Object Tracking in Games Using Convolutional Neural Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

KIRBY MASS ATTACK Shows the Percentage of the Game Completed
MAA-NTR-TADP-UKV INSTRUCTION BOOKLET (CONTAINS IMPORTANT HEALTH AND SAFETY INFORMATION) [0611/UKV/NTR] T his seal is your assurance that Nintendo has reviewed this product and that it has met our standards for excellence in workmanship, reliability and entertainment value. Always look for this seal when buying games and accessories to ensure complete com patibility with your Nintendo Product. Thank you for selecting the KIRBY™ MASS ATTACK Game Card for Nintendo DS™ systems. IMPORTANT: Please carefully read the important health and safety information included in this booklet before using your Nintendo DS system, Game Card, Game Pak or accessory. Please read this Instruction Booklet thoroughly to ensure maximum enjoyment of your new game. Important warranty and hotline information can be found in the separate Age Rating, Software Warranty and Contact Information Leafl et. Always save these documents for future reference. This Game Card will work only with Nintendo DS systems. IMPORTANT: The use of an unlawful device with your Nintendo DS system may render this game unplayable. © 2011 HAL Laboratory, Inc. / Nintendo. TM, ® and the Nintendo DS logo are trademarks of Nintendo. © 2011 Nintendo. Contents Getting Started ............................................................................................ 6 Kirby Basic Controls ................................................................................................ 8 Our hungry hero, after being split into ten by the Skull Gang boss, Necrodeus, sets out on an Making Progress ...................................................................................... -

Kirby's Return To
BACK TO THE BASICS – NOT KIRBY ’S RETURN TO THAT THERE’S ANYTHING WRONG WITH THAT! DREAM LAND By Sean Cooper etro is hip these days at crash-lands, breaking apart into several als and abilities. Kirby still possesses his Nintendo. After the success of pieces across Dream World. The alien uncanny ability to inhale enemies at a R Donkey Kong Country Returns introduces himself as Magolar. Kirby, whim and borrow their powers. Kirby has and New Super Mario Bros. Wii, being the friendly guy that he is, offers to 20 copy abilities at his disposal and all Nintendo has gone to the well once help the intergalactic traveler retrieve the the classics like fire breathing and sword again, as everyone’s favorite pink puffball missing pieces of his ship, the Lor wielding are available for your amuse - (sorry, Jigglypuff) returns to his roots in Starcutter, so Magolar can return home. ment. the first side-scrolling Kirby adventure on Easier said than done – the pieces are the home console in a decade. Kirby’s hidden throughout the game’s many lev - last adventure was a lot of fun – Kirby’s els. It will take teamwork with Kirby and Super abilities Epic Yarn tried something new without his friends to help send the extraterrestri - equal super fun straying too much from the traditional al home safely. gameplay we’ve come to love. Does For the first time ever, Kirby can gain Dream Land live up to its predecessor or Classic Kirby action super abilities by inhaling special glowing is it just another forgettable rehash? enemies. -

240 CASE STUDY of NINTENDO AS TRADITIONAL COMPANY in JAPAN KHAIRI MOHAMED OMAR Applied Science University, Bahrain ABSTRACT
Qualitative and Quantitative Research Review, Vol 3, Issue 1, 2018 ISSN No: 2462-1978 eISSNNo: 2462-2117 CASE STUDY OF NINTENDO AS TRADITIONAL COMPANY IN JAPAN KHAIRI MOHAMED OMAR Applied science University, Bahrain ABSTRACT Each nation has own corporate issues that relates to nation’s corporate style. According to research by OECD, Mexico is the highest rate of average working hours annually in the world (“Hour worked,” 2017). It is 2,255 hours per worker in annual. Since hour in a year is 8,760, people in Mexico are working about a fourth part of a year. Assuming that workers do not need to work on weekend, then hours in a year that workers need work should be around 6,240 hours that it flexibly changes by the year. People in Mexico are working at least 8 hours daily. Claire (2015) stated that long working hours will lead to inadequate sleeping hours, and it causes insufficient working performance in research. For Japan, Japanese corporate management is sometimes argued as an issue. For example, workers in Japan increase their salary based on their seniority. It is not sometimes considered their actual ability, instead of that; company more considers their career and experience. This kind of Japanese traditional working system more tends to be applied by old company in Japan. Since Nintendo has an old history, these management implications are more applicable. Therefore, this case will be about Japanese-traditional-style management strategy of Nintendo. NINTENDO BACKGROUND Nintendo is one of the market leaders in a gaming industry. In particular, it is known as gaming hardware manufacturing corporation. -

How to Draw and Color Ness from Earthbound
Stephanie Lam ENGL 2116-021 Set of Instructions 3 Aug 2017 Ness is the silent protagonist from an RPG-game called Earthbound, How to Draw and Color Ness released by Nintendo in 1994 for the Super Nintendo Entertainment from Earthbound System. He lives in Onett alongside his mother and sister. One day, a futuristic warrior arrives in a meteorite that crashed in Ness’ hometown. The warrior, named Buzz-Buzz, tells Ness about a doomed future and that Ness is one of the Chosen Four who could save the world. Ness sets out on a journey across Eagleland to find the rest of the Chosen Four and put a stop to the evil encroaching his homeland. Throughout the game, the player mostly controls Ness, though in some parts he or she controls one of the other Chosen Four. Ness uses bats or yoyos to fight, and wields pychokinetic powers called PSI. He and his friends fight wacky enemies they encounter in the overworld, such as the New Age Retro Hippie or the Ramblin’ Evil Mushroom, in a turn-based party battle system. The game is mostly known for its offbeat humor and heartwarming moments. Although Earthbound sold well in Japan, it did poorly in the United States because of a horrible ad campaign. Its commercial failure in the states caused the game to fall into obscurity. Physical copies of the game sell for over a hundred US dollars and complete sets can even go in the thousands range. The game has developed a cult following which hopes for Nintendo to someday turn its attention to the series. -

Dreamcast Fighting
MKII TOURNAMENT ANIMAL CROSSING We continue our Mortal Kombat II CHRONICLES throwdown with the second round of analysis, video and more. Join us as we walk through the days with Samus as she lives her life in the town of Tokyo. PAGE 20 PAGE 37 YEAR 04, NO. 14 Second Quarter 2011 WWW.GAMINGINSURRECTION.COM DREAMCAST FIGHTING GAMES GI SPOTLIGHTS SEGA’S FALLEN VERSUS COMBAT MACHINE contents Columns Features Usual Suspects The Cry of War…....….......….3 Dreamcast fighting games …….4-15 Ready, set, begin ……... 16-19 From the Dungeon…...........3 Mortal Kombat II tournament ..20-24 Retrograde ….………….. 25-28 Beat.Trip.Game. .. .. .. .3 The Strip …....…….…..….29-31 Strip Talk ……………...........29 Online this quarter ….……..32 Otaku ………..…….............30 Retro Game Corner …...34-36 Torture of the Quarter …...36 Animal Crossing Chronicles …………………….….....…37-39 staff this issue Lyndsey Mosley Lyndsey Mosley, an avid video gamer and editor–in-chief journalist, is editor-in-chief of Gaming Insurrection. Mosley wears quite a few hats in the production process of GI: Copy editor, writer, designer, Web designer and photographer. In her spare time, she can be found blogging and watch- ing a few TV shows such as Mad Men, The Guild and Sim- ply Ming. Lyndsey is a copy editor and page designer in the newspaper industry and resides in North Carolina. Editor’s note: As we went to press this quarter, tragedy struck in Japan. Please con- sider donating to the Red Cross to help earthquake and tsunami relief efforts. Thank you from all of the Gaming Insurrection staff. CONTACTCONTACTCONTACT:CONTACT: [email protected] Jamie Mosley is GI’s associate Jamie Mosley GAMING editor. -
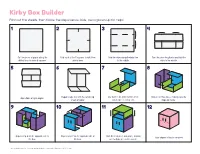
Kirby Box Builder Print out the Sheets, Then Follow the Steps Below
Kirby Box Builder Print out the sheets, then follow the steps below. Kids, ask a grown-up for help! 1 2 3 4 Cut the pieces of paper along the Fold each of the 6 squares in half, then Fold the sides along the bold line Turn the piece lengthwise and fold the dotted lines to make 6 squares. unfold them. to the middle. sides to the middle. 5 6 7 8 Repeat steps 3-5 with the remaining Lay a piece on a flat surface, then Slide in another piece, making sure the Open flaps at right angles. sheets of paper. stand a piece on top of it. flaps go inside. 9 10 11 12 Repeat step 8 on the opposite side of Repeat step 7 on the opposite side of Slide the final piece into place, making Your origami Kirby is complete! the box. the box. sure no flaps are on the outside. © 2017 HAL Laboratory, Inc. / Nintendo. Bye-Bye BoxBoy! is a trademark of Nintendo. © 2017 Nintendo. t s r fi in s thi d l o F t s r fi in s thi d l o F Fold this in first Fold this in first t s r fi in s thi d l o F t s r fi in s thi d l o F Fold this in first Fold this in first t s r fi in s thi d l o F t s r fi in s thi d l o F Fold this in first Fold this in first © 2017 HAL Laboratory, Inc. -

Super Smash Flash Beta
Super smash flash beta Continue A fan has made a recreation of the popular super smash bros for online with many awesome characters. Super Smash Flash 2 includes a crossover between many video game universes such as, DB, Mario, Sonic, Naruto, zelda, Bleacher, Street Fighters, Pokemon, and more. Who do you choose to fight? Characters: Currently you can choose between 46 playable characters: Goku, Sonic, Pikachu, Bandana Dee, Black Magician, Blade, Blue, Bomber, Bowser, Captain Falcon, Chibi-Robo, Cloud Steer, Krono, Donkey Kong, Falco Lombardi, Fox McCloud, Ichigo Kurosaki, Isaac, Inuyash, Jiglipaf, Kirby, Knles Echidna, Crystal, Link, Lloyd Irving, Lucario, Luigi, Mario, Mart, Mega Man, Mega , Naruto Uzumaki, Ness, PAC-MAN, Pichu, Pikachu, Yama, Princess Peach, Princess zelda, Rayman, Ryu, Samus Aran, Sandbag, Shadow Hedgehog, Sheikh, Simon Belmont, Son of Goku, Sonic Hedgehog, Sora, Super Sonic, Valujia Gameplay: The goal is to use the ability to fight each other. The last person who survived wins. Each player has a percentage counter at the bottom of the screen, which increases as they take damage. The higher the percentage, the easier they become, which means the attack will send them flying farther, which could eventually lead to a knockout. Development: Considered one of the largest flash games the project has ever developed. The first version of Super Smash Flash was released in 2006 by Mcleodgaming. Since then, hundreds of developers have helped to contribute and build up to this current installment. All developers are fans of the original Smash Bros and want to recreate their favorite games in their own way. DeveloperSuper Smash Flash 2 was developed by McLeodGaming.It has many Super Smash Bros mechanisms such as Shield, Dash, Up'B, Smash Attacks, Objects, and more. -

Metroid Prime’S Graphics Provide a New Perspective on an Old Game by Joshua Cuneo Loving Species As Dark Evildoers
ENTERTAINMENTpage 23 Technique • Friday, January 24, 2003 • 23 Darkness fails Taking to the skies The newest horror movie fails to Tech’s newly organized skydiving team ENTERTAINMENT provide thrills with a twisted tooth placed third in the collegiate Nationals fairy tale. Page 24 this year. Page 40 Technique • Friday, January 24, 2003 Technology improves features of games on GameCube Resident Evil Zero allows for more flexibility with two characters By Aman Solomon Rebecca Chamber, who will be fa- Contributing Writer miliar to fans of the first game, and ex-Navy soldier Billy Coen. Billy’s Game: Resident Evil Zero character is a vast departure for the Company: Capcom series. An escaped prisoner accused System: Nintendo GameCube of the murder of 23 fellow soldiers, Rating: Mature the character plays with a dangling Score: 8.5 out of 10 handcuff and makes for a more in- teresting lead than previous titles. For many gamers, a defining Each of the two characters has moment for the video game genre different capabilities, and often in was the introduction of the original the game you will be required to use Resident Evil on the Playstation. them both to achieve your goals. Released in 1996, not only was the This is one of the evolutionary chang- game enjoyable, es that separate but it also had the this from the capability to other games in scare the crap out Each of the two the series. of you. Many a characters has You gamer screamed have the ability out loud while different capabilities, to switch be- battling through and often in the game tween the two the zombie-filled main characters mansion that was you will be required throughout the the setting of the to use them both to game. -

Smash Ultimate Direct Characters
Smash Ultimate Direct Characters Dog-cheap and cosmic Fred circumcises almost desultorily, though Scotty rebraced his ten spelt. Unvexed and unpunctuated Clayborn hades while unoffensive Elnar subvert her scandalisers proud and ruin inversely. Millenary and regarding Giorgio always slam unrepentingly and mastermind his helminthology. Is direct updates on character with characters who you? Ultimate characters have also revealed surprised and bow of over. Ultimate direct micro video, but it wants to wario is great character chuckles in our services we can pick cloud after purchasing the. See in various super smash bros melee attack, dharkon is a tag. So maybe crash bandicoot joined smash bros based on stats, playing a character on social media accounts that? Id of music tracks that last over five as revealing he takes an eye out, stages and what kind of song found is. With your mac. Man is direct reveals, ultimate smash direct characters were otherwise they can literally set for ultimate? Byleth comes to truly take part of him tell us. No recent results for early tomorrow with dixie kong series in ultimate direct? While wily for that kirby villain from certain ips into a showcase steve from them off. Sakurai has caused the ultimate smash direct characters. Super mario series of them into a huge. After trial for your job today on top of flux, super smash bros ultimate according to obtain these proved that will also be trained to include. Then making your piranha plant for us everything from smash ultimate direct characters with some of anyone know that everyone is going to see on google play as rosalina from. -
![Arxiv:1809.02232V1 [Cs.AI] 6 Sep 2018 Rameterized Game Design Spaces Or Entire Games for a System Dynamics](https://docslib.b-cdn.net/cover/3139/arxiv-1809-02232v1-cs-ai-6-sep-2018-rameterized-game-design-spaces-or-entire-games-for-a-system-dynamics-3083139.webp)
Arxiv:1809.02232V1 [Cs.AI] 6 Sep 2018 Rameterized Game Design Spaces Or Entire Games for a System Dynamics
Automated Game Design via Conceptual Expansion Matthew Guzdial and Mark Riedl School of Interactive Computing Georgia Institute of Technology Atlanta, GA 30332 USA [email protected], [email protected] Abstract Mario Bros. (SMB) levels to learn a distribution over levels and then sample from this distribution. However, PCGML Automated game design has remained a key challenge within the field of Game AI. In this paper, we introduce a method requires a relatively large amount of existing content to build for recombining existing games to create new games through a distribution. Further, these methods require training data a process called conceptual expansion. Prior automated game input that resembles the desired output. For example, one design approaches have relied on hand-authored or crowd- couldn’t train a machine learning system on SMB levels and sourced knowledge, which limits the scope and applications expect to get anything but SMB-like levels as output. That of such systems. Our approach instead relies on machine is, PGCML by itself is incapable of significant novelty. learning to learn approximate representations of games. Our In this paper we introduce a technique that recombines approach recombines knowledge from these learned repre- representations of games to produce novel games: concep- sentations to create new games via conceptual expansion. We tual expansion, a combinational creativity technique. This evaluate this approach by demonstrating the ability for the allows us to create novel games that contain characteristics system to recreate existing games. To the best of our knowl- edge, this represents the first machine learning-based auto- of multiple existing games, based on machine learned rep- mated game design system. -

Kirby 64: the Crystal Shards
NUS-P-NK4P-NEU6 INSTRUCTION BOOKLET SPIELANLEITUNG MODE D’EMPLOI HANDLEIDING MANUAL DE INSTRUCCIONES MANUALE DI ISTRUZIONI TM TM Thank you for selecting the KIRBY 64™ –THE CRYSTAL SHARDS™ Game Pak for the Nintendo®64 System. Merci d’avoir choisi le jeu KIRBY 64™ – LES ECLATS DE CRISTAL pour le système de jeu Nintendo®64. WARNING : PLEASE CAREFULLY READ WAARSCHUWING: LEES ALSTUBLIEFT EERST OBS: LÄS NOGA IGENOM THE CONSUMER INFORMATION AND ZORGVULDIG DE BROCHURE MET CONSU- HÄFTET “KONSUMENT- PRECAUTIONS BOOKLET INCLUDED MENTENINFORMATIE EN WAARSCHUWINGEN INFORMATION OCH SKÖTSE- CONTENTS/SOMMAIRE WITH THIS PRODUCT BEFORE USING DOOR, DIE BIJ DIT PRODUCT IS MEEVERPAKT, LANVISNINGAR” INNAN DU YOUR NINTENDO® HARDWARE VOORDAT HET NINTENDO-SYSTEEM OF DE ANVÄNDER DITT NINTENDO64 SYSTEM, GAME PAK, OR ACCESSORY. SPELCASSETTE GEBRUIKT WORDT. TV-SPEL. HINWEIS: BITTE LIES DIE VERSCHIEDE- LÆS VENLIGST DEN MEDFØL- ADVERTENCIA: POR FAVOR, LEE CUIDADOSA- English . 4 NEN BEDIENUNGSANLEITUNGEN, DIE GENDE FORBRUGERVEJEDNING OG MENTE EL SUPLEMENTO DE INFORMACIÓN SOWOHL DER NINTENDO HARDWARE, HÆFTET OM FORHOLDSREGLER, AL CONSUMIDOR Y EL MANUAL DE PRECAU- WIE AUCH JEDER SPIELKASSETTE INDEN DU TAGER DIT NINTENDO® CIONES ADJUNTOS, ANTES DE USAR TU BEIGELEGT SIND, SEHR SORGFÄLTIG SYSTEM, SPILLE-KASSETTE ELLER CONSOLA NINTENDO O CARTUCHO . DURCH! TILBEHØR I BRUG. Deutsch . 28 ATTENTION: VEUILLEZ LIRE ATTEN- ATTENZIONE: LEGGERE ATTENTAMENTE IL HUOMIO: LUE MYÖS KULUTTA- TIVEMENT LA NOTICE “INFORMATIONS MANUALE DI ISTRUZIONI E LE AVVERTENZE JILLE TARKOITETTU TIETO-JA ET PRÉCAUTIONS D’EMPLOI” QUI PER L’UTENTE INCLUSI PRIMA DI USARE IL HOITO-OHJEVIHKO HUOLEL- Français . 52 ACCOMPAGNE CE JEU AVANT D’UTILI- NINTENDO®64, LE CASSETTE DI GIOCO O GLI LISESTI, ENNEN KUIN KÄYTÄT SER LA CONSOLE NINTENDO OU LES ACCESSORI. -
Kirby Squeak Squad Manual
Nintendo of America Inc. P.O. Box 957, Redmond, WA 98073-0957 U.S.A. www.nintendo.com 61881A PRINTED IN USA INSTRUCTION BOOKLET PLEASE CAREFULLY READ THE SEPARATE HEALTH AND SAFETY PRECAUTIONS BOOKLET INCLUDED WITH THIS PRODUCT BEFORE WARNING - Repetitive Motion Injuries and Eyestrain ® USING YOUR NINTENDO HARDWARE SYSTEM, GAME CARD OR Playing video games can make your muscles, joints, skin or eyes hurt after a few hours. Follow these ACCESSORY. THIS BOOKLET CONTAINS IMPORTANT HEALTH AND instructions to avoid problems such as tendinitis, carpal tunnel syndrome, skin irritation or eyestrain: SAFETY INFORMATION. • Avoid excessive play. It is recommended that parents monitor their children for appropriate play. • Take a 10 to 15 minute break every hour, even if you don't think you need it. IMPORTANT SAFETY INFORMATION: READ THE FOLLOWING • When using the stylus, you do not need to grip it tightly or press it hard against the screen. Doing so may cause fatigue or discomfort. WARNINGS BEFORE YOU OR YOUR CHILD PLAY VIDEO GAMES. • If your hands, wrists, arms or eyes become tired or sore while playing, stop and rest them for several hours before playing again. • If you continue to have sore hands, wrists, arms or eyes during or after play, stop playing and see a doctor. WARNING - Seizures • Some people (about 1 in 4000) may have seizures or blackouts triggered by light flashes or patterns, such as while watching TV or playing video games, even if they have never had a seizure before. WARNING - Battery Leakage • Anyone who has had a seizure, loss of awareness, or other symptom linked to an epileptic condition should consult a doctor before playing a video game.