Priyam Banerjee
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CERN Courier–Digital Edition
CERNMarch/April 2021 cerncourier.com COURIERReporting on international high-energy physics WELCOME CERN Courier – digital edition Welcome to the digital edition of the March/April 2021 issue of CERN Courier. Hadron colliders have contributed to a golden era of discovery in high-energy physics, hosting experiments that have enabled physicists to unearth the cornerstones of the Standard Model. This success story began 50 years ago with CERN’s Intersecting Storage Rings (featured on the cover of this issue) and culminated in the Large Hadron Collider (p38) – which has spawned thousands of papers in its first 10 years of operations alone (p47). It also bodes well for a potential future circular collider at CERN operating at a centre-of-mass energy of at least 100 TeV, a feasibility study for which is now in full swing. Even hadron colliders have their limits, however. To explore possible new physics at the highest energy scales, physicists are mounting a series of experiments to search for very weakly interacting “slim” particles that arise from extensions in the Standard Model (p25). Also celebrating a golden anniversary this year is the Institute for Nuclear Research in Moscow (p33), while, elsewhere in this issue: quantum sensors HADRON COLLIDERS target gravitational waves (p10); X-rays go behind the scenes of supernova 50 years of discovery 1987A (p12); a high-performance computing collaboration forms to handle the big-physics data onslaught (p22); Steven Weinberg talks about his latest work (p51); and much more. To sign up to the new-issue alert, please visit: http://comms.iop.org/k/iop/cerncourier To subscribe to the magazine, please visit: https://cerncourier.com/p/about-cern-courier EDITOR: MATTHEW CHALMERS, CERN DIGITAL EDITION CREATED BY IOP PUBLISHING ATLAS spots rare Higgs decay Weinberg on effective field theory Hunting for WISPs CCMarApr21_Cover_v1.indd 1 12/02/2021 09:24 CERNCOURIER www. -

REPORTS on RESEARCH PL9800669 6.1 the NA48
114 Annual Report 1996 I REPORTS ON RESEARCH PL9800669 6.1 The NA48 experiment on direct CP violation by A.Chlopik, Z.Guzik, J.Nassalski, E.Rondio, M.Szleper and W.WisIicki The NA48 experiment [1] was built and tested on the kaon beam at CERN. It aims to measure the effect of direct violation of the combined CP transformation in two-pion decays of neutral kaons with precision of 0.1 permille. To perform such a measurement beams of the long-lived and short-lived Ks are produced which decay in the common region of phase space. Decays of both kaons into charged and neutral pions are measured simultaneously. The Warsaw group contributed to the electronics of the data acquisition system, to the offline software and took part in the data taking during test runs in June and September 1996. The hardware contribution of the group consisted of design, prototype manufacturing, testing and production supervision of the data acquisition blocks: RIO Fiber Optics Links, Cluster Interconnectors and Clock Fanouts. These elements are described in a separate note of this report. We worked on the following software related issues: (i) reconstruction of data and Monte Carlo in the magnetic spectrometer consisting of four drift chambers, the bending magnet and the trigger hodoscope. Energy and momentum resolution and background sources were carefully studied, (ii) decoding and undecoding of the liquid kryptonium calorimeter data. This part of the equipment is crucial for the measurement of neutral decays, (iii) correlated Monte Carlo to use the same events to simulate KL and K^ decays and thus speed up simulation considerably. -

CERN to Seek Answers to Such Fundamental 1957, Was CERN’S First Accelerator
What is the nature of our universe? What is it ----------------------------------------- DAY 1 -------- made of? Scientists from around the world go to The 600 MeV Synchrocyclotron (SC), built in CERN to seek answers to such fundamental 1957, was CERN’s first accelerator. It provided questions using particle accelerators and pushing beams for CERN’s first experiments in particle and nuclear the limits of technology. physics. In 1964, this machine started to concentrate on nuclear physics alone, leaving particle physics to the newer During February 2019, I was given a once in a lifetime and more powerful Proton Synchrotron. opportunity to be part of The Maltese Teacher Programme at CERN, which introduced me, as one of the participants, to cutting-edge particle physics through lectures, on-site visits, exhibitions, and hands-on workshops. Why do they do all this? The main objective of these type of visits is to bring modern science into the classroom. Through this report, my purpose is to give an insight of what goes on at CERN as well as share my experience with you students, colleagues, as well as the general public. The SC became a remarkably long-lived machine. In 1967, it started supplying beams for a dedicated radioactive-ion-beam facility called ISOLDE, which still carries out research ranging from pure What does “CERN” stand for? At an nuclear physics to astrophysics and medical physics. In 1990, intergovernmental meeting of UNESCO in Paris in ISOLDE was transferred to the Proton Synchrotron Booster, and the SC closed down after 33 years of service. December 1951, the first resolution concerning the establishment of a European Council for Nuclear Research SM18 is CERN’s main facility for testing large and heavy (in French Conseil Européen pour la Recherche Nucléaire) superconducting magnets at liquid helium temperatures. -

6.2 Transition Radiation
Contents I General introduction 9 1Preamble 11 2 Relevant publications 15 3 A first look at the formation length 21 4 Formation length 23 4.1Classicalformationlength..................... 24 4.1.1 A reduced wavelength distance from the electron to the photon ........................... 25 4.1.2 Ignorance of the exact location of emission . ....... 25 4.1.3 ‘Semi-bare’ electron . ................... 26 4.1.4 Field line picture of radiation . ............... 26 4.2Quantumformationlength..................... 28 II Interactions in amorphous targets 31 5 Bremsstrahlung 33 5.1Incoherentbremsstrahlung..................... 33 5.2Genericexperimentalsetup..................... 35 5.2.1 Detectors employed . ................... 35 5.3Expandedexperimentalsetup.................... 39 6 Landau-Pomeranchuk-Migdal (LPM) effect 47 6.1 Formation length and LPM effect.................. 48 6.2 Transition radiation . ....................... 52 6.3 Dielectric suppression - the Ter-Mikaelian effect.......... 54 6.4CERNLPMExperiment...................... 55 6.5Resultsanddiscussion....................... 55 3 4 CONTENTS 6.5.1 Determination of ELPM ................... 56 6.5.2 Suppression and possible compensation . ........ 59 7 Very thin targets 61 7.1Theory................................ 62 7.1.1 Multiple scattering dominated transition radiation . .... 62 7.2MSDTRExperiment........................ 63 7.3Results................................ 64 8 Ternovskii-Shul’ga-Fomin (TSF) effect 67 8.1Theory................................ 67 8.1.1 Logarithmic thickness dependence -

Beam–Material Interactions
Beam–Material Interactions N.V. Mokhov1 and F. Cerutti2 1Fermilab, Batavia, IL 60510, USA 2CERN, Geneva, Switzerland Abstract This paper is motivated by the growing importance of better understanding of the phenomena and consequences of high-intensity energetic particle beam interactions with accelerator, generic target, and detector components. It reviews the principal physical processes of fast-particle interactions with matter, effects in materials under irradiation, materials response, related to component lifetime and performance, simulation techniques, and methods of mitigating the impact of radiation on the components and environment in challenging current and future applications. Keywords Particle physics simulation; material irradiation effects; accelerator design. 1 Introduction The next generation of medium- and high-energy accelerators for megawatt proton, electron, and heavy- ion beams moves us into a completely new domain of extreme energy deposition density up to 0.1 MJ/g and power density up to 1 TW/g in beam interactions with matter [1, 2]. The consequences of controlled and uncontrolled impacts of such high-intensity beams on components of accelerators, beamlines, target stations, beam collimators and absorbers, detectors, shielding, and the environment can range from minor to catastrophic. Challenges also arise from the increasing complexity of accelerators and experimental set-ups, as well as from design, engineering, and performance constraints. All these factors put unprecedented requirements on the accuracy of particle production predictions, the capability and reliability of the codes used in planning new accelerator facilities and experiments, the design of machine, target, and collimation systems, new materials and technologies, detectors, and radiation shielding and the minimization of radiation impact on the environment. -
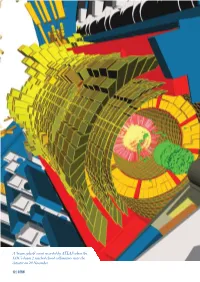
Event Recorded by ATLAS When the LHC's Beam 2 Reached Closed
A ‘beam splash’ event recorded by ATLAS when the LHC’s beam 2 reached closed collimators near the detector on 20 November. 12 | CERN “The imminent start-up of the LHC is an event that excites everyone who has an interest in the fundamental physics of the Universe.” Kaname Ikeda, ITER Director-General, CERN Bulletin, 19 October 2009. Physics and Experiments The moment that particle physicists around the world had been The EMCal is an upgrade for ALICE, having received full waiting for finally arrived on 20 November 2009 when protons approval and construction funds only in early 2008. It will detect circulated again round the LHC. Over the following days, the high-energy photons and neutral pions, as well as the neutral machine passed a number of milestones, from the first collisions component of ‘jets’ of particles as they emerge from quark� at 450 GeV per beam to collisions at a total energy of 2.36 TeV gluon plasma formed in collisions between heavy ions; most — a world record. At the same time, the LHC experiments importantly, it will provide the means to select these events on began to collect data, allowing the collaborations to calibrate line. The EMCal is basically a matrix of scintillator and lead, detectors and assess their performance prior to the real attack which is contained in ‘supermodules’ that weigh about eight tonnes. It will consist of ten full supermodules and two partial on high-energy physics in 2010. supermodules. The repairs to the LHC and subsequent consolidation work For the ATLAS Collaboration, crucial repair work included following the incident in September 2008 took approximately modifications to the cooling system for the inner detector. -

Mayda M. VELASCO Northwestern University, Dept. of Physics And
Mayda M. VELASCO Northwestern University, Dept. of Physics and Astronomy 2145 Sheridan Road, Evanston, IL 60208, USA Phone: Work: +1 847 467 7099 Cell: +1 847 571 3461 E-mail: [email protected] Last Updated: May 2016 Research Interest { High Energy Experimental Elementary Particle Physics: Work toward the understanding of fundamental interactions and its important role in: (a) solving the problem of CP violation in the Universe { Why is there more matter than anti- matter?; (b) explaning how mass is generated { Higgs mechanism and (c) finding the particle nature of Dark-Matter, if any... The required \new" physics phenomena is accessible at the Large Hadron Collider (LHC) at the European Organization for Nuclear Research (CERN). I am an active member of the Compact Muon Solenoid (CMS) collaboration already collect- ing data at the LHC, that led to the discovery of the Higgs boson or \God particle" in 2012. Education: • Ph.D. 1995: Northwestern University (NU) Experimental Particle Physics • 1995: Sicily, Italy ERICE: Spin Structure of Nucleon • 1994: Sorento, Italy CERN Summer School • B.S. 1988: University of Puerto Rico (UPR) Physics (Major) and Math (Minor) Rio Piedras Campus Fellowships and Honors: • 2015: NU, The Graduate School (TGS) Dean's Faculty Award for Diversity. • 2008-09: Paid leave of absence sponsored by US Department of Energy (DOE). • 2002-04: Sloan Research Fellow from Sloan Foundation. • 2002-03: Woodrow Wilson Fellow from Mellon Foundation. • 1999: CERN Achievement Award { Post-doctoral. • 1996-98: CERN Fellowship with Experimental Physics Division { Post-doctoral. • 1989-1995: Fermi National Accelerator Laboratory(FNAL)/URA Fellow { Doctoral. -

Sub Atomic Particles and Phy 009 Sub Atomic Particles and Developments in Cern Developments in Cern
1) Mahantesh L Chikkadesai 2) Ramakrishna R Pujari [email protected] [email protected] Mobile no: +919480780580 Mobile no: +917411812551 Phy 009 Sub atomic particles and Phy 009 Sub atomic particles and developments in cern developments in cern Electrical and Electronics Electrical and Electronics KLS’s Vishwanathrao deshpande rural KLS’s Vishwanathrao deshpande rural institute of technology institute of technology Haliyal, Uttar Kannada Haliyal, Uttar Kannada SUB ATOMIC PARTICLES AND DEVELOPMENTS IN CERN Abstract-This paper reviews past and present cosmic rays. Anderson discovered their existence; developments of sub atomic particles in CERN. It High-energy subato mic particles in the form gives the information of sub atomic particles and of cosmic rays continually rain down on the Earth’s deals with basic concepts of particle physics, atmosphere from outer space. classification and characteristics of them. Sub atomic More-unusual subatomic particles —such as particles also called elementary particle, any of various self-contained units of matter or energy that the positron, the antimatter counterpart of the are the fundamental constituents of all matter. All of electron—have been detected and characterized the known matter in the universe today is made up of in cosmic-ray interactions in the Earth’s elementary particles (quarks and leptons), held atmosphere. together by fundamental forces which are Quarks and electrons are some of the elementary represente d by the exchange of particles known as particles we study at CERN and in other gauge bosons. Standard model is the theory that laboratories. But physicists have found more of describes the role of these fundamental particles and these elementary particles in various experiments. -

CERN's Scientific Strategy
CERN’s Scientific Strategy Fabiola Gianotti ECFA HL-LHC Experiments Workshop, Aix-Les-Bains, 3/10/2016 CERN’s scientific strategy (based on ESPP): three pillars Full exploitation of the LHC: successful operation of the nominal LHC (Run 2, LS2, Run 3) construction and installation of LHC upgrades: LIU (LHC Injectors Upgrade) and HL-LHC Scientific diversity programme serving a broad community: ongoing experiments and facilities at Booster, PS, SPS and their upgrades (ELENA, HIE-ISOLDE) participation in accelerator-based neutrino projects outside Europe (presently mainly LBNF in the US) through CERN Neutrino Platform Preparation of CERN’s future: vibrant accelerator R&D programme exploiting CERN’s strengths and uniqueness (including superconducting high-field magnets, AWAKE, etc.) design studies for future accelerators: CLIC, FCC (includes HE-LHC) future opportunities of diversity programme (new): “Physics Beyond Colliders” Study Group Important milestone: update of the European Strategy for Particle Physics (ESPP): ~ 2019-2020 CERN’s scientific strategy (based on ESPP): three pillars Covered in this WS I will say ~nothing Full exploitation of the LHC: successful operation of the nominal LHC (Run 2, LS2, Run 3) construction and installation of LHC upgrades: LIU (LHC Injectors Upgrade) and HL-LHC Scientific diversity programme serving a broad community: ongoing experiments and facilities at Booster, PS, SPS and their upgrades (ELENA, HIE-ISOLDE) participation in accelerator-based neutrino projects outside Europe (presently mainly -

Around the Laboratories
Around the Laboratories such studies will help our under BROOKHAVEN standing of subnuclear particles. CERN Said Lee, "The progress of physics New US - Japanese depends on young physicists Antiproton encore opening up new frontiers. The Physics Centre RIKEN - Brookhaven Research Center will be dedicated to the t the end of 1996, the beam nurturing of a new generation of Acirculating in CERN's LEAR low recent decision by the Japanese scientists who can meet the chal energy antiproton ring was A Parliament paves the way for the lenge that will be created by RHIC." ceremonially dumped, marking the Japanese Institute of Physical and RIKEN, a multidisciplinary lab like end of an era which began in 1980 Chemical Research (RIKEN) to found Brookhaven, is located north of when the first antiprotons circulated the RIKEN Research Center at Tokyo and is supported by the in CERN's specially-built Antiproton Brookhaven with $2 million in funding Japanese Science & Technology Accumulator. in 1997, an amount that is expected Agency. With the accomplishments of these to grow in future years. The new Center's research will years now part of 20th-century T.D. Lee, who won the 1957 Nobel relate entirely to RHIC, and does not science history, for the future CERN Physics Prize for work done while involve other Brookhaven facilities. is building a new antiproton source - visiting Brookhaven in 1956 and is the antiproton decelerator, AD - to now a professor of physics at cater for a new range of physics Columbia, has been named the experiments. Center's first director. The invention of stochastic cooling The Center will host close to 30 by Simon van der Meer at CERN scientists each year, including made it possible to mass-produce postdoctoral and five-year fellows antiprotons. -

Poster, Some Projects Are Also Progressing at CERN
Status Report of Survey Activities Philippe Dewitte, Tobias Dobers, Jean-Christophe Gayde, CERN, Geneva, Switzerland Introduction: France Besides the main survey activities, which are presented in dedicated talks or poster, some projects are also progressing at CERN. AWAKE, a project to verify the approach of using protons to drive a strong wakefield in a plasma which can then be harnessed to accelerate a witness bunch of electrons, will be using the proton beam of the CERN Neutrino to - Gran Sasso, plus an electron and a laser beam. The proton beam line and laser beam line are ready to send protons inside the 10m long plasma cell in October. The electron beam line will be installed next year. ELENA, a small compact ring for cooling and further deceleration of 5.3 MeV antiprotons delivered by the CERN Antiproton Decelerator, is being installed and aligned, for commissioning later this year. The CERN Neutrino Platform is CERN's undertaking to foster and contribute to fundamental research in neutrino physics at particle accelerators worldwide. Two secondary beamlines are extended in 2016-18 for the experiments WA105 and ProtoDUNE. In parallel the detectors for WA104 are refurbished and the cryostats assembled. This paper gives an overview of the survey activities realised in the frame of the above mentioned projects and the challenges to be addressed. AWAKE - Advance WAKefield Experiment AWAKE will use a protons beam from the Super Proton Synchrotron (SPS) in the CERN Neutrinos to Gran Sasso facility (CNGS). CNGS has been stopped at the end of 2012. A high power laser pulse coming from the laser room will be injected within the proton bunches to create the plasma by ionizing the (initially) neutral gas inside the plasma cell. -

The New Lhc Protectors Elsen
Issue No. 9-10/2018-Wednesday 28 February 2018 CERN Bulletin More articles at http:/ / home.cern/ cern-people A WORD FROM ECKHARD THE NEW LHC PROTECTORS ELSEN A FEAST OF PHYSICS TO TIDE New collimators are being installed and tested in the LHC. They will im- US OVER UNTIL MORIOND. prove its protection and prepare it for higher luminosity in the HL-LHC While awaiting the annual tartiflette of physics that is the Moriond conference, at the forefront of which will be the results of the LHC's 13-TeV runs, it's refreshing to take a look at some of the other research that has been going on around the Laboratory. We have a very rich and diverse programme and there have been some very interesting developments over recent months. (Continued on page 2) In this issue News 1 The new LHC protectors1 A word from Eckhard Elsen2 Two wire collimators have been installed in the LHC tunnel on both sides of the ATLAS experiment. (Image: Max What's YETS for the experiments?3 Brice, Julien Ordan/CERN) High-level visits to CERN4 Collimators are the brave protectors of the has a wire integrated into its jaws, vacuum- New chairs for the Antiproton LHC. They absorb all the particles that brazed into its tungsten-alloy absorbers. A Decelerator Users Community5 stray from the beam trajectory. These un- current passing through the wire creates an Female physicists and engineers go ruly particles may cause damage in sen- electromagnetic field, which can be used back to school5 sitive areas of the accelerator, thereby to compensate the effect of the opposite Computer security: curiosity clicks the endangering operational stability and ma- beam.