An Interactive Web App for Data Envelopment Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Carta E Guida Ai Servizi 2016
Carta e Guida ai Servizi 2016 Services Charter and Guide 2016 INDICE GENERALE: GENERAL INDEX : Carta dei Servizi 2016 pag. 3 Services Charter 2016 p. 3 Guida ai Servizi 2016 pag. 23 Services Guide 2016 p. 23 Shopping in Aeroporto e Norma pag. 57 Shopping at Catania Airport and Compagnie Aeree, Destinazioni e Norma Store p. 57 Mappe pag. 65 Airline companies, Destinations and Maps p. 65 Modello attestazioni Certification requests form Modulo reclami Customer complaint form “L’aeroporto di Catania serve prevalentemente 7 delle 9 provincie siciliane“ "Catania airport mainly serves 7 of the 9 provinces of Sicily" “Per il 2016 prevediamo una crescita dell’1,8% di passeggeri in transito a Catania” “For 2016 we expect a 1.8% growth of passengers in transit in Catania” Carta dei Servizi 2016 Services Charter 2016 Sezione I: SOCIETA’ DI GESTIONE Section I: MANAGEMENT COMPANY SAC – Presentazione pag. 4 SAC - Presentation p. 4 Il nostro impegno per l’Ambiente pag. 5 Our commitment to the Environment page. 5 Il nostro aeroporto in Sicurezza pag. 8 Safety in the airport p. 8 La gestione dell’Energia pag. 9 The Energy Management p. 9 Traffico e destinazioni – 2015 pag. 11 Traffic and destinations - 2015 p. 11 Sezione II: INDICATORI Section II: INDICATORS La nostra politica della Qualità Our Quality Policy La politica della qualità pag. 13 Quality policy p. 13 Indicatori qualità pag. 14 Quality indicators p. 14 I nostri passeggeri PRM pag. 18 Our passengers PRM (Passengers with reduced mobility) p. 18 Indicatori PRM pag. 19 PRM Indicators p. 19 Sezione III: GESTIONE DEI RECLAMI Section III: COMPLAINTS MANAGEMENT Customer Service e reclami pag. -

Fifty Years on Nato's Southern Flank
FIFTY YEARS ON NATO’S SOUTHERN FLANK A HISTORY OF SIXTEENTH AIR FORCE 1954 – 2004 By WILLIAM M. BUTLER Sixteenth Air Force Historian Office of History Headquarters, Sixteenth Air Force United States Air Forces in Europe Aviano Air Base, Italy 1 May 2004 ii FOREWORD The past fifty years have seen tremendous changes in the world and in our Air Force. Since its inception as the Joint U.S Military Group, Air Administration (Spain) responsible for the establishment of a forward presence for strategic and tactical forces, Sixteenth Air Force has stood guard on the southern flank of our NATO partners ensuring final success in the Cold War and fostering the ability to deploy expeditionary forces to crises around our theater. This history then is dedicated to all of the men and women who met the challenges of the past 50 years and continue to meet each new challenge with energy, courage, and devoted service to the nation. GLEN W. MOORHEAD III Lieutenant General, USAF Commander iii PREFACE A similar commemorative history of Sixteenth Air Force was last published in 1989 with the title On NATO’s Southern Flank by previous Sixteenth Air Force Historian, Dr. Robert L. Swetzer. This 50th Anniversary edition contains much of the same structure of the earlier history, but the narrative has been edited, revised, and expanded to encompass events from the end of the Cold War to the emergence of today’s Global War on Terrorism. However, certain sections in the earlier edition dealing with each of the countries in the theater and minor bases have been omitted. -

" CA, CELLED. by AUTHOITY of the ADJUTANT GUA __-Sgha-M-Xagp YEC
,1 I in T S I C I I A N C A IMFP A I G N as compiled from G-3 Journal for period July 10, 1943 - Aug 22, 1943. itsFICATION CHANGED TIO " CA, CELLED. BY AUTHOITY OF THE ADJUTANT GUA __-sGHA-m-xaGp YEC _/ 1%I 4' , I / ~-" - "i't 1Z, *1 M-,:· y . / 1" ; o^ oN l JULY 10, 1943 See Map No 1 (Opp page) The division landed beginning at 0425 on beaches shown on Map No 1, under supporting Naval gunfire. Zones of advance and objectives as shown opposite. 157TH RCT Landed on beaches Green 2 and Yellow 2, against light opposition; advanced inland. 1st Battalion captured S CRUCE, CAMERINA at 1445. 2nd Battalion captured DUNNA FUGATA at 1715, 2nd and 3rd moved on COMISO to positions shown on Map No 1. 179TH RCT Landed on beaches Yel'low and Green, 1st Battalion captured SCOGLITTI at 1400, 3rd Battalion advanced to positions west of VITTORIA, patrol of 45th Cavalry Reconnaissance Troop entered VITTORIA about 1335. 180TH RCT Landings scattered from GELA to points three miles north of Red beach. Elements were assembled late in afternoon and advanced to vicinity Highway 115. Commanding General and G-2, G-3 and G-4 landed on beach Green at 0830. CP established at 367159. .rs~s~T~ l Yt" " GED 6~~~A CA.,CHO" 9 JULY 11, 193 Ma) Nor The advance of the division continued on July 11th. No contact was made with our adjacentunits, 1st Division on the left and 1st Canadian. Division on the right. -

Accessibility to Italian Remote Regions. When Air Transport Is the Best Alternative?
1 Laurino, Beria, Debernardi Accessibility to Italian remote regions. When air transport is the best alternative? Antonio Laurino a, Paolo Beria a, Andrea Debernardi b Presenter: Antonio Laurino a Department of Architecture and Urban Studies (DAStU), Politecnico di Milano, Italy Phone +39 02 2399 5424, [email protected] , [email protected] b Studio META, Via Magenta 15, Monza, Italy [email protected] Historically, for geographically disadvantaged areas, air transport services have represented the main alternative to guarantee residents' mobility needs. In the last decades, many investments in local airports have been promoted as a way to increase accessibility in many Italian regions. On the other side, transport services have also witnessed important changes as the entrance of low cost carriers, the development of high speed services or the increasing role of long distance passenger coach transport. These services together with an improved intermodality could provide an alternative to access areas of the country. The paper, adopting a policymaker perspective, studies the different passenger transport alternatives for a sample of zones in the catchment area of a local airport. It is based on a long distance multimodal transport model describing the entire Italian long distance supply thus it allows to estimate the generalized cost to access all the zones of the country by road, rail, coach and air services. The analysis of the generalized costs for the period 2013/2014 helps to better understand the role of air transport with respect to the other available modes for each zone. It could also represent the first step to reconsider the possible strategies to improve national accessibility levels. -
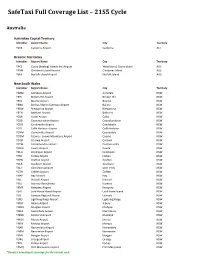
Safetaxi Full Coverage List – 21S5 Cycle
SafeTaxi Full Coverage List – 21S5 Cycle Australia Australian Capital Territory Identifier Airport Name City Territory YSCB Canberra Airport Canberra ACT Oceanic Territories Identifier Airport Name City Territory YPCC Cocos (Keeling) Islands Intl Airport West Island, Cocos Island AUS YPXM Christmas Island Airport Christmas Island AUS YSNF Norfolk Island Airport Norfolk Island AUS New South Wales Identifier Airport Name City Territory YARM Armidale Airport Armidale NSW YBHI Broken Hill Airport Broken Hill NSW YBKE Bourke Airport Bourke NSW YBNA Ballina / Byron Gateway Airport Ballina NSW YBRW Brewarrina Airport Brewarrina NSW YBTH Bathurst Airport Bathurst NSW YCBA Cobar Airport Cobar NSW YCBB Coonabarabran Airport Coonabarabran NSW YCDO Condobolin Airport Condobolin NSW YCFS Coffs Harbour Airport Coffs Harbour NSW YCNM Coonamble Airport Coonamble NSW YCOM Cooma - Snowy Mountains Airport Cooma NSW YCOR Corowa Airport Corowa NSW YCTM Cootamundra Airport Cootamundra NSW YCWR Cowra Airport Cowra NSW YDLQ Deniliquin Airport Deniliquin NSW YFBS Forbes Airport Forbes NSW YGFN Grafton Airport Grafton NSW YGLB Goulburn Airport Goulburn NSW YGLI Glen Innes Airport Glen Innes NSW YGTH Griffith Airport Griffith NSW YHAY Hay Airport Hay NSW YIVL Inverell Airport Inverell NSW YIVO Ivanhoe Aerodrome Ivanhoe NSW YKMP Kempsey Airport Kempsey NSW YLHI Lord Howe Island Airport Lord Howe Island NSW YLIS Lismore Regional Airport Lismore NSW YLRD Lightning Ridge Airport Lightning Ridge NSW YMAY Albury Airport Albury NSW YMDG Mudgee Airport Mudgee NSW YMER -

Financial Statements 2013
Financial Statements 2013 FINANCIAL STATEMENTS CONSOLIDATED FINANCIAL STATEMENT 2013 Bilancio ENAV S.P.A. VIA SALARIA, 716 00138 ROMA www.enav.it Financial Statements 2013 FINANCIAL STATEMENTS CONSOLIDATED FINANCIAL STATEMENT Index ORGANS AND OFFICIAL ROLES OF ENAV S.P.A. 5 REPORT ON OPERATIONS 7 › Profile of ENAV S.p.A. and of the Group 8 › Corporate Governance 9 › Management key areas 10 › Market trends 22 › Commercial activities in domestic and foreign third markets 25 › Investments and research 27 › Environment 33 › Human resources 35 › Other information 41 › Economic trend and financial situation of Enav and of the group 47 › Risk factors 55 › Relation with the related parties 60 › Significant facts at the closing of the fiscal year 62 › Performance Forecast 63 › Proposal for allocation of net profits of Enav S.p.A. 65 FINANCIAL STATEMENTS OF ENAV S.P.A. ON DECEMBER 31 2013 67 Notes to the financial statements 73 › Section 1: Form and content of the technical statements 74 › Section 2: Basis of preparation of the financial statements and accounting policies 75 › Section 3: Analysis of balance sheet items and their changes 80 › Section 4: Further information 115 › Annexes 117 › Certification of the CEO and the Manager in charge 127 › Report of the Supervisory Board 129 › Report of the independent auditors 137 CONSOLIDATED FINANCIAL STATEMENTS OF THE ENAV GROUP ON 31 DECEMBER 2013 141 Notes to the consolidated financial statements 147 › Section 1: Form and content of the consolidated financial statements 148 › Section 2: Group valuation criteria 151 › Section 3: Analysis of balance sheet items and their charge 156 › Section 4: Further information 171 › Annexes 173 › Certification of the CEO and the Manager in charge 183 › Report of the Supervisory Board 185 › Report of the independent auditors 190 Glossary 194 ENAV FINANCIAL STATEMENTS – 2013 3 4 ENAV FINANCIAL STATEMENTS – 2013 Organs and official roles of ENAV S.P.A. -

Sadisopsg/16-Report
SADISOPSG/16-REPORT SIXTEENTH MEETING OF THE SADIS OPERATIONS GROUP (SADISOPSG/16) (Paris, France, 23 to 25 May 2011) INTERNATIONAL CIVIL AVIATION ORGANIZATION The designation and the presentation of material in this publication do not imply the expression of any opinion whatsoever on the part of ICAO concerning the legal status of any country, territory, city or area of its authorities, or concerning the delimitation of its frontiers or boundaries. History of the Meeting i-1 TABLE OF CONTENTS Page List of SADISOPSG decisions ......................................................................................................... i-3 List of SADISOPSG conclusions .................................................................................................... i-3 List of conclusions for consideration by the ICAO planning and implementation regional groups ................................................................................................................................. i-3 Agenda Item 1: Opening of the meeting Place and duration ................................................................................................................. 1-1 Attendance ............................................................................................................................ 1-1 Chairman and officers of the Secretariat ............................................................................... 1-1 Agenda Item 2 Organizational matters Adoption of working arrangements .................................................................................... -

How to Reach Us
The location of Villa Boscarino combines the convenience of being just steps from the historic center with the privacy of a secluded get-away. Villa Boscarino Coordinate GPS Via L.A. Muratori, 63 Latitude: 36.9208679 97100 Ragusa Longitude: 14.717945200000031 HOW TO REACH US FLIGHT Comiso Airport The airport is 26 kilometers away from Villa Boscarino and is 30 minutes away by car. From the airport buses connect the airport of Comiso with the bus station of Ragusa at Via Zama, which is just 1 kilometer from the hotel. Contact our concierge to book your taxi or private transfer. VILLA BOSCARINO Via L.A. Muratori, 63 – 97100 Ragusa, Italy [email protected] - www.villaboscarino.it tel. +39 0932 256749 Catania Airport The airport Vincenzo Bellini-Fontanarossa is less than 100 kilometres away and about 90 minutes away by car. A 2 hour bus ride on one of the busses departing from the terminal near the airport makes Ragusa easy to reach. The taxi rate varies between Euro 100,00 and 130,00 for up to 4 people. Contact our concierge to book your taxi or private transfer. CAR Comiso Airport: From the airport take county road number 5 (SP5) towards “Ragusa”. At the roundabout take the first exit and proceed along county road number 30 (SP30) until turning left on to the entrance of county road number 7 (SP7), then turn left again to take the 514 state highway (SS514) towards Ragusa – keep to the right lane. Proceed for 12 kilometers and turn on to the junction for Vittoria/Comiso/Gela/Ragusa Ovest keep left at the crossroads and follow the signs to Ragusa and take exit “ Ragusa Sud”. -

Download Short Profiles
Numbers SHORT PROFILES OF AIR TECH ITALY COMPANIES Italian Airport Industry Association - ATI Welcome to the Italian Airport Industry Association Air Tech Italy (ATI) is the leading Trade Association representing Italian companies specialized in supplying products, technologies and services for airports and air-traffic control. We are the first hub for international clients looking for top-quality Italian companies. The list of companies is in alphabetical order Segments and colors AIR TRAFFIC MANAGEMENT AIRFIELD CONSTRUCTION & SERVICES ENGINEERING & CONSULTANCY IT TERMINAL Main Segment: IT Numbers 17+ 14 YEARS OF EXPERIENCE PRODUCT PORTFOLIO 46 8 AIRPORTS SERVED SALES AND TECHNICAL WORLDWIDE SUPPORT CENTRES Products & Services Top Airports served • A-DCS Departure Control System • Milan Malpensa MXP • A-WBS Weight and Balance System • Milan Linate LIN • A-CUBE Multi CUTE Client • Gaborone GBE • A-MDS Message Distribution System • Teheran IKA • A-ODB Airport Operational Database • Istanbul IST • A-SCHED Flight Schedule • Verona Catullo VRN IT Solutions Provider for Airports, Airlines and Ground • A-FIDS Flight Information Display System • Rome Fiumicino FCO Handlers A-ICE provides value-added IT solutions and • A-MIS Multimedia Information System • Tel Aviv TLV integrated applications to Airport, Airlines and Ground • A-SCP Security Check Point • A-HDB Handling Database • Bangkok BKK Handlers, with specific experience in the implementa- • A-CAB Contract And Billing • Bari BRI tion and support of mission critical systems. • A-BRS Baggage Reconciliation System A-ICE relies on its strong relationship with the Air • A-VMS Vehicles Maintenance System Transport community, addressing and anticipating the • CLOS Cooperative Logistics Optimization System needs as they evolve. Company associated with Via dei Castelli Romani, 59, 00071 – Pomezia (RM) ITALY Tel. -

KODY LOTNISK ICAO Niniejsze Zestawienie Zawiera 8372 Kody Lotnisk
KODY LOTNISK ICAO Niniejsze zestawienie zawiera 8372 kody lotnisk. Zestawienie uszeregowano: Kod ICAO = Nazwa portu lotniczego = Lokalizacja portu lotniczego AGAF=Afutara Airport=Afutara AGAR=Ulawa Airport=Arona, Ulawa Island AGAT=Uru Harbour=Atoifi, Malaita AGBA=Barakoma Airport=Barakoma AGBT=Batuna Airport=Batuna AGEV=Geva Airport=Geva AGGA=Auki Airport=Auki AGGB=Bellona/Anua Airport=Bellona/Anua AGGC=Choiseul Bay Airport=Choiseul Bay, Taro Island AGGD=Mbambanakira Airport=Mbambanakira AGGE=Balalae Airport=Shortland Island AGGF=Fera/Maringe Airport=Fera Island, Santa Isabel Island AGGG=Honiara FIR=Honiara, Guadalcanal AGGH=Honiara International Airport=Honiara, Guadalcanal AGGI=Babanakira Airport=Babanakira AGGJ=Avu Avu Airport=Avu Avu AGGK=Kirakira Airport=Kirakira AGGL=Santa Cruz/Graciosa Bay/Luova Airport=Santa Cruz/Graciosa Bay/Luova, Santa Cruz Island AGGM=Munda Airport=Munda, New Georgia Island AGGN=Nusatupe Airport=Gizo Island AGGO=Mono Airport=Mono Island AGGP=Marau Sound Airport=Marau Sound AGGQ=Ontong Java Airport=Ontong Java AGGR=Rennell/Tingoa Airport=Rennell/Tingoa, Rennell Island AGGS=Seghe Airport=Seghe AGGT=Santa Anna Airport=Santa Anna AGGU=Marau Airport=Marau AGGV=Suavanao Airport=Suavanao AGGY=Yandina Airport=Yandina AGIN=Isuna Heliport=Isuna AGKG=Kaghau Airport=Kaghau AGKU=Kukudu Airport=Kukudu AGOK=Gatokae Aerodrome=Gatokae AGRC=Ringi Cove Airport=Ringi Cove AGRM=Ramata Airport=Ramata ANYN=Nauru International Airport=Yaren (ICAO code formerly ANAU) AYBK=Buka Airport=Buka AYCH=Chimbu Airport=Kundiawa AYDU=Daru Airport=Daru -
Courses 5 to Play.Indd
COURSES Five to visit this month: High-class Italian resorts Courses of premium quality combine with a desirable climate, legendary cuisine, fine wine and convenient access to make these five complexes highly appealing to travelling golfers. To casual observers, Italy landing the 2022 Ryder Cup might have appeared as much a shot in the dark by the European Tour as if it had gone to Poland, Russia or Bulgaria. In fact, Italy has tremendous pedigree in the sport, and just as the 2018 Ryder Cup has helped shine a light on the wealth of courses – both traditional and modern – in France, the matches four years later ought to do the same in Italy. There are historic and modern courses established in our Top 100 and there are an increasing number of high-class resorts with a wealth of attractions on and off the course. Here are a quintet that we especially like. Bogogno, Piedmont Argentario, Tuscany Donnafugata, Sicily Grado, Friuli Venezia Castelfalfi , Tuscany It has a Top 100 and a Top 200 course plus A luxury retreat with a superb course in the A resort where golf (via two Top 200 Tenuta Primero is a comprehensive holiday There are 27 holes at Castelfalfi golf club, WHAT IS THE an intimate hotel. It was created by the Maremma, a beautiful but still-unexplored courses) truly is the top priority. There is a resort that is renowned in Italy. It is situated while Il Castelfalfi is a fi ve-star hotel being OVERVIEW OF THIS Robert von Hagge-Rick Baril axis of Les part of Southern Tuscany. -
Planetawinetour Service Charter 2016
PLANETAWINETOUR SERVICE CHARTER 2016 LA BARONIA ESTATE SCIARA NUOVA ESTATE ULMO ESTATE PALERMO MESSINA TRAPANI SAMBUCA DI SICILIA CATANIA CAPPARRINA OLIVE GROVE MENFI SIRACUSA NOTO BUONIVINI ESTATE DORILLI ESTATE DISPENSA ESTATE VITTORIA ULMO ESTATE DORILLI ESTATE Ulmo, in Sambuca di Sicilia, is the Planeta’s main Dorilli estate, in Vittoria, in the heart of the area of hospitality centre , dedicated to the knowledge and production of Cerasuolo di Vittoria, lies within the enhancement of Sicilian oenological richness. ancient Feudo di Torrenuova. The farmhouse, restored Here in 1995 the first winery was built, in a charming following the architecture of ‘900 century, has some landscape, between the Arancio Lake and the ancient rooms devoted to hospitality. farmhouse dated 1500 owned by the Planeta family. BUONIVINI ESTATE SCIARANUOVA ESTATE Buonivini estate in the Val di Noto is the synthesis of On the north slope of Etna Feudo di Mezzo winery was Planeta’s commitment to eco-sustainability and respect built on an historical lava flow of 1566, only using the of the territory. The winery is completely underground, lava stone, typical of the area. Sciaranuova estate, thus invisible, and the old wine press was restored few km away, is an old restored wine press, presently following the original architecture. It is possible to stay a wine shop and tasting room, beside the traditional in the Case Sparse, small country houses surrounded Ribatteria with wood stove and a kitchen for convivial by the vineyards. events. * On request it is also possible to visit Dispensa winery and Capparrina olive estate, in Menfi. La Baronia, in Capo Milazzo, is work in progress.