Energy-Efficient Computation and Communication Scheduling for Cluster-Based In-Network Processing in Large-Scale Wireless Sensor Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Ukrainian Weekly 1981, No.45
www.ukrweekly.com ;?C свОБОДАJLSVOBODA І І і о "в УКРДШСШИИ щоліннмк ^Щ^У UKKAINIAHOAIIV PUBLISHEDrainia BY THE UKRAINIAN NATIONAL ASSOCIATIOnN INC . A FRATERNAWeekL NON-PROFIT ASSOCIATION l ї Ш Ute 25 cents voi LXXXVIII No. 45 THE UKRAINIAN WEEKLY SUNDAY, NOVEMBER 8, i98i Reagan administration Five years later announces appointment for rights post The Ukrainian Helsinki Group: WASHINGTON - After months of the struggle continues delay, the Reagan administration an– nounced on October 30 that it is no– When the leaders of 35 states gathered in Helsinki in minating Elliot Abrams, a neo-conser– August 1975 signed the Final Act of the Conference on vative Democrat and former Senate Security and Cooperation in Europe, few could aide, to be assistant secretary of state for have foreseen the impact the agreement would have in human rights and humanitarian affairs, the Soviet Union. While the accords granted the Soviets reported The New York Times. de jure recognition of post-World War ll boundaries, they The 33-year-old lawyer, who pre– also extracted some acquiescence to provisions viously worked as special counsel to guaranteeing human rights and freedom, guarantees Sen. Henry Jackson of Washington and that already existed in the Soviet Constitution and Sen. Daniel Patrick Moynihan of New countless international covenants. York, joined the administration last At the time, the human-rights provisions seemed January as assistant secretary of state unenforceable, a mere formality, a peripheral issue for international organization affairs. agreed to by a regime with no intention of carrying in announcing the nomination, Presi– them through. dent Ronald Reagan stated that hu– But just over one year later, on November 9,1976,10 man-rights considerations are an im– courageous Ukrainian intellectuals in Kiev moat of portant part of foreign policy, the Times them former political prisoners, formed the Ukrainian said. -

Technical Report
NAVAL POSTGRADUATE SCHOOL Monterey, California TECHNICAL REPORT “SEA ARCHER” Distributed Aviation Platform by Faculty Members Charles Calvano David Byers Robert Harney Fotis Papoulias John Ciezki Robert Ashton Student Members LT Joe Keller, USN LCDR Rabon Cooke, USN CDR(sel) James Ivey, USN LT Brad Stallings, USN LT Antonios Dalakos, Helenic Navy LT Scot Searles, USN LTjg Orhan Okan, Turkish Navy LTjg Mersin Gokce, Turkish Navy LT Ryan Kuchler, USN LT Pete Lashomb, USN Ivan Ng, Singapore December 2001 Approved for public release, distribution unlimited REPORT DOCUMENTATION PAGE Form Approved OMB No. 0704-0188 Public reporting burden for this collection of information is estimated to average 1 hour per response, including the time for reviewing instruction, searching existing data sources, gathering and maintaining the data needed, and completing and reviewing the collection of information. Send comments regarding this burden estimate or any other aspect of this collection of information, including suggestions for reducing this burden, to Washington headquarters Services, Directorate for Information Operations and Reports, 1215 Jefferson Davis Highway, Suite 1204, Arlington, VA 22202-4302, and to the Office of Management and Budget, Paperwork Reduction Project (0704-0188) Washington DC 20503. 1. AGENCY USE ONLY (Leave blank) 2. REPORT DATE 3. REPORT TYPE AND DATES COVERED December 2001 Technical Report 4. TITLE AND SUBTITLE: 5. FUNDING NUMBERS “Sea Archer” Distributed Aviation Platform 6. AUTHOR(S) Charles Calvano, Robert Harney, David Byers, Fotis Papoulias, John Ciezki, LT Joe Keller, LCDR Rabon Cooke, CDR (sel) James Ivey, LT Brad Stallings, LT Scot Searles, LT Ryan Kuchler, Ivan Ng, LTjg Orhan Okan, LTjg Mersin Gokce, LT Antonios Dalakos, LT Pete Lashomb. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Kyrillische Schrift Für Den Computer
Hanna-Chris Gast Kyrillische Schrift für den Computer Benennung der Buchstaben, Vergleich der Transkriptionen in Bibliotheken und Standesämtern, Auflistung der Unicodes sowie Tastaturbelegung für Windows XP Inhalt Seite Vorwort ................................................................................................................................................ 2 1 Kyrillische Schriftzeichen mit Benennung................................................................................... 3 1.1 Die Buchstaben im Russischen mit Schreibschrift und Aussprache.................................. 3 1.2 Kyrillische Schriftzeichen anderer slawischer Sprachen.................................................... 9 1.3 Veraltete kyrillische Schriftzeichen .................................................................................... 10 1.4 Die gebräuchlichen Sonderzeichen ..................................................................................... 11 2 Transliterationen und Transkriptionen (Umschriften) .......................................................... 13 2.1 Begriffe zum Thema Transkription/Transliteration/Umschrift ...................................... 13 2.2 Normen und Vorschriften für Bibliotheken und Standesämter....................................... 15 2.3 Tabellarische Übersicht der Umschriften aus dem Russischen ....................................... 21 2.4 Transliterationen veralteter kyrillischer Buchstaben ....................................................... 25 2.5 Transliterationen bei anderen slawischen -

Structure–Function Analysis of the Tssl Cytoplasmic Domain Reveals a New Interaction Between the Type VI Secretion Baseplate A
Structure–Function Analysis of the TssL Cytoplasmic Domain Reveals a New Interaction between the Type VI Secretion Baseplate and Membrane Complexes Abdelrahim Zoued, Chloé Cassaro, Eric Durand, Badreddine Douzi, Alexandre España, Christian Cambillau, Laure Journet, E. Cascales To cite this version: Abdelrahim Zoued, Chloé Cassaro, Eric Durand, Badreddine Douzi, Alexandre España, et al.. Structure–Function Analysis of the TssL Cytoplasmic Domain Reveals a New Interaction between the Type VI Secretion Baseplate and Membrane Complexes. Journal of Molecular Biology, Elsevier, 2016, 428 (22), pp.4413 - 4423. 10.1016/j.jmb.2016.08.030. hal-01780163 HAL Id: hal-01780163 https://hal-amu.archives-ouvertes.fr/hal-01780163 Submitted on 27 Apr 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. 1! Structure-function analysis of the TssL cytoplasmic domain reveals a new 2! interaction between the Type VI secretion baseplate and membrane 3! complexes. 4! Abdelrahim Zoued1,#, Chloé J. Cassaro1, Eric Durand1, Badreddine Douzi2,3,¶, Alexandre P. 5! España1,†, Christian Cambillau2,3, Laure Journet1, and Eric Cascales1,* 6! 7! 1 Laboratoire d’Ingénierie des Systèmes Macromoléculaires (LISM, UMR 7255), Institut de 8! Microbiologie de la Méditerranée (IMM), Aix-Marseille Univ - Centre National de la Recherche 9! Scientifique (CNRS), 31 chemin Joseph Aiguier, 13402 Marseille Cedex 20, France 10! 2 Architecture et Fonction des Macromolécules Biologiques (AFMB, UMR 6098), Centre National de 11! la Recherche Scientifique (CNRS), Campus de Luminy, Case 932, 13288 Marseille Cedex 09, France. -

Proceedings of the Workshop on Computational Linguistics for Linguistic Complexity, Pages 1–11, Osaka, Japan, December 11-17 2016
CL4LC 2016 Computational Linguistics for Linguistic Complexity Proceedings of the Workshop December 11, 2016 Osaka, Japan Copyright of each paper stays with the respective authors (or their employers). ISBN 978-4-87974-709-9 ii Preface Welcome to the first edition of the “Computational Linguistics for Linguistic Complexity” workshop (CL4LC)! CL4LC aims at investigating “processing” aspects of linguistic complexity with the objective of promoting a common reflection on approaches for the detection, evaluation and modelling of linguistic complexity. What has motivated such a focus on linguistic complexity? Although the topic of linguistic complexity has attracted researchers for quite some time, this concept is still poorly defined and often used with different meanings. Linguistic complexity indeed is inherently a multidimensional concept that must be approached from various perspectives, ranging from natural language processing (NLP), second language acquisition (SLA), psycholinguistics and cognitive science, as well as contrastive linguistics. In 2015, a one-day workshop dedicated to the question of Measuring Linguistic Complexity was organized at the catholic University of Louvain (UCL) with the aim of identifying convergent approaches in diverse fields addressing linguistic complexity from their specific viewpoint. Not only did the workshop turn out to be a great success, but it strikingly pointed out that more in–depth thought is required in order to investigate how research on linguistic complexity and its processing aspects could actually benefit from the sharing of definitions, methodologies and techniques developed from different perspectives. CL4LC stems from these reflections and would like to go a step further towards a more multifaceted view of linguistic complexity. In particular, the workshop would like to investigate processing aspects of linguistic complexity both from a machine point of view and from the perspective of the human subject in order to pinpoint possible differences and commonalities. -
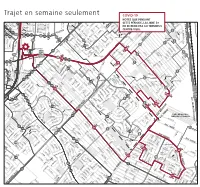
Trajet En Semaine Seulement E R I L R R C O F C N
Fleuve Saint-Laurent des ROSEAUX LA PRAIRIEVille de des ROSELIÈRES de s R UB AN IE RS R IV ER IN RIVERIN de R ROISSY I R I VE V R RENAUD E I R N I N R AM RADISSON E RAINVILLEcr. AU bo ul. MA RAVEL RIE RIEL -V b IC A RAVEL R T o ROCHELLE O D cr. O O u boul. RIVARD R H M pl. ROCHEFORTI R l N . A boul. MATTE ROBERT I N T ROBESPIERRE A R RICHELIEU D E RIVIERA S O cr. U U A pl. C S IG S R IGNACE H E cr L R . R S E O U T pl. RÉCOLLET G B R R E E A C S R NS V H A E pl. I AR IN I N L A RAINIER S L T R E - L U c K I r. I O S N R S O S O RÉCOLLET U I I U S G S E IO S N RÉGINA I I L R N O E L b cr. ROLLIN H RIOPELLE o IC u R T l. l. R RENOIR d p E u RACICOT B c SCHUBERT O r E . S L R EL R ROS A AB TE O TA I IS T U N N A G D R AM T M E E M - pl. JADE . M L oul O ROSSINI BR A b N A cr. RAPHAËL U T ND R T PM E c AM r N . S AM RODIER AM I T R b O O O o du RHÔNE SAINT-Ç L u N p U pl A l I cr. -

Iso/Iec Jtc1/Sc2/Wg2 N3748 L2/10-002
ISO/IEC JTC1/SC2/WG2 N3748 L2/10-002 2010-01-21 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation internationale de normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal to encode nine Cyrillic characters for Slavonic Source: UC Berkeley Script Encoding Initiative (Universal Scripts Project) Authors: Michael Everson, Victor Baranov, Heinz Miklas, Achim Rabus Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2010-01-21 1. Introduction. This document requests the addition of a nine Cyrillic characters to the UCS, extending the set of combining characters introduced in the Cyrillic Extended A block (U+2DE0..2DFF). These characters occur in medieval Church Slavonic manuscripts from the 10th/11th to the 17th centuries CE which are at present the object of scholarly investigations and publications in printed and electronic form. They are also used in modern ecclesiastical editions of liturgical and religious books. The set comprises nine superscript letters for which examples from representative primary sources are given. Printed samples of all units proposed for addition are to be found in the new Belgrade table, worked out by a group of slavists in 2007-08 (cf. BS). They also occur in certain Cyrillic fonts composed for scholarly publications, like the one designed by Victor A. Baranov at Izhevsk Technical university. 2. Additional combining characters. Principally, the superscription of characters in medieval Cyrillic manuscripts and printed ecclesiastical editions fulfils two major functions—the classification of abbreviations (in addition to other means, inherited from the Greek mother-tradition: per suspensionem— for common words of liturgical rubrics, and per contractionem—for nomina sacra, cf. -

Estrategia De Promoción Del Tercer Sector Social De Euskadi Plan De Legislatura 2018 -2020
Estrategia de Promoción del Tercer Sector Social de Euskadi Plan de Legislatura 2018 -2020 Edición: 1ª. XXXXX 2018 Tirada: XXXX ejemplares © Administración de la Comunidad Autónoma del País Vasco Departamento de Empleo y Políticas Sociales Internet: www.euskadi.eus Edita: Eusko Jaurlaritza Argitalpen Zerbitzu Nagusia Servicio Central de Publicaciones del Gobierno Vasco Donostia-San Sebastián, 1 – 01010 Vitoria-Gasteiz Autoría: Gobierno Vasco, en colaboración con las redes del TSSE a través de la Mesa de Diálogo Civil de Euskadi Fotocomposición: Impresión: ISBN: DL: Una estrategia conjunta para impulsar el tejido social y la cooperación entre sectores en el ámbito de la intervención social Las organizaciones de iniciativa social e intervención social constituyen un activo fundamental de la sociedad vasca y su contribución resulta imprescindible para construir una sociedad que sea, a la vez, justa y solidaria, igualitaria y cohesionada, democrática y participativa, así como para responder de manera más adecuada (integral, cercana, personalizada, participativa) a las necesidades sociales, desde la colaboración entre sectores y con la participación de las propias personas, familias, colectivos o comunidades destinatarias. Así lo reconoce y declara la ley 6/2016, de 12 de mayo, del Tercer Sector Social de Euskadi (LTSSE) en el párrafo décimo de su exposición de motivos y al consolidar el principio de diálogo civil y el modelo mixto de provisión de servicios de responsabilidad pública. Diálogo civil y modelo mixto que, como la solidaridad y la justicia, la igualdad y la cohesión o la democracia y la participación, se reclaman mutuamente . Principio de diálogo civil , con el sector público vasco (ejecutivos y legislativos), que implica el reconocimiento del derecho de las organizaciones y redes, y de las y los destinatarios y protagonistas de la intervención social a través de ellas, a participar en las políticas públicas que les conciernen en todas sus fases, incluida la ejecución (artículo 7). -

Thoroughfare Types and Abbreviations
Universal Postal Union - ASO April 2021 1/57 ABBREVIATIONS Where can I find lists of different types of thoroughfares, and their abbreviations used in different countries? Où puis-je trouver les listes de différents types de voies, et leurs abréviations utilisées dans les différents pays? ABRÉVIATIONS Your one-stop address: [email protected] International Bureau of the Universal Postal Union POST*CODE ® Addressing Solutions (ASO) P.O. Box 312 3000 BERNE 15 SWITZERLAND Tél. +41 31 350 34 67- Fax +41 31 350 31 10 www.upu.int Universal Postal Union - ASO April 2021 2/57 AGO - Angola - Thoroughfare types and abbreviations Abbreviations for Types of Artery Type of Artery Abbreviation Avenida Av. Bairro Ba Quilômetro Km Largo Lar Número n° Principal Princ. Quarteirão Quart Abbreviations of Titles Title Abbreviation Comandante Cmdte Doutor Dr. San S. Abbreviations of Designators in frequent addresses Designation Abbreviation Empresa de Transporte Público ETP Angola Music Group AMG Obra da Divina Providência ODP Universal Postal Union - ASO Februay 2019 3/57 ARG - Argentina - Throroughfares types and abbreviations Glossary in Spanish Abbreviation Name in French Name in English 3er piso 3° troisième étage third floor 3ra puerta 3a troisième porte third door Aldea Ald. village village AtenciÓn At. A l'attention Attention Avenida Avda. Avenue Avenue Barrio Ba. quartier neighbourhood Bodega Bod. entrepôt/entrepôt de vinstorage cellar /winery Casa Ca. maison house Calle Cl. rue street Camino Cam. chemin path Canal Can. canal channel Correo Ceo Poste Post Casilla de correo C.c case postale Post Office Box Don D. Monsieur Mister Doña Dña. Madame Miss Edificio Edif. -

ISO/IEC International Standard 10646-1
JTC1/SC2/WG2 N3381 ISO/IEC 10646:2003/Amd.4:2008 (E) Information technology — Universal Multiple-Octet Coded Character Set (UCS) — AMENDMENT 4: Cham, Game Tiles, and other characters such as ISO/IEC 8824 and ISO/IEC 8825, the concept of Page 1, Clause 1 Scope implementation level may still be referenced as „Implementa- tion level 3‟. See annex N. In the note, update the Unicode Standard version from 5.0 to 5.1. Page 12, Sub-clause 16.1 Purpose and con- text of identification Page 1, Sub-clause 2.2 Conformance of in- formation interchange In first paragraph, remove „, the implementation level,‟. In second paragraph, remove „, and to an identified In second paragraph, remove „with an implementation implementation level chosen from clause 14‟. level‟. In fifth paragraph, remove „, the adopted implementa- Page 12, Sub-clause 16.2 Identification of tion level‟. UCS coded representation form with imple- mentation level Page 1, Sub-clause 2.3 Conformance of de- vices Rename sub-clause „Identification of UCS coded repre- sentation form‟. In second paragraph (after the note), remove „the adopted implementation level,‟. In first paragraph, remove „and an implementation level (see clause 14)‟. In fourth and fifth paragraph (b and c statements), re- move „and implementation level‟. Replace the 6-item list by the following 2-item list and note: Page 2, Clause 3 Normative references ESC 02/05 02/15 04/05 Update the reference to the Unicode Bidirectional Algo- UCS-2 rithm and the Unicode Normalization Forms as follows: ESC 02/05 02/15 04/06 Unicode Standard Annex, UAX#9, The Unicode Bidi- rectional Algorithm, Version 5.1.0, March 2008. -

Responds to 940406 Ltr Requesting Addl Info Re Radioactive
.,_ ., m 1 . .m m .. i - . MS-ilo- h'i g' BostonUniversity naaiation protection N W# Medical Center office ei Ncwton Street. D Mu limtor. Mawchosetts 02116 2 m 61' 63N'04 2 USNRC Region I I 475 Allendale Rd. King of Prussia, PA 19406 | Attn: Keith Brown, Ph.D. I June 24, 1994 ! Docket No. 030-01845 Control No. 118364 . Dear Dr. Brown, |I i We are responJ'ng to the April 6, 1994 request for additional informat W regarding radioactive incineration on our ' broad medical license # 20-02215-01. Questions 1 & 2 ) Per our May 5, 1994 telephone conversation, you indicated that we would be allowed to incinerate radioactive materials with half-lives less than 90 days for volume reduction. We therefere wish to be allowed to exercise this option as we previoucly ! stated in past letters, should we need to incinerate short-lived material with long-lived radwaste e.g. animal carcasses. ouestion 3 | l a) The following procedures will be performed to determine that ash generated from our incinerator is not radioactive. Ash Analysis of Gamma Emitters i Analysis of gamma emitters of ash is a procedure that is fairly straight forward and compares to our rcutinc r.nalysis for I gamma emitters with wipe tests and a radioic ination air sample ! measurements. These procedures have been described in our | license renewal. Ash would be sampled from the incinerator and i counted in a marinelli beaker using a high purity germanium detector coupled to a computer controlled Aptec software multichannel analysis system. While individual MDA's for different gamma emitters will vary, we estimate that we easily can measure activities in ash in nanocurie to picocurie ranges at the 95% confidence interval, our system is NIST calibrated and can identify unknown isotopes.