Japanese Character Input: Its State and Problems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Summary Double Your Typing Speed
Summary Double Your Typing Speed.............................................................1 Stenography Benefits......................................................................1 Speed...........................................................................................................................................1 Fluency Of Thought....................................................................................................................2 Ergonomy....................................................................................................................................3 Mobile/Wearable Computing and Augmented Reality...............................................................3 Memorable Customizable Macros..............................................................................................4 Stenography Is Cool, But................................................................5 Open Source Stenography: Who Is Using It...................................5 Then I Saw The Light.....................................................................6 My Contributions............................................................................7 Stenography Is The Way.................................................................8 Machine stenography costs too much.........................................................................................8 Proprietary steno software might be better..................................................................................9 Learning takes too much -

Speech-To-Text Interpreting in Finland, Sweden and Austria Norberg
https://helda.helsinki.fi Speech-to-text interpreting in Finland, Sweden and Austria Norberg, Ulf 2015 Norberg , U , Stachl-Peier , U & Tiittula , L 2015 , ' Speech-to-text interpreting in Finland, Sweden and Austria ' , Translation & Interpreting , vol. 7 , no. 3 , pp. 36-49 . https://doi.org/10.12807/ti.107203.2015.a03 http://hdl.handle.net/10138/162021 https://doi.org/10.12807/ti.107203.2015.a03 Downloaded from Helda, University of Helsinki institutional repository. This is an electronic reprint of the original article. This reprint may differ from the original in pagination and typographic detail. Please cite the original version. Speech-to-text interpreting in Finland, Sweden and Austria The International Journal for Translation & Interpreting Research Ulf Norberg trans-int.org Stockholm University, Sweden [email protected] Ursula Stachl-Peier University of Graz, Austria [email protected] Liisa Tiittula University of Helsinki, Finland [email protected] DOI: 10.12807/ti.107203.2015.a03 Abstract: Speech-to-text (STT) interpreting is a type of intralingual interpreting mostly used by late deafened and hearing impaired persons who have a spoken language as their first language. In Finland, Sweden and Austria the speech-to-text transfer is performed in real-time by interpreters using a (specially adapted or standard) keyboard that is connected to a screen. As a result of different legislative frameworks governing services for the disabled, STT interpreting has developed differently in different countries and so far there has been little international cooperation. STT interpreting has also been largely ignored by Translation and Interpreting Studies. This paper examines the situation in Finland and Sweden, where STT interpreting training programmes have been available since the 1980s, and Austria, where the first training programme started in 2010, and investigates the norms, values and expectations that guide STT interpreters’ practice in the three countries. -

Using Action-Level Metrics to Report the Performance of Multi-Step Keyboards
Using Action-Level Metrics to Report the Performance of Multi-Step Keyboards Gulnar Rakhmetulla* Ahmed Sabbir Arif† Steven J. Castellucci‡ Human-Computer Interaction Group Human-Computer Interaction Group Independent Researcher University of California, Merced University of California, Merced Toronto I. Scott MacKenzie§ Caitlyn E. Seim¶ Electrical Engineering and Computer Science Mechanical Engineering York University Stanford University Table 1: Conventional error rate (ER) and action-level unit error rate ABSTRACT (UnitER) for a constructive method (Morse code). This table illustrates Computer users commonly use multi-step text entry methods on the phenomenon of using Morse code to enter “quickly” with one handheld devices and as alternative input methods for accessibility. character error (“l”) in each attempt. ER is 14.28% for each attempt. These methods are also commonly used to enter text in languages One of our proposed action-level metrics, UnitER, gives a deeper with large alphabets or complex writing systems. These methods insight by accounting for the entered input sequence. It yields an error require performing multiple actions simultaneously (chorded) or rate of 7.14% for the first attempt (with two erroneous dashes), and in a specific sequence (constructive) to produce input. However, an improved error rate of 3.57% for the second attempt (with only evaluating these methods is difficult since traditional performance one erroneous dash). The action-level metric shows that learning has metrics were designed explicitly for non-ambiguous, uni-step meth- occurred with a minor improvement in error rate, but this phenomenon ods (e.g., QWERTY). They fail to capture the actual performance of is omitted in the ER metric, which is the same for both attempts. -
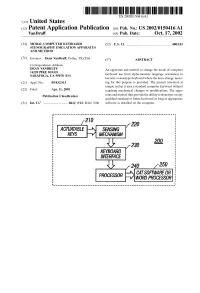
(12) Patent Application Publication (10) Pub. No.: US 2002/0150416A1 Vandruff (43) Pub
US 2002O150416A1 '(19) United States (12) Patent Application Publication (10) Pub. No.: US 2002/0150416A1 VanDruff (43) Pub. Date: Oct. 17, 2002 (54) MODAL COMPUTER KEYBOARD (52) U.S. Cl. .............................................................. 400/103 STENOGRAPHY EMULATION APPARATUS AND METHOD (76) Inventor: Dean VanDruff, Dallas, TX (US) (57) ABSTRACT Correspondence Address: DEAN VANDRUFF An apparatus and method to change the mode of computer 1422O PIKE ROAD SARATOGA, CA 95070 (US) keyboard use from alpha-numeric language orientation to become a Stenotype keyboard where the keys change mean (21) Appl. No.: 09/832,915 ing for this purpose is provided. The present invention is unique in that it uses a Standard computer keyboard without (22) Filed: Apr. 11, 2001 requiring mechanical changes or modifications. The appa Publication Classification ratus and method thus provide the ability to Stenotype on any qualified Standard or future keyboard as long as appropriate (51) Int. Cl." .................................. B41J 5/12; B41J 5/08 Software is installed on the computer. 220 SEWSNG MECHAWS 230 200 KEYBOARD INTERFACE 250 CATSOFTWARE OR WORD PROCESSOR Patent Application Publication Oct. 17, 2002 Sheet 1 of 2 US 2002/0150416A1 FIG. A 202 208 204 216 HOSTIPCI MAIN AUDIO B 206 210 214 218 219 - - - - - - - - - - - A232 LAN EXPANSION BUS GRAPHICS AUDIO/WIDEO HOSTBUSADAPER n 220 222 224 1/ !----Y---------- 200 FIG. 1B 20 220 ACTUATABLE SEWSNG MECHANISM KEYBOARD FIG 2 INTERFACE 250 PROCESSOR CATSOFTWAREPREESSR OR Patent Application Publication Oct. 17, 2002 Sheet 2 of 2 US 2002/0150416A1 UMBER BAR 1 2 3 4 6 7, 8 9 PPER BANK Swest." W 5 0 g WO WEL BANK FIG. -

Io2 Report: Lta Curriculum Design
http://www.ltaproject.eu/ Project Ref: 2018-1-DE01-KA203-004218: LTA Quality Training in real time subtitling across EU and EU languages IO2 REPORT: LTA CURRICULUM DESIGN Grant Agreement nº: 2018-1-DE01-KA203-00 Project acronym: LTA Project title: Quality Training in real-time subtitling across EU and EU languages Funding Scheme: Erasmus + Project Duration: 01/09/2018-31/08/2021 (36 months) Manager: Sprachen-und Dolmetscher-Institut München Beneficiaries: Universitat Autònoma de Barcelona Scuola Superiore per Mediatori Linguistici -Pisa ECQA Velotype SUB-TI Access European Federation of Hard of Hearing People ZDF Digital This project is supported by funding from the European Union. http://www.ltaproject.eu/ Project Ref: 2018-1-DE01-KA203-004218: LTA Quality Training in real time subtitling across EU and EU languages Dissemination level Abbreviation Level X PU Public X PP Restricted to other programme participants (including the Commission Services) RE Restricted to a group specified by the consortium (including the Commission Services) CO Confidential, only for members of the consortium History Chart Issue Date Changed page(s) Cause of change Implemented by 1.00 09-08-2019 First draft SSML 2.00 30-09-2019 several Partners’ input SSML, All 3.00 28-10-2019 several Input by Advisory SSML Board Validation No. Action Beneficiary Date 1 Prepared SSML 09-08-2019 2 Approved All partners 15-09-2019 3 Approved Advisory board members 10-10-2019 4 Released SDI 30-10-2019 Disclaimer: The information in this document is subject to change without notice. Company or product names mentioned in this document may be trademarks or registered trademarks of their respective companies. -

Using Action-Level Metrics to Report the Performance of Multi-Step Keyboards
Using Action-Level Metrics to Report the Performance of Multi-Step Keyboards Gulnar Rakhmetulla* Ahmed Sabbir Arif† Steven J. Castellucci‡ Human-Computer Interaction Group Human-Computer Interaction Group Independent Researcher University of California, Merced University of California, Merced Toronto I. Scott MacKenzie§ Caitlyn E. Seim¶ Electrical Engineering and Computer Science Mechanical Engineering York University Stanford University Table 1: Conventional error rate (ER) and action-level unit error rate ABSTRACT (UnitER) for a constructive method (Morse code). This table illustrates Computer users commonly use multi-step text entry methods on the phenomenon of using Morse code to enter “quickly” with one handheld devices and as alternative input methods for accessibility. character error (“l”) in each attempt. ER is 14.28% for each attempt. These methods are also commonly used to enter text in languages One of our proposed action-level metrics, UnitER, gives a deeper with large alphabets or complex writing systems. These methods insight by accounting for the entered input sequence. It yields an error require performing multiple actions simultaneously (chorded) or rate of 7.14% for the first attempt (with two erroneous dashes), and in a specific sequence (constructive) to produce input. However, an improved error rate of 3.57% for the second attempt (with only evaluating these methods is difficult since traditional performance one erroneous dash). The action-level metric shows that learning has metrics were designed explicitly for non-ambiguous, uni-step meth- occurred with a minor improvement in error rate, but this phenomenon ods (e.g., QWERTY). They fail to capture the actual performance of is omitted in the ER metric, which is the same for both attempts. -

(12) Patent Application Publication (10) Pub. No.: US 2008/0181706 A1 Jackson (43) Pub
US 2008O181706A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2008/0181706 A1 JacksOn (43) Pub. Date: Jul. 31, 2008 (54) TACTILE FORCE SENSOR AND HYBRD Publication Classification STENOTYPE KEYBOARDS AND METHOD OF USE (51) Int. Cl. B4 5/00 (2006.01) (76) Inventor: Johnny J. Jackson, Charleston, (52) U.S. Cl. ........................................................ 400/482 WV (US) Correspondence Address: (57) ABSTRACT THOMPSON HINE L.L.P. A Stenotype keyboard utilizes pressure sensitive tactile sen Intellectual Property Group sors to register key presses and output interpreted keystrokes. P.O. BOX 8801 The pressure sensitive tactile sensors are illuminated inter DAYTON, OH 45401-8801 nally and create detectible changes to the electromagnetic radiation when compressed. The detectible changes are (21) Appl. No.: 12/020,340 picked up by sensors and analyzed to determine which keys are pressed and the appropriate keystrokes are generated. (22) Filed: Jan. 25, 2008 Keystrokes are then either output or stored in memory for later retrieval. The pressure sensitive tactile sensors facilitate Related U.S. Application Data creating keyboard configurations such as combination hybrid (60) Provisional application No. 60/886,572, filed on Jan. keyboards that have both computer style layouts and Steno 25, 2007. type keyboard layouts. U - 304 r - - - - 304 : ( C - & x. s & { & { i 3 - - 304 w & K p Q S / \ \- \- N- N- Y - N - \- \--- Y- \ se 3O2 302 Y 3O2 C --, - --f -- - - \ Patent Application Publication Jul. 31, 2008 Sheet 1 of 6 US 2008/O181706 A1 NYXXXYY-sixxxx six-swaxxxx xxxx xxxxxxx-xx-xx-xxx-xxxxx xxxx ws L six-staxas(BUAEEAL SaaSX S. -

Intersteno E-News 52
Intersteno e - news 52 www.intersteno.org E-news 52 – June 2012 1 Contents Intersteno e Contents ................................................................................. 2 From the President's desk .......................................................... 3 Internet competition 2012 .......................................................... 4 Comments of the Jury President .................................................... 4 A winning experience by Carlo Paris - mother tongue champion of Internet contest 2012 ............................................................................ 9 In memoriam prof. Marcello Melani ............................................. 10 Programme of the meetings of the Council and Professional reporters' section in Prague - 29th September - 2nd October ......................... 12 A new future for Mr. Mark Golden (USA) ...................................... 13 NCRA Board selects Jim Cudahy as next executive director & CEO ..... 14 London 26 September, 1887 - The Birth of Intersteno ..................... 15 From Giuseppe Ravizza to Steve Jobs .......................................... 17 Intersteno Usa group on Facebook .............................................. 18 Competitions ......................................................................... 19 Swiss shorthand competition in Gossau .......................................... 19 Lipsia Open 2012 ..................................................................... 19 13-14 April 2012 - International competitions in The Hague and Dutch -

Ltaproject.Eu
http://www.ltaproject.eu/ Project Ref: 2018-1-DE01-KA203-004218: LTA Quality Training in real time subtitling across EU and EU languages IO1 REPORT: TRAINING PRACTICE Grant Agreement nº: 2018-1-DE01-KA203-00 Project acronym: LTA Project title: Quality Training in real-time subtitling across EU and EU languages Funding Scheme: Erasmus + Project Duration: 01/09/2018-31/08/2021 (36 months) Manager: Sprachen-und Dolmetscher-Institut München Beneficiaries: Universitat Autònoma de Barcelona Scuola Superiore per Mediatori Linguistici ECQA Velotype SUB-TI Access European Federation of Hard of Hearing People ZDF Digital This project is supported by funding from the European Union. http://www.ltaproject.eu/ Project Ref: 2018-1-DE01-KA203-004218: LTA Quality Training in real time subtitling across EU and EU languages Dissemination level Abbreviation Level X PU Public PP Restricted to other programme participants (including the Commission Services) RE Restricted to a group specified by the consortium (including the Commission Services) CO Confidential, only for members of the consortium X History Chart Issue Date Changed page(s) Cause of change Implemented by 1.00 2019/02/14 SDI 2.00 2019/03/30 SDI Validation No. Action Beneficiary Date 1 Prepared SDI 2019/02/14 2 Approved All partners 2019/02/28 3 Released SDI 2019/03/11 4 Approved All partners 2019/03/30 Disclaimer: The information in this document is subject to change without notice. Company or product names mentioned in this document may be trademarks or registered trademarks of their respective companies. All rights reserved The document is proprietary of the LTA consortium members. -

Barrier-Free Communication: Methods and Products
Barrier-free Communication: Methods and Products Proceedings of the 1st Swiss Conference on Barrier- free Communication Winterthur, 15th – 16th September 2017 ZHAW School of Applied Linguistics Institute of Translation and Interpreting Edited by Susanne Johanna Jekat and Gary Massey Proceedings of the 1st Swiss Conference on Barrier-free Communication, ZHAW, Winterthur 2017 DOI 10.21256/zhaw-3000 Susanne Johanna Jekat, Gary Massey (Eds.) Barrier-free Communication: Methods and Products. Proceedings of the 1st Swiss Conference on Barrier-free Communication (2017) This work is a joint effort of the ZHAW Zurich University of Applied Sciences and the University of Geneva. It is approved by swissuniversities and funded by federal contributions in the framework of the Project “P-16: Proposal and implementation of a Swiss research centre for barrier-free communication” (2017-2020). The responsibility for the contents of this work lies with the authors. © The Authors (individual papers) © The Editors (collection) 2018, ZHAW digitalcollection DOI 10.21256/zhaw-3000 This PDF document has been made accessible in axesPDF for Word (www.axes4.com) and in PAVE (www.pave-pdf.org). I Proceedings of the 1st Swiss Conference on Barrier-free Communication, ZHAW, Winterthur 2017 DOI 10.21256/zhaw-3000 The Editors would like to thank the following for their support and cooperation in this work: Scientific Review Board Albl-Mikasa, Michaela Professor of Interpreting Studies, ZHAW Zurich University of Applied Sciences Bouillon, Pierrette Head of the Department -

Free Books & Magazines Looking Back and Going Forward in IT This Page Intentionally Left Blank Looking Back and Going Forward in IT
www.dbebooks.com - Free Books & magazines Looking Back and Going Forward in IT This page intentionally left blank Looking Back and Going Forward in IT Jean-Pierre Corniou First published in France in 2002 by Hermes Science/Lavoisier entitled “La société de la connaissance : nouvel enjeu pour les organisations” First published in Great Britain and the United States in 2006 by ISTE Ltd Translated by Tim Pike Apart from any fair dealing for the purposes of research or private study, or criticism or review, as permitted under the Copyright, Designs and Patents Act 1988, this publication may only be reproduced, stored or transmitted, in any form or by any means, with the prior permission in writing of the publishers, or in the case of reprographic reproduction in accordance with the terms and licenses issued by the CLA. Enquiries concerning reproduction outside these terms should be sent to the publishers at the undermentioned address: ISTE Ltd ISTE USA 6 Fitzroy Square 4308 Patrice Road London W1T 5DX Newport Beach, CA 92663 UK USA www.iste.co.uk © LAVOISIER, 2002 © ISTE Ltd, 2006 The rights of Jean-Pierre Corniou to be identified as the authors of this work has been asserted by them in accordance with the Copyright, Designs and Patents Act 1988. Library of Congress Cataloging-in-Publication Data Corniou, Jean-Pierre. [Société de la connaissance. English] Looking back and going forward in IT / Jean-Pierre Corniou.-- 1st ed. p. cm. ISBN-13: 978-1-905209-58-3 1. Information technology--History. 2. Management information systems. 3. Information technology--Social aspects. -
The Buxton / Microsoft Collection Inventory of Interactive Device Collection
The Buxton / Microsoft Collection Inventory of Interactive Device Collection Bill Buxton First Draft: February 30th, 2011 Current Draft: Feb 28th, 2018 Contents: 1. MICE 11. Watches 2. Tablet Pucks and Pens 12. Wearables: Gloves, Rings, 3. Touch Pads Heads, etc. 4. Joysticks 13. Pedals 5. Trackballs 14. Game Controllers & Toys 6. Chord Keyboards 15. Remote Controls 7. Keyboards 16. Dials 8. Handhelds, PDAs … 17. Miscellaneous 9. e-Readers 18. Reference Material, Toys, … 10. Pen Computers 19. Purging from Collection Note: • Devices that have a “Y” in the right-most column are included in the current collection web-site which can be accessed here: https://www.microsoft.com/buxtoncollection. Note that perhaps less than 1/3 of the collection is on-line, and for the most part, the entries for those that are on-line are minimal (though hopefully still useful), compared to what is being prepared. A new, complete site is under curation and will be posted as soon as possible – but don’t hold your breath. It’s a big job. • Devices with a red “N” in the rightmost column are in the process of being documented and prepared for inclusion on the web site. For requests for photos or other details of items not yet on the site, contact me via email. • The Catalogue Code in the second column tells me where the item is stored. This code is in the form BBB-NNN, where BBB is the bin code & NNN (not always used) is the 3-digit item number in that bin Page 1 of 122 MICE Photo Code Name Year Price Compan Notes Pivot? y M-04 NRC 1968 NFS National Donated by Nestor Burtnyk.