Punctuation the Comma
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ST.36 Page: 3.36.1
HANDBOOK ON INDUSTRIAL PROPERTY INFORMATION AND DOCUMENTATION Ref.: Standards – ST.36 page: 3.36.1 STANDARD ST.36 Version 1.2 RECOMMENDATION FOR THE PROCESSING OF PATENT INFORMATION USING XML (EXTENSIBLE MARKUP LANGUAGE) Revision adopted by ST.36 Task Force of the Standards and Documentation Working Group (SDWG) on November 23, 2007 TABLE OF CONTENTS INTRODUCTION ............................................................................................................................................................ 2 DEFINITIONS ................................................................................................................................................................. 3 SCOPE OF THE STANDARD ........................................................................................................................................ 3 REQUIREMENTS OF THE STANDARD........................................................................................................................ 4 General ......................................................................................................................................................................... 4 Characters .................................................................................................................................................................... 5 Naming international common elements....................................................................................................................... 6 Naming office-specific elements -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Orthographies in Grammar Books
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 30 July 2018 doi:10.20944/preprints201807.0565.v1 Tomislav Stojanov, [email protected], [email protected] Institute of Croatian Language and Linguistic Republike Austrije 16, 10.000 Zagreb, Croatia Orthographies in Grammar Books – Antiquity and Humanism Summary This paper researches the as yet unstudied topic of orthographic content in antique, medieval, and Renaissance grammar books in European languages, as part of a wider research of the origin of orthographic standards in European languages. As a central place for teachings about language, grammar books contained orthographic instructions from the very beginning, and such practice continued also in later periods. Understanding the function, content, and orthographic forms in the past provides for a better description of the nature of the orthographic standard in the present. The evolution of grammatographic practice clearly shows the continuity of development of orthographic content from a constituent of grammar studies through the littera unit gradually to an independent unit, then into annexed orthographic sections, and later into separate orthographic manuals. 5 antique, 22 Latin, and 17 vernacular grammars were analyzed, describing 19 European languages. The research methodology is based on distinguishing orthographic content in the narrower sense (grapheme to meaning) from the broader sense (grapheme to phoneme). In this way, the function of orthographic description was established separately from the study of spelling. As for the traditional description of orthographic content in the broader sense in old grammar books, it is shown that orthographic content can also be studied within the grammatographic framework of a specific period, similar to the description of morphology or syntax. -

1St Rule: FANBOYS and Compound Sentences FANBOYS Is a Mnemonic Device, Which Stands for the Coordinating Conjunctions: For, And, Nor, But, Or, Yet, and So
1st Rule: FANBOYS and Compound Sentences FANBOYS is a mnemonic device, which stands for the coordinating conjunctions: For, And, Nor, But, Or, Yet, and So. These words, when used to connect two independent clauses (two complete thoughts), must be preceded by a comma. A sentence is a complete thought, consisting of a Subject and a Verb. Conjunctions should not be confused with conjunctive adverbs, such as However, Therefore, and Moreover or with conjunctions, such as Because. 2nd Rule: Introductory Bits When using an introductory word, phrase, or clause to begin a sentence, it is important to place a comma between the introduction and the main sentence. The introduction is not a complete thought on its own; it simply introduces the main clause. This lets the reader know that the “meat” of the sentence is what follows the comma. You should be able to remove the part which comes before the comma and still have a complete thought. Examples: Generally, John is opposed to overt acts of affection. However, Lucy inspires him to be kind. If the hamster is launched fifty feet, there is too much pressure in the cannon. Although the previous sentence has little to do with John and Lucy, it is a good example of how to use commas with introductory clauses. 3rd Rule: Separating Items in a Series Commas belong between each item in a list. However, in a series of three items, the comma between the second and third item and the conjunction (generally and or or) is optional, whereas in a list of four items, the comma is necessary. -

International Language Environments Guide
International Language Environments Guide Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 806–6642–10 May, 2002 Copyright 2002 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, Java, XView, ToolTalk, Solstice AdminTools, SunVideo and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. SunOS, Solaris, X11, SPARC, UNIX, PostScript, OpenWindows, AnswerBook, SunExpress, SPARCprinter, JumpStart, Xlib The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. -

List of Approved Special Characters
List of Approved Special Characters The following list represents the Graduate Division's approved character list for display of dissertation titles in the Hooding Booklet. Please note these characters will not display when your dissertation is published on ProQuest's site. To insert a special character, simply hold the ALT key on your keyboard and enter in the corresponding code. This is only for entering in a special character for your title or your name. The abstract section has different requirements. See abstract for more details. Special Character Alt+ Description 0032 Space ! 0033 Exclamation mark '" 0034 Double quotes (or speech marks) # 0035 Number $ 0036 Dollar % 0037 Procenttecken & 0038 Ampersand '' 0039 Single quote ( 0040 Open parenthesis (or open bracket) ) 0041 Close parenthesis (or close bracket) * 0042 Asterisk + 0043 Plus , 0044 Comma ‐ 0045 Hyphen . 0046 Period, dot or full stop / 0047 Slash or divide 0 0048 Zero 1 0049 One 2 0050 Two 3 0051 Three 4 0052 Four 5 0053 Five 6 0054 Six 7 0055 Seven 8 0056 Eight 9 0057 Nine : 0058 Colon ; 0059 Semicolon < 0060 Less than (or open angled bracket) = 0061 Equals > 0062 Greater than (or close angled bracket) ? 0063 Question mark @ 0064 At symbol A 0065 Uppercase A B 0066 Uppercase B C 0067 Uppercase C D 0068 Uppercase D E 0069 Uppercase E List of Approved Special Characters F 0070 Uppercase F G 0071 Uppercase G H 0072 Uppercase H I 0073 Uppercase I J 0074 Uppercase J K 0075 Uppercase K L 0076 Uppercase L M 0077 Uppercase M N 0078 Uppercase N O 0079 Uppercase O P 0080 Uppercase -

Hong Kong Supplementary Character Set – 2016 (Draft)
中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Hong Kong Supplementary Character Set – 2016 (Draft) Office of the Government Chief Information Officer & Official Languages Division, Civil Service Bureau The Government of the Hong Kong Special Administrative Region April 2017 1/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Table of Contents Preface Section 1 Overview……………….……………………………………………. 1 - 1 Section 2 Coding Scheme of the HKSCS–2016….……………………………. 2 - 1 Section 3 HKSCS–2016 under the Architecture of the ISO/IEC 10646………. 3 - 1 Table 1: Code Table of the HKSCS–2016……………………………………….. i - 1 Table 2: Newly Included Characters in the HKSCS–2016...………………….…. ii - 1 Table 3: Compatibility Characters in the HKSCS–2016…......………………..…. iii - 1 2/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Preface After the first release of the Hong Kong Supplementary Character Set (HKSCS) in 1999, there have been three updated versions. The HKSCS-2001, HKSCS-2004 and HKSCS-2008 were published with 116, 123 and 68 new characters added respectively. A total of 5 009 characters were included in the HKSCS-2008. These publications formed the foundation for promoting the adoption of the ISO/IEC 10646 international coding standard, and were widely supported and adopted by the IT sector and members of the public. The ISO/IEC 10646 international coding standard is developed by the International Organization for Standardization (ISO) to provide a common technical basis for the storage and exchange of electronic information. -

Top Ten Tips for Effective Punctuation in Legal Writing
TIPS FOR EFFECTIVE PUNCTUATION IN LEGAL WRITING* © 2005 The Writing Center at GULC. All Rights Reserved. Punctuation can be either your friend or your enemy. A typical reader will seldom notice good punctuation (though some readers do appreciate truly excellent punctuation). However, problematic punctuation will stand out to your reader and ultimately damage your credibility as a writer. The tips below are intended to help you reap the benefits of sophisticated punctuation while avoiding common pitfalls. But remember, if a sentence presents a particularly thorny punctuation problem, you may want to consider rephrasing for greater clarity. This handout addresses the following topics: THE COMMA (,)........................................................................................................................... 2 PUNCTUATING QUOTATIONS ................................................................................................. 4 THE ELLIPSIS (. .) ..................................................................................................................... 4 THE APOSTROPHE (’) ................................................................................................................ 7 THE HYPHEN (-).......................................................................................................................... 8 THE DASH (—) .......................................................................................................................... 10 THE SEMICOLON (;) ................................................................................................................ -
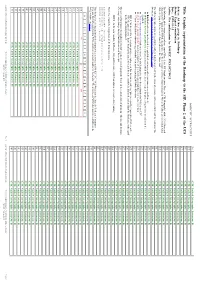
Netscape: Roadmap to Plane 2 (SIP) of ISO/IEC 10646 and Unicode
14 (CJK Unified Ideographs Extension B) ISO/IEC JTC1/SC2/WG2 N2115 15 (CJK Unified Ideographs Extension B) Title: Graphic representation of the Roadmap to the SIP, Plane 2 of the UCS 16 (CJK Unified Ideographs Extension B) 17 (CJK Unified Ideographs Extension B) Source: Ad hoc group on Roadmap 18 (CJK Unified Ideographs Extension B) Status: Expert contribution 19 (CJK Unified Ideographs Extension B) Date: 1999-09-15 Action: For confirmation by ISO/IEC JTC1/SC2/WG2 1A (CJK Unified Ideographs Extension B) 1B (CJK Unified Ideographs Extension B) The following tables comprise a real-size map of Plane 2, the SIP (Supplementary Plane for CJK Ideographs) of the UCS (Universal 1C (CJK Unified Ideographs Extension B) Character Set). To print the HTML document it may be necessary to set the print percentage to 90% as the tables are wider than A4 or US Letter paper. The tables are formatted to use the Times font. 1D (CJK Unified Ideographs Extension B) 1E (CJK Unified Ideographs Extension B) The following conventions are used in the table to help the user identify the status of (colours can be seen in the online version of this document, http://www.dkuug.dk/jtc1/sc2/wg2/docs/n2115.pdf): 1F (CJK Unified Ideographs Extension B) 20 (CJK Unified Ideographs Extension B) Bold text indicates an allocated (i.e. published) character collection (none as yet in Plane 2). (Bold text between parentheses) indicates scripts which have been accepted for processing toward inclusion in the 21 (CJK Unified Ideographs Extension B) standard. 22 (CJK Unified Ideographs Extension B) (Text between parentheses) indicates scripts for which proposals have been submitted to WG2 or the UTC. -

IRG N2153 IRG Principles and Procedures 2016-10-20 Version 8Confirmed Page 1 of 40 2.3.3
INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION ISO/IEC JTC 1/SC 2/WG 2/IRG Universal Coded Character Set (UCS) ISO/IEC JTC 1/SC 2/WG 2/IRGN2153 SC2N5405 (Revision of IRG N1503/N1772/N1823/N1920/N1942/N1975/N2016/N2092) 2016-10-20 Title: IRG Principles and Procedures(IRG PnP) Version 9 Source: IRG Rapporteur Action: For review by the IRG and WG2 Distribution: IRG Member Bodies and Ideographic Experts Editor in chief: Lu Qin, IRG Rapporteur References: IRG Meeting No. 45 Recommendations(IRGN2150), IRG Special Meeting No. 44 discussions and recommendation No. 44.6(IRGN2080), IRGN2016, and IRGN 1975 and IRG Meeting No. 42 discussions IRGN 1952 and feedback from HKSARG, Japan, ROK and TCA, IRG 1920 Draft(2012-11-15), Draft 2(2013-05-04) and Draft 3(2013-05-22); feedback from Japan(2013-04-23) and ROK(2013-05-16 and 2013-05-21); and IRG Meeting No. 40 discussions IRG 1823 Draft 3 and feedback from HKSAR, Korea and IRG Meeting No. 39 discussions IRGN1823 Draft2 feedback from HKSAR and Japan IRG N1823Draft_gimgs2_Feedback IRG N1781 and N1782 Feedback from KIM Kyongsok IRGN1772 (P&P Version 5) IRG N1646 (P&P Version 4 draft) IRG N1602 (P&P Draft 4) and IRG N1633 (P&P Editorial Report) IRG N1601 (P&P Draft 3 Feedback from HKSAR) IRG N1590 and IRGN 1601(P&P V2 and V3 draft and all feedback) IRG N1562 (P&P V3 Draft 1 and Feedback from HKSAR) IRG N1561 (P&P V2 and all feedback) IRG N1559 (P&P V2 Draft and all feedback) IRG N1516 (P&P V1 Feedback from HKSAR) IRG N1489 (P&P V1 Feedback from Taichi Kawabata) IRG N1487 (P&P V1 Feedback from HKSAR) IRG N1465, IRG N1498 and IRG N1503 (P&P V1 drafts) Table of Contents 1. -

Character and String Representation
Character and String Representation CS520 Department of Computer Science University of New Hampshire CDC 6600 • 6-bit character encodings • i.e. only 64 characters • Designers were not too concerned about text processing! The table is from Assembly Language Programming for the Control Data 6000 series and the Cyber 70 series by Grishman. C Strings • Usually implemented as a series of ASCII characters terminated by a null byte (0x00). • ″abc″ in memory is: n 0x61 n+1 0x62 n+2 0x63 n+3 0x00 Unicode • The space of values is divided into 17 planes. • Plane 0 is the Basic Multilingual Plane (BMP). – Supports nearly all modern languages. – Encodings are 0x0000-0xFFFF. • Planes 1-16 are supplementary planes. – Supports historic scripts and special symbols. – Encodings are 0x10000-0x10FFFF. • Planes are divided into blocks. Unicode and ASCII • ASCII is the bottom block in the BMP, known as the Basic Latin block. • So ASCII values are embedded “as is” into Unicode. • i.e. 'a' is 0x61 in ASCII and 0x0061 in Unicode. Special Encodings • The Byte-Order Mark (BOM) is used to signal endian-ness. • Has no other meaning (i.e. usually ignored). • Encoded as 0xFEFF. • 0xFFFE is a noncharacter. – Cannot appear in any exchange of Unicode. • So file can be started with a BOM; the reader can then know the endian-ness of the file. • In absence of a BOM, Big Endian is assumed. Other Noncharacters • There are a total of 66 noncharacters: – 0xFFFE and 0xFFFF of the BMP – 0x1FFFE and 0x1FFFF of plane 1 – 0x2FFFE and 0x2FFFF of plane 2 – etc., up to – 0x10FFFE and 0x10FFFF of plane 16 – Also 0xFDD0-0xFDEF of the BMP. -

1 Symbols (2286)
1 Symbols (2286) USV Symbol Macro(s) Description 0009 \textHT <control> 000A \textLF <control> 000D \textCR <control> 0022 ” \textquotedbl QUOTATION MARK 0023 # \texthash NUMBER SIGN \textnumbersign 0024 $ \textdollar DOLLAR SIGN 0025 % \textpercent PERCENT SIGN 0026 & \textampersand AMPERSAND 0027 ’ \textquotesingle APOSTROPHE 0028 ( \textparenleft LEFT PARENTHESIS 0029 ) \textparenright RIGHT PARENTHESIS 002A * \textasteriskcentered ASTERISK 002B + \textMVPlus PLUS SIGN 002C , \textMVComma COMMA 002D - \textMVMinus HYPHEN-MINUS 002E . \textMVPeriod FULL STOP 002F / \textMVDivision SOLIDUS 0030 0 \textMVZero DIGIT ZERO 0031 1 \textMVOne DIGIT ONE 0032 2 \textMVTwo DIGIT TWO 0033 3 \textMVThree DIGIT THREE 0034 4 \textMVFour DIGIT FOUR 0035 5 \textMVFive DIGIT FIVE 0036 6 \textMVSix DIGIT SIX 0037 7 \textMVSeven DIGIT SEVEN 0038 8 \textMVEight DIGIT EIGHT 0039 9 \textMVNine DIGIT NINE 003C < \textless LESS-THAN SIGN 003D = \textequals EQUALS SIGN 003E > \textgreater GREATER-THAN SIGN 0040 @ \textMVAt COMMERCIAL AT 005C \ \textbackslash REVERSE SOLIDUS 005E ^ \textasciicircum CIRCUMFLEX ACCENT 005F _ \textunderscore LOW LINE 0060 ‘ \textasciigrave GRAVE ACCENT 0067 g \textg LATIN SMALL LETTER G 007B { \textbraceleft LEFT CURLY BRACKET 007C | \textbar VERTICAL LINE 007D } \textbraceright RIGHT CURLY BRACKET 007E ~ \textasciitilde TILDE 00A0 \nobreakspace NO-BREAK SPACE 00A1 ¡ \textexclamdown INVERTED EXCLAMATION MARK 00A2 ¢ \textcent CENT SIGN 00A3 £ \textsterling POUND SIGN 00A4 ¤ \textcurrency CURRENCY SIGN 00A5 ¥ \textyen YEN SIGN 00A6