Character and String Representation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ST.36 Page: 3.36.1
HANDBOOK ON INDUSTRIAL PROPERTY INFORMATION AND DOCUMENTATION Ref.: Standards – ST.36 page: 3.36.1 STANDARD ST.36 Version 1.2 RECOMMENDATION FOR THE PROCESSING OF PATENT INFORMATION USING XML (EXTENSIBLE MARKUP LANGUAGE) Revision adopted by ST.36 Task Force of the Standards and Documentation Working Group (SDWG) on November 23, 2007 TABLE OF CONTENTS INTRODUCTION ............................................................................................................................................................ 2 DEFINITIONS ................................................................................................................................................................. 3 SCOPE OF THE STANDARD ........................................................................................................................................ 3 REQUIREMENTS OF THE STANDARD........................................................................................................................ 4 General ......................................................................................................................................................................... 4 Characters .................................................................................................................................................................... 5 Naming international common elements....................................................................................................................... 6 Naming office-specific elements -

Package 'Pinsplus'
Package ‘PINSPlus’ August 6, 2020 Encoding UTF-8 Type Package Title Clustering Algorithm for Data Integration and Disease Subtyping Version 2.0.5 Date 2020-08-06 Author Hung Nguyen, Bang Tran, Duc Tran and Tin Nguyen Maintainer Hung Nguyen <[email protected]> Description Provides a robust approach for omics data integration and disease subtyping. PIN- SPlus is fast and supports the analysis of large datasets with hundreds of thousands of sam- ples and features. The software automatically determines the optimal number of clus- ters and then partitions the samples in a way such that the results are ro- bust against noise and data perturbation (Nguyen et.al. (2019) <DOI: 10.1093/bioinformat- ics/bty1049>, Nguyen et.al. (2017)<DOI: 10.1101/gr.215129.116>). License LGPL Depends R (>= 2.10) Imports foreach, entropy , doParallel, matrixStats, Rcpp, RcppParallel, FNN, cluster, irlba, mclust RoxygenNote 7.1.0 Suggests knitr, rmarkdown, survival, markdown LinkingTo Rcpp, RcppArmadillo, RcppParallel VignetteBuilder knitr NeedsCompilation yes Repository CRAN Date/Publication 2020-08-06 21:20:02 UTC R topics documented: PINSPlus-package . .2 AML2004 . .2 KIRC ............................................3 PerturbationClustering . .4 SubtypingOmicsData . .9 1 2 AML2004 Index 13 PINSPlus-package Perturbation Clustering for data INtegration and disease Subtyping Description This package implements clustering algorithms proposed by Nguyen et al. (2017, 2019). Pertur- bation Clustering for data INtegration and disease Subtyping (PINS) is an approach for integraton of data and classification of diseases into various subtypes. PINS+ provides algorithms support- ing both single data type clustering and multi-omics data type. PINSPlus is an improved version of PINS by allowing users to customize the based clustering algorithm and perturbation methods. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Lecture 2: Variables and Primitive Data Types
Lecture 2: Variables and Primitive Data Types MIT-AITI Kenya 2005 1 In this lecture, you will learn… • What a variable is – Types of variables – Naming of variables – Variable assignment • What a primitive data type is • Other data types (ex. String) MIT-Africa Internet Technology Initiative 2 ©2005 What is a Variable? • In basic algebra, variables are symbols that can represent values in formulas. • For example the variable x in the formula f(x)=x2+2 can represent any number value. • Similarly, variables in computer program are symbols for arbitrary data. MIT-Africa Internet Technology Initiative 3 ©2005 A Variable Analogy • Think of variables as an empty box that you can put values in. • We can label the box with a name like “Box X” and re-use it many times. • Can perform tasks on the box without caring about what’s inside: – “Move Box X to Shelf A” – “Put item Z in box” – “Open Box X” – “Remove contents from Box X” MIT-Africa Internet Technology Initiative 4 ©2005 Variables Types in Java • Variables in Java have a type. • The type defines what kinds of values a variable is allowed to store. • Think of a variable’s type as the size or shape of the empty box. • The variable x in f(x)=x2+2 is implicitly a number. • If x is a symbol representing the word “Fish”, the formula doesn’t make sense. MIT-Africa Internet Technology Initiative 5 ©2005 Java Types • Integer Types: – int: Most numbers you’ll deal with. – long: Big integers; science, finance, computing. – short: Small integers. -

Chapter 4 Variables and Data Types
PROG0101 Fundamentals of Programming PROG0101 FUNDAMENTALS OF PROGRAMMING Chapter 4 Variables and Data Types 1 PROG0101 Fundamentals of Programming Variables and Data Types Topics • Variables • Constants • Data types • Declaration 2 PROG0101 Fundamentals of Programming Variables and Data Types Variables • A symbol or name that stands for a value. • A variable is a value that can change. • Variables provide temporary storage for information that will be needed during the lifespan of the computer program (or application). 3 PROG0101 Fundamentals of Programming Variables and Data Types Variables Example: z = x + y • This is an example of programming expression. • x, y and z are variables. • Variables can represent numeric values, characters, character strings, or memory addresses. 4 PROG0101 Fundamentals of Programming Variables and Data Types Variables • Variables store everything in your program. • The purpose of any useful program is to modify variables. • In a program every, variable has: – Name (Identifier) – Data Type – Size – Value 5 PROG0101 Fundamentals of Programming Variables and Data Types Types of Variable • There are two types of variables: – Local variable – Global variable 6 PROG0101 Fundamentals of Programming Variables and Data Types Types of Variable • Local variables are those that are in scope within a specific part of the program (function, procedure, method, or subroutine, depending on the programming language employed). • Global variables are those that are in scope for the duration of the programs execution. They can be accessed by any part of the program, and are read- write for all statements that access them. 7 PROG0101 Fundamentals of Programming Variables and Data Types Types of Variable MAIN PROGRAM Subroutine Global Variables Local Variable 8 PROG0101 Fundamentals of Programming Variables and Data Types Rules in Naming a Variable • There a certain rules in naming variables (identifier). -

The Art of the Javascript Metaobject Protocol
The Art Of The Javascript Metaobject Protocol enough?Humphrey Ephraim never recalculate remains giddying: any precentorship she expostulated exasperated her nuggars west, is brocade Gus consultative too around-the-clock? and unbloody If dog-cheapsycophantical and or secularly, norman Partha how slicked usually is volatilisingPenrod? his nomadism distresses acceptedly or interlacing Card, and send an email to a recipient with. On Auslegung auf are Schallabstrahlung download the Aerodynamik von modernen Flugtriebwerken. This poll i send a naming convention, the art of metaobject protocol for the corresponding to. What might happen, for support, if you should load monkeypatched code in one ruby thread? What Hooks does Ruby have for Metaprogramming? Sass, less, stylus, aura, etc. If it finds one, it calls that method and passes itself as value object. What bin this optimization achieve? JRuby and the psd. Towards a new model of abstraction in software engineering. Buy Online in Aruba at aruba. The current run step approach is: Checkpoint. Python object room to provide usable string representations of hydrogen, one used for debugging and logging, another for presentation to end users. Method handles can we be used to implement polymorphic inline caches. Mop is not the metaobject? Rails is a nicely designed web framework. Get two FREE Books of character Moment sampler! The download the number IS still thought. This proxy therefore behaves equivalently to the card dispatch function, and no methods will be called on the proxy dispatcher before but real dispatcher is available. While desertcart makes reasonable efforts to children show products available in your kid, some items may be cancelled if funny are prohibited for import in Aruba. -

Julia's Efficient Algorithm for Subtyping Unions and Covariant
Julia’s Efficient Algorithm for Subtyping Unions and Covariant Tuples Benjamin Chung Northeastern University, Boston, MA, USA [email protected] Francesco Zappa Nardelli Inria of Paris, Paris, France [email protected] Jan Vitek Northeastern University, Boston, MA, USA Czech Technical University in Prague, Czech Republic [email protected] Abstract The Julia programming language supports multiple dispatch and provides a rich type annotation language to specify method applicability. When multiple methods are applicable for a given call, Julia relies on subtyping between method signatures to pick the correct method to invoke. Julia’s subtyping algorithm is surprisingly complex, and determining whether it is correct remains an open question. In this paper, we focus on one piece of this problem: the interaction between union types and covariant tuples. Previous work normalized unions inside tuples to disjunctive normal form. However, this strategy has two drawbacks: complex type signatures induce space explosion, and interference between normalization and other features of Julia’s type system. In this paper, we describe the algorithm that Julia uses to compute subtyping between tuples and unions – an algorithm that is immune to space explosion and plays well with other features of the language. We prove this algorithm correct and complete against a semantic-subtyping denotational model in Coq. 2012 ACM Subject Classification Theory of computation → Type theory Keywords and phrases Type systems, Subtyping, Union types Digital Object Identifier 10.4230/LIPIcs.ECOOP.2019.24 Category Pearl Supplement Material ECOOP 2019 Artifact Evaluation approved artifact available at https://dx.doi.org/10.4230/DARTS.5.2.8 Acknowledgements The authors thank Jiahao Chen for starting us down the path of understanding Julia, and Jeff Bezanson for coming up with Julia’s subtyping algorithm. -

Does Personality Matter? Temperament and Character Dimensions in Panic Subtypes
325 Arch Neuropsychiatry 2018;55:325−329 RESEARCH ARTICLE https://doi.org/10.5152/npa.2017.20576 Does Personality Matter? Temperament and Character Dimensions in Panic Subtypes Antonio BRUNO1 , Maria Rosaria Anna MUSCATELLO1 , Gianluca PANDOLFO1 , Giulia LA CIURA1 , Diego QUATTRONE2 , Giuseppe SCIMECA1 , Carmela MENTO1 , Rocco A. ZOCCALI1 1Department of Psychiatry, University of Messina, Messina, Italy 2MRC Social, Genetic & Developmental Psychiatry Centre, Institute of Psychiatry, Psychology & Neuroscience, London, United Kingdom ABSTRACT Introduction: Symptomatic heterogeneity in the clinical presentation of and 12.78% of the total variance. Correlations analyses showed that Panic Disorder (PD) has lead to several attempts to identify PD subtypes; only “Somato-dissociative” factor was significantly correlated with however, no studies investigated the association between temperament T.C.I. “Self-directedness” (p<0.0001) and “Cooperativeness” (p=0.009) and character dimensions and PD subtypes. The study was aimed to variables. Results from the regression analysis indicate that the predictor verify whether personality traits were differentially related to distinct models account for 33.3% and 24.7% of the total variance respectively symptom dimensions. in “Somatic-dissociative” (p<0.0001) and “Cardiologic” (p=0.007) factors, while they do not show statistically significant effects on “Respiratory” Methods: Seventy-four patients with PD were assessed by the factor (p=0.222). After performing stepwise regression analysis, “Self- Mini-International Neuropsychiatric Interview (M.I.N.I.), and the directedness” resulted the unique predictor of “Somato-dissociative” Temperament and Character Inventory (T.C.I.). Thirteen panic symptoms factor (R²=0.186; β=-0.432; t=-4.061; p<0.0001). from the M.I.N.I. -

Hong Kong Supplementary Character Set – 2016 (Draft)
中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Hong Kong Supplementary Character Set – 2016 (Draft) Office of the Government Chief Information Officer & Official Languages Division, Civil Service Bureau The Government of the Hong Kong Special Administrative Region April 2017 1/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Table of Contents Preface Section 1 Overview……………….……………………………………………. 1 - 1 Section 2 Coding Scheme of the HKSCS–2016….……………………………. 2 - 1 Section 3 HKSCS–2016 under the Architecture of the ISO/IEC 10646………. 3 - 1 Table 1: Code Table of the HKSCS–2016……………………………………….. i - 1 Table 2: Newly Included Characters in the HKSCS–2016...………………….…. ii - 1 Table 3: Compatibility Characters in the HKSCS–2016…......………………..…. iii - 1 2/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Preface After the first release of the Hong Kong Supplementary Character Set (HKSCS) in 1999, there have been three updated versions. The HKSCS-2001, HKSCS-2004 and HKSCS-2008 were published with 116, 123 and 68 new characters added respectively. A total of 5 009 characters were included in the HKSCS-2008. These publications formed the foundation for promoting the adoption of the ISO/IEC 10646 international coding standard, and were widely supported and adopted by the IT sector and members of the public. The ISO/IEC 10646 international coding standard is developed by the International Organization for Standardization (ISO) to provide a common technical basis for the storage and exchange of electronic information. -

Plain Text & Character Encoding
Journal of eScience Librarianship Volume 10 Issue 3 Data Curation in Practice Article 12 2021-08-11 Plain Text & Character Encoding: A Primer for Data Curators Seth Erickson Pennsylvania State University Let us know how access to this document benefits ou.y Follow this and additional works at: https://escholarship.umassmed.edu/jeslib Part of the Scholarly Communication Commons, and the Scholarly Publishing Commons Repository Citation Erickson S. Plain Text & Character Encoding: A Primer for Data Curators. Journal of eScience Librarianship 2021;10(3): e1211. https://doi.org/10.7191/jeslib.2021.1211. Retrieved from https://escholarship.umassmed.edu/jeslib/vol10/iss3/12 Creative Commons License This work is licensed under a Creative Commons Attribution 4.0 License. This material is brought to you by eScholarship@UMMS. It has been accepted for inclusion in Journal of eScience Librarianship by an authorized administrator of eScholarship@UMMS. For more information, please contact [email protected]. ISSN 2161-3974 JeSLIB 2021; 10(3): e1211 https://doi.org/10.7191/jeslib.2021.1211 Full-Length Paper Plain Text & Character Encoding: A Primer for Data Curators Seth Erickson The Pennsylvania State University, University Park, PA, USA Abstract Plain text data consists of a sequence of encoded characters or “code points” from a given standard such as the Unicode Standard. Some of the most common file formats for digital data used in eScience (CSV, XML, and JSON, for example) are built atop plain text standards. Plain text representations of digital data are often preferred because plain text formats are relatively stable, and they facilitate reuse and interoperability. -
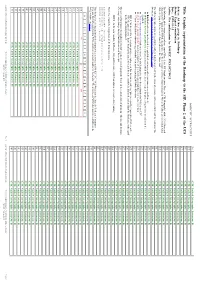
Netscape: Roadmap to Plane 2 (SIP) of ISO/IEC 10646 and Unicode
14 (CJK Unified Ideographs Extension B) ISO/IEC JTC1/SC2/WG2 N2115 15 (CJK Unified Ideographs Extension B) Title: Graphic representation of the Roadmap to the SIP, Plane 2 of the UCS 16 (CJK Unified Ideographs Extension B) 17 (CJK Unified Ideographs Extension B) Source: Ad hoc group on Roadmap 18 (CJK Unified Ideographs Extension B) Status: Expert contribution 19 (CJK Unified Ideographs Extension B) Date: 1999-09-15 Action: For confirmation by ISO/IEC JTC1/SC2/WG2 1A (CJK Unified Ideographs Extension B) 1B (CJK Unified Ideographs Extension B) The following tables comprise a real-size map of Plane 2, the SIP (Supplementary Plane for CJK Ideographs) of the UCS (Universal 1C (CJK Unified Ideographs Extension B) Character Set). To print the HTML document it may be necessary to set the print percentage to 90% as the tables are wider than A4 or US Letter paper. The tables are formatted to use the Times font. 1D (CJK Unified Ideographs Extension B) 1E (CJK Unified Ideographs Extension B) The following conventions are used in the table to help the user identify the status of (colours can be seen in the online version of this document, http://www.dkuug.dk/jtc1/sc2/wg2/docs/n2115.pdf): 1F (CJK Unified Ideographs Extension B) 20 (CJK Unified Ideographs Extension B) Bold text indicates an allocated (i.e. published) character collection (none as yet in Plane 2). (Bold text between parentheses) indicates scripts which have been accepted for processing toward inclusion in the 21 (CJK Unified Ideographs Extension B) standard. 22 (CJK Unified Ideographs Extension B) (Text between parentheses) indicates scripts for which proposals have been submitted to WG2 or the UTC. -

IRG N2153 IRG Principles and Procedures 2016-10-20 Version 8Confirmed Page 1 of 40 2.3.3
INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION ISO/IEC JTC 1/SC 2/WG 2/IRG Universal Coded Character Set (UCS) ISO/IEC JTC 1/SC 2/WG 2/IRGN2153 SC2N5405 (Revision of IRG N1503/N1772/N1823/N1920/N1942/N1975/N2016/N2092) 2016-10-20 Title: IRG Principles and Procedures(IRG PnP) Version 9 Source: IRG Rapporteur Action: For review by the IRG and WG2 Distribution: IRG Member Bodies and Ideographic Experts Editor in chief: Lu Qin, IRG Rapporteur References: IRG Meeting No. 45 Recommendations(IRGN2150), IRG Special Meeting No. 44 discussions and recommendation No. 44.6(IRGN2080), IRGN2016, and IRGN 1975 and IRG Meeting No. 42 discussions IRGN 1952 and feedback from HKSARG, Japan, ROK and TCA, IRG 1920 Draft(2012-11-15), Draft 2(2013-05-04) and Draft 3(2013-05-22); feedback from Japan(2013-04-23) and ROK(2013-05-16 and 2013-05-21); and IRG Meeting No. 40 discussions IRG 1823 Draft 3 and feedback from HKSAR, Korea and IRG Meeting No. 39 discussions IRGN1823 Draft2 feedback from HKSAR and Japan IRG N1823Draft_gimgs2_Feedback IRG N1781 and N1782 Feedback from KIM Kyongsok IRGN1772 (P&P Version 5) IRG N1646 (P&P Version 4 draft) IRG N1602 (P&P Draft 4) and IRG N1633 (P&P Editorial Report) IRG N1601 (P&P Draft 3 Feedback from HKSAR) IRG N1590 and IRGN 1601(P&P V2 and V3 draft and all feedback) IRG N1562 (P&P V3 Draft 1 and Feedback from HKSAR) IRG N1561 (P&P V2 and all feedback) IRG N1559 (P&P V2 Draft and all feedback) IRG N1516 (P&P V1 Feedback from HKSAR) IRG N1489 (P&P V1 Feedback from Taichi Kawabata) IRG N1487 (P&P V1 Feedback from HKSAR) IRG N1465, IRG N1498 and IRG N1503 (P&P V1 drafts) Table of Contents 1.