Modeling and Optimization of Extracellular Polysaccharides Production by Enterobacter A47
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Postulated Physiological Roles of the Seven-Carbon Sugars, Mannoheptulose, and Perseitol in Avocado
J. AMER. SOC. HORT. SCI. 127(1):108–114. 2002. Postulated Physiological Roles of the Seven-carbon Sugars, Mannoheptulose, and Perseitol in Avocado Xuan Liu,1 James Sievert, Mary Lu Arpaia, and Monica A. Madore2 Department of Botany and Plant Sciences, University of California, Riverside, CA 92521 ADDITIONAL INDEX WORDS. ‘Hass’ avocado on ‘Duke 7’ rootstock, phloem transport, ripening, Lauraceae ABSTRACT. Avocado (Persea americana Mill.) tissues contain high levels of the seven-carbon (C7) ketosugar mannoheptulose and its polyol form, perseitol. Radiolabeling of intact leaves of ‘Hass’ avocado on ‘Duke 7’ rootstock indicated that both perseitol and mannoheptulose are not only primary products of photosynthetic CO2 fixation but are also exported in the phloem. In cell-free extracts from mature source leaves, formation of the C7 backbone occurred by condensation of a three-carbon metabolite (dihydroxyacetone-P) with a four-carbon metabolite (erythrose-4-P) to form sedoheptulose-1,7- bis-P, followed by isomerization to a phosphorylated D-mannoheptulose derivative. A transketolase reaction was also observed which converted five-carbon metabolites (ribose-5-P and xylulose-5-P) to form the C7 metabolite, sedoheptu- lose-7-P, but this compound was not metabolized further to mannoheptulose. This suggests that C7 sugars are formed from the Calvin Cycle, not oxidative pentose phosphate pathway, reactions in avocado leaves. In avocado fruit, C7 sugars were present in substantial quantities and the normal ripening processes (fruit softening, ethylene production, and climacteric respiration rise), which occurs several days after the fruit is picked, did not occur until levels of C7 sugars dropped below an apparent threshold concentration of ≈20 mg·g–1 fresh weight. -

PENTOSE PHOSPHATE PATHWAY — Restricted for Students Enrolled in MCB102, UC Berkeley, Spring 2008 ONLY
Metabolism Lecture 5 — PENTOSE PHOSPHATE PATHWAY — Restricted for students enrolled in MCB102, UC Berkeley, Spring 2008 ONLY Bryan Krantz: University of California, Berkeley MCB 102, Spring 2008, Metabolism Lecture 5 Reading: Ch. 14 of Principles of Biochemistry, “Glycolysis, Gluconeogenesis, & Pentose Phosphate Pathway.” PENTOSE PHOSPHATE PATHWAY This pathway produces ribose from glucose, and it also generates 2 NADPH. Two Phases: [1] Oxidative Phase & [2] Non-oxidative Phase + + Glucose 6-Phosphate + 2 NADP + H2O Ribose 5-Phosphate + 2 NADPH + CO2 + 2H ● What are pentoses? Why do we need them? ◦ DNA & RNA ◦ Cofactors in enzymes ● Where do we get them? Diet and from glucose (and other sugars) via the Pentose Phosphate Pathway. ● Is the Pentose Phosphate Pathway just about making ribose sugars from glucose? (1) Important for biosynthetic pathways using NADPH, and (2) a high cytosolic reducing potential from NADPH is sometimes required to advert oxidative damage by radicals, e.g., ● - ● O2 and H—O Metabolism Lecture 5 — PENTOSE PHOSPHATE PATHWAY — Restricted for students enrolled in MCB102, UC Berkeley, Spring 2008 ONLY Two Phases of the Pentose Pathway Metabolism Lecture 5 — PENTOSE PHOSPHATE PATHWAY — Restricted for students enrolled in MCB102, UC Berkeley, Spring 2008 ONLY NADPH vs. NADH Metabolism Lecture 5 — PENTOSE PHOSPHATE PATHWAY — Restricted for students enrolled in MCB102, UC Berkeley, Spring 2008 ONLY Oxidative Phase: Glucose-6-P Ribose-5-P Glucose 6-phosphate dehydrogenase. First enzymatic step in oxidative phase, converting NADP+ to NADPH. Glucose 6-phosphate + NADP+ 6-Phosphoglucono-δ-lactone + NADPH + H+ Mechanism. Oxidation reaction of C1 position. Hydride transfer to the NADP+, forming a lactone, which is an intra-molecular ester. -

Sedoheptulose in Photosynthesis by Plants
TWO-WEEK LOAN COPY This is a Library Circulating Copy which may be borrowed for two weeks. For a personal retention copy, call Tech. Info. Division, Ext. 5545 UCRW.268 Unclassified - Biology Distribution UNIVERSITY OF CALIFOmIA Radiation Laboratory Contract No. W-7405-eng-48 SEDOHEPT[JLOSE IN PHOTOSYNTHESIS BY PLANTS A. A. Benson, J. A. Bassham, and Me Calvin May 1, 1951 Berkeley, California A. A. Benson, 6. A, Bassham, and M, Calvin Radiation Laboratory and Department of Ohemistry University of Calif omia, Berkeley May 1, 1951 Although its function has not been ascertained, the general 1 occurrence of sedohep~ulose, D-altroheptuLose, in the succulent plants is well established. This sugar has not been identified in the majority of the members of the plat lringdom, but it now appears possibae that its phosphate esters may perform a vital function during photosynthesis. We haw isolated labeled sedoheptulose monopho sphate in cl% 2 photosynthesis products of all the plants thus far studied in this laboratory (~lorelh,Scenedesmus, Rhodospfr5.llyn rubn~,and the leaves of barley seedlings, soy bean, alf~lfa,sugar beet, spinach and geranium). It is invariably found as monophosphate esters. At least two such esters have been observed in radiograms of C1'-labeled Scenedesmus. The mjor one is associated with fructose monophosphztte while the minor one is inseparable, as yet, from glucose monophosphate. Sedoheptulose may be liberated e~zymticallyfrom its phosphates during the lrilling of the plan-i;,'but it has not been observed to accwnulate In amounts exceeding tbe steady state concentrations of -these phosphates. .--LL- * This work was sponsored bp the United States Atomic Energy Cormnission, -- This suggests its participation only as a phosphate in most plznts. -
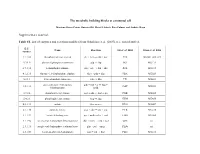
The Metabolic Building Blocks of a Minimal Cell Supplementary
The metabolic building blocks of a minimal cell Mariana Reyes-Prieto, Rosario Gil, Mercè Llabrés, Pere Palmer and Andrés Moya Supplementary material. Table S1. List of enzymes and reactions modified from Gabaldon et. al. (2007). n.i.: non identified. E.C. Name Reaction Gil et. al. 2004 Glass et. al. 2006 number 2.7.1.69 phosphotransferase system glc + pep → g6p + pyr PTS MG041, 069, 429 5.3.1.9 glucose-6-phosphate isomerase g6p ↔ f6p PGI MG111 2.7.1.11 6-phosphofructokinase f6p + atp → fbp + adp PFK MG215 4.1.2.13 fructose-1,6-bisphosphate aldolase fbp ↔ gdp + dhp FBA MG023 5.3.1.1 triose-phosphate isomerase gdp ↔ dhp TPI MG431 glyceraldehyde-3-phosphate gdp + nad + p ↔ bpg + 1.2.1.12 GAP MG301 dehydrogenase nadh 2.7.2.3 phosphoglycerate kinase bpg + adp ↔ 3pg + atp PGK MG300 5.4.2.1 phosphoglycerate mutase 3pg ↔ 2pg GPM MG430 4.2.1.11 enolase 2pg ↔ pep ENO MG407 2.7.1.40 pyruvate kinase pep + adp → pyr + atp PYK MG216 1.1.1.27 lactate dehydrogenase pyr + nadh ↔ lac + nad LDH MG460 1.1.1.94 sn-glycerol-3-phosphate dehydrogenase dhp + nadh → g3p + nad GPS n.i. 2.3.1.15 sn-glycerol-3-phosphate acyltransferase g3p + pal → mag PLSb n.i. 2.3.1.51 1-acyl-sn-glycerol-3-phosphate mag + pal → dag PLSc MG212 acyltransferase 2.7.7.41 phosphatidate cytidyltransferase dag + ctp → cdp-dag + pp CDS MG437 cdp-dag + ser → pser + 2.7.8.8 phosphatidylserine synthase PSS n.i. cmp 4.1.1.65 phosphatidylserine decarboxylase pser → peta PSD n.i. -

Ii- Carbohydrates of Biological Importance
Carbohydrates of Biological Importance 9 II- CARBOHYDRATES OF BIOLOGICAL IMPORTANCE ILOs: By the end of the course, the student should be able to: 1. Define carbohydrates and list their classification. 2. Recognize the structure and functions of monosaccharides. 3. Identify the various chemical and physical properties that distinguish monosaccharides. 4. List the important monosaccharides and their derivatives and point out their importance. 5. List the important disaccharides, recognize their structure and mention their importance. 6. Define glycosides and mention biologically important examples. 7. State examples of homopolysaccharides and describe their structure and functions. 8. Classify glycosaminoglycans, mention their constituents and their biological importance. 9. Define proteoglycans and point out their functions. 10. Differentiate between glycoproteins and proteoglycans. CONTENTS: I. Chemical Nature of Carbohydrates II. Biomedical importance of Carbohydrates III. Monosaccharides - Classification - Forms of Isomerism of monosaccharides. - Importance of monosaccharides. - Monosaccharides derivatives. IV. Disaccharides - Reducing disaccharides. - Non- Reducing disaccharides V. Oligosaccarides. VI. Polysaccarides - Homopolysaccharides - Heteropolysaccharides - Carbohydrates of Biological Importance 10 CARBOHYDRATES OF BIOLOGICAL IMPORTANCE Chemical Nature of Carbohydrates Carbohydrates are polyhydroxyalcohols with an aldehyde or keto group. They are represented with general formulae Cn(H2O)n and hence called hydrates of carbons. -

Structures and Characteristics of Carbohydrates in Diets Fed to Pigs: a Review Diego M
Navarro et al. Journal of Animal Science and Biotechnology (2019) 10:39 https://doi.org/10.1186/s40104-019-0345-6 REVIEW Open Access Structures and characteristics of carbohydrates in diets fed to pigs: a review Diego M. D. L. Navarro1, Jerubella J. Abelilla1 and Hans H. Stein1,2* Abstract The current paper reviews the content and variation of fiber fractions in feed ingredients commonly used in swine diets. Carbohydrates serve as the main source of energy in diets fed to pigs. Carbohydrates may be classified according to their degree of polymerization: monosaccharides, disaccharides, oligosaccharides, and polysaccharides. Digestible carbohydrates include sugars, digestible starch, and glycogen that may be digested by enzymes secreted in the gastrointestinal tract of the pig. Non-digestible carbohydrates, also known as fiber, may be fermented by microbial populations along the gastrointestinal tract to synthesize short-chain fatty acids that may be absorbed and metabolized by the pig. These non-digestible carbohydrates include two disaccharides, oligosaccharides, resistant starch, and non-starch polysaccharides. The concentration and structure of non-digestible carbohydrates in diets fed to pigs depend on the type of feed ingredients that are included in the mixed diet. Cellulose, arabinoxylans, and mixed linked β-(1,3) (1,4)-D-glucans are the main cell wall polysaccharides in cereal grains, but vary in proportion and structure depending on the grain and tissue within the grain. Cell walls of oilseeds, oilseed meals, and pulse crops contain cellulose, pectic polysaccharides, lignin, and xyloglucans. Pulse crops and legumes also contain significant quantities of galacto-oligosaccharides including raffinose, stachyose, and verbascose. -

Extending Enzyme Molecular Recognition with an Expanded Amino Acid Alphabet
Extending enzyme molecular recognition with an expanded amino acid alphabet Claire L. Windlea,b, Katie J. Simmonsa,c, James R. Aulta,b, Chi H. Trinha,b, Adam Nelsona,c,1, Arwen R. Pearsona,2,3, and Alan Berrya,b,1 aAstbury Centre for Structural Molecular Biology, University of Leeds, Leeds LS2 9JT, United Kingdom; bSchool of Molecular and Cellular Biology, University of Leeds, Leeds LS2 9JT, United Kingdom; and cSchool of Chemistry, University of Leeds, Leeds LS2 9JT, United Kingdom Edited by Perry Allen Frey, University of Wisconsin–Madison, Madison, WI, and approved January 20, 2017 (received for review October 26, 2016) Natural enzymes are constructed from the 20 proteogenic amino for catalysis and arise through posttranslational modifications of acids, which may then require posttranslational modification or the the polypeptide chain (21, 22), allowing access to chemistries not recruitment of coenzymes or metal ions to achieve catalytic function. otherwise provided by the 20 proteogenic amino acids. Here, we demonstrate that expansion of the alphabet of amino acids Technologies for the protein engineer to incorporate Ncas into can also enable the properties of enzymes to be extended. A proteins at specifically chosen sites, either by genetic means (23–25) chemical mutagenesis strategy allowed a wide range of noncanon- or by chemical modification (26, 27), have recently been developed. ical amino acids to be systematically incorporated throughout an These approaches are powerful because, unlike traditional protein active site to alter enzymic substrate specificity. Specifically, 13 engineering with the 20 canonical amino acids, protein engineering different noncanonical side chains were incorporated at 12 different with Ncas has almost unlimited novel side-chain structures and positions within the active site of N-acetylneuraminic acid lyase chemistries from which to choose. -

Reaction of Glucose Catalyzed by Framework and Extraframework Tin Sites in Zeolite Beta
Reaction of Glucose Catalyzed by Framework and Extraframework Tin Sites in Zeolite Beta Thesis by Ricardo Bermejo-Deval In Partial Fulfillment of the Requirements for the degree of Doctor of Philosophy CALIFORNIA INSTITUTE OF TECHNOLOGY Pasadena, California 2014 (Defended 12 May 2014) ii 2014 Ricardo Bermejo-Deval All Rights Reserved iii ACKNOWLEDGEMENTS The past years at Caltech have been one of the most challenging periods of my life, learning to be a better person and being part of the world of science. I feel privileged to have interacted with such talented and inspiring colleagues and scientists, as well as those I have disagreed with. The variety of people I have encountered and the experiences I have gathered have helped me to gain scholarship, wisdom, confidence and critical thinking, as much as to become an open-minded person to any opinion or people. First and foremost, I am very grateful to my advisor and mentor, Professor Mark E. Davis, for his financial, scientific and personal support. I appreciate his patience, flexibility, advice and scientific discussions, helping me to grow and mature scientifically. I would like to thank the thesis committee Professors Richard Flagan, Jay Labinger and Theodor Agapie, for their discussions and kindness. I appreciate everyone in the Davis group for helping me in the lab throughout these years. Special thanks to Yasho for helping me get started in the lab, to Bingjun and Raj for scientific advice, and to Marat for helpful talks. I am also very thankful to Sonjong Hwang for SS NMR, David Vandervelde for NMR and Mona Shahgholi for mass spectrometry. -

Conformational Study of the Open-Chain and Furanose Structures of D-Erythrose and D-Threose ⇑ Luis Miguel Azofra A, Ibon Alkorta A, , José Elguero A, Paul L
Carbohydrate Research 358 (2012) 96–105 Contents lists available at SciVerse ScienceDirect Carbohydrate Research journal homepage: www.elsevier.com/locate/carres Conformational study of the open-chain and furanose structures of D-erythrose and D-threose ⇑ Luis Miguel Azofra a, Ibon Alkorta a, , José Elguero a, Paul L. A. Popelier b,c a Instituto de Química Médica, CSIC, Juan de la Cierva, 3, E-28006 Madrid, Spain b Manchester Interdisciplinary Biocentre (MIB), 131 Princess Street, Manchester M1 7DN, United Kingdom c School of Chemistry, University of Manchester, Oxford Road, Manchester M13 9PL, United Kingdom article info abstract Article history: The potential energy surfaces for the different configurations of the D-erythrose and D-threose (open- Received 3 May 2012 chain, a- and b-furanoses) have been studied in order to find the most stable structures in the gas phase. Received in revised form 18 June 2012 For that purpose, a large number of initial structures were explored at B3LYP/6-31G(d) level. All the min- Accepted 19 June 2012 ima obtained at this level were compared and duplicates removed. A further reoptimization of the Available online 27 June 2012 remaining structures was carried out at B3LYP/6-311++G(d,p) level. We characterized 174 and 170 min- ima for the open-chain structures of D-erythrose and D-threose, respectively, with relative energies that Keywords: range over an interval of just over 50 kJ/mol. In the case of the furanose configurations, the number of D-Erythrose minima is smaller by approximately one to two dozen. G3B3 calculations on the most stable minima indi- D-Threose DFT cate that the a-furanose configuration is the most stable for both D-erythrose and D-threose. -

Trehalose and Carbon Partitioning in Sugarcane
TREHALOSE AND CARBON PARTITIONING IN SUGARCANE Susan Bosch Dissertation presented for the Degree of Doctor of Philosophy (Plant Biotechnology) at the University of Stellenbosch Promoter: Prof. F.C. Botha Institute for Plant Biotechnology and South African Sugar Research Institute Co-Promoter: Prof. J.M. Rohwer Department of Biochemistry December 2005 i Declaration I, the undersigned, hereby declare that the work contained in this dissertation is my own original work and that I have not previously in its entirety or in part submitted it at any university for a degree. Signature: ……………………….. Date: ……………………….. ii ABSTRACT The current understanding of the regulation of sucrose accumulation is still incomplete even though many scientists have investigated this subject. Components of trehalose metabolism have been implicated in the regulation of carbon flux in bacteria, yeast and more recently in plants. With a view to placing trehalose metabolism in the context of cytosolic sugarcane sucrose metabolism and carbon partitioning we have investigated the metabolites, transcripts and enzymes involved in this branch of carbohydrate metabolism in sugarcane internodal tissues. Sugarcane internodal trehalose levels varied between 0.31 ± 0.09 and 3.91 ± 0.99 nmol.g-1 fresh weight (FW). From statistical analysis of the metabolite profile it would appear that trehalose does not directly affect sucrose accumulation, although this does not preclude involvement of trehalose- 6-phosphate in the regulation of carbon partitioning. The metabolite data generated in this study demanded further investigation into the enzymes (and their transcripts) responsible for trehalose metabolism. Trehalose is synthesised in a two step process by the enzymes trehalose-6-phosphate synthase (EC 2.4.1.15, TPS) and trehalose-6-phosphate phosphatase (EC 3.1.3.12, TPP), and degraded by trehalase (EC 3.2.1.28). -

Nucleotide Sugars in Chemistry and Biology
molecules Review Nucleotide Sugars in Chemistry and Biology Satu Mikkola Department of Chemistry, University of Turku, 20014 Turku, Finland; satu.mikkola@utu.fi Academic Editor: David R. W. Hodgson Received: 15 November 2020; Accepted: 4 December 2020; Published: 6 December 2020 Abstract: Nucleotide sugars have essential roles in every living creature. They are the building blocks of the biosynthesis of carbohydrates and their conjugates. They are involved in processes that are targets for drug development, and their analogs are potential inhibitors of these processes. Drug development requires efficient methods for the synthesis of oligosaccharides and nucleotide sugar building blocks as well as of modified structures as potential inhibitors. It requires also understanding the details of biological and chemical processes as well as the reactivity and reactions under different conditions. This article addresses all these issues by giving a broad overview on nucleotide sugars in biological and chemical reactions. As the background for the topic, glycosylation reactions in mammalian and bacterial cells are briefly discussed. In the following sections, structures and biosynthetic routes for nucleotide sugars, as well as the mechanisms of action of nucleotide sugar-utilizing enzymes, are discussed. Chemical topics include the reactivity and chemical synthesis methods. Finally, the enzymatic in vitro synthesis of nucleotide sugars and the utilization of enzyme cascades in the synthesis of nucleotide sugars and oligosaccharides are briefly discussed. Keywords: nucleotide sugar; glycosylation; glycoconjugate; mechanism; reactivity; synthesis; chemoenzymatic synthesis 1. Introduction Nucleotide sugars consist of a monosaccharide and a nucleoside mono- or diphosphate moiety. The term often refers specifically to structures where the nucleotide is attached to the anomeric carbon of the sugar component. -

A Genetically Adaptable Strategy for Ribose Scavenging in a Human Gut Symbiont Plays a 4 Diet-Dependent Role in Colon Colonization 5 6 7 8 Robert W
1 2 3 A genetically adaptable strategy for ribose scavenging in a human gut symbiont plays a 4 diet-dependent role in colon colonization 5 6 7 8 Robert W. P. Glowacki1, Nicholas A. Pudlo1, Yunus Tuncil2,3, Ana S. Luis1, Anton I. Terekhov2, 9 Bruce R. Hamaker2 and Eric C. Martens1,# 10 11 12 13 1Department of Microbiology and Immunology, University of Michigan Medical School, Ann 14 Arbor, MI 48109 15 16 2Department of Food Science and Whistler Center for Carbohydrate Research, Purdue 17 University, West Lafayette, IN 47907 18 19 3Current location: Department of Food Engineering, Ordu University, Ordu, Turkey 20 21 22 23 Correspondence to: [email protected] 24 #Lead contact 25 26 Running Title: Bacteroides ribose utilization 27 28 29 30 31 32 33 34 35 36 37 38 Summary 39 40 Efficient nutrient acquisition in the competitive human gut is essential for microbial 41 persistence. While polysaccharides have been well-studied nutrients for the gut microbiome, 42 other resources such as co-factors and nucleic acids have been less examined. We describe a 43 series of ribose utilization systems (RUSs) that are broadly represented in Bacteroidetes and 44 appear to have diversified to allow access to ribose from a variety of substrates. One Bacteroides 45 thetaiotaomicron RUS variant is critical for competitive gut colonization in a diet-specific 46 fashion. Using molecular genetics, we probed the nature of the ribose source underlying this diet- 47 specific phenotype, revealing that hydrolytic functions in RUS (e.g., to cleave ribonucleosides) 48 are present but dispensable. Instead, ribokinases that are activated in vivo and participate in 49 cellular ribose-phosphate metabolism are essential.