Shadow Algorithms Data Miner Shadow Algorithms Data Miner
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Developing an Execution Plan for Scan to BIM Raghavendra Bhat Stantec
CES469694 Developing an Execution Plan for Scan to BIM Raghavendra Bhat Stantec Joseph Huang Stantec Learning Objectives • Discover requirements for a Scan-to-BIM job • Learn how to define and set standards for level of accuracy and level of development • Learn how to save time in handling and modeling from large-size point clouds • Learn about QC workflows using Revit templates, Navisworks, and Virtual Reality Description The quality of a Scan to BIM (Building Information Modeling) model can vary, depending on the surveyor, instrument used, field conditions, especially on the requirements specified. There are, however, no industry standards templates available to follow. This class will focus on the essentials for developing a Scan to BIM execution plan. Starting form providing & clarifying scope of work to define LOD requirements shall be discussed. There are a lot of potential risks that need to be identified and highlighted when picking up a Scan to BIM job. We will discuss some of these cases with project examples. Basic tools like Revit, ReCap, Navisworks available can help us through this process of visualizing model mistakes and getting a quality product. We will learn several tips that can assist us while facing the quality control of a model replicated from a point cloud. Those tips will also help us locate where the focus should go in each case. The goal of this class is, therefore, not only to learn the available tools, but also to analyze the current gaps in setting up Scan to BIM project execution plan. The agenda we will -

Science Fiction Artist In-Depth Interviews
DigitalArtLIVE.com DigitalArtLIVE.com SCIENCE FICTION ARTIST IN-DEPTH INTERVIEWS THE FUTURE OCEANS ISSUE ARTUR ROSA SAMUEL DE CRUZ TWENTY-EIGHT MATT NAVA APRIL 2018 VUE ● TERRAGEN ● POSER ● DAZ STUDIO ● REAL-TIME 3D ● 2D DIGITAL PAINTING ● 2D/3D COMBINATIONS We visit Portugal, to talk with a master of the Vue software, Artur Rosa. Artur talks with Digital Art Live about his love of the ocean, his philosophy of beauty, and the techniques he uses to make his pictures. Picture: “The Sentinels” 12 ARTUR ROSA PORTUGAL VUE | PHOTOSHOP | POSER | ZBRUSH WEB DAL: Artur, welcome back to Digital Art Live magazine. We last interviewed you in our special #50 issue of the old 3D Art Direct magazine. That was back in early 2015, when we mainly focussed on your architectural series “White- Orange World” and your forest pictures. In this ‘Future Oceans’ themed issue of Digital Art Live we’d like to focus on some of your many ocean colony pictures and your recent sea view and sea -cave pictures. Which are superb, by the way! Some of the very best Vue work I’ve seen. Your recent work of the last six months is outstanding, even more so that the work you made in the early and mid 2010s. You must be very pleased at the level of achievement that you can now reach by using Vue and Photoshop? AR: Thank you for having me again, and thank you for the compliment and feedback. I’m humbled and honoured that my work may be of interest for your readers. To be honest, I’m never quite sure if my work is getting better or worse. -

An Introduction to Building 3D Crime Scene Models Using Sketchup
ARTICLE Original Article An Introduction to Building 3D Crime Scene Models Using SketchUp Elissa St. Clair1, Andy Maloney2, and Albert Schade III3 1 Naval Criminal Investigative Service, 2 FORident Software, 3 Berks County District Attorney’s Office, Forensic Services Unit ABSTRACT ARTICLE INFORMATION Crime scene investigators generally have two options when they need to create a three-dimensional (3D) Received: 11 May 2012 model of a crime scene: enlist the services of an expert 3D modeller who specializes in graphic modelling or Revised: 20 July 2012 learn one of the full-fledged modelling tools to create the model themselves. Many modelling tools have a Accepted: 22 September 2012 very steep learning curve, so the time required to invest in learning a tool to get even a simple result is often prohibitive. In this article, we introduce SketchUp (version 8) as a relatively easy-to-use tool for modelling Citation: St. Clair E, Maloney A, crime scenes in 3D, give an example of how the software can be applied, and provide resources for further Schade A. An Introduction to Building 3D Crime Scene Models information. Using SketchUp. J Assoc Crime Scene Reconstr. 2012:18(4);29-47. Author Contacts: Keywords: Crime scene sketching, 3D visualization, software modelling, crime scene models, SketchUp, [email protected], [email protected], Trimble, crime scene reconstruction, forensic science [email protected] Introduction modelling or computer aided design (CAD) to Computer graphics have been used to enhance produce a meaningful 3D model. As a result, the visualization of shapes and structures across investigators have been limited in terms of a wide variety of disciplines since the 1970s, which scenes they can model in 3D because of when the capability to produce computerized the time-consuming and expensive nature of 3D models was first developed [1]. -

Cour Art of Illusion
© Club Informatique Pénitentiaire avril 2016 Initiation au dessin 3D avec "Art Of Illusion" Sommaire OBJECTIFS ET MOYENS. ..................................................... 2 LES MATERIAUX. ................................................................ 30 PRESENTATION GENERALE DE LA 3D.......................... 2 Les matériaux uniformes ..................................... 30 La 3D dans la vie quotidienne. .............................. 2 Les matériaux procéduraux................................. 30 Les Outils disponibles. ........................................... 2 LES LUMIERES..................................................................... 31 PRESENTATION GENERALE DE "ART OF ILLUSION"3 Les lumières ponctuelles. .................................... 31 L'aide. ................................................................... 3 Les lumières directionnelles ................................ 32 L'interface. ............................................................ 4 Les lumières de type "spot"................................. 32 Le système de coordonnées................................... 6 Exemples de lumières.......................................... 33 LES OBJETS ............................................................................. 9 LES CAMERAS. ..................................................................... 34 Les primitives. ....................................................... 9 Les filtres sur les caméras.................................... 35 Manipulation des objets. ................................... -

An Overview of 3D Data Content, File Formats and Viewers
Technical Report: isda08-002 Image Spatial Data Analysis Group National Center for Supercomputing Applications 1205 W Clark, Urbana, IL 61801 An Overview of 3D Data Content, File Formats and Viewers Kenton McHenry and Peter Bajcsy National Center for Supercomputing Applications University of Illinois at Urbana-Champaign, Urbana, IL {mchenry,pbajcsy}@ncsa.uiuc.edu October 31, 2008 Abstract This report presents an overview of 3D data content, 3D file formats and 3D viewers. It attempts to enumerate the past and current file formats used for storing 3D data and several software packages for viewing 3D data. The report also provides more specific details on a subset of file formats, as well as several pointers to existing 3D data sets. This overview serves as a foundation for understanding the information loss introduced by 3D file format conversions with many of the software packages designed for viewing and converting 3D data files. 1 Introduction 3D data represents information in several applications, such as medicine, structural engineering, the automobile industry, and architecture, the military, cultural heritage, and so on [6]. There is a gamut of problems related to 3D data acquisition, representation, storage, retrieval, comparison and rendering due to the lack of standard definitions of 3D data content, data structures in memory and file formats on disk, as well as rendering implementations. We performed an overview of 3D data content, file formats and viewers in order to build a foundation for understanding the information loss introduced by 3D file format conversions with many of the software packages designed for viewing and converting 3D files. -

Sketchup Tutorials, Tips & Tricks, and Links
SketchUp Tutorials, Tips & Tricks, and Links This compendium is for all to use. While I have taken the time to verify every site listed below when they were initially added, that’s also the last time I have checked them. Therefore I ask, you, the user, should a link no longer be valid, or the link contains incorrect information, please e-mail me at [email protected] and I will have the link removed or corrected. It is only through your efforts this compendium can remain as accurate as possible. Thank you for you help and keep on SketchUpping! Steven. ------------------------------------------------------------------------------------------------------------------------------------------------------------------ Quick Links Index (Not all headings are listed below) Animation CAD Related Components Drafting Software File Conversion Fun Stuff Latitude/Longitude/Maps Misc. Software Modeling Software Models New User Tips PDF Creator Photo Editing Photo Measure Polygon Reduction Presentation Software Rendering Ruby Scripts SU Books Terrain Text Texture Editor Textures TimeTracking Tips & Tricks Tutorials Utilities Video Capture Web Music ------------------------------------------------------------------------------------------------------------------------------------------------------------------ SketchUp Books e-mail: [email protected] telephone: 1-973-364-1120 fax: 1-973-364-1126 The SketchUp 5 “Delta” Book -- 49.95The SketchUp Book (Release 5, color) -- 84.95 SU Version 5 Delta: Price $49.95 (This just covers what’s new in V5) SU Version 5: Price $84.95 SU Version 4: Price: $69.95 USD SU Version 4 Delta: Price: $43.95 USD (This just covers what’s new in V4) SU Version 3: Price: $62.95 USD SU Version 2: Price: $54.95 USD Orders can be placed via e-mail, phone, or fax. Visa, MasterCard, American Express accepted. -

Sketchup-Ur-Space-August-2017.Pdf
1. A Letter to the desk of editor A letter direct from the editor desk highlighting on August’17 edition 2. Interview Interview with Mauritz Snyman 3. Cover Storey 11 Best Free 3D Designing Software You Shouldn’t Miss 4. Article Best SketchUp Practices for Exceptional Designs How Easy Is SketchUp for 3D Designs? Maxwell Rendering 4.1 for Smoother 3D Rendering SketchUp for Fine Woodwork Designs 5. Blog 3D Model of London for SketchUp Complex 3D shapes Become Easier with SketchUp Solid Tool How to Use Orbit, Zoom and Pan Tools to Get the Best View Know about Edges and Faces of 3D model in SketchUp my.SketchUp – Take along Your 3D Models Wherever You Go 6. Tips & Tutorial SketchUp Dialog Box – A Complete Tutorial SketchUp Inferences Position the 3D Model Accurately SketchUp to Vizard workflow 4 Reasons why You Need SketchUp for 3D Modeling 7. News Room 8. Magazine Details – The Creative team of Sketchup-ur-Space 1 | Page A letter direct from the editor desk highlighting on August’17 edition This August Edition of SketchUp Ur Space 2017 brings to you interesting and innovative topics that will sharpen your knowledge and expand your creativity in the 3D designing. Each write-up reveals the insight of SketchUp so that you can experience a complete navigation on the application like a pro. Behind this ingeniously presented magazine is the work of our expert team that chooses topics in keeping your interest and learning in mind. They gradually unfold the world of SketchUp where you can experience some welcoming features along with the expansion of the existing one. -

2020/2021 Local-Provided Training Skills Training Application
2020/2021 Local-Provided Training Skills Training Application This application packet consists of the Skills Training Application and the Course Reference List. Your Skills Training Application must be approved by Contract Services Administration Training Trust Fund (CSATTF) prior to taking the requested course. There is no reimbursement for Local-Provided Training. Please note that Contract Services’ facilitation of skills training is not intended to expand, limit or in any way affect the scope of work covered by any collective bargaining agreement. Eligibility: • For Roster classifications, you must be active on the Roster for the applicable local union and classification, and be in compliance with Contract Services training requirements. You may check your status on the Online Roster at www.csatf.org, under “Rosters & Lists.” • For Non-Roster classifications, you must reflect on the Online Roster in the applicable Local Union and classification and be in compliance with Contract Services training requirements. For questions regarding training dates, course content and scheduling, please contact your Local Union. This form must be completed, signed, and returned as instructed below. Submit one signed application for each requested course. Please allow 1-2 weeks for processing. Print all information completely and legibly. Personal information will be updated accordingly. Name: Last four digits of SSN*:_____________________ *First time applicants must provide full SSN Local Union: Job Title/Classification: Address: City: State: Zip Code: Cell #: ( ) - Home #: ( ) - Email: Course #: Course Name: (Please write course name exactly as it appears on the Course Reference List) I have read, understood and agree to all the terms and conditions listed above: Applicant Signature: Date: Return this form to CSATTF via email to [email protected], in person, by fax or mail. -

Using Augmented Reality for Architecture Artifacts Visualizations
Using augmented reality for architecture artifacts visualizations Zarema S. Seidametova1, Zinnur S. Abduramanov1 and Girey S. Seydametov1 1Crimean Engineering and Pedagogical University, 8 Uchebnyi per., Simferopol, 95015, Crimea Abstract Nowadays one of the most popular trends in software development is Augmented Reality (AR). AR applications offer an interactive user experience and engagement through a real-world environment. AR application areas include archaeology, architecture, business, entertainment, medicine, education and etc. In the paper we compared the main SDKs for the development of a marker-based AR apps and 3D modeling freeware computer programs used for developing 3D-objects. We presented a concept, design and development of AR application “Art-Heritage’’ with historical monuments and buildings of Crimean Tatars architecture (XIII-XX centuries). It uses a smartphone or tablet to alter the existing picture, via an app. Using “Art-Heritage’’ users stand in front of an area where the monuments used to be and hold up mobile device in order to see an altered version of reality. Keywords Augmented Reality, smartphones, mobile-AR, architecture artifact, ARToolkit, Vuforia 1. Introduction In recent years, Augmented Reality (AR) has been named as one of the top 10 new technology trends. AR technology has primarily been used for gaming but nowadays it has also found widespread use in education, training, medicine, architecture, archeology, entertainment, mar- keting and etc. According to the International Data Corporation (IDC) [1] worldwide spending on AR and virtual reality (VR) is growing from just over $12.0 billion this year to $72.8 billion in 2024. AR as technology allows researchers, educators and visual artists to investigate a variety of AR apps possibilities using mobile AR in many areas – from education [2, 3, 4, 5, 6] to cultural heritage [7, 8, 9, 10, 11]. -

What Is 3D Printing and Why Should I Care?
3D Printing Initiative Mission: Introduce 3D printing to the community via hands-on training at the library Travel to offer training at clubs, schools, town organizations, etc. Entirely grant funded by the Norwin S. and Elizabeth N. Bean Foundation Two Cube2 printers donated by 3DSystems One printer donated by Folger Technologies Completely volunteer operated No tax impact Why 3D Printing at the Library? Digital literacy Promotes STE(A)M (Science Technology Engineering (Art) and Math) education Entices people into the library who might not normally frequent it 250 libraries in the US offer 3D printers Out of 119,729 libraries of all kinds in the US Source: OITP Perspectives, a publication by the American Library Association (ALA) – 1/2015 How 3D Printing Works For printing an object you need a digital 3D-model. Download it from internet Draw it using computer-assisted design or CAD software Scan an object .STL File Developed in 1987 for 3D Systems the STL format was designed as a standard format to allow data movement between CAD programs and stereolithography machines. 'STL' stands for Surface Tesselation Language (or, depending on who you talk to, perhaps 'STereoLithography file' or 'Standard Transform Language file'). A tessellation is a gap-less, repeating pattern of non-overlapping figures across a surface. Any shape can be used; STL format uses triangles. This triangular mesh is most often derived from the surface - and only the surface - of a 3D CAD designed object. The number of triangles is primarily a function of the size of the surface and the resolution of the tessellation. -

2020/2021 Local-Provided Training Skills Training Application
2020/2021 Local-Provided Training Skills Training Application This application packet consists of the Skills Training Application and the Course Reference List. Your Skills Training Application must be approved by Contract Services Administration Training Trust Fund (CSATTF) prior to taking the requested course. There is no reimbursement for Local-Provided Training. Please note that Contract Services’ facilitation of skills training is not intended to expand, limit or in any way affect the scope of work covered by any collective bargaining agreement. Eligibility: • For Roster classifications, you must be active on the Roster for the applicable local union and classification, and be in compliance with Contract Services training requirements. You may check your status on the Online Roster at www.csatf.org, under “Rosters & Lists.” • For Non-Roster classifications, you must reflect on the Online Roster in the applicable Local Union and classification and be in compliance with Contract Services training requirements. For questions regarding training dates, course content and scheduling, please contact your Local Union. This form must be completed, signed, and returned as instructed below. Submit one signed application for each requested course. Please allow 1-2 weeks for processing. Print all information completely and legibly. Personal information will be updated accordingly. Name: Last four digits of SSN*:_____________________ *First time applicants must provide full SSN Local Union: Job Title/Classification: Address: City: State: Zip Code: Cell #: ( ) - Home #: ( ) - Email: Course #: Course Name: (Please write course name exactly as it appears on the Course Reference List) I have read, understood and agree to all the terms and conditions listed above: Applicant Signature: Date: Return this form to CSATTF via email to [email protected], in person, by fax or mail. -
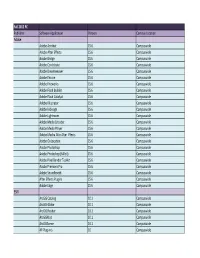
Fall 2012 PC Publisher Software Application Version Campus Location Adobe Adobe Acrobat CS 6 Campuswide Adobe After Effects CS
Fall 2012 PC Publisher Software Application Version Campus Location Adobe Adobe Acrobat CS 6 Campuswide Adobe After Effects CS 6 Campuswide Adobe Bridge CS 6 Campuswide Adobe Contribute CS 6 Campuswide Adobe Dreamweaver CS 6 Campuswide Adobe Encore CS 6 Campuswide Adobe Fireworks CS 6 Campuswide Adobe Flash Builder CS 6 Campuswide Adobe Flash Catalyst CS 6 Campuswide Adobe Illustrator CS 6 Campuswide Adobe InDesign CS 6 Campuswide Adobe Lightroom CS 6 Campuswide Adobe Media Encoder CS 6 Campuswide Adobe Media Player CS 6 Campuswide Adobe Mocha Afor After Effects CS 6 Campuswide Adobe OnLocation CS 6 Campuswide Adobe Photoshop CS 6 Campuswide Adobe Photoshop (64 bit) CS 6 Campuswide Adobe Pixel Bender Toolkit CS 6 Campuswide Adobe Premiere Pro CS 6 Campuswide Adobe Soundbooth CS 6 Campuswide After Effects Plugins CS 6 Campuswide Adobe Edge CS 6 Campuswide ESRI ArcGIS Catalog 10.1 Campuswide ArcGIS Globe 10.1 Campuswide ArcGIS Reader 10.1 Campuswide ArcGISMap 10.1 Campuswide ArcGISScene 10.1 Campuswide All Plug‐in's 10 Campuswide Apple Apple iTunes 10.3 Campuswide Apple Quicktime 7 Pro 7X Campuswide Arudino Arudino 1 Campuswide (ITEC) Rockwall Automation Arena 14 Campuswide (Engineering) Autodesk Site License Autodesk Building Design Suite AutoCAD Architecture Campuswide AutoCAD MEP Campuswide AutoCAD Structural Detailing Campuswide Autodesk Showcase Campuswide Autodesk SketchBook Designer Campuswide Autodesk Revit Campuswide Autodesk 3ds Maxv Design Campuswide Autodesk Navisworks Simulate Campuswide Autodesk Navisworks Manage Campuswide