Using Action-Level Metrics to Report the Performance of Multi-Step Keyboards
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Summary Double Your Typing Speed
Summary Double Your Typing Speed.............................................................1 Stenography Benefits......................................................................1 Speed...........................................................................................................................................1 Fluency Of Thought....................................................................................................................2 Ergonomy....................................................................................................................................3 Mobile/Wearable Computing and Augmented Reality...............................................................3 Memorable Customizable Macros..............................................................................................4 Stenography Is Cool, But................................................................5 Open Source Stenography: Who Is Using It...................................5 Then I Saw The Light.....................................................................6 My Contributions............................................................................7 Stenography Is The Way.................................................................8 Machine stenography costs too much.........................................................................................8 Proprietary steno software might be better..................................................................................9 Learning takes too much -

Speech-To-Text Interpreting in Finland, Sweden and Austria Norberg
https://helda.helsinki.fi Speech-to-text interpreting in Finland, Sweden and Austria Norberg, Ulf 2015 Norberg , U , Stachl-Peier , U & Tiittula , L 2015 , ' Speech-to-text interpreting in Finland, Sweden and Austria ' , Translation & Interpreting , vol. 7 , no. 3 , pp. 36-49 . https://doi.org/10.12807/ti.107203.2015.a03 http://hdl.handle.net/10138/162021 https://doi.org/10.12807/ti.107203.2015.a03 Downloaded from Helda, University of Helsinki institutional repository. This is an electronic reprint of the original article. This reprint may differ from the original in pagination and typographic detail. Please cite the original version. Speech-to-text interpreting in Finland, Sweden and Austria The International Journal for Translation & Interpreting Research Ulf Norberg trans-int.org Stockholm University, Sweden [email protected] Ursula Stachl-Peier University of Graz, Austria [email protected] Liisa Tiittula University of Helsinki, Finland [email protected] DOI: 10.12807/ti.107203.2015.a03 Abstract: Speech-to-text (STT) interpreting is a type of intralingual interpreting mostly used by late deafened and hearing impaired persons who have a spoken language as their first language. In Finland, Sweden and Austria the speech-to-text transfer is performed in real-time by interpreters using a (specially adapted or standard) keyboard that is connected to a screen. As a result of different legislative frameworks governing services for the disabled, STT interpreting has developed differently in different countries and so far there has been little international cooperation. STT interpreting has also been largely ignored by Translation and Interpreting Studies. This paper examines the situation in Finland and Sweden, where STT interpreting training programmes have been available since the 1980s, and Austria, where the first training programme started in 2010, and investigates the norms, values and expectations that guide STT interpreters’ practice in the three countries. -

Interaction Techniques for Finger Sensing Input Devices
PreSense: Interaction Techniques for Finger Sensing Input Devices ££ £ £ Jun Rekimoto £ Takaaki Ishizawa Carsten Schwesig Haruo Oba £ Interaction Laboratory ££ Graduate School of Media and Governance Sony Computer Science Laboratories, Inc. Keio University 3-14-13 Higashigotanda Shonan Fujisawa Campus Shinagawa-ku, Tokyo 141-0022 Japan 5322 Endo, Fujisawa 252-8520 Japan Phone: +81 3 5448 4380, Fax +81 3 5448 4273 [email protected] rekimoto,oba @csl.sony.co.jp http://www.csl.sony.co.jp/person/rekimoto.html ABSTRACT Although graphical user interfaces started as imitations of the physical world, many interaction techniques have since been invented that are not available in the real world. This paper focuses on one of these “previewing”, and how a sen- sory enhanced input device called “PreSense Keypad” can provide a preview for users before they actually execute the commands. Preview important in the real world because it is often not possible to undo an action. This previewable fea- Figure 1: PreSense Keypad senses finger contact ture helps users to see what will occur next. It is also helpful (proximity) and position before the key press. when the command assignment of the keypad dynamically changes, such as for universal commanders. We present sev- eral interaction techniques based on this input device, includ- touch sensor, finger motions on the keypad are recognized ing menu and map browsing systems and a text input system. by integrating each keytop’s information. We also discuss finger gesture recognition for the PreSense This sensor and keytop combination makes it possible to rec- Keypad. ognize “which button is about to be pressed”, and the system KEYWORDS: input devices, previewable user interfaces, can provide appropriate information to users. -

Using Action-Level Metrics to Report the Performance of Multi-Step Keyboards
Using Action-Level Metrics to Report the Performance of Multi-Step Keyboards Gulnar Rakhmetulla* Ahmed Sabbir Arif† Steven J. Castellucci‡ Human-Computer Interaction Group Human-Computer Interaction Group Independent Researcher University of California, Merced University of California, Merced Toronto I. Scott MacKenzie§ Caitlyn E. Seim¶ Electrical Engineering and Computer Science Mechanical Engineering York University Stanford University Table 1: Conventional error rate (ER) and action-level unit error rate ABSTRACT (UnitER) for a constructive method (Morse code). This table illustrates Computer users commonly use multi-step text entry methods on the phenomenon of using Morse code to enter “quickly” with one handheld devices and as alternative input methods for accessibility. character error (“l”) in each attempt. ER is 14.28% for each attempt. These methods are also commonly used to enter text in languages One of our proposed action-level metrics, UnitER, gives a deeper with large alphabets or complex writing systems. These methods insight by accounting for the entered input sequence. It yields an error require performing multiple actions simultaneously (chorded) or rate of 7.14% for the first attempt (with two erroneous dashes), and in a specific sequence (constructive) to produce input. However, an improved error rate of 3.57% for the second attempt (with only evaluating these methods is difficult since traditional performance one erroneous dash). The action-level metric shows that learning has metrics were designed explicitly for non-ambiguous, uni-step meth- occurred with a minor improvement in error rate, but this phenomenon ods (e.g., QWERTY). They fail to capture the actual performance of is omitted in the ER metric, which is the same for both attempts. -
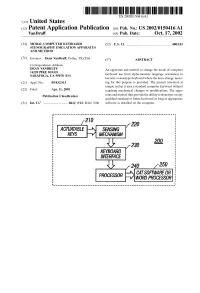
(12) Patent Application Publication (10) Pub. No.: US 2002/0150416A1 Vandruff (43) Pub
US 2002O150416A1 '(19) United States (12) Patent Application Publication (10) Pub. No.: US 2002/0150416A1 VanDruff (43) Pub. Date: Oct. 17, 2002 (54) MODAL COMPUTER KEYBOARD (52) U.S. Cl. .............................................................. 400/103 STENOGRAPHY EMULATION APPARATUS AND METHOD (76) Inventor: Dean VanDruff, Dallas, TX (US) (57) ABSTRACT Correspondence Address: DEAN VANDRUFF An apparatus and method to change the mode of computer 1422O PIKE ROAD SARATOGA, CA 95070 (US) keyboard use from alpha-numeric language orientation to become a Stenotype keyboard where the keys change mean (21) Appl. No.: 09/832,915 ing for this purpose is provided. The present invention is unique in that it uses a Standard computer keyboard without (22) Filed: Apr. 11, 2001 requiring mechanical changes or modifications. The appa Publication Classification ratus and method thus provide the ability to Stenotype on any qualified Standard or future keyboard as long as appropriate (51) Int. Cl." .................................. B41J 5/12; B41J 5/08 Software is installed on the computer. 220 SEWSNG MECHAWS 230 200 KEYBOARD INTERFACE 250 CATSOFTWARE OR WORD PROCESSOR Patent Application Publication Oct. 17, 2002 Sheet 1 of 2 US 2002/0150416A1 FIG. A 202 208 204 216 HOSTIPCI MAIN AUDIO B 206 210 214 218 219 - - - - - - - - - - - A232 LAN EXPANSION BUS GRAPHICS AUDIO/WIDEO HOSTBUSADAPER n 220 222 224 1/ !----Y---------- 200 FIG. 1B 20 220 ACTUATABLE SEWSNG MECHANISM KEYBOARD FIG 2 INTERFACE 250 PROCESSOR CATSOFTWAREPREESSR OR Patent Application Publication Oct. 17, 2002 Sheet 2 of 2 US 2002/0150416A1 UMBER BAR 1 2 3 4 6 7, 8 9 PPER BANK Swest." W 5 0 g WO WEL BANK FIG. -

Io2 Report: Lta Curriculum Design
http://www.ltaproject.eu/ Project Ref: 2018-1-DE01-KA203-004218: LTA Quality Training in real time subtitling across EU and EU languages IO2 REPORT: LTA CURRICULUM DESIGN Grant Agreement nº: 2018-1-DE01-KA203-00 Project acronym: LTA Project title: Quality Training in real-time subtitling across EU and EU languages Funding Scheme: Erasmus + Project Duration: 01/09/2018-31/08/2021 (36 months) Manager: Sprachen-und Dolmetscher-Institut München Beneficiaries: Universitat Autònoma de Barcelona Scuola Superiore per Mediatori Linguistici -Pisa ECQA Velotype SUB-TI Access European Federation of Hard of Hearing People ZDF Digital This project is supported by funding from the European Union. http://www.ltaproject.eu/ Project Ref: 2018-1-DE01-KA203-004218: LTA Quality Training in real time subtitling across EU and EU languages Dissemination level Abbreviation Level X PU Public X PP Restricted to other programme participants (including the Commission Services) RE Restricted to a group specified by the consortium (including the Commission Services) CO Confidential, only for members of the consortium History Chart Issue Date Changed page(s) Cause of change Implemented by 1.00 09-08-2019 First draft SSML 2.00 30-09-2019 several Partners’ input SSML, All 3.00 28-10-2019 several Input by Advisory SSML Board Validation No. Action Beneficiary Date 1 Prepared SSML 09-08-2019 2 Approved All partners 15-09-2019 3 Approved Advisory board members 10-10-2019 4 Released SDI 30-10-2019 Disclaimer: The information in this document is subject to change without notice. Company or product names mentioned in this document may be trademarks or registered trademarks of their respective companies. -

Senorita: a Chorded Keyboard for Sighted, Low Vision, and Blind
Senorita: A Chorded Keyboard for Sighted, Low Vision, and Blind Mobile Users Gulnar Rakhmetulla Ahmed Sabbir Arif Human-Computer Interaction Group Human-Computer Interaction Group University of California, Merced University of California, Merced Merced, CA, United States Merced, CA, United States [email protected] [email protected] Figure 1. With Senorita, the left four keys are tapped with the left thumb and the right four keys are tapped with the right thumb. Tapping a key enters the letter in the top label. Tapping two keys simultaneously (chording) enters the common letter between the keys in the bottom label. The chord keys are arranged on opposite sides. Novices can tap a key to see the chords available for that key. This figure illustrates a novice user typing the word “we”. She scans the keyboard from the left and finds ‘w’ on the ‘I’ key. She taps on it with her left thumb to see all chords for that key on the other side, from the edge: ‘C’, ‘F’, ‘W’, and ‘X’ (the same letters in the bottom label of the ‘I’ key). She taps on ‘W’ with her right thumb to form a chord to enter the letter. The next letter ‘e’ is one of the most frequent letters in English, thus has a dedicated key. She taps on it with her left thumb to complete the word. ABSTRACT INTRODUCTION Senorita is a novel two-thumb virtual chorded keyboard for Virtual Qwerty augmented with linguistic and behavioral mod- mobile devices. It arranges the letters on eight keys in a single els has become the dominant input method for mobile devices. -

Gesture Typing on Smartwatches Using a Segmented QWERTY Around the Bezel
SwipeRing: Gesture Typing on Smartwatches Using a Segmented QWERTY Around the Bezel Gulnar Rakhmetulla* Ahmed Sabbir Arif† Human-Computer Interaction Group Human-Computer Interaction Group University of California, Merced University of California, Merced Figure 1: SwipeRing arranges the standard QWERTY layout around the edge of a smartwatch in seven zones. To enter a word, the user connects the zones containing the target letters by drawing gestures on the screen, like gesture typing on a virtual QWERTY. A statistical decoder interprets the input and enters the most probable word. A suggestion bar appears to display other possible words. The user could stroke right or left on the suggestion bar to see additional suggestions. Tapping on a suggestion replaces the last entered word. One-letter and out-of-vocabulary words are entered by repeated strokes from/to the zones containing the target letters, in which case the keyboard first enters the two one-letter words in the English language (see the second last image from the left), then the other letters in the sequence in which they appear in the zones (like multi-tap). Users could also repeatedly tap (instead of stroke) on the zones to enter the letters. The keyboard highlights the zones when the finger enters them and traces all finger movements. This figure illustrates the process of entering the phrase “the world is a stage” on the SwipeRing keyboard (upper sequence) and on a smartphone keyboard (bottom sequence). We can clearly see the resemblance of the gestures. ABSTRACT player or rejecting a phone call), checking notifications on incoming Most text entry techniques for smartwatches require repeated taps to text messages and social media posts, and using them as fitness enter one word, occupy most of the screen, or use layouts that are trackers to record daily physical activity. -

Clavier DUCK
Clavier DUCK : Utilisation d'un syst`emede d´eduction de mots pour faciliter la saisie de texte sur ´ecrantactile pour les non-voyants Philippe Roussille, Mathieu Raynal, Christophe Jouffrais To cite this version: Philippe Roussille, Mathieu Raynal, Christophe Jouffrais. Clavier DUCK : Utilisation d'un syst`emede d´eduction de mots pour faciliter la saisie de texte sur ´ecrantactile pour les non- voyants. 27`eme conf´erencefrancophone sur l'Interaction Homme-Machine., Oct 2015, Toulouse, France. ACM, IHM-2015, pp.a19, 2015, <10.1145/2820619.2820638>. <hal-01218748> HAL Id: hal-01218748 https://hal.archives-ouvertes.fr/hal-01218748 Submitted on 21 Oct 2015 HAL is a multi-disciplinary open access L'archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destin´eeau d´ep^otet `ala diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publi´esou non, lished or not. The documents may come from ´emanant des ´etablissements d'enseignement et de teaching and research institutions in France or recherche fran¸caisou ´etrangers,des laboratoires abroad, or from public or private research centers. publics ou priv´es. Clavier DUCK : Utilisation d’un système de déduction de mots pour faciliter la saisie de texte sur écran tactile pour les non-voyants. Philippe Roussille Mathieu Raynal Christophe Jouffrais Université de Toulouse & Université de Toulouse & CNRS & Université de CNRS ; IRIT ; CNRS ; IRIT ; Toulouse ; IRIT ; F31 062 Toulouse, France F31 062 Toulouse, France F31 062 Toulouse, France [email protected] [email protected] [email protected] RÉSUMÉ fournissant des claviers logiciels qui s’affichent sur ces L’utilisation des écrans tactiles et en particulier les cla- surfaces tactiles. -

(12) Patent Application Publication (10) Pub. No.: US 2008/0181706 A1 Jackson (43) Pub
US 2008O181706A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2008/0181706 A1 JacksOn (43) Pub. Date: Jul. 31, 2008 (54) TACTILE FORCE SENSOR AND HYBRD Publication Classification STENOTYPE KEYBOARDS AND METHOD OF USE (51) Int. Cl. B4 5/00 (2006.01) (76) Inventor: Johnny J. Jackson, Charleston, (52) U.S. Cl. ........................................................ 400/482 WV (US) Correspondence Address: (57) ABSTRACT THOMPSON HINE L.L.P. A Stenotype keyboard utilizes pressure sensitive tactile sen Intellectual Property Group sors to register key presses and output interpreted keystrokes. P.O. BOX 8801 The pressure sensitive tactile sensors are illuminated inter DAYTON, OH 45401-8801 nally and create detectible changes to the electromagnetic radiation when compressed. The detectible changes are (21) Appl. No.: 12/020,340 picked up by sensors and analyzed to determine which keys are pressed and the appropriate keystrokes are generated. (22) Filed: Jan. 25, 2008 Keystrokes are then either output or stored in memory for later retrieval. The pressure sensitive tactile sensors facilitate Related U.S. Application Data creating keyboard configurations such as combination hybrid (60) Provisional application No. 60/886,572, filed on Jan. keyboards that have both computer style layouts and Steno 25, 2007. type keyboard layouts. U - 304 r - - - - 304 : ( C - & x. s & { & { i 3 - - 304 w & K p Q S / \ \- \- N- N- Y - N - \- \--- Y- \ se 3O2 302 Y 3O2 C --, - --f -- - - \ Patent Application Publication Jul. 31, 2008 Sheet 1 of 6 US 2008/O181706 A1 NYXXXYY-sixxxx six-swaxxxx xxxx xxxxxxx-xx-xx-xxx-xxxxx xxxx ws L six-staxas(BUAEEAL SaaSX S. -

Intersteno E-News 52
Intersteno e - news 52 www.intersteno.org E-news 52 – June 2012 1 Contents Intersteno e Contents ................................................................................. 2 From the President's desk .......................................................... 3 Internet competition 2012 .......................................................... 4 Comments of the Jury President .................................................... 4 A winning experience by Carlo Paris - mother tongue champion of Internet contest 2012 ............................................................................ 9 In memoriam prof. Marcello Melani ............................................. 10 Programme of the meetings of the Council and Professional reporters' section in Prague - 29th September - 2nd October ......................... 12 A new future for Mr. Mark Golden (USA) ...................................... 13 NCRA Board selects Jim Cudahy as next executive director & CEO ..... 14 London 26 September, 1887 - The Birth of Intersteno ..................... 15 From Giuseppe Ravizza to Steve Jobs .......................................... 17 Intersteno Usa group on Facebook .............................................. 18 Competitions ......................................................................... 19 Swiss shorthand competition in Gossau .......................................... 19 Lipsia Open 2012 ..................................................................... 19 13-14 April 2012 - International competitions in The Hague and Dutch -

Designing a Better Touch Keyboard
Designing a Better Touch Keyboard JOEL BESADA ([email protected]) DD143X Degree Project in Computer Science, First Level KTH Royal Institute of Technology, School of Computer Science and Communication - Supervisor: Anders Askenfelt Examiner: Mårten Björkman iii Abstract The growing market of smartphone and tablet devices has made touch screens a big part of how people interact with technology today. The standard virtual keyboard used on these devices is based on the computer keyboard – a design that may not be very well suited for touch screens. This study sought to answer whether there are alterna- tive ways to design virtual touch keyboards. An alternative design may require training to use, but the user should be able to use it viably after a reasonable amount of prac- tice. Optimally, the user should also have the potential to reach a higher level of efficiency than what is possible on the standard touch keyboard design. Analysis was done by researching current and previous attempts at alternative keyboard designs, and by imple- menting an own prototype based on analysis made on the researched designs. The thesis concludes that there is an interest in solving issues encountered in this area, and that there is good potential in building viable virtual keyboards using alternative design paradigms. iv Referat Utformning av ett bättre pektangentbord Den växande marknaden för smarttelefoner och surfplattor har gjort pekskärmen till en stor del av hur folket interage- rar med dagens teknologi. Det virtuella standardtangent- bordet som används på dessa enheter är baserad på dator- tangentbordet – en design som möjligen inte är särskilt bra anpassad för pekskärmar.