Historical Vehicle Traffic Analysis and Commute Time Prediction Using Web Mining
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
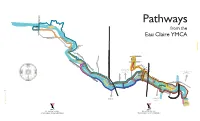
ECY Running Map:Layout 1.Qxd
Pathways from the Eau Claire YMCA GOING EAST 13. EDWORTHY PARK LOOP (15.1 km): Head west on the South side of the river beyond the CPR Rail 1. LANGEVIN LOOP (3.5 km): Go East on the South side of the river, past Centre Street underpass. way Crossing at Edworthy Park. Cross Edworthy Bridge to the North side of the river and head East. Cross over at the Langevin Bridge and head West. Return via Prince’s Island Bridge. Return to the South side via Prince’s Island Bridge. 2. SHORT ZOO (6.1 km): Go East on the South side of the river past Langevin Bridge to St George’s 14. SHOULDICE BRIDGE (20.4 km): Cross Prince’s Island Bridge to the North side of the river and head Island footbridge. Cross to the North side via Baines Bridge. Return on the North side heading West West to Shouldice Bridge at Bowness Road. Return the same way heading East. via Prince’s Island Bridge. 15. BOWNESS PARK via BOW CRESCENT (32.4 km): Follow North side of river going West from 3. LONG ZOO (7.6 km): Go East on the South side of the river over 9th Avenue Bridge. Travel through Prince’s Island to Bowness Road. Cross over Shouldice Bridge. Follow Bow Crescent, 70th Street, and the zoo to Baines Bridge. Return heading west on the North side of the river, crossing back via 48th Avenue to Bowness Park. Make loop of paved road (West) and return to YMCA same way. pathway around zoo and returning through Prince’s Island. -

182 Hamptons Link NW St
1 8 2 H A M P T O N S L I N K N W 403.247.9988 [email protected] www.themckelviegroup.com 1 8 2 H A M P T O N S L I N K N W Opportunity to live a simpler life! LaVita is a quiet, well managed complex offering excellent yard maintenance & snow removal - imagine all the extra free time to pursue your interests! Lovely corner unit benefits from additional windows & is flooded w natural light. Extremely well cared for & maintained, you will appreciate freshly painted walls & new carpet, baseboards & taps. Open concept design is unique in this complex & combined with 9ft ceilings & light laminate floors creates a very spacious & airy feeling. Kitchen & bathrooms have white cabinets w neutral charcoal or white counters making these spaces feel classic & always current. Kitchen offers a center island with bar seating, stainless steel appliances & beautiful sea-blue glass tiles. Upstairs there are 2 large bedrooms - both with great views. Conveniently located close to great amenities, 15 min from YYC airport, close to golf course & quick access to Ring Road, Country Hills Blvd & Shaganappi Trail. Pets welcome! A very special find - act fast! La Vita is perfectly located near and in walking distance to the Hampton's school, Golf Course, playgrounds, parks and pathways, amenities such as shopping and restaurants, public transportation. Easy access to major roadways such as Country Hills Boulevard, Stoney Trail, and Shaganappi Trail. Condo fees are low in this professionally managed complex. 403.247.9988 [email protected] www.themckelviegroup.com WELCOME TO THE HAMPTONS The Hamptons was developed in 1990 and is one of Calgary’s nicest North West communities. -

Direction to the Rimrock Resort Hotel from the Calgary International Airport 1A Crowchild Trail
2 Beddington Trail 3 Country Hill Blvd. Trail Barlow Direction to the Rimrock Resort Hotel from the Calgary International Airport 1A Crowchild Trail Deerfoot Trail NE 201 Country Hill Blvd. Harvest Hills Blvd. 2 2A 14 St NW Mountain Avenue, P.O. Box 1110, Stoney Trail. Nosehill Dr. Shaganappi Trail Barlow Trail Barlow Banff, Alberta Canada T1L 1J2 1A Sarcee Trail Calgary John Laurier Blvd. International Crowchild Trail Nosehill Natural Airport 1 Phone: (403) 762-3356 Environment Park Fax: (403) 762-4132 Deerfoot Trail NE John Laurier Blvd. McNight Blvd 5 Trans Canada Highway 1A McNight Blvd 1 Centre St Centre 2 Trans Canada Highway 6 Sarcee Trail 4 1 1 East From Calgary Town Of Banff Deerfoot Trail SE Trans Canada Highway To Town of Banff 5 7 Banff Avenue To Town of Banff City of Calgary West To Lake Louise Mt. Norquay Road Fox Cougar Check Points ad Banff AvenueDeer Ro ain nt ou l M ne 1 Moose n Tu From the Airport, take Barlow Trail (Left Turn). Squirrel Moose Gopher Street Marten Elk 2 Turn left on Country Hills Blvd. Beaver Muskrat Otter Linx StreetWolf Wolf 3 St. Julien Turn left (South) onto Stoney Trail. Bear Caribou 4 Turn right (Westbound) onto Highway 1 (Trans Buffalo Banff Avenue Buffalo Canada Highway). 8 Bow River 5 Follow highway 1 West to Banff National Park. 9 Canada Place Casscade Gardens 6 Take the Banff, Lake Minnewanka exit and turn left at the stop sign on to Banff Avenue. Avenue Mountain 7 Follow Banff Avenue through town and across the Bow River bridge. -

Macleod Trail Corridor Study TT2015-0183 Information Brochure ATTACHMENT 2
Macleod Trail Corridor Study TT2015-0183 Information Brochure ATTACHMENT 2 MACLEOD TRAIL CORRIDOR STUDY A balanced approach to transportation planning 2015-0626 calgary.ca | contact 311 Onward/ Providing more travel choices helps to improve overall mobility in Calgary’s transportation system. TT2015-0183 Macleod Trail Corridor Study - Att 2.pdf Page 1 of 12 ISC: Unrestricted Macleod Trail Corridor Study Information Brochure 100 YEARS OF MACLEOD TRAIL: PAST, PRESENT, FUTURE Photo of Macleod Trail circa 1970. The City of Calgary, Corporate Records, Archives. Photo of Macleod Trail circa 2005. The City of Calgary, Corporate Records, Archives. Macleod Trail, as we know it today, has remained much the same since the 1960’s. It was, and continues to be, characterized by low-rise buildings accompanied by paved parking lots and poor infrastructure for pedestrians. The development of low-density land use and long distances between destinations or areas of interest has encouraged driving as the primary way for people to get to and from key destinations along Macleod Trail. What will Macleod Trail look like Because people will be living within walking or cycling distances to businesses and major activity centres over the next 50 years? (e.g. shopping centres), there will be a need for quality Many of the older buildings along Macleod Trail are sidewalks, bikeways, and green spaces that help enhance approaching the end of their lifecycle. Now is an safety of road users and improve the overall streetscape. opportune time to put in place conditions that will help guide a different type of land use and development along PEOPLE WILL HAVE ACCESS TO SAFE, Macleod Trail for the next 50 years. -

Stand Alone Office Building for Lease 431 - 58Th Avenue Se, Calgary, Ab
STAND ALONE OFFICE BUILDING FOR LEASE 431 - 58TH AVENUE SE, CALGARY, AB N 4 Street SE P P 58 Avenue SE Dining Major Public Transit Services Thoroughfares Accessibility Petro Canada Subway 58th Avenue SE Serviced by Bus Wholesale Foods Tim Hortons Blackfoot Trail Routes: 66, 72, 73 TD Canada Trust Wendy’s Macleod Trail Oriental Phoenix RBC Royal Bank Gaucho 7-Eleven Alexi Olcheski, Principal Paul McKay, Vice President Eric Demaere, Associate 403.232.4332 587.293.3365 587.293.3366 [email protected] [email protected] [email protected] © 2018 Avison Young Real Estate Alberta Inc. All rights reserved. E. & O.E.: The information contained herein was obtained from sources which we deem reliable and, while thought to be correct, is not guaranteed by Avison Young. 431 - 58TH AVENUE SE, CALGARY, AB Particulars estled on 58th Avenue SE between the major Available Space: 5,048 SF (Demisable) Nthouroughfares of Blackfoot Trail and Macleod Trail, this rare stand alone office space is a one-of-a Demising A. 1,528 SF kind opportunity for various tenants. Whether the Options: B. 2,099 SF use is medical or business, this space is guaranteed to be the perfect location to build and expand your C. 2,949 SF business. Within a 3 km radius, the 2017 daytime D. 3,520 SF population was 58,467, with 24,000 vehicles per day (VPD) on 58th Avenue SE and 57,000 VPD on Rental Rates: Market Blackfoot Trail SE. Op. Costs: $12.76 PSF (2018 est.) Zoning: I-G (Industrial-General) Occupancy: 30 days Term: 5 - 10 years Highlights - Located on the southwest corner of 58th Avenue and 4th Street SE - Minutes away from Chinook Centre, Calgary’s largest enclosed mall (1.2M GLA) - 23 surface parking stalls at the rear of the property - High quality interior finishes - Features include showers, washing machine, and dryer Alexi Olcheski, Principal Paul McKay, Vice President Eric Demaere, Associate 403.232.4332 587.293.3365 587.293.3366 [email protected] [email protected] [email protected] © 2018 Avison Young Real Estate Alberta Inc. -

Markin Macphail Centre Floor
DRIVING PARKING MAP DIRECTIONS N Approximate driving time from *+..'{-->^. e v Calgary lnternational Airport: 30 minutes s Directions from the Galgary lnternational Airport; north of the city: . Hmd North on Deerfoot Trail b,ry* ' . Take Stoney Trail West (this is the ring e{,i road and will eventually turn south) . Take Trans-Canada Highway ."& (16th Ave. NW) East I ATct c€ofe . the right-hand lane and turn right Stay in ffi AlCo C6rfr6 Pandu lot into Canada Olympic Park I Mdkin t ePhdl cnre I F6dEl Ted Directions from east of the city: *& Mridn tlacPhail Cmtre . Head west on Trans-Canada Highway aU FestEl Tmt P&klng Lot (16th Ave. NQ I ftof6ifid Bullding o Continue on 16th Ave., past Deerfoot Trail I tub0cEnhm . Continue along 16th Ave., past W Hayffi Entrdce McMahon Stadium and the Foothills Hospital oledo/ Palking lot . Once across the river, stay in S D4dodgo the left-hand lane and follow o4hdge Pdldng Lo! the signs for the left-hand turn into Canada Olympic Park Directions from south of the city: MARKIN MACPHAIL CENTRE . Head nofth on MacLeod Trail r Take Glenmore Trail West . Merge onto Crowchild Trail North FLOOR MAP . Take Memorial Drive West . Once through the traffiic lights at Shaganappi Trail stay to the right and ffi *u*r*,. fl{..i}{.:iflq merge onto 16th Ave. NW I *' li,:ll;,;;:::" heading westbound r''' llr[r;-, *"' r Once across the river, stay in the left-hand ,r f mb ils.D3 I :1::::ir;3:, I *" lane and follow the signs for the left-hand f :I)"";"*'* turn into Canada Otympic Park ]: :iliifur" * . -

A Comprehensive Guide to the Alberta Oil Sands
A COMPREHENSIVE GUIDE TO THE ALBERTA OIL SANDS UNDERSTANDING THE ENVIRONMENTAL AND HUMAN IMPACTS , EXPORT IMPLICATIONS , AND POLITICAL , ECONOMIC , AND INDUSTRY INFLUENCES Michelle Mech May 2011 (LAST REVISED MARCH 2012) A COMPREHENSIVE GUIDE TO THE ALBERTA OIL SANDS UNDERSTANDING THE ENVIRONMENTAL AND HUMAN IMPACTS , EXPORT IMPLICATIONS , AND POLITICAL , ECONOMIC , AND INDUSTRY INFLUENCES ABOUT THIS REPORT Just as an oil slick can spread far from its source, the implications of Oil Sands production have far reaching effects. Many people only read or hear about isolated aspects of these implications. Media stories often provide only a ‘window’ of information on one specific event and detailed reports commonly center around one particular facet. This paper brings together major points from a vast selection of reports, studies and research papers, books, documentaries, articles, and fact sheets relating to the Alberta Oil Sands. It is not inclusive. The objective of this document is to present sufficient information on the primary factors and repercussions involved with Oil Sands production and export so as to provide the reader with an overall picture of the scope and implications of Oil Sands current production and potential future development, without perusing vast volumes of publications. The content presents both basic facts, and those that would supplement a general knowledge base of the Oil Sands and this document can be utilized wholly or in part, to gain or complement a perspective of one or more particular aspect(s) associated with the Oil Sands. The substantial range of Oil Sands- related topics is covered in brevity in the summary. This paper discusses environmental, resource, and health concerns, reclamation, viable alternatives, crude oil pipelines, and carbon capture and storage. -

Leasing Opportunity 88% Occupied 1000 Sf
LEASING OPPORTUNITY 88% OCCUPIED 1,000 S.F. — 2,800 S.F. OF MEDICAL OFFICE SPACE AVAILABLE 1 2 OVERVIEW D&P Commercial Group is a private real estate investor, developer, owner, and manager that specializes in destination medical facilities. Founded by physicians, we understand the unique requirements of our tenants (healthcare providers) and their patrons (patients). An experienced team and network of trusted partners ensures that global trends are combined with local needs to create sustainable properties that make lasting contributions to the overall health and wellness of people and communities. From inception to operation, D&P Commercial Group’s goal for each project remains steadfast: provide tenants (healthcare providers) the best opportunity to run successful practices and give every patron (patient) the optimal environment for healing. With this in mind, novel concepts and high-quality materials are used to build state-of-the-art destination medical facilities with iconic architecture, modern design, cutting-edge technology, environmentally-friendly features, and efficient flow. In addition, we take great pride in strategic planning, meticulous attention to detail, and timely execution before and during construction as well as proactive and responsible management after completion. Meadows Mile Professional Building—the first in a series of projects by D&P Commercial Group—is located in the thriving southeast quadrant of Calgary, Alberta, Canada. Brilliantly situated along a major thoroughfare and in close proximity to a unique blend of residential, retail, and industrial areas, this site has high visibility and easy accessibility. With visually stunning and fully integrated spaces, Meadows Mile Professional Building is the true confluence of form and function, enabling a positive and seamless experience for tenants (healthcare providers) and patrons (patients) alike. -

Sand Tiger Lodge!
WELCOME TO SAND TIGER LODGE! 11/1/2018 1 WELCOME TO SAND TIGER LODGE Dear Guest, On behalf of the STL Team, Welcome to Sand Tiger Lodge! We have had the honor of serving Japan Canada Oil Sands since we commenced operations in December 2007. We are located less than a ten minute drive from your site at Hangingstone. Currently, our camp consists of 622 beds, which includes Premier Executive, Standard Executive and Craft Housing, enhanced recreation facilities (including theatre and workout areas) and fine dining. The purpose of this document is to help orient you to our camp. Many camps have a variety of guidelines and quite often, these guidelines vary. STL wants to ensure you have a “Home Away From Home” experience whilst residing with us. We promise to provide: ✓ A safe, clean environment ✓ Excellence in Facilities ✓ Outstanding Food and Housekeeping ✓ Personalized Service In closing, the Sand Tiger Team has a “Servant’s Heart”. We will be “The Best Serving The Best”. If you have any questions or concerns, please do not hesitate to contact your STL Team. Sincerely, Wayne Sluice President Sand Tiger Lodge 11/1/2018 2 DIRECTIONS TO SAND TIGER LODGE Directions to Sand Tiger Lodge from Fort McMurray International Airport (YMM) • Turn West (Right) on to Alberta Highway 69 & follow for approximately 7.4 Kilometers. • Turn South (Left) on to Alberta Highway 63 & follow for approximately 45 Kilometers. Look for Sand Tiger sign. • Turn North (Right) on to Access Road after sign at KM Marker 196 & follow for approximately 330 meters. • Turn West (Left) into Entrance Gate. -

Functional Planning Report Shaganappi Trail, Sarcee Trail NW
TABLE OF CONTENTS PREFACE ii LIST OF EXHIBITS iv INTRODUCTION SUMMARY AND RECOMMENDATIONS 3 GENERAL 5 Scope 5 Study Area 5 TRAFFIC 6 Relationship to CALTS Report 6 Traffic Volume Analysis in the Study Area 7 Design Hour Volumes 7 Traffic Diversion 7 Anticipated High Density Generators 8 Service Level and Lane Requirements 8 DESCRIPTION OF RECOMMENDED PLAN 9 Stage 1 9 Stage 2 10 Stage 3 12 ADJACENT LAND USE AND LOCAL ACCESS 15 TRANSIT CONSIDERATIONS 19 PEDESTRIAN ACCOMMODATION AND CONTROL 21 AESTHETIC CONSIDERATIONS 23 Integration with Environment 23 Horizontal and Vertical Alignment 24 Basic Grading 25 Structures 25 Landscaping 26 COST ESTIMATES 27 STAGE 1 COST SUMMARY 29 STAGE 2 COST SUMMARY 29 STAGE.3 COST SUMMARY 30 TOTAL COST ESTIMATE SUMMARY 31 iii LIST OF EXHIBITS 1. Key Plan - Stage 1 2. Key Plan - Stage 3 3. 1986 Traffic Volumes - Graphical 4. 1986 Traffic Volumes - Dagrammatic 5. 1986 Traffic Volumes - Dagrammatic 6. Stage 1 Plan· Sarcee Trail to South of 80th Avenue N.W. 7. Stage 1 Profile - Sarcee Trail to South of 80th Avenue N.W. 8. Stage 1 Plan - South of 80th Avenue N.W. to Varsity Drive 9. Stage 1 Profile - South of 80th Avenue N.W. to Crowchild Trail 10. Stage 1 Plan - Varsity Drive to South of 32nd Avenue NW. 11. Stage 1 Profile - Crowchild Trail to South of 32nd Avenue N.W. 12. Stage 1 Plan - South of 32nd Avenue N.W. to 3rd Avenue N.W. 13. Stage 1 Profile - South cf 32nd Avenue N.W. to 3rd Avenue N.W. -

Ledcor Goes Anywhere Our Clients Need Us, Discovering New Opportunities and New Ways to Support Their Success Along the Way
LEDCOR EARNS GROWING OUR REDEVELOPING EXPANDING OUR SUNCOR OPERATIONAL PRESENCE IN SAN DieGO’S AVIATION SERVICES IN EXCELLENCE AWARD SASKATCHEWAN WATERFRONT NORTHERN CANADA THEGLOBE SPRING 2013 VOLUME ELEVEN – ISSUE ONE INVESTING IN NORTH AMERICA Ledcor GOES ANYWHERE OUR CLIENTS NEED US, discovering NEW OPPORTUNITIES AND NEW waYS to SUPPORT THEIR SUCCESS ALONG THE waY. Ledcor’s first out-of-province project was in 1957, when we entered Saskatchewan for our client, Texaco, now owned by Chevron. We were in a position to bring our construction services to the oil market, and within six months our team was doing 90 percent of the oil field work in the province for several clients. Fifty-five years later, we are still expanding across North America, travelling with clients to new markets, opening new offices, and entering new business ventures wherever we find opportunity. We bring our corporate standards to every new market, but always invest in local talent and suppliers. This approach is important to our growth strategy and provides stability to the company in the form of a more diverse, more resilient portfolio. In this issue of The Globe, you will learn about some of the projects and businesses that have taken us to new territories and helped our company and clients continue to grow. Sincerely, Dave Lede Chairman & CEO FIREBAG STAGE 4 17 WOOD CANTS FOR ASIAN 2 MARKETS 20 LEDCOR INVESTS IN NORTH AMERICA 8 BUILDING 20 forestrY Ruocco Park Wood Cants for Asian Markets Marciano Winery 21 transportation Ritchie Bros. Auction Facility Ledcor -

Changes to Alberta's Highway System Between 2003
Changes to Alberta’s Highway System between 2003 and 2005 According to the Official Alberta Road Map Series Twinning 1. Highway #2 (Deerfoot Trail) twinned extension constructed from Highway #22X in Calgary to the former Highway #2, now Highway #2A, at De Winton (see M-5). 2. Highway #43 twinned from Highway #658 near Blue Ridge to Little Paddle River between Green Court and Mayerthorpe (see I-4). 3. Highway #43 twinned from northwest of Fox Creek near Iosegun Lake to south of Little Smoky (see H-3). New Interchanges 1. Highway #2 interchange where the Deerfoot Trail twinned extension meets the old Highway #2, now Highway #2A near De Winton (see M-5). 2. Highway #2 interchange south of Highway #54 at Innisfail added despite not being opened to date (see K-5). 3. Highway #2 interchange between Highway #19 and Highway #39 at Leduc despite being in service for years (see J-6). Primary Highway Paving 1. Highway #25 paved from Highway #521 north of Turin to Highway #526 west of Enchant (see N-6). Secondary Highway Paving 1. Highway #529 paved from Highway #2 between Parkland and Stavely to north of Little Bow River enroute to Highway #23 near Champion (see M-6 and N-6). 2. Highway #866 paved from Highway #9 at Cereal to south of Highway #570 enroute to Buffalo (see l-8). 3. Highway # 791 paved from Highway #581 west of Carstairs to south of Highway #575 west of Acme (see L-5). 4. Highway #827 paved from Highway #663 west of Colinton to north of Highway #661 at Pine Creek (see H-6).