IRG N2153 IRG Principles and Procedures 2016-10-20 Version 8Confirmed Page 1 of 40 2.3.3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ST.36 Page: 3.36.1
HANDBOOK ON INDUSTRIAL PROPERTY INFORMATION AND DOCUMENTATION Ref.: Standards – ST.36 page: 3.36.1 STANDARD ST.36 Version 1.2 RECOMMENDATION FOR THE PROCESSING OF PATENT INFORMATION USING XML (EXTENSIBLE MARKUP LANGUAGE) Revision adopted by ST.36 Task Force of the Standards and Documentation Working Group (SDWG) on November 23, 2007 TABLE OF CONTENTS INTRODUCTION ............................................................................................................................................................ 2 DEFINITIONS ................................................................................................................................................................. 3 SCOPE OF THE STANDARD ........................................................................................................................................ 3 REQUIREMENTS OF THE STANDARD........................................................................................................................ 4 General ......................................................................................................................................................................... 4 Characters .................................................................................................................................................................... 5 Naming international common elements....................................................................................................................... 6 Naming office-specific elements -

SLP-5 Setup for Uni-3/5/7 & WM-Nano Chinese BIG5 Characters
SLP-5 Configuration for Uni-3, Uni-5, Uni-7 & WM-Nano Chinese BIG5 Characters The Uni-3, Uni-5, Uni-7 scales and WM-Nano wrapper can display and print PLU information in Chinese BIG5, also known as Traditional, characters but all menus, etc. remain in English. Chinese characters are entered in SLP-5 and sent to the scales. Chinese characters cannot be entered at the scales. Refer to the following procedure to configure the scales and wrapper and SLP-5. SCALE SETUP Update the firmware for the Uni-5, Uni-7 and WM-Nano to the following versions. Uni-5: C1830x Uni-7: C1828x (PK-260A CF CPU), C2072x (PK-260B SD CPU) WM-Nano: C1832x (PK-260A CF CPU), C2074x (PK-260B SD CPU) Uni-3: C1937U or later, C2271x The Language setting in the Uni-3 must be set to print and display Chinese characters. Note: Only the Uni-3L2 models display Chinese characters. KEY IN ITEM No. Enter 6000, press MODE 0.000 0.000 0.00 0.00 <B00 SETUP> Enter 495344, press PLU <B00 SETUP> <B00 SETUP> Enter 26, press Down Arrow <B00 SETUP> B26 COUNTRY Press ENTER B26 COUNTRY *LANGUAGE 1:ENGLISH Enter 15, press ENTER B26-01-02 LANGUAGE 1 *LANGUAGE 15:FORMOSAN After the long beep press MODE B26-01-02 LANGUAGE 15 REBOOT Shut off the scale for this setting change to 19004-0000 take effect. SLP-5 SETUP SLP-5 must be configured to use Chinese fonts. Refer to the instructions below. The following Chinese character sizes are available. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Basis Technology Unicode対応ライブラリ スペックシート 文字コード その他の名称 Adobe-Standard-Encoding A
Basis Technology Unicode対応ライブラリ スペックシート 文字コード その他の名称 Adobe-Standard-Encoding Adobe-Symbol-Encoding csHPPSMath Adobe-Zapf-Dingbats-Encoding csZapfDingbats Arabic ISO-8859-6, csISOLatinArabic, iso-ir-127, ECMA-114, ASMO-708 ASCII US-ASCII, ANSI_X3.4-1968, iso-ir-6, ANSI_X3.4-1986, ISO646-US, us, IBM367, csASCI big-endian ISO-10646-UCS-2, BigEndian, 68k, PowerPC, Mac, Macintosh Big5 csBig5, cn-big5, x-x-big5 Big5Plus Big5+, csBig5Plus BMP ISO-10646-UCS-2, BMPstring CCSID-1027 csCCSID1027, IBM1027 CCSID-1047 csCCSID1047, IBM1047 CCSID-290 csCCSID290, CCSID290, IBM290 CCSID-300 csCCSID300, CCSID300, IBM300 CCSID-930 csCCSID930, CCSID930, IBM930 CCSID-935 csCCSID935, CCSID935, IBM935 CCSID-937 csCCSID937, CCSID937, IBM937 CCSID-939 csCCSID939, CCSID939, IBM939 CCSID-942 csCCSID942, CCSID942, IBM942 ChineseAutoDetect csChineseAutoDetect: Candidate encodings: GB2312, Big5, GB18030, UTF32:UTF8, UCS2, UTF32 EUC-H, csCNS11643EUC, EUC-TW, TW-EUC, H-EUC, CNS-11643-1992, EUC-H-1992, csCNS11643-1992-EUC, EUC-TW-1992, CNS-11643 TW-EUC-1992, H-EUC-1992 CNS-11643-1986 EUC-H-1986, csCNS11643_1986_EUC, EUC-TW-1986, TW-EUC-1986, H-EUC-1986 CP10000 csCP10000, windows-10000 CP10001 csCP10001, windows-10001 CP10002 csCP10002, windows-10002 CP10003 csCP10003, windows-10003 CP10004 csCP10004, windows-10004 CP10005 csCP10005, windows-10005 CP10006 csCP10006, windows-10006 CP10007 csCP10007, windows-10007 CP10008 csCP10008, windows-10008 CP10010 csCP10010, windows-10010 CP10017 csCP10017, windows-10017 CP10029 csCP10029, windows-10029 CP10079 csCP10079, windows-10079 -

AIX Globalization
AIX Version 7.1 AIX globalization IBM Note Before using this information and the product it supports, read the information in “Notices” on page 233 . This edition applies to AIX Version 7.1 and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 2010, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document............................................................................................vii Highlighting.................................................................................................................................................vii Case-sensitivity in AIX................................................................................................................................vii ISO 9000.....................................................................................................................................................vii AIX globalization...................................................................................................1 What's new...................................................................................................................................................1 Separation of messages from programs..................................................................................................... 1 Conversion between code sets............................................................................................................. -

Data Encoding: All Characters for All Countries
PhUSE 2015 Paper DH03 Data Encoding: All Characters for All Countries Donna Dutton, SAS Institute Inc., Cary, NC, USA ABSTRACT The internal representation of data, formats, indexes, programs and catalogs collected for clinical studies is typically defined by the country(ies) in which the study is conducted. When data from multiple languages must be combined, the internal encoding must support all characters present, to prevent truncation and misinterpretation of characters. Migration to different operating systems with or without an encoding change make it impossible to use catalogs and existing data features such as indexes and constraints, unless the new operating system’s internal representation is adopted. UTF-8 encoding on the Linux OS is used by SAS® Drug Development and SAS® Clinical Trial Data Transparency Solutions to support these requirements. UTF-8 encoding correctly represents all characters found in all languages by using multiple bytes to represent some characters. This paper explains transcoding data into UTF-8 without data loss, writing programs which work correctly with MBCS data, and handling format catalogs and programs. INTRODUCTION The internal representation of data, formats, indexes, programs and catalogs collected for clinical studies is typically defined by the country or countries in which the study is conducted. The operating system on which the data was entered defines the internal data representation, such as Windows_64, HP_UX_64, Solaris_64, and Linux_X86_64.1 Although SAS Software can read SAS data sets copied from one operating system to another, it impossible to use existing data features such as indexes and constraints, or SAS catalogs without converting them to the new operating system’s data representation. -

International Language Environments Guide
International Language Environments Guide Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 806–6642–10 May, 2002 Copyright 2002 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, Java, XView, ToolTalk, Solstice AdminTools, SunVideo and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. SunOS, Solaris, X11, SPARC, UNIX, PostScript, OpenWindows, AnswerBook, SunExpress, SPARCprinter, JumpStart, Xlib The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. -

Hong Kong Supplementary Character Set – 2016 (Draft)
中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Hong Kong Supplementary Character Set – 2016 (Draft) Office of the Government Chief Information Officer & Official Languages Division, Civil Service Bureau The Government of the Hong Kong Special Administrative Region April 2017 1/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Table of Contents Preface Section 1 Overview……………….……………………………………………. 1 - 1 Section 2 Coding Scheme of the HKSCS–2016….……………………………. 2 - 1 Section 3 HKSCS–2016 under the Architecture of the ISO/IEC 10646………. 3 - 1 Table 1: Code Table of the HKSCS–2016……………………………………….. i - 1 Table 2: Newly Included Characters in the HKSCS–2016...………………….…. ii - 1 Table 3: Compatibility Characters in the HKSCS–2016…......………………..…. iii - 1 2/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Preface After the first release of the Hong Kong Supplementary Character Set (HKSCS) in 1999, there have been three updated versions. The HKSCS-2001, HKSCS-2004 and HKSCS-2008 were published with 116, 123 and 68 new characters added respectively. A total of 5 009 characters were included in the HKSCS-2008. These publications formed the foundation for promoting the adoption of the ISO/IEC 10646 international coding standard, and were widely supported and adopted by the IT sector and members of the public. The ISO/IEC 10646 international coding standard is developed by the International Organization for Standardization (ISO) to provide a common technical basis for the storage and exchange of electronic information. -
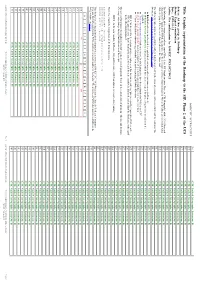
Netscape: Roadmap to Plane 2 (SIP) of ISO/IEC 10646 and Unicode
14 (CJK Unified Ideographs Extension B) ISO/IEC JTC1/SC2/WG2 N2115 15 (CJK Unified Ideographs Extension B) Title: Graphic representation of the Roadmap to the SIP, Plane 2 of the UCS 16 (CJK Unified Ideographs Extension B) 17 (CJK Unified Ideographs Extension B) Source: Ad hoc group on Roadmap 18 (CJK Unified Ideographs Extension B) Status: Expert contribution 19 (CJK Unified Ideographs Extension B) Date: 1999-09-15 Action: For confirmation by ISO/IEC JTC1/SC2/WG2 1A (CJK Unified Ideographs Extension B) 1B (CJK Unified Ideographs Extension B) The following tables comprise a real-size map of Plane 2, the SIP (Supplementary Plane for CJK Ideographs) of the UCS (Universal 1C (CJK Unified Ideographs Extension B) Character Set). To print the HTML document it may be necessary to set the print percentage to 90% as the tables are wider than A4 or US Letter paper. The tables are formatted to use the Times font. 1D (CJK Unified Ideographs Extension B) 1E (CJK Unified Ideographs Extension B) The following conventions are used in the table to help the user identify the status of (colours can be seen in the online version of this document, http://www.dkuug.dk/jtc1/sc2/wg2/docs/n2115.pdf): 1F (CJK Unified Ideographs Extension B) 20 (CJK Unified Ideographs Extension B) Bold text indicates an allocated (i.e. published) character collection (none as yet in Plane 2). (Bold text between parentheses) indicates scripts which have been accepted for processing toward inclusion in the 21 (CJK Unified Ideographs Extension B) standard. 22 (CJK Unified Ideographs Extension B) (Text between parentheses) indicates scripts for which proposals have been submitted to WG2 or the UTC. -

Traditional Chinese Solaris User's Guide
Traditional Chinese Solaris User’s Guide Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 816–0669–10 May 2002 Copyright 2002 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN LOOK GUIs and otherwise comply with Sun’s written license agreements. -

Character and String Representation
Character and String Representation CS520 Department of Computer Science University of New Hampshire CDC 6600 • 6-bit character encodings • i.e. only 64 characters • Designers were not too concerned about text processing! The table is from Assembly Language Programming for the Control Data 6000 series and the Cyber 70 series by Grishman. C Strings • Usually implemented as a series of ASCII characters terminated by a null byte (0x00). • ″abc″ in memory is: n 0x61 n+1 0x62 n+2 0x63 n+3 0x00 Unicode • The space of values is divided into 17 planes. • Plane 0 is the Basic Multilingual Plane (BMP). – Supports nearly all modern languages. – Encodings are 0x0000-0xFFFF. • Planes 1-16 are supplementary planes. – Supports historic scripts and special symbols. – Encodings are 0x10000-0x10FFFF. • Planes are divided into blocks. Unicode and ASCII • ASCII is the bottom block in the BMP, known as the Basic Latin block. • So ASCII values are embedded “as is” into Unicode. • i.e. 'a' is 0x61 in ASCII and 0x0061 in Unicode. Special Encodings • The Byte-Order Mark (BOM) is used to signal endian-ness. • Has no other meaning (i.e. usually ignored). • Encoded as 0xFEFF. • 0xFFFE is a noncharacter. – Cannot appear in any exchange of Unicode. • So file can be started with a BOM; the reader can then know the endian-ness of the file. • In absence of a BOM, Big Endian is assumed. Other Noncharacters • There are a total of 66 noncharacters: – 0xFFFE and 0xFFFF of the BMP – 0x1FFFE and 0x1FFFF of plane 1 – 0x2FFFE and 0x2FFFF of plane 2 – etc., up to – 0x10FFFE and 0x10FFFF of plane 16 – Also 0xFDD0-0xFDEF of the BMP. -

UTF-8 for User Defined Fields
Proposed Updates to ANSI/NIST-ITL 1-2005 UTF8, GPS, Tracking Subcommittee Scott Hills, Aware, Inc. Rob Mungovan, Aware, Inc. Dale Hapeman, DOD-BFC Tony Misslin, Identix Bonny Scheier, Sabre Ralph Lessman, Smiths-Heimann UTF-8 for User Defined Fields Change to Section 6.1 File Format The second paragraph restricts text or character data in Type 2 and Type 9 through Type 16 records to 7-bit ASCII code. This should be modified to allow 8-bit UTF-8 characters in all user defined fields within these records. Proposed wording change to paragraph 2: After the first sentence: “The text or character data in Type-2, and Type-9 through Type-16 records will normally be recorded using 7-bit ASCII code in variable length fields with specified upper limits on the size of the fields.” … Add this… “Eight bit UTF-8 characters shall be allowed to support international character sets for all user defined fields in all record types. By definition this excludes record types 1, 3, 4, 5, 6 and 8.” The third paragraph should be changed to suggest UTF-8 as the preferred way of storing data that cannot be represented in 7-bit ASCII. Proposed wording change to paragraph 3: After the first sentence: “For data interchange between non-English speaking agencies, character sets other than 7-bit ASCII may be used in textual fields contained in Type-2 and Type-9 through Type- 16 records.” … Add this… “UTF-8 is the preferred method of storing textual data that cannot be represented as 7 bit ASCII.” Change to Section 7.2.3 International character sets … at the very end of this section add this text… “Usage of UTF-8 is allowed as an alternative to the technique that requires the usage of the ASCII “STX” and “ETX” characters to signify the beginning or end of of international characters.