Annotating Gene Sets by Mining Large Literature Collections with Protein Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Targeting Hedgehog Signalling Through the Ubiquitylation Process: the Multiple Roles of the HECT-E3 Ligase Itch
cells Review Targeting Hedgehog Signalling through the Ubiquitylation Process: The Multiple Roles of the HECT-E3 Ligase Itch Paola Infante 1,†, Ludovica Lospinoso Severini 2,† , Flavia Bernardi 2, Francesca Bufalieri 2 and Lucia Di Marcotullio 2,3,* 1 Center for Life NanoScience@Sapienza, Istituto Italiano di Tecnologia, 00161 Rome, Italy; [email protected] 2 Department of Molecular Medicine, University of Rome La Sapienza, 00161 Rome, Italy; [email protected] (L.L.S.); fl[email protected] (F.B.); [email protected] (F.B.) 3 Istituto Pasteur-Fondazione Cenci Bolognetti, University of Rome La Sapienza, 00161 Rome, Italy * Correspondence: [email protected]; Tel.: +39-06-49255657 † These authors contributed equally to this work. Received: 28 December 2018; Accepted: 26 January 2019; Published: 29 January 2019 Abstract: Hedgehog signalling (Hh) is a developmental conserved pathway strongly involved in cancers when deregulated. This important pathway is orchestrated by numerous regulators, transduces through distinct routes and is finely tuned at multiple levels. In this regard, ubiquitylation processes stand as essential for controlling Hh pathway output. Although this post-translational modification governs proteins turnover, it is also implicated in non-proteolytic events, thereby regulating the most important cellular functions. The HECT E3 ligase Itch, well known to control immune response, is emerging to have a pivotal role in tumorigenesis. By illustrating Itch specificities on Hh signalling key components, here we review the role of this HECT E3 ubiquitin ligase in suppressing Hh-dependent tumours and explore its potential as promising target for innovative therapeutic approaches. Keywords: Hedgehog; cancer; ubiquitylation; Itch; Numb; β-arrestin2; GLI1; SuFu; Patched1 1. -
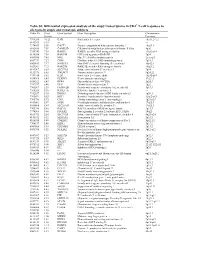
Table S1| Differential Expression Analysis of the Atopy Transcriptome
Table S1| Differential expression analysis of the atopy transcriptome in CD4+ T-cell responses to allergens in atopic and nonatopic subjects Probe ID S.test Gene Symbol Gene Description Chromosome Statistic Location 7994280 10.32 IL4R Interleukin 4 receptor 16p11.2-12.1 8143383 8.95 --- --- --- 7974689 8.50 DACT1 Dapper, antagonist of beta-catenin, homolog 1 14q23.1 8102415 7.59 CAMK2D Calcium/calmodulin-dependent protein kinase II delta 4q26 7950743 7.58 RAB30 RAB30, member RAS oncogene family 11q12-q14 8136580 7.54 RAB19B GTP-binding protein RAB19B 7q34 8043504 7.45 MAL Mal, T-cell differentiation protein 2cen-q13 8087739 7.27 CISH Cytokine inducible SH2-containing protein 3p21.3 8000413 7.17 NSMCE1 Non-SMC element 1 homolog (S. cerevisiae) 16p12.1 8021301 7.15 RAB27B RAB27B, member RAS oncogene family 18q21.2 8143367 6.83 SLC37A3 Solute carrier family 37 member 3 7q34 8152976 6.65 TMEM71 Transmembrane protein 71 8q24.22 7931914 6.56 IL2R Interleukin 2 receptor, alpha 10p15-p14 8014768 6.43 PLXDC1 Plexin domain containing 1 17q21.1 8056222 6.43 DPP4 Dipeptidyl-peptidase 4 (CD26) 2q24.3 7917697 6.40 GFI1 Growth factor independent 1 1p22 7903507 6.39 FAM102B Family with sequence similarity 102, member B 1p13.3 7968236 5.96 RASL11A RAS-like, family 11, member A --- 7912537 5.95 DHRS3 Dehydrogenase/reductase (SDR family) member 3 1p36.1 7963491 5.83 KRT1 Keratin 1 (epidermolytic hyperkeratosis) 12q12-q13 7903786 5.72 CSF1 Colony stimulating factor 1 (macrophage) 1p21-p13 8019061 5.67 SGSH N-sulfoglucosamine sulfohydrolase (sulfamidase) 17q25.3 -
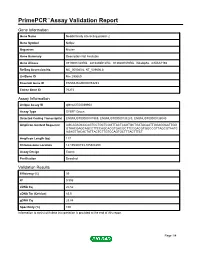
Primepcr™Assay Validation Report
PrimePCR™Assay Validation Report Gene Information Gene Name Nedd4 family interacting protein 2 Gene Symbol Ndfip2 Organism Mouse Gene Summary Description Not Available Gene Aliases 0710001O20Rik, 2810436B12Rik, 9130207N19Rik, N4wbp5a, mKIAA1165 RefSeq Accession No. NC_000080.6, NT_039606.8 UniGene ID Mm.290669 Ensembl Gene ID ENSMUSG00000053253 Entrez Gene ID 76273 Assay Information Unique Assay ID qMmuCED0039954 Assay Type SYBR® Green Detected Coding Transcript(s) ENSMUST00000181969, ENSMUST00000138283, ENSMUST00000136040 Amplicon Context Sequence AGCAGAGCCCAGTCCTGCTCGGTTACTCAGTGCTGATACAATTGGAGGAATTGG GTAACGAGCAGCCTTCCAGCACGTGACGCTTCCGACGTGGCCGTTAGCGTAATC AGAGTTACACTATTACTCTTGTCCAGTGCTTTACTTTCT Amplicon Length (bp) 117 Chromosome Location 14:105308153-105308299 Assay Design Exonic Purification Desalted Validation Results Efficiency (%) 99 R2 0.996 cDNA Cq 20.52 cDNA Tm (Celsius) 83.5 gDNA Cq 23.84 Specificity (%) 100 Information to assist with data interpretation is provided at the end of this report. Page 1/4 PrimePCR™Assay Validation Report Ndfip2, Mouse Amplification Plot Amplification of cDNA generated from 25 ng of universal reference RNA Melt Peak Melt curve analysis of above amplification Standard Curve Standard curve generated using 20 million copies of template diluted 10-fold to 20 copies Page 2/4 PrimePCR™Assay Validation Report Products used to generate validation data Real-Time PCR Instrument CFX384 Real-Time PCR Detection System Reverse Transcription Reagent iScript™ Advanced cDNA Synthesis Kit for RT-qPCR Real-Time PCR Supermix SsoAdvanced™ SYBR® Green Supermix Experimental Sample qPCR Mouse Reference Total RNA Data Interpretation Unique Assay ID This is a unique identifier that can be used to identify the assay in the literature and online. Detected Coding Transcript(s) This is a list of the Ensembl transcript ID(s) that this assay will detect. -

Downloaded Per Proteome Cohort Via the Web- Site Links of Table 1, Also Providing Information on the Deposited Spectral Datasets
www.nature.com/scientificreports OPEN Assessment of a complete and classifed platelet proteome from genome‑wide transcripts of human platelets and megakaryocytes covering platelet functions Jingnan Huang1,2*, Frauke Swieringa1,2,9, Fiorella A. Solari2,9, Isabella Provenzale1, Luigi Grassi3, Ilaria De Simone1, Constance C. F. M. J. Baaten1,4, Rachel Cavill5, Albert Sickmann2,6,7,9, Mattia Frontini3,8,9 & Johan W. M. Heemskerk1,9* Novel platelet and megakaryocyte transcriptome analysis allows prediction of the full or theoretical proteome of a representative human platelet. Here, we integrated the established platelet proteomes from six cohorts of healthy subjects, encompassing 5.2 k proteins, with two novel genome‑wide transcriptomes (57.8 k mRNAs). For 14.8 k protein‑coding transcripts, we assigned the proteins to 21 UniProt‑based classes, based on their preferential intracellular localization and presumed function. This classifed transcriptome‑proteome profle of platelets revealed: (i) Absence of 37.2 k genome‑ wide transcripts. (ii) High quantitative similarity of platelet and megakaryocyte transcriptomes (R = 0.75) for 14.8 k protein‑coding genes, but not for 3.8 k RNA genes or 1.9 k pseudogenes (R = 0.43–0.54), suggesting redistribution of mRNAs upon platelet shedding from megakaryocytes. (iii) Copy numbers of 3.5 k proteins that were restricted in size by the corresponding transcript levels (iv) Near complete coverage of identifed proteins in the relevant transcriptome (log2fpkm > 0.20) except for plasma‑derived secretory proteins, pointing to adhesion and uptake of such proteins. (v) Underrepresentation in the identifed proteome of nuclear‑related, membrane and signaling proteins, as well proteins with low‑level transcripts. -

A SARS-Cov-2 Protein Interaction Map Reveals Targets for Drug Repurposing
Article A SARS-CoV-2 protein interaction map reveals targets for drug repurposing https://doi.org/10.1038/s41586-020-2286-9 A list of authors and affiliations appears at the end of the paper Received: 23 March 2020 Accepted: 22 April 2020 A newly described coronavirus named severe acute respiratory syndrome Published online: 30 April 2020 coronavirus 2 (SARS-CoV-2), which is the causative agent of coronavirus disease 2019 (COVID-19), has infected over 2.3 million people, led to the death of more than Check for updates 160,000 individuals and caused worldwide social and economic disruption1,2. There are no antiviral drugs with proven clinical efcacy for the treatment of COVID-19, nor are there any vaccines that prevent infection with SARS-CoV-2, and eforts to develop drugs and vaccines are hampered by the limited knowledge of the molecular details of how SARS-CoV-2 infects cells. Here we cloned, tagged and expressed 26 of the 29 SARS-CoV-2 proteins in human cells and identifed the human proteins that physically associated with each of the SARS-CoV-2 proteins using afnity-purifcation mass spectrometry, identifying 332 high-confdence protein–protein interactions between SARS-CoV-2 and human proteins. Among these, we identify 66 druggable human proteins or host factors targeted by 69 compounds (of which, 29 drugs are approved by the US Food and Drug Administration, 12 are in clinical trials and 28 are preclinical compounds). We screened a subset of these in multiple viral assays and found two sets of pharmacological agents that displayed antiviral activity: inhibitors of mRNA translation and predicted regulators of the sigma-1 and sigma-2 receptors. -

4766.Full.Pdf
Identification of Novel Th2-Associated Genes in T Memory Responses to Allergens Anthony Bosco, Kathy L. McKenna, Catherine J. Devitt, Martin J. Firth, Peter D. Sly and Patrick G. Holt This information is current as of October 1, 2021. J Immunol 2006; 176:4766-4777; ; doi: 10.4049/jimmunol.176.8.4766 http://www.jimmunol.org/content/176/8/4766 Downloaded from References This article cites 119 articles, 43 of which you can access for free at: http://www.jimmunol.org/content/176/8/4766.full#ref-list-1 Why The JI? Submit online. http://www.jimmunol.org/ • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication *average by guest on October 1, 2021 Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2006 by The American Association of Immunologists All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Identification of Novel Th2-Associated Genes in T Memory Responses to Allergens1 Anthony Bosco, Kathy L. McKenna, Catherine J. Devitt, Martin J. Firth, Peter D. Sly, and Patrick G. Holt2 Atopic diseases are associated with hyperexpression of Th2 cytokines by allergen-specific T memory cells. -

NDFIP1 Antibody (Center) Affinity Purified Rabbit Polyclonal Antibody (Pab) Catalog # Ap13449c
10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 NDFIP1 Antibody (Center) Affinity Purified Rabbit Polyclonal Antibody (Pab) Catalog # AP13449c Specification NDFIP1 Antibody (Center) - Product Information Application WB,E Primary Accession Q9BT67 Other Accession Q5U2S1, Q8R0W6, NP_085048.1 Reactivity Human Predicted Mouse, Rat Host Rabbit Clonality Polyclonal Isotype Rabbit Ig Calculated MW 24899 Antigen Region 77-106 NDFIP1 Antibody (Center) - Additional Information Gene ID 80762 Anti-NDFIP1 Antibody (Center) at 1:1000 dilution + PC-3 whole cell lysate Other Names Lysates/proteins at 20 µg per lane. NEDD4 family-interacting protein 1, Breast Secondary Goat Anti-Rabbit IgG, (H+L), cancer-associated protein SGA-1M, NEDD4 Peroxidase conjugated at 1/10000 dilution. WW domain-binding protein 5, Putative Predicted band size : 25 kDa MAPK-activating protein PM13, Putative NF-kappa-B-activating protein 164, Putative Blocking/Dilution buffer: 5% NFDM/TBST. NFKB and MAPK-activating protein, NDFIP1, N4WBP5 NDFIP1 Antibody (Center) - Background Target/Specificity This NDFIP1 antibody is generated from The protein encoded by this gene belongs to a rabbits immunized with a KLH conjugated small group of evolutionarily conserved synthetic peptide between 77-106 amino proteins with three transmembrane domains. It acids from the Central region of human is a potential target for ubiquitination by the NDFIP1. Nedd4 family of proteins. This protein is thought to be part of a family of integral Golgi Dilution membrane proteins. WB~~1:1000 NDFIP1 Antibody (Center) - References Format Purified polyclonal antibody supplied in PBS Mund, T., et al. Proc. Natl. Acad. Sci. U.S.A. -

Gene-Expression and in Vitro Function of Mesenchymal Stromal Cells Are Affected in Juvenile Myelomonocytic Leukemia
Myeloproliferative Disorders SUPPLEMENTARY APPENDIX Gene-expression and in vitro function of mesenchymal stromal cells are affected in juvenile myelomonocytic leukemia Friso G.J. Calkoen, 1 Carly Vervat, 1 Else Eising, 2 Lisanne S. Vijfhuizen, 2 Peter-Bram A.C. ‘t Hoen, 2 Marry M. van den Heuvel-Eibrink, 3,4 R. Maarten Egeler, 1,5 Maarten J.D. van Tol, 1 and Lynne M. Ball 1 1Department of Pediatrics, Immunology, Hematology/Oncology and Hematopoietic Stem Cell Transplantation, Leiden University Med - ical Center, the Netherlands; 2Department of Human Genetics, Leiden University Medical Center, Leiden, the Netherlands; 3Dutch Childhood Oncology Group (DCOG), The Hague, the Netherlands; 4Princess Maxima Center for Pediatric Oncology, Utrecht, the Nether - lands; and 5Department of Hematology/Oncology and Hematopoietic Stem Cell Transplantation, Hospital for Sick Children, University of Toronto, ON, Canada ©2015 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol.2015.126938 Manuscript received on March 5, 2015. Manuscript accepted on August 17, 2015. Correspondence: [email protected] Supplementary data: Methods for online publication Patients Children referred to our center for HSCT were included in this study according to a protocol approved by the institutional review board (P08.001). Bone-marrow of 9 children with JMML was collected prior to treatment initiation. In addition, bone-marrow after HSCT was collected from 5 of these 9 children. The patients were classified following the criteria described by Loh et al.(1) Bone-marrow samples were sent to the JMML-reference center in Freiburg, Germany for genetic analysis. Bone-marrow samples of healthy pediatric hematopoietic stem cell donors (n=10) were used as control group (HC). -

Molecular Targeting and Enhancing Anticancer Efficacy of Oncolytic HSV-1 to Midkine Expressing Tumors
University of Cincinnati Date: 12/20/2010 I, Arturo R Maldonado , hereby submit this original work as part of the requirements for the degree of Doctor of Philosophy in Developmental Biology. It is entitled: Molecular Targeting and Enhancing Anticancer Efficacy of Oncolytic HSV-1 to Midkine Expressing Tumors Student's name: Arturo R Maldonado This work and its defense approved by: Committee chair: Jeffrey Whitsett Committee member: Timothy Crombleholme, MD Committee member: Dan Wiginton, PhD Committee member: Rhonda Cardin, PhD Committee member: Tim Cripe 1297 Last Printed:1/11/2011 Document Of Defense Form Molecular Targeting and Enhancing Anticancer Efficacy of Oncolytic HSV-1 to Midkine Expressing Tumors A dissertation submitted to the Graduate School of the University of Cincinnati College of Medicine in partial fulfillment of the requirements for the degree of DOCTORATE OF PHILOSOPHY (PH.D.) in the Division of Molecular & Developmental Biology 2010 By Arturo Rafael Maldonado B.A., University of Miami, Coral Gables, Florida June 1993 M.D., New Jersey Medical School, Newark, New Jersey June 1999 Committee Chair: Jeffrey A. Whitsett, M.D. Advisor: Timothy M. Crombleholme, M.D. Timothy P. Cripe, M.D. Ph.D. Dan Wiginton, Ph.D. Rhonda D. Cardin, Ph.D. ABSTRACT Since 1999, cancer has surpassed heart disease as the number one cause of death in the US for people under the age of 85. Malignant Peripheral Nerve Sheath Tumor (MPNST), a common malignancy in patients with Neurofibromatosis, and colorectal cancer are midkine- producing tumors with high mortality rates. In vitro and preclinical xenograft models of MPNST were utilized in this dissertation to study the role of midkine (MDK), a tumor-specific gene over- expressed in these tumors and to test the efficacy of a MDK-transcriptionally targeted oncolytic HSV-1 (oHSV). -

Comparing the Effects of Vitamin E Tocotrienol-Rich Fraction Supplementation and Α-Tocopherol Supplementation on Gene Expression in Healthy Older Adults
ORIGINAL ARTICLE Comparing the effects of vitamin E tocotrienol-rich fraction supplementation and α-tocopherol supplementation on gene expression in healthy older adults Siti Madiani Abdul Ghani,I Jo Aan Goon,I,* Nor Helwa Ezzah Nor Azman,I Siti Nor Asyikin Zakaria,I Zalina Hamid,II Wan Zurinah Wan NgahI I Department of Biochemistry, Faculty of Medicine, Universiti Kebangsaan Malaysia, Kuala Lumpur, Malaysia. II Sime Darby Foods & Beverages Marketing Sdn Bhd, Petaling Jaya, Selangor, Malaysia. Abdul Ghani SM, Goon JA, Nor Azman NHE, Asyikin Zakaria SN, Hamid Z, Wan Ngah WZ. Comparing the effects of Vitamin E Tocotrienol-Rich Fraction supplementation and α-Tocopherol supplementation on gene expression in healthy older adults. Clinics. 2019;74:e688 *Corresponding author. E-mail: [email protected] OBJECTIVES: This study aims to compare the differential gene expression resulting from tocotrienol-rich fraction and α-tocopherol supplementation in healthy older adults. METHODS: A total of 71 eligible subjects aged 50 to 55 years from Gombak and Kuala Lumpur, Malaysia, were divided into three groups and supplemented with placebo (n=23), α-tocopherol (n=24) or tocotrienol-rich fraction (n=24). Blood samples were collected at baseline and at 3 and 6 months of supplementation for microarray analysis. RESULTS: The number of genes altered by α-tocopherol was higher after 6 months (1,410) than after 3 months (273) of supplementation. α-Tocopherol altered the expression of more genes in males (952) than in females (731). Similarly, tocotrienol-rich fraction modulated the expression of more genes after 6 months (1,084) than after 3 months (596) and affected more genes in males (899) than in females (781). -
Ndfip Proteins Target Robo Receptors for Degradation and Allow
Article Ndfip Proteins Target Robo Receptors for Degradation and Allow Commissural Axons to Cross the Midline in the Developing Spinal Cord Graphical Abstract Authors Madhavi Gorla, Celine Santiago, Karina Chaudhari, Awo Akosua Kesewa Layman, Paula M. Oliver, Greg J. Bashaw Correspondence [email protected] In Brief In order to cross the midline in the developing spinal cord, commissural axons must prevent premature responses to the midline repellant Slit. Here Gorla et al. define a key role for the Ndfip adaptor proteins in preventing the surface expression of the Robo1 receptor prior to midline crossing. Highlights d Ndfip proteins bind to and recruit the Robo1 receptor to late endosomes d Ndfip proteins recruit Nedd4-family E3 ubiquitin ligases to trigger Robo degradation d Loss of Ndfip proteins results in a significant reduction of midline crossing d Robo1 expression on pre-crossing commissural axons is increased in Ndfip mutants Gorla et al., 2019, Cell Reports 26, 3298–3312 March 19, 2019 ª 2019 The Authors. https://doi.org/10.1016/j.celrep.2019.02.080 Cell Reports Article Ndfip Proteins Target Robo Receptors for Degradation and Allow Commissural Axons to Cross the Midline in the Developing Spinal Cord Madhavi Gorla,1 Celine Santiago,1 Karina Chaudhari,1 Awo Akosua Kesewa Layman,2,3 Paula M. Oliver,2,3 and Greg J. Bashaw1,4,* 1Department of Neuroscience, Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA 19104, USA 2The Children’s Hospital of Philadelphia, Division of Protective Immunity, 3615 Civic Center Boulevard, Philadelphia, PA 19104, USA 3Department of Pathology and Laboratory Medicine, Perelman School of Medicine, University of Pennsylvania, 3400 Civic Center Boulevard, Building 421, Philadelphia, PA 19104, USA 4Lead Contact *Correspondence: [email protected] https://doi.org/10.1016/j.celrep.2019.02.080 SUMMARY (Charron et al., 2003; Ishii et al., 1992; Mitchell et al., 1996; Ser- afini et al., 1996). -

Differentiation Involved in Early Th1 and Th2 Cell Genome-Wide
Genome-Wide Identification of Novel Genes Involved in Early Th1 and Th2 Cell Differentiation This information is current as Riikka J. Lund, Maritta Löytömäki, Tiina Naumanen, Craig of September 28, 2021. Dixon, Zhi Chen, Helena Ahlfors, Soile Tuomela, Johanna Tahvanainen, Joonas Scheinin, Tiina Henttinen, Omid Rasool and Riitta Lahesmaa J Immunol 2007; 178:3648-3660; ; doi: 10.4049/jimmunol.178.6.3648 Downloaded from http://www.jimmunol.org/content/178/6/3648 References This article cites 43 articles, 22 of which you can access for free at: http://www.jimmunol.org/content/178/6/3648.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists by guest on September 28, 2021 • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2007 by The American Association of Immunologists All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Genome-Wide Identification of Novel Genes Involved in Early Th1 and Th2 Cell Differentiation1 Riikka J. Lund,2* Maritta Lo¨yto¨ma¨ki,2*† Tiina Naumanen,* Craig Dixon,* Zhi Chen,* Helena Ahlfors,*‡ Soile Tuomela,*† Johanna Tahvanainen,*§ Joonas Scheinin,* Tiina Henttinen,* Omid Rasool,* and Riitta Lahesmaa3* Th cell subtypes, Th1 and Th2, are involved in the pathogenesis or progression of many immune-mediated diseases, such as type 1 diabetes and asthma, respectively.