An Integrative, Multi-Omics Approach Towards the Prioritization Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
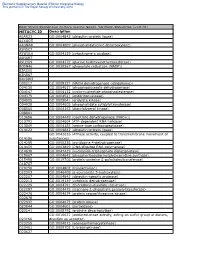
METACYC ID Description A0AR23 GO:0004842 (Ubiquitin-Protein Ligase
Electronic Supplementary Material (ESI) for Integrative Biology This journal is © The Royal Society of Chemistry 2012 Heat Stress Responsive Zostera marina Genes, Southern Population (α=0. -

Gene Symbol Gene Description ACVR1B Activin a Receptor, Type IB
Table S1. Kinase clones included in human kinase cDNA library for yeast two-hybrid screening Gene Symbol Gene Description ACVR1B activin A receptor, type IB ADCK2 aarF domain containing kinase 2 ADCK4 aarF domain containing kinase 4 AGK multiple substrate lipid kinase;MULK AK1 adenylate kinase 1 AK3 adenylate kinase 3 like 1 AK3L1 adenylate kinase 3 ALDH18A1 aldehyde dehydrogenase 18 family, member A1;ALDH18A1 ALK anaplastic lymphoma kinase (Ki-1) ALPK1 alpha-kinase 1 ALPK2 alpha-kinase 2 AMHR2 anti-Mullerian hormone receptor, type II ARAF v-raf murine sarcoma 3611 viral oncogene homolog 1 ARSG arylsulfatase G;ARSG AURKB aurora kinase B AURKC aurora kinase C BCKDK branched chain alpha-ketoacid dehydrogenase kinase BMPR1A bone morphogenetic protein receptor, type IA BMPR2 bone morphogenetic protein receptor, type II (serine/threonine kinase) BRAF v-raf murine sarcoma viral oncogene homolog B1 BRD3 bromodomain containing 3 BRD4 bromodomain containing 4 BTK Bruton agammaglobulinemia tyrosine kinase BUB1 BUB1 budding uninhibited by benzimidazoles 1 homolog (yeast) BUB1B BUB1 budding uninhibited by benzimidazoles 1 homolog beta (yeast) C9orf98 chromosome 9 open reading frame 98;C9orf98 CABC1 chaperone, ABC1 activity of bc1 complex like (S. pombe) CALM1 calmodulin 1 (phosphorylase kinase, delta) CALM2 calmodulin 2 (phosphorylase kinase, delta) CALM3 calmodulin 3 (phosphorylase kinase, delta) CAMK1 calcium/calmodulin-dependent protein kinase I CAMK2A calcium/calmodulin-dependent protein kinase (CaM kinase) II alpha CAMK2B calcium/calmodulin-dependent -

Medical Review(S) Clinical Review
CENTER FOR DRUG EVALUATION AND RESEARCH APPLICATION NUMBER: 200327 MEDICAL REVIEW(S) CLINICAL REVIEW Application Type NDA Application Number(s) 200327 Priority or Standard Standard Submit Date(s) December 29, 2009 Received Date(s) December 30, 2009 PDUFA Goal Date October 30, 2010 Division / Office Division of Anti-Infective and Ophthalmology Products Office of Antimicrobial Products Reviewer Name(s) Ariel Ramirez Porcalla, MD, MPH Neil Rellosa, MD Review Completion October 29, 2010 Date Established Name Ceftaroline fosamil for injection (Proposed) Trade Name Teflaro Therapeutic Class Cephalosporin; ß-lactams Applicant Cerexa, Inc. Forest Laboratories, Inc. Formulation(s) 400 mg/vial and 600 mg/vial Intravenous Dosing Regimen 600 mg every 12 hours by IV infusion Indication(s) Acute Bacterial Skin and Skin Structure Infection (ABSSSI); Community-acquired Bacterial Pneumonia (CABP) Intended Population(s) Adults ≥ 18 years of age Template Version: March 6, 2009 Reference ID: 2857265 Clinical Review Ariel Ramirez Porcalla, MD, MPH Neil Rellosa, MD NDA 200327: Teflaro (ceftaroline fosamil) Table of Contents 1 RECOMMENDATIONS/RISK BENEFIT ASSESSMENT ......................................... 9 1.1 Recommendation on Regulatory Action ........................................................... 10 1.2 Risk Benefit Assessment.................................................................................. 10 1.3 Recommendations for Postmarketing Risk Evaluation and Mitigation Strategies ........................................................................................................................ -

General Items
Essential Medicines List (EML) 2019 Application for the inclusion of imipenem/cilastatin, meropenem and amoxicillin/clavulanic acid in the WHO Model List of Essential Medicines, as reserve second-line drugs for the treatment of multidrug-resistant tuberculosis (complementary lists of anti-tuberculosis drugs for use in adults and children) General items 1. Summary statement of the proposal for inclusion, change or deletion This application concerns the updating of the forthcoming WHO Model List of Essential Medicines (EML) and WHO Model List of Essential Medicines for Children (EMLc) to include the following medicines: 1) Imipenem/cilastatin (Imp-Cln) to the main list but NOT the children’s list (it is already mentioned on both lists as an option in section 6.2.1 Beta Lactam medicines) 2) Meropenem (Mpm) to both the main and the children’s lists (it is already on the list as treatment for meningitis in section 6.2.1 Beta Lactam medicines) 3) Clavulanic acid to both the main and the children’s lists (it is already listed as amoxicillin/clavulanic acid (Amx-Clv), the only commercially available preparation of clavulanic acid, in section 6.2.1 Beta Lactam medicines) This application makes reference to amendments recommended in particular to section 6.2.4 Antituberculosis medicines in the latest editions of both the main EML (20th list) and the EMLc (6th list) released in 2017 (1),(2). On the basis of the most recent Guideline Development Group advising WHO on the revision of its guidelines for the treatment of multidrug- or rifampicin-resistant (MDR/RR-TB)(3), the applicant considers that the three agents concerned be viewed as essential medicines for these forms of TB in countries. -

Structure of a Penicillin Binding Protein Complexed with a Cephalosporin-Peptidoglycan Mimic M.A
Structure of a Penicillin Binding Protein Complexed with a Cephalosporin-Peptidoglycan Mimic M.A. McDonough1, W. Lee2, N.R. Silvaggi1, L.P. Kotra 2, Z-H. Li2, Y. Takeda2, S .O. Mobashery2, and J.A. Kelly1 1Department of Molecular and Cell Biology and Institute for Materials Science, Univ. of Connecticut, Storrs, CT 2Institute for Drug Design and the Department of Chemistry, Wayne State Univ., Detroit, MI Many bacteria that are responsible for causing dis- lactams. Also, one questions why ß-lactamases hydro- eases in humans are rapidly developing mutant strains lyze ß-lactams and release them rapidly but they do resistant to existing antibiotics. Proliferation of these not react with peptide substrates. mutant strains is likely to be a serious health-care prob- To help answer these questions, structural studies lem of increasing proportions. Almost sixty percent of of the Streptomyces sp. R61 D-Ala-D-Ala-peptidase all clinically used antibiotics are beta-lactams, which have been undertaken to investigate how the enzyme stop the growth of bacteria by interfering with their cell- wall biosynthesis. The cell walls are made of glycan chains that polymerize to form a structure that gives strength and shape to the bacteria. An understanding of the process how the cell wall is synthesized may help in designing more potent antibiotics. D-Ala-D-Ala-carboxypeptidase/transpeptidases (DD-peptidases) are penicillin-binding proteins (PBPs), the targets of ß-lactam antibiotics such as penicillins and cephalosporins (Figure 1A). These enzymes cata- lyze the final cross-linking step of bacterial cell wall bio- synthesis. In vivo inhibition of PBPs by ß-lactams re- sults in the cessation of bacterial growth. -

35 Disorders of Purine and Pyrimidine Metabolism
35 Disorders of Purine and Pyrimidine Metabolism Georges van den Berghe, M.- Françoise Vincent, Sandrine Marie 35.1 Inborn Errors of Purine Metabolism – 435 35.1.1 Phosphoribosyl Pyrophosphate Synthetase Superactivity – 435 35.1.2 Adenylosuccinase Deficiency – 436 35.1.3 AICA-Ribosiduria – 437 35.1.4 Muscle AMP Deaminase Deficiency – 437 35.1.5 Adenosine Deaminase Deficiency – 438 35.1.6 Adenosine Deaminase Superactivity – 439 35.1.7 Purine Nucleoside Phosphorylase Deficiency – 440 35.1.8 Xanthine Oxidase Deficiency – 440 35.1.9 Hypoxanthine-Guanine Phosphoribosyltransferase Deficiency – 441 35.1.10 Adenine Phosphoribosyltransferase Deficiency – 442 35.1.11 Deoxyguanosine Kinase Deficiency – 442 35.2 Inborn Errors of Pyrimidine Metabolism – 445 35.2.1 UMP Synthase Deficiency (Hereditary Orotic Aciduria) – 445 35.2.2 Dihydropyrimidine Dehydrogenase Deficiency – 445 35.2.3 Dihydropyrimidinase Deficiency – 446 35.2.4 Ureidopropionase Deficiency – 446 35.2.5 Pyrimidine 5’-Nucleotidase Deficiency – 446 35.2.6 Cytosolic 5’-Nucleotidase Superactivity – 447 35.2.7 Thymidine Phosphorylase Deficiency – 447 35.2.8 Thymidine Kinase Deficiency – 447 References – 447 434 Chapter 35 · Disorders of Purine and Pyrimidine Metabolism Purine Metabolism Purine nucleotides are essential cellular constituents 4 The catabolic pathway starts from GMP, IMP and which intervene in energy transfer, metabolic regula- AMP, and produces uric acid, a poorly soluble tion, and synthesis of DNA and RNA. Purine metabo- compound, which tends to crystallize once its lism can be divided into three pathways: plasma concentration surpasses 6.5–7 mg/dl (0.38– 4 The biosynthetic pathway, often termed de novo, 0.47 mmol/l). starts with the formation of phosphoribosyl pyro- 4 The salvage pathway utilizes the purine bases, gua- phosphate (PRPP) and leads to the synthesis of nine, hypoxanthine and adenine, which are pro- inosine monophosphate (IMP). -

Mapping Active Site Residues in Glutamate-5-Kinase. the Substrate Glutamate and the Feed-Back Inhibitor Proline Bind at Overlapping Sites
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector FEBS Letters 580 (2006) 6247–6253 Mapping active site residues in glutamate-5-kinase. The substrate glutamate and the feed-back inhibitor proline bind at overlapping sites Isabel Pe´rez-Arellanoa, Vicente Rubiob, Javier Cerveraa,* a Centro de Investigacio´n Prı´ncipe Felipe, Avda. Autopista del Saler, 16, Valencia 46013, Spain b Instituto de Biomedicina de Valencia (IBV-CSIC), Jaime Roig 11, Valencia 46010, Spain Received 22 August 2006; revised 10 October 2006; accepted 12 October 2006 Available online 20 October 2006 Edited by Stuart Ferguson (a domain named after pseudo uridine synthases and archaeo- Abstract Glutamate-5-kinase (G5K) catalyzes the controlling first step of proline biosynthesis. Substrate binding, catalysis sine-specific transglycosylases) domain [10]. AAK domains and feed-back inhibition by proline are functions of the N-termi- bind ATP and a phosphorylatable acidic substrate, and make nal 260-residue domain of G5K. We study here the impact on a phosphoric anhydride [11]. The function of the PUA domain these functions of 14 site-directed mutations affecting 9 residues (a domain characteristically found in some RNA-modifying of Escherichia coli G5K, chosen on the basis of the structure of enzymes) [12] is not known. By deleting the PUA domain of the bisubstrate complex of the homologous enzyme acetylgluta- E. coli G5K we showed [10] that the isolated AAK domain, mate kinase (NAGK). The results support the predicted roles as the complete enzyme, forms tetramers, catalyzes the reac- of K10, K217 and T169 in catalysis and ATP binding and of tion and is feed-back inhibited by proline. -

(12) Patent Application Publication (10) Pub. No.: US 2014/0155567 A1 Burk Et Al
US 2014O155567A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2014/0155567 A1 Burk et al. (43) Pub. Date: Jun. 5, 2014 (54) MICROORGANISMS AND METHODS FOR (60) Provisional application No. 61/331,812, filed on May THE BIOSYNTHESIS OF BUTADENE 5, 2010. (71) Applicant: Genomatica, Inc., San Diego, CA (US) Publication Classification (72) Inventors: Mark J. Burk, San Diego, CA (US); (51) Int. Cl. Anthony P. Burgard, Bellefonte, PA CI2P 5/02 (2006.01) (US); Jun Sun, San Diego, CA (US); CSF 36/06 (2006.01) Robin E. Osterhout, San Diego, CA CD7C II/6 (2006.01) (US); Priti Pharkya, San Diego, CA (52) U.S. Cl. (US) CPC ................. CI2P5/026 (2013.01); C07C II/I6 (2013.01); C08F 136/06 (2013.01) (73) Assignee: Genomatica, Inc., San Diego, CA (US) USPC ... 526/335; 435/252.3:435/167; 435/254.2: (21) Appl. No.: 14/059,131 435/254.11: 435/252.33: 435/254.21:585/16 (22) Filed: Oct. 21, 2013 (57) ABSTRACT O O The invention provides non-naturally occurring microbial Related U.S. Application Data organisms having a butadiene pathway. The invention addi (63) Continuation of application No. 13/101,046, filed on tionally provides methods of using Such organisms to produce May 4, 2011, now Pat. No. 8,580,543. butadiene. Patent Application Publication Jun. 5, 2014 Sheet 1 of 4 US 2014/O155567 A1 ?ueudos!SMS |?un61– Patent Application Publication Jun. 5, 2014 Sheet 2 of 4 US 2014/O155567 A1 VOJ OO O Z?un61– Patent Application Publication US 2014/O155567 A1 {}}} Hººso Patent Application Publication Jun. -

Yeast Genome Gazetteer P35-65
gazetteer Metabolism 35 tRNA modification mitochondrial transport amino-acid metabolism other tRNA-transcription activities vesicular transport (Golgi network, etc.) nitrogen and sulphur metabolism mRNA synthesis peroxisomal transport nucleotide metabolism mRNA processing (splicing) vacuolar transport phosphate metabolism mRNA processing (5’-end, 3’-end processing extracellular transport carbohydrate metabolism and mRNA degradation) cellular import lipid, fatty-acid and sterol metabolism other mRNA-transcription activities other intracellular-transport activities biosynthesis of vitamins, cofactors and RNA transport prosthetic groups other transcription activities Cellular organization and biogenesis 54 ionic homeostasis organization and biogenesis of cell wall and Protein synthesis 48 plasma membrane Energy 40 ribosomal proteins organization and biogenesis of glycolysis translation (initiation,elongation and cytoskeleton gluconeogenesis termination) organization and biogenesis of endoplasmic pentose-phosphate pathway translational control reticulum and Golgi tricarboxylic-acid pathway tRNA synthetases organization and biogenesis of chromosome respiration other protein-synthesis activities structure fermentation mitochondrial organization and biogenesis metabolism of energy reserves (glycogen Protein destination 49 peroxisomal organization and biogenesis and trehalose) protein folding and stabilization endosomal organization and biogenesis other energy-generation activities protein targeting, sorting and translocation vacuolar and lysosomal -

Antimicrobial Stewardship Guidance
Antimicrobial Stewardship Guidance Federal Bureau of Prisons Clinical Practice Guidelines March 2013 Clinical guidelines are made available to the public for informational purposes only. The Federal Bureau of Prisons (BOP) does not warrant these guidelines for any other purpose, and assumes no responsibility for any injury or damage resulting from the reliance thereof. Proper medical practice necessitates that all cases are evaluated on an individual basis and that treatment decisions are patient-specific. Consult the BOP Clinical Practice Guidelines Web page to determine the date of the most recent update to this document: http://www.bop.gov/news/medresources.jsp Federal Bureau of Prisons Antimicrobial Stewardship Guidance Clinical Practice Guidelines March 2013 Table of Contents 1. Purpose ............................................................................................................................................. 3 2. Introduction ...................................................................................................................................... 3 3. Antimicrobial Stewardship in the BOP............................................................................................ 4 4. General Guidance for Diagnosis and Identifying Infection ............................................................. 5 Diagnosis of Specific Infections ........................................................................................................ 6 Upper Respiratory Infections (not otherwise specified) .............................................................................. -

New Β-Lactamase Inhibitor Combinations: Options for Treatment; Challenges for Testing
MEDICAL/SCIENTIFIC AffAIRS BULLETIN New β-lactamase Inhibitor Combinations: Options for Treatment; Challenges for Testing Background The β-lactam class of antimicrobial agents has played a crucial role in the treatment of infectious diseases since the discovery of penicillin, but β–lactamases (enzymes produced by the bacteria that can hydrolyze the β-lactam core of the antibiotic) have provided an ever expanding threat to their successful use. Over a thousand β-lactamases have been described. They can be divided into classes based on their molecular structure (Classes A, B, C and D) or their function (e.g., penicillinase, oxacillinase, extended-spectrum activity, or carbapenemase activity).1 While the first approach to addressing the problem ofβ -lactamases was to develop β-lactamase stable β-lactam antibiotics, such as extended-spectrum cephalosporins, another strategy that has emerged is to combine existing β-lactam antibiotics with β-lactamase inhibitors. Key β-lactam/β-lactamase inhibitor combinations that have been used widely for over a decade include amoxicillin/clavulanic acid, ampicillin/sulbactam, and pipercillin/tazobactam. The continued use of β-lactams has been threatened by the emergence and spread of extended-spectrum β-lactamases (ESBLs) and more recently by carbapenemases. The global spread of carbapenemase-producing organisms (CPOs) including Enterobacteriaceae, Pseudomonas aeruginosa, and Acinetobacter baumannii, limits the use of all β-lactam agents, including extended-spectrum cephalosporins (e.g., cefotaxime, ceftriaxone, and ceftazidime) and the carbapenems (doripenem, ertapenem, imipenem, and meropenem). This has led to international concern and calls to action, including encouraging the development of new antimicrobial agents, enhancing infection prevention, and strengthening surveillance systems. -

Pyruvate-Phosphate Dikinase of Oxymonads and Parabasalia and the Evolution of Pyrophosphate-Dependent Glycolysis in Anaerobic Eukaryotes† Claudio H
EUKARYOTIC CELL, Jan. 2006, p. 148–154 Vol. 5, No. 1 1535-9778/06/$08.00ϩ0 doi:10.1128/EC.5.1.148–154.2006 Copyright © 2006, American Society for Microbiology. All Rights Reserved. Pyruvate-Phosphate Dikinase of Oxymonads and Parabasalia and the Evolution of Pyrophosphate-Dependent Glycolysis in Anaerobic Eukaryotes† Claudio H. Slamovits and Patrick J. Keeling* Canadian Institute for Advanced Research, Botany Department, University of British Columbia, 3529-6270 University Boulevard, Vancouver, British Columbia V6T 1Z4, Canada Received 29 September 2005/Accepted 8 November 2005 In pyrophosphate-dependent glycolysis, the ATP/ADP-dependent enzymes phosphofructokinase (PFK) and pyruvate kinase are replaced by the pyrophosphate-dependent PFK and pyruvate phosphate dikinase (PPDK), respectively. This variant of glycolysis is widespread among bacteria, but it also occurs in a few parasitic anaerobic eukaryotes such as Giardia and Entamoeba spp. We sequenced two genes for PPDK from the amitochondriate oxymonad Streblomastix strix and found evidence for PPDK in Trichomonas vaginalis and other parabasalia, where this enzyme was thought to be absent. The Streblomastix and Giardia genes may be related to one another, but those of Entamoeba and perhaps Trichomonas are distinct and more closely related to bacterial homologues. These findings suggest that pyrophosphate-dependent glycolysis is more widespread in eukaryotes than previously thought, enzymes from the pathway coexists with ATP-dependent more often than previously thought and may be spread by lateral transfer of genes for pyrophosphate-dependent enzymes from bacteria. Adaptation to anaerobic metabolism is a complex process (PPDK), respectively (for a comparison of these reactions, see involving changes to many proteins and pathways of critical reference 21).