Phonological Representations of the Japanese Language: Levels of Processing and Orthographic Influences
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Look at Linguistic Readers
Reading Horizons: A Journal of Literacy and Language Arts Volume 10 Issue 3 April 1970 Article 5 4-1-1970 A Look At Linguistic Readers Nicholas P. Criscuolo New Haven, Connecticut Public Schools Follow this and additional works at: https://scholarworks.wmich.edu/reading_horizons Part of the Education Commons Recommended Citation Criscuolo, N. P. (1970). A Look At Linguistic Readers. Reading Horizons: A Journal of Literacy and Language Arts, 10 (3). Retrieved from https://scholarworks.wmich.edu/reading_horizons/vol10/iss3/5 This Article is brought to you for free and open access by the Special Education and Literacy Studies at ScholarWorks at WMU. It has been accepted for inclusion in Reading Horizons: A Journal of Literacy and Language Arts by an authorized editor of ScholarWorks at WMU. For more information, please contact wmu- [email protected]. A LOOK AT LINGUISTIC READERS Nicholas P. Criscuolo NEW HAVEN, CONNECTICUT, PUBLIC SCHOOLS Linguistics, as it relates to reading, has generated much interest lately among educators. Although linguistics is not a new science, its recent focus has captured the interest of the reading specialist because both the specialist and the linguist are concerned with language. This surge of interest in linguistics becomes evident when one sees that a total of forty-four articles on linguistics are listed in the Education Index for July, 1965 to June, 1966. The number of articles on linguistics written for educational journals has been increasing ever SInce. This interest has been sharpened to some degree by the publi cation of Chall's book Learning to Read: The Great Debate (1). -

2 Mora and Syllable
2 Mora and Syllable HARUO KUBOZONO 0 Introduction In his classical typological study Trubetzkoy (1969) proposed that natural languages fall into two groups, “mora languages” and “syllable languages,” according to the smallest prosodic unit that is used productively in that lan- guage. Tokyo Japanese is classified as a “mora” language whereas Modern English is supposed to be a “syllable” language. The mora is generally defined as a unit of duration in Japanese (Bloch 1950), where it is used to measure the length of words and utterances. The three words in (1), for example, are felt by native speakers of Tokyo Japanese as having the same length despite the different number of syllables involved. In (1) and the rest of this chapter, mora boundaries are marked by hyphens /-/, whereas syllable boundaries are marked by dots /./. All syllable boundaries are mora boundaries, too, although not vice versa.1 (1) a. to-o-kyo-o “Tokyo” b. a-ma-zo-n “Amazon” too.kyoo a.ma.zon c. a-me-ri-ka “America” a.me.ri.ka The notion of “mora” as defined in (1) is equivalent to what Pike (1947) called a “phonemic syllable,” whereas “syllable” in (1) corresponds to what he referred to as a “phonetic syllable.” Pike’s choice of terminology as well as Trubetzkoy’s classification may be taken as implying that only the mora is relevant in Japanese phonology and morphology. Indeed, the majority of the literature emphasizes the importance of the mora while essentially downplaying the syllable (e.g. Sugito 1989, Poser 1990, Tsujimura 1996b). This symbolizes the importance of the mora in Japanese, but it remains an open question whether the syllable is in fact irrelevant in Japanese and, if not, what role this second unit actually plays in the language. -

A Student Model of Katakana Reading Proficiency for a Japanese Language Intelligent Tutoring System
A Student Model of Katakana Reading Proficiency for a Japanese Language Intelligent Tutoring System Anthony A. Maciejewski Yun-Sun Kang School of Electrical Engineering Purdue University West Lafayette, Indiana 47907 Abstract--Thls work describes the development of a kanji. Due to the limited number of kana, their relatively low student model that Is used In a Japanese language visual complexity, and their systematic arrangement they do Intelligent tutoring system to assess a pupil's not represent a significant barrier to the student of Japanese. proficiency at reading one of the distinct In fact, the relatively small effort required to learn katakana orthographies of Japanese, known as k a t a k a n a , yields significant returns to readers of technical Japanese due to While the effort required to memorize the relatively the high incidence of terms derived from English and few k a t a k a n a symbols and their associated transliterated into katakana. pronunciations Is not prohibitive, a major difficulty In reading katakana Is associated with the phonetic This work describes the development of a system that is modifications which occur when English words used to automatically acquire knowledge about how English which are transliterated Into katakana are made to words are transliterated into katakana and then to use that conform to the more restrictive rules of Japanese information in developing a model of a student's proficiency in phonology. The algorithm described here Is able to reading katakana. This model is used to guide the instruction automatically acquire a knowledge base of these of the student using an intelligent tutoring system developed phonological transformation rules, use them to previously [6,8]. -

JLPT Explanatory Notes on the Use of the Flashcards.Pdf
Explanatory Notes on the Use of the Flashcards General Introduction There are four sets of flashcards—Grammar, Kana, Kanji and Vocabulary flashcards. In the current digital age, it might seem superfluous to have printable, paper flashcards as there are now plenty of resources online to learn and review Japanese with. However, they can be very useful for a variety of reasons. First of all, physical flashcards have one primary purpose: to help you learn something. That might sound strange, but haven’t you ever switched on your phone to study some vocabulary on your favorite app only to get distracted by some social media notification. The next thing you know, you’ve spent 30 minutes checking up on your friend’s social life and haven’t learned anything new. That’s why using a single-purpose tool like paper flashcards can be a huge help. It helps you to stay focused and sometimes that is the most difficult part of studying a new language. The second reason is that paper flashcards don’t require any electricity. You can use them anytime, anywhere in any environment without worrying about a system crash or your battery dying. Use these flashcards to review what you’ve learned from the Study Guide so that you are fully equipped with the necessary language skills, before going into the test. There is a big difference between being familiar with something and knowing it well. The JLPT expects you to know the material and recall it quickly. That means frequent revision and practice. 1. Grammar Flashcards – Quick Start Guide The grammar cards contain the key phrases from all the grammar units of the Study Guide. -
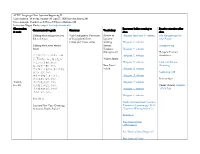
ALTEC Language Class: Japanese Beginning II
ALTEC Language Class: Japanese Beginning II Class duration: 10 weeks, January 28–April 7, 2020 (no class March 24) Class meetings: Tuesdays at 5:30pm–7:30pm in Hellems 145 Instructor: Megan Husby, [email protected] Class session Resources before coming to Practice exercises after Communicative goals Grammar Vocabulary & topic class class Talking about things that you Verb Conjugation: Past tense Review of Hiragana Intro and あ column Fun Hiragana app for did in the past of long (polite) forms Japanese your Phone (~desu and ~masu verbs) Writing Hiragana か column Talking about your winter System: Hiragana song break Hiragana Hiragana さ column (Recognition) Hiragana Practice クリスマス・ハヌカー・お Hiragana た column Worksheet しょうがつ 正月はなにをしましたか。 Winter Sports どこにいきましたか。 Hiragana な column Grammar Review なにをたべましたか。 New Year’s (Listening) プレゼントをかいましたか/ Vocab Hiragana は column もらいましたか。 Genki I pg. 110 スポーツをしましたか。 Hiragana ま column だれにあいましたか。 Practice Quiz Week 1, えいがをみましたか。 Hiragana や column Jan. 28 ほんをよみましたか。 Omake (bonus): Kasajizō: うたをききましたか/ Hiragana ら column A Folk Tale うたいましたか。 Hiragana わ column Particle と Genki: An Integrated Course in Japanese New Year (Greetings, Elementary Japanese pgs. 24-31 Activities, Foods, Zodiac) (“Japanese Writing System”) Particle と Past Tense of desu (Affirmative) Past Tense of desu (Negative) Past Tense of Verbs Discussing family, pets, objects, Verbs for being (aru and iru) Review of Katakana Intro and ア column Katakana Practice possessions, etc. Japanese Worksheet Counters for people, animals, Writing Katakana カ column etc. System: Genki I pgs. 107-108 Katakana Katakana サ column (Recognition) Practice Quiz Katakana タ column Counters Katakana ナ column Furniture and common Katakana ハ column household items Katakana マ column Katakana ヤ column Katakana ラ column Week 2, Feb. -

Learning About Phonology and Orthography
EFFECTIVE LITERACY PRACTICES MODULE REFERENCE GUIDE Learning About Phonology and Orthography Module Focus Learning about the relationships between the letters of written language and the sounds of spoken language (often referred to as letter-sound associations, graphophonics, sound- symbol relationships) Definitions phonology: study of speech sounds in a language orthography: study of the system of written language (spelling) continuous text: a complete text or substantive part of a complete text What Children Children need to learn to work out how their spoken language relates to messages in print. Have to Learn They need to learn (Clay, 2002, 2006, p. 112) • to hear sounds buried in words • to visually discriminate the symbols we use in print • to link single symbols and clusters of symbols with the sounds they represent • that there are many exceptions and alternatives in our English system of putting sounds into print Children also begin to work on relationships among things they already know, often long before the teacher attends to those relationships. For example, children discover that • it is more efficient to work with larger chunks • sometimes it is more efficient to work with relationships (like some word or word part I know) • often it is more efficient to use a vague sense of a rule How Children Writing Learn About • Building a known writing vocabulary Phonology and • Analyzing words by hearing and recording sounds in words Orthography • Using known words and word parts to solve new unknown words • Noticing and learning about exceptions in English orthography Reading • Building a known reading vocabulary • Using known words and word parts to get to unknown words • Taking words apart while reading Manipulating Words and Word Parts • Using magnetic letters to manipulate and explore words and word parts Key Points Through reading and writing continuous text, children learn about sound-symbol relation- for Teachers ships, they take on known reading and writing vocabularies, and they can use what they know about words to generate new learning. -

LT3212 Phonetics Assignment 4 Mavis, Wong Chak Yin
LT3212 Phonetics Assignment 4 Mavis, Wong Chak Yin Essay Title: The sound system of Japanese This essay aims to introduce the sound system of Japanese, including the inventories of consonants, vowels, and diphthongs. The phonological variations of the sound segments in different phonetic environments are also included. For the illustration, word examples are given and they are presented in the following format: [IPA] (Romaji: “meaning”). Consonants In Japanese, there are 14 core consonants, and some of them have a lot of allophonic variations. The various types of consonants classified with respect to their manner of articulation are presented as follows. Stop Japanese has six oral stops or plosives, /p b t d k g/, which are classified into three place categories, bilabial, alveolar, and velar, as listed below. In each place category, there is a pair of plosives with the contrast in voicing. /p/ = a voiceless bilabial plosive [p]: [ippai] (ippai: “A cup of”) /b/ = a voiced bilabial plosive [b]: [baɴ] (ban: “Night”) /t/ = a voiceless alveolar plosive [t]: [oto̞ ːto̞ ] (ototo: “Brother”) /d/ = a voiced alveolar plosive [d]: [to̞ mo̞ datɕi] (tomodachi: “Friend”) /k/ = a voiceless velar plosive [k]: [kaiɰa] (kaiwa: “Conversation”) /g/ = a voiced velar plosive [g]: [ɡakɯβsai] (gakusai: “Student”) Phonetically, Japanese also has a glottal stop [ʔ] which is commonly produced to separate the neighboring vowels occurring in different syllables. This phonological phenomenon is known as ‘glottal stop insertion’. The glottal stop may be realized as a pause, which is used to indicate the beginning or the end of an utterance. For instance, the word “Japanese money” is actually pronounced as [ʔe̞ ɴ], instead of [je̞ ɴ], and the pronunciation of “¥15” is [dʑɯβːɡo̞ ʔe̞ ɴ]. -

Syllabus 1 Lín Táo 林燾 and Gêng Zhènshëng 耿振生
CHINESE 542 Introduction to Chinese Historical Phonology Spring 2005 This course is a basic introduction at the graduate level to methods and materials in Chinese historical phonology. Reading ability in Chinese is required. It is assumed that students have taken Chinese 342, 442, or the equivalent, and are familiar with articulatory phonetics concepts and terminology, including the International Phonetic Alphabet, and with general notions of historical sound change. Topics covered include the periodization of the Chinese language; the source materials for reconstructing earlier stages of the language; traditional Chinese phonological categories and terminology; fânqiè spellings; major reconstruction systems; the use of reference materials to determine reconstructions in these systems. The focus of the course is on Middle Chinese. Class: Mondays & Fridays 3:30 - 5:20, Savery 335 Web: http://courses.washington.edu/chin532/ Instructor: Zev Handel 245 Gowen, 543-4863 [email protected] Office hours: MF 2-3pm Grading: homework exercises 30% quiz 5% comprehensive test 25% short translations 15% annotated translation 25% Readings: Readings are available on e-reserves or in the East Asian library. Items below marked with a call number are on reserve in the East Asian Library or (if the call number starts with REF) on the reference shelves. Items marked eres are on course e-reserves. Baxter, William H. 1992. A handbook of Old Chinese phonology. (Trends in linguistics: studies and monographs, 64.) Berlin and New York: Mouton de Gruyter. PL1201.B38 1992 [eres: chapters 2, 8, 9] Baxter, William H. and Laurent Sagart. 1998 . “Word formation in Old Chinese” . In New approaches to Chinese word formation: morphology, phonology and the lexicon in modern and ancient Chinese. -

The Degree of the Speaker's Negative Attitude in a Goal-Shifting
In Christopher Brown and Qianping Gu and Cornelia Loos and Jason Mielens and Grace Neveu (eds.), Proceedings of the 15th Texas Linguistics Society Conference, 150-169. 2015. The degree of the speaker’s negative attitude in a goal-shifting comparison Osamu Sawada∗ Mie University [email protected] Abstract The Japanese comparative expression sore-yori ‘than it’ can be used for shifting the goal of a conversation. What is interesting about goal-shifting via sore-yori is that, un- like ordinary goal-shifting with expressions like tokorode ‘by the way,’ using sore-yori often signals the speaker’s negative attitude toward the addressee. In this paper, I will investigate the meaning and use of goal-shifting comparison and consider the mecha- nism by which the speaker’s emotion is expressed. I will claim that the meaning of the pragmatic sore-yori conventionally implicates that the at-issue utterance is preferable to the previous utterance (cf. metalinguistic comparison (e.g. (Giannakidou & Yoon 2011))) and that the meaning of goal-shifting is derived if the goal associated with the at-issue utterance is considered irrelevant to the goal associated with the previous utterance. Moreover, I will argue that the speaker’s negative attitude is shown by the competition between the speaker’s goal and the hearer’s goal, and a strong negativity emerges if the goals are assumed to be not shared. I will also compare sore-yori to sonna koto-yori ‘than such a thing’ and show that sonna koto-yori directly expresses a strong negative attitude toward the previous utterance. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role. -

Characteristics of Developmental Dyslexia in Japanese Kana: From
al Ab gic no lo rm o a h l i c t y i e s s Ogawa et al., J Psychol Abnorm Child 2014, 3:3 P i Journal of Psychological Abnormalities n f o C l DOI: 10.4172/2329-9525.1000126 h a i n l d ISSN:r 2329-9525 r u e o n J in Children Research Article Open Access Characteristics of Developmental Dyslexia in Japanese Kana: from the Viewpoint of the Japanese Feature Shino Ogawa1*, Miwa Fukushima-Murata2, Namiko Kubo-Kawai3, Tomoko Asai4, Hiroko Taniai5 and Nobuo Masataka6 1Graduate School of Medicine, Kyoto University, Kyoto, Japan 2Research Center for Advanced Science and Technology, the University of Tokyo, Tokyo, Japan 3Faculty of Psychology, Aichi Shukutoku University, Aichi, Japan 4Nagoya City Child Welfare Center, Aichi, Japan 5Department of Pediatrics, Nagoya Central Care Center for Disabled Children, Aichi, Japan 6Section of Cognition and Learning, Primate Research Institute, Kyoto University, Aichi, Japan Abstract This study identified the individual differences in the effects of Japanese Dyslexia. The participants consisted of 12 Japanese children who had difficulties in reading and writing Japanese and were suspected of having developmental disorders. A test battery was created on the basis of the characteristics of the Japanese language to examine Kana’s orthography-to-phonology mapping and target four cognitive skills: analysis of phonological structure, letter-to-sound conversion, visual information processing, and eye–hand coordination. An examination of the individual ability levels for these four elements revealed that reading and writing difficulties are not caused by a single disability, but by a combination of factors. -

Jtc1/Sc2/Wg2 N3427 L2/08-132
JTC1/SC2/WG2 N3427 L2/08-132 2008-04-08 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal to encode 39 Unified Canadian Aboriginal Syllabics in the UCS Source: Michael Everson and Chris Harvey Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2008-04-08 1. Summary. This document requests 39 additional characters to be added to the UCS and contains the proposal summary form. 1. Syllabics hyphen (U+1400). Many Aboriginal Canadian languages use the character U+1428 CANADIAN SYLLABICS FINAL SHORT HORIZONTAL STROKE, which looks like the Latin script hyphen. Algonquian languages like western dialects of Cree, Oji-Cree, western and northern dialects of Ojibway employ this character to represent /tʃ/, /c/, or /j/, as in Plains Cree ᐊᓄᐦᐨ /anohc/ ‘today’. In Athabaskan languages, like Chipewyan, the sound is /d/ or an alveolar onset, as in Sayisi Dene ᐨᕦᐣᐨᕤ /t’ąt’ú/ ‘how’. To avoid ambiguity between this character and a line-breaking hyphen, a SYLLABICS HYPHEN was developed which resembles an equals sign. Depending on the typeface, the width of the syllabics hyphen can range from a short ᐀ to a much longer ᐀. This hyphen is line-breaking punctuation, and should not be confused with the Blackfoot syllable internal-w final proposed for U+167F. See Figures 1 and 2. 2. DHW- additions for Woods Cree (U+1677..U+167D). ᙷᙸᙹᙺᙻᙼᙽ/ðwē/ /ðwi/ /ðwī/ /ðwo/ /ðwō/ /ðwa/ /ðwā/. The basic syllable structure in Cree is (C)(w)V(C)(C).