345 characters, and 28,534 lines and contains hymns of 36 composers written in twenty-two languages in Gurmukhi script (Lal). In addition to text being in form of hymns and coming from so many composers belonging to different languages, what makes the language of Shri Guru Granth Sahib even more different from contemporary Punjabi. The task of developing an accurate Letter-to-Sound system is made difficult due to two further reasons: 1. Punjabi being the only tonal language 2. Historical and Cultural circumstance/period of writings in terms of historical and religious nature of text and use of words from multiple languages and non-native phonemes. The handling of schwa deletion is of great concern for development of accurate/ near perfect system, the presented work intend to report the state-of-the-art in terms of schwa deletion for Indian languages, in general and for Gurmukhi Punjabi, in particular. -
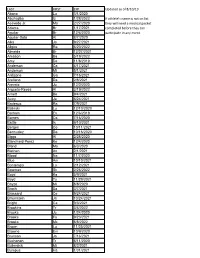
LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
LAST FIRST EXP Updated as of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If athlete's name is not on list Acevedo Jr. Ma 2/27/2020 they will need a medical packet Adams Br 1/17/2021 completed before they can Aguilar Br 12/6/2020 participate in any event. Aguilar-Soto Al 8/7/2020 Alka Ja 9/27/2021 Allgire Ra 6/20/2022 Almeida Br 12/27/2021 Amason Ba 5/19/2022 Amy De 11/8/2019 Anderson Ca 4/17/2021 Anderson Mi 5/1/2021 Ardizone Ga 7/16/2021 Arellano Da 2/8/2021 Arevalo Ju 12/2/2020 Argueta-Reyes Al 3/19/2022 Arnett Be 9/4/2021 Autry Ja 6/24/2021 Badeaux Ra 7/9/2021 Balinski Lu 12/10/2020 Barham Ev 12/6/2019 Barnes Ca 7/16/2020 Battle Is 9/10/2021 Bergen Co 10/11/2021 Bermudez Da 10/16/2020 Biggs Al 2/28/2020 Blanchard-Perez Ke 12/4/2020 Bland Ma 6/3/2020 Blethen An 2/1/2021 Blood Na 11/7/2020 Blue Am 10/10/2021 Bontempo Lo 2/12/2021 Bowman Sk 2/26/2022 Boyd Ka 5/9/2021 Boyd Ty 11/29/2021 Boyzo Mi 8/8/2020 Brach Sa 3/7/2021 Brassard Ce 9/24/2021 Braunstein Ja 10/24/2021 Bright Ca 9/3/2021 Brookins Tr 3/4/2022 Brooks Ju 1/24/2020 Brooks Fa 9/23/2021 Brooks Mc 8/8/2022 Brown Lu 11/25/2021 Browne Em 10/9/2020 Brunson Jo 7/16/2021 Buchanan Tr 6/11/2020 Bullerdick Mi 8/2/2021 Bumpus Ha 1/31/2021 LAST FIRST EXP Updated as of 8/10/19 Burch Co 11/7/2020 Burch Ma 9/9/2021 Butler Ga 5/14/2022 Byers Je 6/14/2021 Cain Me 6/20/2021 Cao Tr 11/19/2020 Carlson Be 5/29/2021 Cerda Da 3/9/2021 Ceruto Ri 2/14/2022 Chang Ia 2/19/2021 Channapati Di 10/31/2021 Chao Et 8/20/2021 Chase Em 8/26/2020 Chavez Fr 6/13/2020 Chavez Vi 11/14/2021 Chidambaram Ga 10/13/2019 -

Review of Research
Review Of ReseaRch impact factOR : 5.7631(Uif) UGc appROved JOURnal nO. 48514 issn: 2249-894X vOlUme - 8 | issUe - 7 | apRil - 2019 __________________________________________________________________________________________________________________________ AN ANALYSIS OF CURRENT TRENDS FOR SANSKRIT AS A COMPUTER PROGRAMMING LANGUAGE Manish Tiwari1 and S. Snehlata2 1Department of Computer Science and Application, St. Aloysius College, Jabalpur. 2Student, Deparment of Computer Science and Application, St. Aloysius College, Jabalpur. ABSTRACT : Sanskrit is said to be one of the systematic language with few exception and clear rules discretion.The discussion is continued from last thirtythat language could be one of best option for computers.Sanskrit is logical and clear about its grammatical and phonetically laws, which are not amended from thousands of years. Entire Sanskrit grammar is based on only fourteen sutras called Maheshwar (Siva) sutra, Trimuni (Panini, Katyayan and Patanjali) are responsible for creation,explainable and exploration of these grammar laws.Computer as machine,requires such language to perform better and faster with less programming.Sanskrit can play important role make computer programming language flexible, logical and compact. This paper is focused on analysis of current status of research done on Sanskrit as a programming languagefor .These will the help us to knowopportunity, scope and challenges. KEYWORDS : Artificial intelligence, Natural language processing, Sanskrit, Computer, Vibhakti, Programming language. -

The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes
Portland State University PDXScholar Mathematics and Statistics Faculty Fariborz Maseeh Department of Mathematics Publications and Presentations and Statistics 3-2018 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hu Sun University of Macau Christine Chambris Université de Cergy-Pontoise Judy Sayers Stockholm University Man Keung Siu University of Hong Kong Jason Cooper Weizmann Institute of Science SeeFollow next this page and for additional additional works authors at: https:/ /pdxscholar.library.pdx.edu/mth_fac Part of the Science and Mathematics Education Commons Let us know how access to this document benefits ou.y Citation Details Sun X.H. et al. (2018) The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes. In: Bartolini Bussi M., Sun X. (eds) Building the Foundation: Whole Numbers in the Primary Grades. New ICMI Study Series. Springer, Cham This Book Chapter is brought to you for free and open access. It has been accepted for inclusion in Mathematics and Statistics Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Authors Xu Hu Sun, Christine Chambris, Judy Sayers, Man Keung Siu, Jason Cooper, Jean-Luc Dorier, Sarah Inés González de Lora Sued, Eva Thanheiser, Nadia Azrou, Lynn McGarvey, Catherine Houdement, and Lisser Rye Ejersbo This book chapter is available at PDXScholar: https://pdxscholar.library.pdx.edu/mth_fac/253 Chapter 5 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hua Sun , Christine Chambris Judy Sayers, Man Keung Siu, Jason Cooper , Jean-Luc Dorier , Sarah Inés González de Lora Sued , Eva Thanheiser , Nadia Azrou , Lynn McGarvey , Catherine Houdement , and Lisser Rye Ejersbo 5.1 Introduction Mathematics learning and teaching are deeply embedded in history, language and culture (e.g. -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ].