The Aggregation Mechanism Mining of Passengers' Flow with Period Distribution Based on Suburban Rail Lines
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Program Book(EN)
TRANSPORTATION IN CHINA 2025: CONNECTING THE WORLD 中国交通 2025:联通世界 Transportation in China 2025: Connecting the World 1 CONTENTS The 19th COTA International Conference of Transportation Professionals Transportation in China 2025: Connecting the World Welcome Remarks ······································ 4 Organization Council ································· 8 Organizers ······················································ 13 Sponsors ·························································· 17 Instructions for Presenters ························ 19 Instructions for Session Chairs ················ 19 Program at a Glance ··································· 20 Program ··························································· 22 Poster Sessions ············································· 56 General Information ··································· 86 Conference Speakers & Organizers ······· 95 Pre- and Post-CICTP2019 Events ············ 196 • Welcome Remarks It is our great pleasure to welcome you all to the 19th COTA International Conference Welcome of Transportation Professionals (CICTP 2019) in Nanjing, China. The CICTP2019 is jointly Remarks organized by Chinese Overseas Transportation Association (COTA), Southeast University, and Jiaotong International Cooperation Service Center of Ministry of Transport. The CICTP annual conference series was established by COTA back in 2001 and in the past two decades benefited from support from the American Society of Civil Engineers (ASCE), Transportation Research Board (TRB), and many other -

8Th Metro World Summit 201317-18 April
30th Nov.Register to save before 8th Metro World $800 17-18 April Summit 2013 Shanghai, China Learning What Are The Series Speaker Operators Thinking About? Faculty Asia’s Premier Urban Rail Transit Conference, 8 Years Proven Track He Huawu Chief Engineer Record: A Comprehensive Understanding of the Planning, Ministry of Railways, PRC Operation and Construction of the Major Metro Projects. Li Guoyong Deputy Director-general of Conference Highlights: Department of Basic Industries National Development and + + + Reform Commission, PRC 15 30 50 Yu Guangyao Metro operators Industry speakers Networking hours President Shanghai Shentong Metro Corporation Ltd + ++ Zhang Shuren General Manager 80 100 One-on-One 300 Beijing Subway Corporation Metro projects meetings CXOs Zhang Xingyan Chairman Tianjin Metro Group Co., Ltd Tan Jibin Chairman Dalian Metro Pak Nin David Yam Head of International Business MTR C. C CHANG President Taoyuan Metro Corp. Sunder Jethwani Chief Executive Property Development Department, Delhi Metro Rail Corporation Ltd. Rachmadi Chief Engineering and Project Officer PT Mass Rapid Transit Jakarta Khoo Hean Siang Executive Vice President SMRT Train N. Sivasailam Managing Director Bangalore Metro Rail Corporation Ltd. Endorser Register Today! Contact us Via E: [email protected] T: +86 21 6840 7631 W: http://www.cdmc.org.cn/mws F: +86 21 6840 7633 8th Metro World Summit 2013 17-18 April | Shanghai, China China Urban Rail Plan 2012 Dear Colleagues, During the "12th Five-Year Plan" period (2011-2015), China's national railway operation of total mileage will increase from the current 91,000 km to 120,000 km. Among them, the domestic urban rail construction showing unprecedented hot situation, a new round of metro construction will gradually develop throughout the country. -

The Research About Line 3 and Line 4 Run Independently Transformed of Shanghai Urban Rail Transit
International Journal of Business and Social Science Vol. 5 No. 1; January 2014 The Research about Line 3 and Line 4 run Independently Transformed of Shanghai Urban Rail Transit Aiqin Sun School of Management Shanghai University of Engineering Science Shanghai, China Zhigang Liu Vice-President of School of Urban Rail Transit Professor, Postdoctoral School of Urban Rail Transit Shanghai University of Engineering Science Shanghai, China Hua Hu Deputy Director of Rail Transport Operations Management Department Associate Professor, Doctor School of Urban Rail Transit Shanghai University of Engineering Science Shanghai, China Abstract As Shanghai rail network has been basically completed and its growth in passenger traffic, the situation about Line 3 and Line 4 collinear run has become a bottlenecks that constraint to improve overall network transport. This paper will be based on the analysis of the basic situation of Shanghai Rail Transit Network and Line 3 and Line 4 collinear running status, pointing out the drawbacks of Collinear run, which proposed the necessity and importance of the transformation to change the situation that Line 3 and Line 4 operate independently. And it will give the corresponding suggestions and measures. Key Words: Shanghai rail transit; Line 3; Line 4; run independently 1. The Status Quo of Development of Shanghai Rail Transit Network and Collinear Operation of Line3 and Line 4 1.1 Development of Shanghai Rail Transit Network With the rapid expansion of Shanghai urban rail transit network, the benefit of rail network passenger flow is increasingly prominent. The proportion of network passenger continues to rise, and enter the period of growing leaps and bounds with geometric growth. -

Transportation Situation and Traffic Air Pollution Status in Shanghai
AEI-SAES-Re. G-0309-07094/00138.07 NO: 2005-003 Transportation Situation and Traffic Air Pollution Status in Shanghai Vehicle Emissions Control and Health Benefits; Technical and Policy Barriers to Sustainable Transport (Part One Report, Draft) Shanghai Academy of Environmental Sciences Shanghai, P.R. China January 27, 2005 Transportation Situation and Traffic Air Pollution Status in Shanghai Vehicle Emissions Control and Health Benefits; Technical and Policy Barriers to Sustainable Transport (Part One Report, Draft) Funded By: U.S. Energy Foundation, EMARQ Report Period: February 1, 2004 to January 21, 2005 Grant Number: G-0309-07094 Team Leaders: Changhong CHEN Professor/Deputy Chief Engineer Shanghai Academy of Environmental Sciences (SAES) Bingheng CHEN Professor School of Public Health (SOPH) Fudan University Qingyan FU Senior Engineer Shanghai Environmental Monitoring Center (SEMC) Team Members: Qiguo JING, Assistant Engineer, SAES Haidong KAN Ph.D., SOPH, Fudan University Lily Assistant Engineer, SAES Hansheng PAN Assistant Engineer, SAES Guohai CHEN Senior Engineer, SEMC Haiying HUANG Assistant Engineer, SAES Bingyan WANG Assistant Engineer, SAES Minghhua CHEN Senior Engineer, SAES Jibing QIU Engineer, SAES Cheng HUANG Masters Student, East China University of Science and Technology (ECUS&T) Yi DAI Masters Student, ECUS&T Haikun WANG Masters Student, ECUS&T Jing ZHAO Masters Student, ECUS&T Transportation Situation and Traffic Air Pollution Status in Shanghai Vehicle Emissions Control and Health Benefits; Technical and Policy Barriers to Sustainable Transport (Part One Report, Draft) Authors Changhong CHEN, Jiguo JING, Lyli, Cheng HUANG, Hansheng PAN, Haikun WANG, Yi DAI, Haiying HUANG, Jing ZHAO Co-Authors Guohai CHEN, Bingyan WANG, Hua QIAN, Haixia DAI, Hongyi LIN, Shaojun WANG Shanghai Academy of Environmental Sciences Shanghai, P.R. -

NEW LRT SYSTEMS for 2013 Hong Kong’S Changing Transit Landscape
THE INTERNATIONAL LIGHT RAIL MAGAZINE HEADLINES l Royal opening for Casablanca tramway l DART becomes USA’s biggest LRT system l Edinburgh Trams - full speed tests begin TOURS DE FORCE: NEW LRT SYSTEMS FOR 2013 Hong Kong’s changing transit landscape Salt Lake City Liberec Utah’s key player The dual-gauge in the modern network with renaissance high ambitions of US light rail for the future FEBRUARY 2013 No. 902 WWW . LRTA . ORG l WWW . TRAMNEWS . NET £3.80 TAUT_1302_Cover.indd 1 03/01/2013 13:54 AD TRAM URBAN.pdf 2 27/06/12 11:18 C M Y CM With the merger of three of their companies, CAF Group MY has multiplied resources in a single company: CY CAF Power & Automation. CMY CAF Group promoted the merger of three of its companies (Traintic, Trainelec and DTQ4) K to form a single company: CAF Power & Automation. A new company dedicated to the design and production of onboard power units as well as control and communication systems for any type of rolling stock. CAF Power & Automation is an evolution in the solution suppliers market for the international rail sector, providing its own technology and human team, which is both adaptable and highly qualified. 60th UITP World Congress and Mobility & City Transport Exhibition # 21 Congress sessions and 10 Regional workshops # 15 Expo forums to share product development information # Platform for innovations, networking, business opportunities # Multi-modal Exhibition, 30,000m² # Over 150 speakers from 30+ countries # A special Swiss Day! www.uitpgeneva2013.org Organiser Local host Supporters Under the patronage of 42_TAUT1302_layoutpage.indd 1 19/12/2012 10:45 Contents The official journal of the Light Rail Transit Association 44 News 44 FEBRUARY 2013 Vol. -

Pew.2657/Shanghai Report
solutions+ + Transportation in Developing Countries Greenhouse Gas Scenarios for Shanghai, China + Hongchang Zhou T ONGI U NIVERSITY, S HANGHAI Daniel Sperling I NSTITUTE OF T RANSPORTATION S TUDIES, U NIVERSITY OF + CALIFORNIA,DAVIS Transportation in Developing Countries Greenhouse Gas Scenarios for Shanghai, China Prepared for the Pew Center on Global Climate Change by Hongchang Zhou T ONGJI U NIVERSITY,SHANGHAI Daniel Sperling Mark Delucchi Deborah Salon I NSTITUTE OF T RANSPORTATION S TUDIES,UNIVERSITY OF CALIFORNIA,DAVIS J ULY 2001 Contents Foreword ii Executive Summary iii I. Introduction 1 A. China: A Changing Nation 1 B. Shanghai: A City in Transition 2 II. Shanghai's Transportation Picture 4 A. Transport Infrastructure: Plans and Investments 7 B. Vehicle Ownership in Shanghai 8 C. Motorization in the Coming Decades 10 III. Policies and Strategies 14 A. Air Quality and Energy 14 B. Avoiding Gridlock 17 C. Leapfrog Technology Opportunities 21 V. Scenarios for the Future 23 + A. Greenhouse Gas Scenarios 23 B. High Greenhouse Gas Emissions Scenario 26 C. Low Greenhouse Gas Emissions Scenario 28 V. Conclusion 31 Glossary 34 Appendix 35 + Endnotes 40 i Transportation Scenarios for Shanghai, China + Foreword Eileen Claussen, President, Pew Center on Global Climate Change The transportation sector is a leading source of greenhouse gas (GHG) emissions worldwide, and one of the most difficult to control. In developing countries, where vehicle ownership rates are consider- ably below the OECD average, transport sector emissions are poised to soar as income levels rise. This is especially true for China, whose imminent accession to the World Trade Organization will contribute to economic growth and could make consumer credit widely available for the first time. -
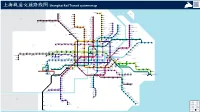
广东地铁迷 上 海 轨 道 交 通 路 线 图 Shanghai Rail Transit System Map
广东地铁迷 上 海 轨 道 交 通 路 线 图 Shanghai Rail Transit system map https://guangdongmtr.home.blog/ 宝 山 Baoshan 江杨北路 铁力路 North Jiangyang Road Tieli Road 嘉定北 长 兴 North Jiading 美兰湖 Changxing Meilan Lake 友谊路 嘉定西 Youyi Road West Jiading 罗南新村 Luonan Xincun 富锦路 Fujin Road 宝杨路 白银路 Baoyang Road 昆 山 Baiyin Road 潘广路 Panguang Road 友谊西路 Kunshan West Youyi Road 水产路 光明路 上海汽车城 上海赛车场 Shuichan Road Guangming Road Shanghai Automobile City Shanghai Circuit 嘉定新城 刘行 Jiading Xincheng Liuhang 宝安公路 花桥 兆丰路 安亭 昌吉东路 Bao'an Highway 淞滨路 Huaqiao Zhaofeng Road Anting East Changji Road Songbin Road 马陆 顾村公园 Gucun Park Malu 共富新村 张华浜 新江湾城 Gongfu Xincun Xinjiangwancheng 南翔 Zhanghuabang 嘉 定 Nanxiang 祁华路 Jiading Qihua Road 呼兰路 殷高东路 市光路 港城路 Hulan Road 淞发路 East Yingao Road Shiguang Road Gangcheng Road 桃浦新村 南陈路 场中路 Songfa Road Taopu Xincun Nanchen Road Changzhong Road 通河新村 嫩江路 长江南路 三门路 外高桥保税区北 上海大学 Tonghe Xincun Sanmen Road Nenjiang Road North Waigaoqiao Free Trade Zone 武威路 Shanghai University 上大路 South Changjiang Road Wuwei Road Shangda Road 大场镇 共康路 江湾体育场 翔殷路 航津路 Gongkang Road 殷高西路 Xiangyin Road 祁连山路 Dachang Town West Yingao Road Jiangwan Stadium Hangjin Road Qilianshan Road 行知路 彭浦新村 江湾镇 五角场 黄兴公园 外高桥保税区南 李子园 Xingzhi Road Pengpu Xincun Huangxing Park Liziyuan Jiangwan Town Wujiaochang South Waigaoqiao Free Trade Zone 上海西站 大华三路 汶水路 国权路 洲海路 Wenshui Road 大柏树 Guoquan Road West Shanghai Railway Station Dahuasan Road Dabaishu 延吉中路 Zhouhai Road Middle Yanji Road 上海马戏城 虹 口 同济大学 普 陀 真如 新村路 赤峰路 Tongji University 五洲大道 Zhenru Xincun Road Shanghai Circus World Hongkou 黄兴路 Wuzhou Avenue Putuo Chifeng -

Identifying Organizational and Contractual Drivers Behind Metro Accidents in Shanghai
IDENTIFYING ORGANIZATIONAL AND CONTRACTUAL DRIVERS BEHIND METRO ACCIDENTS IN SHANGHAI Yue Chen, 4181166 Construction Management and Engineering Faulty of Civil Engineering Technology University of Delft November 2013 0 ABSTRACT In recent years, China has witnessed rapid development in urban transportation, especially in metro projects. However the safety records of metro projects is rather worrying and cannot help to make us think where actually is going wrong. Official reports have claimed that the causes for those metro accidents are mainly from technical and organizational aspects. But are the reports really telling the true story? Or are there deeper reasons that lead to accidents which are not so obvious? In previous studies, Martin de Jong and Yongchi Ma have asked the same question. They conduct their research on three Chinese cities of Beijing, Hangzhou and Dalian through Jens Rasmussen’s safety theory: drift to safety boundaries. In this theory, various incentives drive stakeholders to trade off quality and safety for other core values, resulting in safety boundaries to be crossed. All three cities represent a certain extent of profit driven, excessive subcontracting and loose monitoring which rightly match what is described in Rasmussen’s theory. In my study, I will take the city Shanghai as an example to do a replicative research following Martin de Jong and Ma Yongchi’s work. Based on the main research question of searching for the contractual and organizational arrangements in metro accidents, firstly Rasmussen’s theory will be discussed in Chapter 2 to lay a theoretical underpinning for latter research. Secondly the development of Shanghai metro system will be introduced to provide background information for latter case studies. -

Risk Analysis and Fuzzy Comprehensive Assessment on Construction of Shield Tunnel in Shanghai Metro Line
INTERNATIONAL SOCIETY FOR SOIL MECHANICS AND GEOTECHNICAL ENGINEERING This paper was downloaded from the Online Library of the International Society for Soil Mechanics and Geotechnical Engineering (ISSMGE). The library is available here: https://www.issmge.org/publications/online-library This is an open-access database that archives thousands of papers published under the Auspices of the ISSMGE and maintained by the Innovation and Development Committee of ISSMGE. Geotechnical Aspects of Underground Construction in Soft Ground – Ng, Huang & Liu (eds) © 2009 Taylor & Francis Group, London, ISBN 978-0-415-48475-6 Risk analysis and fuzzy comprehensive assessment on construction of shield tunnel in Shanghai metro line H.B. Zhou, H. Yao & W.J. Gao Shanghai Jianke Project Management Co., Ltd., Shanghai, P.R.China ABSTRACT: Based on risk management of metro line in Shanghai the risk analysis and fuzzy comprehensive assessment model was introduced to the very long metro line project risk assessment of shield tunnel construction. Firstly, Work Breakdown Structure method was brought forward to break down the shield tunnel construction works according to the features of the engineering geology and surrounding building and underground public pipes, the fault tree method was used to identify the shield tunnel construction’s risk events and risk factors and the risk list can be established. Secondly, the fuzzy comprehensive assessment model was presented to assess the construction risk in view of the complexity of underground space and difficulty of quantifying the evaluation parameters, and the sub-project’s risk level and the project’ overall risk level can be calculated . Finally, a case about very long metro line project in Shanghai was studied, the assessment results is consistent with reality. -

Railway Operations
Executive MTR CORPORATION LIMITED 09 management’s report Railway Operations SARS posed serious short-term challenges to the railway operations, Metros (CoMET) benchmarking report and won for the fifth time the but the small decline in revenue testifies to the subsequent recovery Customer Service Award in the transportation category organised by and MTR’s effective operations management. Total fare revenues fell “Next Magazine”. by 4% to HK$5,489 million. Service improvements Patronage The largest network enhancement was the completion of four- Patronage fell by up to 25% during the SARS peak but recovered later tracking of the Airport Railway between Lai King and Olympic stations, in the year, helped by traffic on the new Tseung Kwan O Line. as well as the new Nam Cheong Station on the Tung Chung Line (TCL). Four-tracking allows AEL and TCL trains to operate on separate tracks MTR Lines recorded total passenger volume of 770 million, against for 4.5 kilometres and its completion contributed to the successful 777 million in 2002, a 24.3% share of the total franchised public opening of the interchanges with KCRC’s West Rail at Nam Cheong transport market, and a good increase from 2002. This included an and Mei Foo stations. During the year,TCL trains were converted from increased share of cross-harbour traffic to 58.7%. Fare revenues fell 7-car to 8-car formation, resulting in a 14% increase in capacity. slightly to HK$5,064 million from HK$5,167 million. In 2003 we extended inter-modal fare discounts to travellers Airport Express Line (AEL) patronage declined 19% to 6.8 million. -

Consideration on Construction and Development of Shanghai Smart Metro
New Metro (2020) 1(3): 1-10 INTELLIGENT METRO Consideration on Construction and Development of Shanghai Smart Metro Liu Chunjie1,*, Sun Yu1, Zhao Yuqing1, Cai Qing1 1Shanghai Shentong Metro Group Co., Ltd., Shanghai 201103, China. *Corresponding author: [email protected] © The Authors 2020 ABSTRACT ARTICLE HISTORY The degree of intelligence and service level of urban rail transit has Received: 10-02-2020 significant influence on the measurement of intelligent transportation. In Revised: 15-03-2020 this paper, the importance of smart metro development is discussed from Accepted: 20-03-2020 the perspectives of national development background, technology development trends, and people’s basic requirements, and the features of KEYWORDS smart metro in multiple levels are analyzed. On this basis, the construction Urban rail transit target, system architecture, and construction methods of smart metro are put Smart metro forward, and the applications of smart metro are elaborated from smart Technical framework construction, smart operation and maintenance, and smart service. Smart application With the rapid development of new generation 1. Development background communication and computer technologies such as 5G, block chain, and artificial intelligence, mankind 1.1. Construction of transportation power has ushered in the fifth industrial revolution, which has also added wings to the development of smart In September 2019, the Central Committee of the metro. In recent years, the smart applications of Communist Party of China and the State Council -
Sanctioned Entities Name of Firm & Address Date of Imposition of Sanction Sanction Imposed Grounds China Railway Constructio
Sanctioned Entities Name of Firm & Address Date of Imposition of Sanction Sanction Imposed Grounds China Railway Construction Corporation Limited Procurement Guidelines, (中国铁建股份有限公司)*38 March 4, 2020 - March 3, 2022 Conditional Non-debarment 1.16(a)(ii) No. 40, Fuxing Road, Beijing 100855, China China Railway 23rd Bureau Group Co., Ltd. Procurement Guidelines, (中铁二十三局集团有限公司)*38 March 4, 2020 - March 3, 2022 Conditional Non-debarment 1.16(a)(ii) No. 40, Fuxing Road, Beijing 100855, China China Railway Construction Corporation (International) Limited Procurement Guidelines, March 4, 2020 - March 3, 2022 Conditional Non-debarment (中国铁建国际集团有限公司)*38 1.16(a)(ii) No. 40, Fuxing Road, Beijing 100855, China *38 This sanction is the result of a Settlement Agreement. China Railway Construction Corporation Ltd. (“CRCC”) and its wholly-owned subsidiaries, China Railway 23rd Bureau Group Co., Ltd. (“CR23”) and China Railway Construction Corporation (International) Limited (“CRCC International”), are debarred for 9 months, to be followed by a 24- month period of conditional non-debarment. This period of sanction extends to all affiliates that CRCC, CR23, and/or CRCC International directly or indirectly control, with the exception of China Railway 20th Bureau Group Co. and its controlled affiliates, which are exempted. If, at the end of the period of sanction, CRCC, CR23, CRCC International, and their affiliates have (a) met the corporate compliance conditions to the satisfaction of the Bank’s Integrity Compliance Officer (ICO); (b) fully cooperated with the Bank; and (c) otherwise complied fully with the terms and conditions of the Settlement Agreement, then they will be released from conditional non-debarment. If they do not meet these obligations by the end of the period of sanction, their conditional non-debarment will automatically convert to debarment with conditional release until the obligations are met.