UC Berkeley Phonlab Annual Report
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

A Different Look at the Lutsk Karaim Sound System (From the Second Half of the 19Th Century On)
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Jagiellonian Univeristy Repository Studia Linguistica Universitatis Iagellonicae Cracoviensis 128 (2011) MICHAŁ NÉMETH Jagiellonian University, Cracow A DIFFERENT LOOK AT THE LUTSK KARAIM SOUND SYSTEM (FROM THE SECOND HALF OF THE 19TH CENTURY ON) Keywords: Lutsk Karaim, Karaim phonetics and phonology, Ukrainian dialects Abstract After endeavouring to examine the grammatical descriptions published in the literature to date and to reconstruct the sound system of the south-western dialect of Karaim as it was presented in the literature, it can certainly be concluded that the matter is far from clear. This is for the simple reason that these works contradict each other at various points. The reason for such discrepancies should be sought in the historical and linguistic backgrounds of the two main centres of the south-western Karaim population, i.e. Lutsk and Halich. Even though these two centres were always in close communication with one another, and the language that was spoken in them originates beyond any doubt from one common root, they remained for centuries under slightly different linguistic influences as a result of the Slavonic languages surrounding them. The present paper aims to present and, where possible, clarify the differences which follow from the studies on the Karaim sound system we have at our disposal. An attempt is also made to identify some differences between the Lutsk and Halich subdialects of south-western Karaim, and explain their origin. Since the grammatical descriptions we are dealing with here and the written sources we are able to work with concern the end of the first half of the 19th century at the earliest, the time scale of our interest is limited to the second half of the 19th and the first four decades of the 20th century. -

Wagner 1 Dutch Fricatives Dutch Is an Indo-European Language of The
Wagner 1 Dutch Fricatives Dutch is an Indo-European language of the West Germanic branch, closely related to Frisian and English. It is spoken by about 22 million people in the Netherlands, Belgium, Aruba, Suriname, and the Netherlands Antilles, nations in which the Dutch language also has an official status. Additionally, Dutch is still spoken in parts of Indonesia as a result of colonial rule, but it has been replaced by Afrikaans in South Africa. In the Netherlands, Algemeen Nederlands is the standard form of the language taught in schools and used by the government. It is generally spoken in the western part of the country, in the provinces of Nord and Zuid Holland. The Netherlands is divided into northern and southern regions by the Rijn river and these regions correspond to the areas where the main dialects of Dutch are distinguished from each other. My consultant, Annemarie Toebosch, is from the village of Bemmel in the Netherlands. Her dialect is called Betuws Dutch because Bemmel is located in the Betuwe region between two branches of the Rijn river. Toebosch lived in the Netherlands until the age of 25 when she relocated to the United States for graduate school. Today she is a professor of linguistics at the University of Michigan-Flint and speaks only English in her professional career. For the past 18 months she has been speaking Dutch more at home with her son, but in the 9 years prior to that, she only spoke Dutch once or twice a week with her parents and other relatives who remain in the Netherlands. -

Velar Segments in Old English and Old Irish
In: Jacek Fisiak (ed.) Proceedings of the Sixth International Conference on Historical Linguistics. Amsterdam: John Benjamins, 1985, 267-79. Velar segments in Old English and Old Irish Raymond Hickey University of Bonn The purpose of this paper is to look at a section of the phoneme inventories of the oldest attested stage of English and Irish, velar segments, to see how they are manifested phonetically and to consider how they relate to each other on the phonological level. The reason I have chosen to look at two languages is that it is precisely when one compares two language systems that one notices that structural differences between languages on one level will be correlated by differences on other levels demonstrating their interrelatedness. Furthermore it is necessary to view segments on a given level in relation to other segments. The group under consideration here is just one of several groups. Velar segments viewed within the phonological system of both Old English and Old Irish cor relate with three other major groups, defined by place of articulation: palatals, dentals, and labials. The relationship between these groups is not the same in each language for reasons which are morphological: in Old Irish changes in grammatical category are frequently indicated by palatalizing a final non-palatal segment (labial, dental, or velar). The same function in Old English is fulfilled by suffixes and /or prefixes. This has meant that for Old English the phonetically natural and lower-level alternation of velar elements with palatal elements in a palatal environ ment was to be found whereas in Old Irish this alternation had been denaturalized and had lost its automatic character. -

Equivalences Between Different Phonetic Alphabets
Equivalences between different phonetic alphabets by Carlos Daniel Hern´andezMena Description IPA Mexbet X-SAMPA IPA Symbol in LATEX Voiceless bilabial plosive p p p p Voiceless dental plosive” t t t d ntextsubbridgeftg Voiceless velar plosive k k k k Voiceless palatalized plosive kj k j k j kntextsuperscriptfjg Voiced bilabial plosive b b b b Voiced bilabial approximant B VB o ntextloweringfntextbetag fl Voiced dental plosive d” d d d ntextsubbridgefdg Voiced dental fricative flD DD o ntextloweringfntextipafn;Dgg Voiced velar plosive g g g g Voiced velar fricative Èfl GG o ntextloweringfntextbabygammag Voiceless palato-alveolar affricate t“S tS tS ntextroundcapftntexteshg Voiceless labiodental fricative f f f f Voiceless alveolar fricative s s s s Voiced alveolar fricative z z z z Voiceless dental fricative” s s [ s d ntextsubbridgefsg Voiced dental fricative” z z [ z d ntextsubbridgefzg Voiceless postalveolar fricative S SS ntextesh Voiceless velar fricative x x x x Voiced palatal fricative J Z jn ntextctj Voiced postalveolar affricate d“Z dZ dZ ntextroundcapfdntextyoghg Voiced bilabial nasal m m m m Voiced alveolar nasal n n n n Voiced labiodental nasal M MF ntextltailm Voiced dental nasal n” n [ n d ntextsubbridgefng Voiced palatalized nasal nj n j n j nntextsuperscriptfjg Voiced velarized nasal nÈ N n G nntextsuperscript fntextbabygammag Voiced palatal nasal ñ n∼ J ntextltailn Voiced alveolar lateral approximant l l l l Voiced dental lateral” l l [ l d ntextsubbridgeflg Voiced palatalized lateral lj l j l j lntextsuperscriptfjg Lowered -

An Autosegmental Account of Melodic Processes in Jordanian Rural Arabic
International Journal of Applied Linguistics & English Literature E-ISSN: 2200-3592 & P-ISSN: 2200-3452 www.ijalel.aiac.org.au An Autosegmental Account of Melodic Processes in Jordanian Rural Arabic Zainab Sa’aida* Department of English, Tafila Technical University, P.O. Box 179, Tafila 66110, Jordan Corresponding Author: Zainab Sa’aida, E-mail: [email protected] ARTICLE INFO ABSTRACT Article history This study aims at providing an autosegmental account of feature spread in assimilatory situations Received: October 02, 2020 in Jordanian rural Arabic. I hypothesise that in any assimilatory situation in Jordanian rural Arabic Accepted: December 23, 2020 the undergoer assimilates a whole or a portion of the matrix of the trigger. I also hypothesise Published: January 31, 2021 that assimilation in Jordanian rural Arabic is motivated by violation of the obligatory contour Volume: 10 Issue: 1 principle on a specific tier or by spread of a feature from a trigger to a compatible undergoer. Advance access: January 2021 Data of the study were analysed in the framework of autosegmental phonology with focus on the notion of dominance in assimilation. Findings of the study have revealed that an undergoer assimilates a whole of the matrix of a trigger in the assimilation of /t/ of the detransitivizing Conflicts of interest: None prefix /Ɂɪt-/, coronal sonorant assimilation, and inter-dentalization of dentals. However, partial Funding: None assimilation occurs in the processes of nasal place assimilation, anticipatory labialization, and palatalization of plosives. Findings have revealed that assimilation occurs when the obligatory contour principle is violated on the place tier. Violation is then resolved by deletion of the place node in the leftmost matrix and by right-to-left spread of a feature from rightmost matrix to leftmost matrix. -
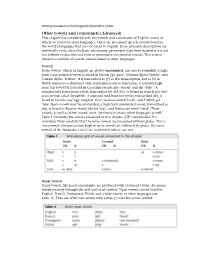
Other Vowels and Consonants (Advanced) This Chapter Has Considered Only the Vowels and Consonants of English, Many of Which Are Found in Other Languages
www.pearsoned.ca/text/ogrady/phonetics/other Other vowels and consonants (Advanced) This chapter has considered only the vowels and consonants of English, many of which are found in other languages. There are also many speech sounds found in the world’s languages that are not heard in English. Since phonetic descriptions are universally valid, once the basic articulatory parameters have been mastered it is not too difficult to describe and even to pronounce less familiar sounds. This section presents a number of speech sounds found in other languages. Vowels Front vowels, which in English are always unrounded, can also be rounded. A high front tense rounded vowel is heard in French pur ‘pure’, German Bücher ‘books’, and Turkish düg˘ me ‘button’. It is transcribed as [y] in IPA transcription, but as [ü] in North America—a difference that sometimes leads to confusion. A rounded high front lax vowel [] is heard in Canadian French lune ‘moon’ and duc ‘duke’. A rounded mid front tense vowel, transcribed [ø] (NA [ö]), is found in French peu ‘few’ and German schön ‘beautiful’. A rounded mid front lax vowel, transcribed [œ], is heard in French oeuf ‘egg’ and peur ‘fear’, German örtlich ‘local’, and Turkish göl ‘lake’. Back vowels may be unrounded; a high back unrounded vowel, transcribed as [ɯ], is heard in Russian words like byl ‘was’, and Rumanian mîna˘ ‘hand’. These vowels, as well as other ‘exotic’ ones, are found in many other languages as well. Table 1 illustrates the vowels presented in this chapter (UR = unrounded; R = rounded). Note carefully that the tense vowels are presented without glides. -

UC Berkeley Phonlab Annual Report
UC Berkeley UC Berkeley PhonLab Annual Report Title Turbulence & Phonology Permalink https://escholarship.org/uc/item/4kp306rx Journal UC Berkeley PhonLab Annual Report, 4(4) ISSN 2768-5047 Authors Ohala, John J Solé, Maria-Josep Publication Date 2008 DOI 10.5070/P74kp306rx eScholarship.org Powered by the California Digital Library University of California UC Berkeley Phonology Lab Annual Report (2008) Turbulence & Phonology John J. Ohala* & Maria-Josep Solé # *Department of Linguistics, University of California, Berkeley [email protected] #Department of English, Universitat Autònoma de Barcelona, Spain [email protected] In this paper we aim to provide an account of some of the phonological patterns involving turbulent sounds, summarizing material we have published previously and results from other investigators. In addition, we explore the ways in which sounds pattern, combine, and evolve in language and how these patterns can be derived from a few physical and perceptual principles which are independent from language itself (Lindblom 1984, 1990a) and which can be empirically verified (Ohala and Jaeger 1986). This approach should be contrasted with that of mainstream phonological theory (i.e., phonological theory within generative linguistics) which primarily considers sound structure as motivated by ‘formal’ principles or constraints that are specific to language, rather than relevant to other physical or cognitive domains. For this reason, the title of this paper is meant to be ambiguous. The primary sense of it refers to sound patterns in languages involving sounds with turbulence, e.g., fricatives and stops bursts, but a secondary meaning is the metaphorical turbulence in the practice of phonology over the past several decades. -

The Case of Classical Arabic and Biblical Hebrew
LUBLIN STUDIES IN MODERN LANGUAGES AND LITERATURE, 42(1), 2018, HTTP :// LSMLL .JOURNALS .UMCS .PL Bartosz Pietrzak Jagiellonian University Al. Mickiewicza 3 31-120 Krakow, Poland Rhotic Phonemes in Semitic Languages – The Case of Classical Arabic and Biblical Hebrew ABSTRACT Classical Arabic and Biblical Hebrew represent two opposite directions of the development of Proto-Semitic phonological system. This also refers to the rhotic phonemes /r/ and / ġ/. The comparison of the situation of their respective allophones portrays a different fate of these phonemes in Semitic languages in general. The comparison is based mostly on the description provided by Semitic languages researchers, including the medieval Arabic grammarian Sibawayh. Additionally, it takes into consideration the results of a statistical analysis on the situation of the phoneme / ġ/ in Biblical Hebrew. Keywords: rhotic phonemes; Semitic languages; Hebrew 1. Introduction The phonological systems of Classical Arabic and Biblical Hebrew represent two opposite directions of development of Semitic languages. The first one was a lingua franca of secluded nomadic tribes, which dwelled in the Arabian deserts before Islam, and as a result, was utterly conservative in respect to any change (al-Ğanābī 1981: 14, 23-24). The other was spoken by a society, which lived at the crossroads between Asia, Africa and Europe and as such DOI: 10.17951/lsmll.2018.42.1.33 34 Bartosz Pietrzak underwent significant evolution (Kutscher 1982: 1-2). The two systems are in fact two extreme points of the spectrum of phonological changes present in the Semitic languages. Therefore, their comparison presents the whole range of phenomena, which occurred in the phonological history of the Semitic language family. -

Seville Pronunciation: the Phonetics and Phonology of 'Aspirated S'
University of Calgary PRISM: University of Calgary's Digital Repository Calgary (Working) Papers in Linguistics Volume 13, Fall 1987 1987-09 Seville pronunciation: the phonetics and phonology of 'aspirated S' Izzo, Herbert J University of Calgary Izzo, H. J. (1987). Seville pronunciation: the phonetics and phonology of 'aspirated S'. Calgary Working Papers in Linguistics, 13(Fall), 15-26. http://hdl.handle.net/1880/51344 journal article Downloaded from PRISM: https://prism.ucalgary.ca Seville Pronunciation: The Phonetics and Phonology or ·Aspirated S.' Herbert J. Izzo Department of Linguistics University of Calgary It is generally assumed that the phonology of Andalusian (and therefore of Sevillian) Spanish is readily derivable from that of standard Castllian by the application of a few simple rules:I ( 1 ) the distinction between Isl and 191 is lost: 191 -> Isl ~ 's-using' or. in part of the region. Isl -> 191 ·~ '&-using;' (2) the distinction between lyl and If.I is lost: If.I-> lyl; (3) final Isl is 'aspirated': Isl-> lhl I_ [+cons] # My investigations in the Province of Seville. carried out in 1981 and 1983. have shown not only that the above rules are oversimplifications, but also that there are additional differences that cannot be accounted for by strictly phonological rules. As a basis of comparison. so that it can be seen how deviant the consonant system of SeviJJe Spanish really is. I should like to review briefly the consonants of Standard Spanish, i.e., the upper-class urban speech of Old and New CastiJe.2 Standard Spanish has three voiceless stops: Ip, t. k/, which are normally unaspirated. -
![UKRAINIAN CONSONANT PHONES in the IPA CONTEXT with SPECIAL REFERENCE to /V/ and /Gh/[*] Maksym O](https://docslib.b-cdn.net/cover/4501/ukrainian-consonant-phones-in-the-ipa-context-with-special-reference-to-v-and-gh-maksym-o-2854501.webp)
UKRAINIAN CONSONANT PHONES in the IPA CONTEXT with SPECIAL REFERENCE to /V/ and /Gh/[*] Maksym O
Linguistica ONLINE. Issue 22. Published: August 22, 2019 http://www.phil.muni.cz/linguistica/art/vakulenko/vak-001.pdf ISSN 1801-5336 UKRAINIAN CONSONANT PHONES IN THE IPA CONTEXT WITH SPECIAL REFERENCE TO /v/ AND /gh/[*] Maksym O. Vakulenko (State Science and Technical Library of Ukraine, Ukraine, [email protected]) Abstract: The acoustic and articulatory properties of Ukrainian consonant phones were investigated, and a full set of relevant IPA notations was proposed for these and compiled in a table. Acoustic correspondence of Ukrainian phones to those appearing in European languages was analyzed and discussed. Special attention was paid to the phonemes /v/ (represented in Cyrillic script as “/в/”) and /gh/ (ren- dered in Cyrillic script as “/г/”) that cause the most difficulties in their description. In particular, our experiments and observations suggest that a standard Ukrainian phoneme /v/ is realised as labiodental fricatives [v] and [vj] before vowels and also as sonorant bilabial approximants [β̞ β̞˛ β̞ɔ] between a vowel and a consonant, in the initial position before consonants and after a vowel at the end of a word, and sometimes is devoiced to [v̥ ] in the coda after a voiceless consonant. In some ut- terances after a vowel (before a consonant and in the coda), a strongly rounded bilabial approximant [β̞ɔ] may approach a non-syllabic semivowel [ṷ]. These con- clusions are in good agreement with the consonantal status of the Ukrainian lan- guage and with the general tendencies of sound combinations in the world lan- guages. The findings of this research contribute to better understanding of Ukrain- ian and its special features in comparison with other world languages that may have substantial practical use in various phonetic and translation studies, as well as in modern linguistic technologies aimed at artificial intelligence development, machine translation incorporating text-to-speech conversion, automatic speech analysis, recognition and synthesis, and in other areas of applied linguistics. -

List of Symbols Because the International Phonetic Association
List of Symbols Because the International Phonetic Association (IPA) and its symbols and conventions are the most linguistically acceptable tool of phonetic transcription, they have been adopted in this book to transcribe both English and Spanish as well as other languages when necessary. Slight modifications in both letter symbols and diacritics are occasionally used. Below is a list of the symbols and conventions used: Vowels Phonetic Description i Close front with spread lips Close front (somewhat centralized) to close-mid with spread lips گ e Close-mid front with unrounded lips ϯ Open-mid front with unrounded lips ҷ Open-mid central with unrounded lips a Open front with unrounded lips э Near-open central vowel æ Near-open front with unrounded lips Ϫ Open back with unrounded lips Ҳ Open back with rounded lips o Close-mid back with rounded lips ѐ Open-mid back with rounded lips u Close back with rounded lips Ѩ Near-close near-back with rounded lips ѩ Open-mid back with unrounded lips ђ Mid central (neutral) vowel (schwa) ɚ R-colored (rhotacized) mid central (schwar) ɝ R-colored (rhotacized) open-mid central Diphthongs au as in <how, now> ai as in <high, tie> oi as in <boy, noise> ou; o as in <go, know> ei; e as in <bait, gate> i; iɚ as in <here, dear> e; eɚ as in <there, bear> u; uɚ as in <poor, tour> x Consonants Phonetic Description b Voiced bilabial plosive p Voiceless unaspirated bilabial plosive p Voiceless aspirated bilabial plosive d Voiced alveolar plosive t Voiceless unaspirated alveolar plosive t Voiceless aspirated alveolar -

ARTICULATORY EVIDENCES for the EXISTENCE of the SOFT-G PHONEME from the ORKHON MONUMENTS to the MODERN STANDARD TURKISH
ARTICULATORY EVIDENCES FOR THE EXISTENCE OF THE SOFT-g PHONEME FROM THE ORKHON MONUMENTS TO THE MODERN STANDARD TURKISH Mehmet DEMIREZEN Abstract The existence of the soft-g phoneme as a voiced velar fricative in Turkish is a matter of heated discussion. Some language scientists insist that there is no such phoneme like soft-g in Turkish, and then claim that the letter ğ only compensatorily lengthens the vowels that take place before it. The application of the current phonemic analysis techniques on the words that have the soft-g indicate the fact that it has been in existence since the time of Orkhon Monuments. In this study, the existence of the soft-g phoneme, from the 8th to 13th centuries, will be analyzed by the application of such phonemic analysis techniques like minimal pairs, contrastiveness, and free variation. The current status of this phoneme in modern standard Turkish will also be investigated. Key words: voiced velar fricative, phonemic analysis, minimal pairs, contrastiveness, free variation. Ötümlü Gırtlaksıl Sızıcı –g Sesbiriminin Türkçede Orhon Anıtlarından Beri Varlığına Kanıtlar Özet Türkçede yumuşak-g olarak ötümlü gırtlaksal sızıcının bir sesbirim olarak varlığı bir tartışma konusudur. Bazı bilim adamları bu sesbirimin Türkçede olmadığını iddia etmekte, ğ harfinin sadece bir önceki ünlüyü uzattığını ileri sürmektedir. Çağdaş sesbiliminin sesbirim çözümlemesi tekniklerinin içinde ğ harfinin geçtiği sözcüklere uygulanması, yumuşak-g sesbiriminin aslında Türkçede Orhon Anıtlarının zamanından beri var olduğununa işaret etmektedir. Bu araştırmada, sesbirim çözümlemesinin en küçük çift, sesbirimsel kıyaslama ve serbest değişim gibi teknikleri yoluyla, yumuşak-g sesbirimin varlığı veya yokluğu 8. yüzyıldan 13. yüzyıla kadar incelenecek, çağdaş Türkçedeki konumu saptanacaktır.