Linguistica Pragensia 2018-1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Read Between the Sheets PAOLA N
TUESDAY MARCH 22, 2016 NEWS // New Zipcars on campus A&E // Health columnist’s tips on OPINIONS // Staff Editorial: It’s always SPORTS // Softball team sweeps Akron VOL.63 NO. 14 encourage ride-sharing, pg. 4. #HowToSurviveThePoolDeck, pg. 8. sunny in Dayton, pg. 10. with two shutouts, pg. 15. FLYERTUESDAY MARCH 22, 2016NEWS | ISSUE 14 *Pg. 3 Sheet sign culture at UD: Read between the sheets PAOLA N. ORTIZ Junior, Marketing The sheet sign culture in the student neighborhood is affect- ing the way parents and students see the University of Dayton and its community. The sheet sign culture started about 25 years ago in the student neighborhood when students took white bed sheets and wrote on them to express their Flyer spirit in a creative way whenev- er the school achieved a signifi- cant accomplishment or when a UD team won. Sheet signs have changed considerably since then. Students commonly feature inappropriate sexual messages on sheet signs, especially during Welcome Weekend, Family Week- end and March Madness. Some students do not consider these Students often create sheet signs for special events, such as Welcome Weekend, Family Weekend and March Madness. Some, though not all, signs have messages as inappropriate. They received criticism for their inappropriate nature. Chris Santucci/ Multimedia Editor view them as a funny way to share Flyer pride. asking to take the sign down; that “I do not necessarily feel un- fended nor fear for my life, but said. Some examples of these mes- would be a violation of compli- safe but uncomfortable because I do feel bad for other people In an interview with Kristen sages are “Daddy issues save us ance in the code of conduct. -

Los Simpson Versus Trump
LOS SIMPSON VERSUS TRUMP Graciela Martínez-Zalce Sánchez* Para GAH, quien no conocía a los Simpson y cree conocer a Trump And that is how I became a Democrat HOMERO J. SIMPSON El corto titulado “Donald Trump’s first 100 days in office”,1 publicado el 26 de abril de 2017 como parte de la temporada 28 de Los Simpson en el canal Animation Fox en Youtube, cierra con un negro sarcasmo.2 En una serie, en la que por casi tres décadas se han utilizado los matices y las sutilezas indis- pensables para que los episodios, escritos con gran inteligencia por presti- giosos grupos de guionistas irreverentes,3 tengan como característica sobresaliente tres figuras retóricas, la parodia, la ironía y, sobre todo, la sátira, * Directora e investigadora del Centro de Investigaciones sobre América del Norte de la Universidad Nacional Autónoma de México, <[email protected]>. 1 En este artículo utilizaré los títulos de los capítulos y los nombres que se le han dado a los per- sonajes en español en el doblaje para México (donde la serie comenzó a transmitirse en el canal 13 de Imevisión en marzo de 1991, los martes a las 20:30 horas), pero, en su mayoría, las citas textuales de los diálogos se harán en el original en inglés debido a que el doblaje tropicaliza las alusiones y, por tratarse aquí de los partidos y los políticos estadunidenses, es importante que se conserven. En el caso específico de este corto, puesto que no fue exhibido fuera de Estados Unidos y Canadá, y como la wiki en español aún está consignando la temporada 27, el título del mismo se anota en inglés. -
Peter Gallant Works
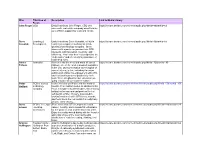
Who Title/Area of Description Link to Media Library Focus John Frager CEO David interviews John Frager, CEO of a https://secure.davidco.com/connect/audio.php?titleid=8&trackid=63 successful real estate company about how he uses GTD to support his team and clients. Steve Learning & David interviews Steve Kowalski, a PhD in https://secure.davidco.com/connect/audio.php?titleid=9&trackid=65 Kowalski Development learning development working for a fast- growing biotechnology company. Steve shares with a particular passion how GTD intersects with innovation, creativity, and efficiency. You'll also hear his perspective on "authenticity" and it's emerging importance in leadership roles. James Journalist Welcome into the mind and world of James https://secure.davidco.com/connect/audio.php?titleid=12&trackid=90 Fallows Fallows, one of the most renowned journalists in the U.S. Our conversation covers topics of current interest to Jim, including American politics and China, his engagement with GTD, and his favorite personal productivity tech tools. We're delighted to have Jim as an on- going resource in our Connect "salon." Peter CEO of startup In this interview you'll dive into the world of https://secure.davidco.com/connect/multimedia/audio.php?titleid=15&trackid=100 Gallant technology how Dr. Peter Gallant works. In addition to his company Ph.D. in Engineering (which gives him a strong inclination for systems and process) he's a self-taught GTD'er. If you're interested in working models of what GTD looks, sounds, and feels like in the real world of a really busy person, listen closely.. -

The Simpsons Am Beispiel Der 17
DIPLOMARBEIT Titel der Diplomarbeit Vom Dialogbuch zur fertigen Episode. Veränderungen durch die deutschsprachige Synchronisation der U.S. amerikanischen Zeichentrickserie The Simpsons am Beispiel der 17. Staffel. Verfasser Patrick Seirafi angestrebter akademischer Grad Magister der Philosophie (Mag.phil.) Wien, 2014 Studienkennzahl lt. Studienblatt: A 317 Studienrichtung lt. Studienblatt: Theater-, Film- u. Medienwissenschaft Betreuer: Mag. Dr. habil. Ramón Reichert Abbildungsverzeichnis ............................................................................. 6 1. Einleitung ............................................................................................... 8 2. Theoretische Grundlagen der Übersetzungswissenschaft ............. 12 2.1 Arten der Übersetzung ............................................................................ 12 2.2 Übersetzungskritik .................................................................................. 13 2.3 Zur Definition eines Übersetzungsbegriffs ........................................... 13 2.4 Die Skopostheorie ................................................................................... 14 2.5 Zur unübersetzbaren Übersetzung ........................................................ 15 2.6 Äquivalenz und Adäquatheit .................................................................. 18 2.7 Zum Übersetzungsprozess ..................................................................... 20 2.7.1 Voraussetzungen an einen Übersetzer ........................................................... -

(Don't) Wear Glasses: the Performativity of Smart Girls On
GIRLS WHO (DON'T) WEAR GLASSES: THE PERFORMATIVITY OF SMART GIRLS ON TEEN TELEVISION Sandra B. Conaway A Dissertation Submitted to the Graduate College of Bowling Green State University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY August 2007 Committee: Kristine Blair, Advisor Julie Edmister Graduate Faculty Representative Erin Labbie Katherine Bradshaw © 2007 Sandra Conaway All Rights Reserved iii ABSTRACT Kristine Blair, Advisor This dissertation takes a feminist view of t television programs featuring smart girls, and considers the “wave” of feminism popular at the time of each program. Judith Butler’s concept from Gender Trouble of “gender as a performance,” which says that normative behavior for a given gender is reinforced by culture, helps to explain how girls learn to behave according to our culture’s rules for appropriate girlhood. Television reinforces for intellectual girls that they must perform their gender appropriately, or suffer the consequences of being invisible and unpopular, and that they will win rewards for performing in more traditionally feminine ways. 1990-2006 featured a large number of hour-long television dramas and dramedies starring teenage characters, and aimed at a young audience, including Beverly Hills, 90210, My So-Called Life, Buffy the Vampire Slayer, Freaks and Geeks, and Gilmore Girls. In most teen shows there is a designated smart girl who is not afraid to demonstrate her interest in math or science, or writing or reading. In lieu of ethnic or racial minority characters, she is often the “other” of the group because of her less conventionally attractive appearance, her interest in school, her strong sense of right and wrong, and her lack of experience with boys. -

Functions of Intermediality in the Simpsons
Functions of Intertextuality and Intermediality in The Simpsons Der Fakultät für Geisteswissenschaften der Universität Duisburg-Essen zur Erlangung des akademischen Grades eines Doktors der Philosophie (Dr. phil.) eingereichte Dissertation von Wanja Matthias Freiherr von der Goltz Datum der Disputation: 05. Juli 2011 Gutachter: Prof. Dr. Josef Raab Prof. Dr. Jens Gurr Table of Contents List of Figures...................................................................................................................... 4 1. Introduction .............................................................................................. 5 1.1 The Simpsons: Postmodern Entertainment across Generations ................ 5 1.2 Research Focus .............................................................................................11 1.3 Choice of Material ..........................................................................................16 1.4 Current State of Research .............................................................................21 2. Text-Text Relations in Television Programs ....................................... 39 2.1 Poststructural Intertextuality: Bakhtin, Kristeva, Barthes, Bloom, Riffaterre .........................................................................................................39 2.2 Forms and Functions of Intertextual References ........................................48 2.3 Intertextuality and Intermediality ..................................................................64 2.4 Television as a -

Evolución De La Comedia De Situación
UNIVERSIDAD DE SEVILLA FACULTAD DE COMUNICACIÓN ESTUDIO DE LA COMEDIA DE SITUACIÓN Y SU EVOLUCIÓN ANÁLISIS DE ROCKEFELLER PLAZA YTHE BIG BANG THEORY TRABAJO DE SAIDA HERRERO MORALES | [email protected] DIRIGIDO POR Dra. INMACULADA GORDILLO ÁLVAREZ Septiembre 2016 MÁSTER EN GUION, NARRATIVA Y CREACIÓN AUDIOVISUAL DEPARTAMENTO DE COMUNICACIÓN AUDIOVISUAL y PUBLICIDAD En memoria de Garry Shandling, creador y protagonista de The Larry Sanders Show (1949-2016). Y de mi tío Mario. Cincuenta y tres años de anécdotas que van más allá de lo que cualquier sitcom podría recoger. Nuestros momentos contigo han quedado enlatados como aquellas risas de estudio, pudiendo recordarlos una y otra vez. Inolvidables cuál gran éxito de la pequeña pantalla. Descansa en paz. ÍNDICE Resumen ............................................................................................................... 4 Palabras Clave ...................................................................................................... 4 Agradecimientos ................................................................................................... 4 1. INTRODUCCIÓN .................................................................................................. 5 2. PLANTEAMIENTO DE LA INVESTIGACIÓN .................................................. 6 Justificación ........................................................................................................ 6 La ‘sitcom clásica’ frente a la ‘sitcom televisiva’ ............................................... -

“Trumpism”? Part 1 Clay Nelson © 3 April 2016
Is New Zealand safe from “Trumpism”? Part 1 Clay Nelson © 3 April 2016 Sixteen years ago there was an episode of The Simpsons where Bart is shown his life 30 years in the future. Not surprisingly he learns he will become a beer-swilling bum. On the other hand Lisa is shown behind the desk in the Oval Office as the “first straight female President” telling her staff “As you know, we’ve inherited quite a budget crunch from President Trump. How bad is it? The country is broke.” It turns out that Dan Greaney who wrote the episode may have only been about six years off in his prediction. His explanation for the prescient prediction was he wanted Lisa to come into the presidency when America is on the ropes. “What we needed was for Lisa to have problems that were beyond her fixing, that everything was as bad as it could possibly be. That’s why we had Trump be president before her.” “The Simpson’s,” he said, “has always embraced the over-the-top side of American culture … and Trump is just the fulfilment of that.” For that reason The Donald has been a running joke for late night television hosts for decades. Jon Stewart had only one regret in his decision to step down from The Daily Show recently. When he announced it he did not know Trump was going to run for president, which would have given him an enormous amount of fodder for his special brand of satire. In other words, no one thought anyone could or would take Trump seriously. -

Television and New Media Nominees Drama Series Comedy Series
TELEVISION AND NEW MEDIA NOMINEES DRAMA SERIES COMEDY SERIES The Americans, Written by Peter Atlanta, Written by Donald Glover, Ackerman, Tanya Barfield, Joshua Stephen Glover, Jamal Olori, Brand, Joel Fields, Stephen Schiff, Stefani Robinson, Paul Simms; FX Joe Weisberg, Tracey Scott Wilson; FX Silicon Valley, Written by Megan Better Call Saul, Written by Ann Amram, Alec Berg, Donick Cary, Cherkis, Vince Gilligan, Jonathan Adam Countee, Jonathan Dotan, Glatzer, Peter Gould, Gennifer Mike Judge, Carrie Kemper, Hutchison, Heather Marion, Thomas John Levenstein, Dan Lyons, Carson Schnauz, Gordon Smith; AMC Mell, Dan O’Keefe, Clay Tarver, Ron Weiner; HBO Game of Thrones, Written by David Benioff, Bryan Cogman, Dave Hill, Transparent, Written by Arabella D.B. Weiss; HBO Anderson, Bridget Bedard, Micah Fitzerman-Blue, Noah Harpster, Stranger Things, Written by Paul Jessi Klein, Stephanie Kornick, Dichter, Justin Doble, The Duffer Ethan Kuperberg, Ali Liebegott, Brothers, Karl Gajdusek, Jessica Our Lady J, Faith Soloway, Mecklenburg, Jessie Nickson-Lopez, Jill Soloway; Amazon Studios Alison Tatlock; Netflix Unbreakable Kimmy Schmidt, Written Westworld, Written by Ed Brubaker, by Emily Altman, Robert Carlock, Bridget Carpenter; Dan Dietz, Halley Azie Mira Dungey, Tina Fey, Lauren Gross; Lisa Joy; Katherine Lingenfelter, Gurganous, Sam Means, Dylan Dominic Mitchell, Jonathan Nolan, Morgan, Marlena Rodriguez, Roberto Patino, Daniel T. Thomsen, Dan Rubin, Meredith Scardino, Charles Yu; HBO Josh Siegal, Allison Silverman, Leila Strachan; Netflix Veep, Written by Rachel Axler, Sean Gray, Alex Gregory, Peter Huyck, Erik Kenward, Billy Kimball, Steve Koren, David Mandel, Jim Margolis, Lew Morton, Georgia Pritchett, Will Smith, Alexis Wilkinson; HBO FEBRUARY 19, 2017 11 TELEVISION AND NEW MEDIA NOMINEES NEW SERIES LONG FORM ORIGINAL Atlanta, Written by Donald Glover, American Crime, Written by Julie Stephen Glover, Jamal Olori, Hébert, Sonay Hoffman, Keith Huff, Stefani Robinson, Paul Simms; FX Stacy A. -

04-Encuentros-Inglc3a9s-Interiores.Pdf
ENRIQUE GRAUE WIECHERS Rector ENCUENTROS2050 $30.00 LEONARDO LOMELÍ VANEGAS Secretario General Encuentros2050, Año 1, Número 4 (Abril 2017) es una publicación mensual, ALBERTO VITAL DÍAZ editada por la Universidad Nacional Autónoma Coordinador de Humanidades de México, Ciudad Universitaria, Delegación Coyoacán, Ciudad de México, C.P. 04510, a través de la Coordinación de Humanidades, MALENA MIJARES Presidente Carranza 162, Col. Villa Coyoacán, Coordinadora de Divulgación Delegación Coyoacán, Ciudad de México, C.P. y Publicaciones 04000, teléfono: 5554-5579 y 5554-8513 ext. DIEGO GARCÍA DEL GÁLLEGO 128. correo electrónico: revistaencuentros2050 Secretario Técnico @gmail.com, Editor responsable: María del Programa Editorial Alejandra Ordóñez Cruickshank. Certificado de Reserva de Derechos al uso Exclusivo No. 04-2017-021412463800-102, otorgado por Encuentros2050 el Instituto Nacional del Derecho de Autor, Certificado de Licitud de Título y Contenido MARÍA ORDÓÑEZ CRUICKSHANK No. en trámite, otorgado por la Comisión Jefa de redacción Calificadora de Publicaciones y Revistas Ilustradas de la Secretaria de Gobernación, impresa por Litográfica Ingramex, S.A. de NÚMERO 4, ABRIL DE 2017 C.V., Centeno 195, Col. Granjas Esmeralda, C.P. 09819, Delegación Iztapalapa, Ciudad de México, este número se terminó de imprimir el día 24 de abril de 2017, con un tiraje de ROGELIO RANGEL 1000 ejemplares, impresión tipo offset, con Diseño gráfico papel bond de 120 gramos para los interiores y cartulina sulfatada de 250 gramos para PABLO RULFO los forros. El contenido de los artículos es Coordinador de ilustradores responsabilidad de los autores y no refleja el punto de vista de la UNAM. Se autoriza la GERARDO CASTILLO reproducción de los artículos (no así de las Ilustraciones Relaciones bilaterales imágenes) con la condición de citar la fuente y de que se respeten los derechos de autor. -

Homer Simpson, on His Role As Internet Journalist Mr. X
The Scoop on The Simpsons: Journalism in U.S. Television’s Longest Running Prime-Time Animated Series By Stephanie Woo “I changed the world. Now I know exactly how God feels.”1 – Homer Simpson, on his role as Internet journalist Mr. X Although the journalists of The Simpsons are far from godly, news in The Simpsons is vital, if for no reason other than its ability to provide exposition and advance a plot quickly. A week of Homer Simpson’s public service is documented with daily headlines as he gets speed bumps and safety signs installed.2 Power-plant owner Montgomery Burns’ rise and fall in a gubernatorial campaign occur through headlines reading: “Burns Skyrockets to Seven Percent in Latest Polls,” “Burns Nukes Bailey in Latest Poll,” “Forty-Two Percent and Climbing,” and, in the end, a broadcast story announcing: “The latest polls indicate Burns’ popularity has plummeted to Earth like so much half-chewed fish.”3 But media in The Simpsons are more than a plot device. They are the representation of journalistic quality, integrity, and influence. The news industry on The Simpsons faces the same dilemmas as outlets such as CBS News and The New York Times – maligned public images, a dearth of audience trust, and the chore of maintaining both credibility and entertainment value. When an anonymous Internet watchdog gains popularity in town, news anchor Kent Brockman tells his television audience: “We must never forget that the real news is on local TV, delivered by real, officially licensed newsmen like me, Kent Brockman.” But the news up next on Brockman’s show is an expose about a beer commercial’s talking dogs, presented by a newsman called Cowboy Steve.4 Stephanie Woo 2 A Show with a Message Simpsons creator Matt Groening has never been a news anchor, but he has been a journalist. -

SUNDAY, FEBRUARY 19, 2017 the 69Th Annual Writers Guild Awards SUNDAY, FEBRUARY 19, 2017 • EDISON BALLROOM • NEW YORK CITY
SUNDAY, FEBRUARY 19, 2017 The 69th Annual Writers Guild Awards SUNDAY, FEBRUARY 19, 2017 • EDISON BALLROOM • NEW YORK CITY Officers Lowell Peterson Michael Winship: President Executive Director Jeremy Pikser: Vice President Bob Schneider: Secretary–Treasurer Ruth Gallo Assistant Executive Director Council Members John Auerbach Marsha Seeman Henry Bean Assistant Executive Director Kyle Bradstreet Sue “Bee” Brown Awards Committee Andrea Ciannavei Bonnie Datt, Chair Lisa Takeuchi Cullen Ann B. Cohen Bonnie Datt Don Hooper A.M. Homes Lily-Hayes Kaufman David Keller Gail Lee Susan Kim Allan Neuwirth Christopher Kyle Danielle Paige Gail Lee Dan Perlman Kathy McGee Bill Scheft Matt Nelko Courtney Simon Phil Pilato Richard Vetere Theresa Rebeck Shannon Walker Bill Scheft Courtney Simon Dana Weissman Beau Willimon Director of Programs Nancy Hathorne Events Coordinator Jason Gordon Director of Communications Jenna Bond Member Services Manager PKPR 2 Red Carpet 3 GREETING We’re happy to be back at the elegant Edison Ballroom for the fourth time, as we continue to add to this venue’s colorful history. The Edison got its start as a music club in the 1930s, featuring the era’s top Swing bands. Then, in the 1990s it briefly became The Supper Club, hosting everyone from Tony Bennett to David Bowie. In the interim, it was the Edison Theatre, home to many Broadway shows, including the infamous “Oh! Calcutta!” But tonight is not about great music or Seventies nudity. It’s about elevating the words of the writer. The Writers Guild of America, East brings us here to honor some of the best work that our members have produced in the past year.