AI for Chrome Offline Dinosaur Game
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Location-Based Mobile Games
LOCATION-BASED MOBILE GAMES Creating a location-based game with Unity game engine LAB-UNIVERSITY OF APPLIED SCIENCES Engineer (AMK) Information and Communications Technology, Media technology Spring 2020 Samuli Korhola Tiivistelmä Tekijä(t) Julkaisun laji Valmistumisaika Korhola, Samuli Opinnäytetyö, AMK Kevät 2020 Sivumäärä 28 Työn nimi Sijaintipohjaisuus mobiilipeleissä Sijaintipohjaisen pelin kehitys Unity pelimoottorissa Tutkinto Tieto- ja viestintätekniikan insinööri. Tiivistelmä Tämän opinnäytetyön aiheena oli sijaintipohjaiset mobiilipelit. Sijaintipohjaiset mobiili- pelit ovat pelien tapa yhdistää oikea maailma virtuaalisen maailman kanssa ja täten ne luovat yhdessä aivan uuden pelikokemuksen. Tämä tutkimus syventyi teknologiaan ja työkaluihin, joilla kehitetään sijaintipohjaisia pelejä. Näihin sisältyy esimerkiksi GPS ja Bluetooth. Samalla työssä myös tutustuttiin yleisesti sijaintipohjaisten pelien ominaisuuksiin. Melkein kaikki tekniset ratkaisut, jotka oli esitetty opinnäytetyössä, olivat Moomin Move peliprojektin teknisiä ratkaisuja. Opinnäytetyön tuloksena tuli lisää mahdolli- suuksia kehittää Moomin Move pelin sijaintipohjaisia ominaisuuksia, kuten tuomalla kamerapohjaisia sijaintitekniikoita. Asiasanat Unity, sijaintipohjainen, mobiilipelit, GPS, Bluetooth Abstract Author(s) Type of publication Published Korhola, Samuli Bachelor’s thesis Spring 2020 Number of pages 28 Title of publication Location-based mobile games Creating a location-based game with the Unity game engine Name of Degree Bachelor of Information and Communications -
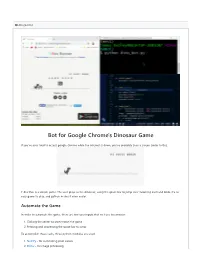
Bot for Google Chrome's Dinosaur Game
dino_bot.md Bot for Google Chrome's Dinosaur Game If you've ever tried to access google chrome while the internet is down, you've probably seen a screen simlar to this: T-Rex Run is a simple game. The user plays as the dinosaur, using the space bar to jump over incoming cacti and birds. It's an easy game to play, and python makes it even easier. Automate the Game In order to automate the game, there are two user inputs that we have to consider: 1. Clicking the center to start/restart the game 2. Pressing and unpressing the space bar to jump To accomplish these tasks, three python modules are used: 1. NumPy - for summating pixel values 2. Pillow - for image processing 3. PyAutoGUI - for controlling mouse and keyboard input Conceptual Overview The goal is to make the program able to analyze the area in front of the dinosaur and jump when something is in his way. The following image shows the two places that the program is using to do this: The blue rectangle is a reference to the area of the screen in front of the dinosaur that the bot is constantly running calculations on. As the game runs, the area in front of the dinosaur changes as obstacles approach. With Pillow, we're able to calculate the sum of the different pixel values specifically in the blue area in front of the dinosaur. When nothing is in front of the dinosaur, the value of the sum of these pixels represented by the blue rectangle is 1,447. -

Foundation Stage Medium Term Planning Summer Term 2018 Title: All Creatures Great and Small Memorable Experience: Dinosaur Egg and Bones to Be Found
Foundation Stage Medium Term Planning Summer Term 2018 Title: All Creatures Great and Small Memorable experience: dinosaur egg and bones to be found. Please note that EYFS Medium Term Planning is updated weekly to accommodate for children’s interests. Week C/L & Literacy Mathematics ,Topic Session 1 Topic Session 2 Topic session 3 Topic focus task Music/ICT session Week 1 Text: How to look after your Shape space and measure: Where have dinosaurs been Why are they extinct? How are dinosaurs similar and EAD: dinosaur craft Musci/PSHE/RE see scheme of 16/04/18 dinosaur by Jason Cockcroft weight and capacity found? Discuss what the word extinct different to animals we know Make dinosaur skeletons work. M- find a dinosaur egg and M- how much does the Look at a palaeontology dig means. Why did dinosaurs today? using pipe cleaners or pasta dinosaur bones. Who might dinosaur egg weigh compare online and how this is how we become extinct discuss Share pictures of alligators shapes. ICT: Use google Earth to they belong to? Read the with other objects and order. know that dinosaurs existed. theories. and crocodiles what features locate the places around the story. T- use balance scale to Look at a map of the world What other animals do we do these have that link them world that dinosaurs have T- Re-read the story and measure the weight of the and mark the places around know that are extinct? to dinosaurs? Look at a range been found compare to our discuss the things we need to egg. -
![Reinforcement Learning and Video Games Arxiv:1909.04751V1 [Cs.LG]](https://docslib.b-cdn.net/cover/5874/reinforcement-learning-and-video-games-arxiv-1909-04751v1-cs-lg-2395874.webp)
Reinforcement Learning and Video Games Arxiv:1909.04751V1 [Cs.LG]
University of Sheffield Reinforcement Learning and Video Games Yue Zheng Supervisor: Prof. Eleni Vasilaki A report submitted in partial fulfilment of the requirements for the degree of MSc Data Analytics in Computer Science in the arXiv:1909.04751v1 [cs.LG] 10 Sep 2019 Department of Computer Science September 12, 2019 i Declaration All sentences or passages quoted in this document from other people's work have been specif- ically acknowledged by clear cross-referencing to author, work and page(s). Any illustrations that are not the work of the author of this report have been used with the explicit permis- sion of the originator and are specifically acknowledged. I understand that failure to do this amounts to plagiarism and will be considered grounds for failure. Name: Yue Zheng Abstract Reinforcement learning has exceeded human-level performance in game playing AI with deep learning methods according to the experiments from DeepMind on Go and Atari games. Deep learning solves high dimension input problems which stop the development of reinforcement for many years. This study uses both two techniques to create several agents with different algorithms that successfully learn to play T-rex Runner. Deep Q network algorithm and three types of improvements are implemented to train the agent. The results from some of them are far from satisfactory but others are better than human experts. Batch normalization is a method to solve internal covariate shift problems in deep neural network. The positive influence of this on reinforcement learning has also been proved in this study. ii Acknowledgement I would like to express many thanks to my supervisor, Prof. -

Accessing Hid Devices on the Web with the Webhid Api How to Play the Chrome Dino Game by Jumping with a Nintendo Joy-Con Controller in One’S Pocket
Accessing hid Devices on the Web With the Webhid api How to play the Chrome Dino Game by Jumping With a Nintendo Joy-Con Controller in One’s Pocket Thomas Steiner François Beaufort [email protected] [email protected] Google Germany GmbH Google France sarl Hamburg, Germany Paris, France ABSTRACT 2 RELATED WORK In this demonstration, we show how special hardware like Nin- The Gamepad speci.cation [1] de.nes a low-level interface that tendo Joy-Con controllers can be made accessible from the Web represents gamepad devices and allows Web applications to di- through the new Webhid api. This novel technology proposal al- rectly act on gamepad data. Interfacing with external devices de- lows developers to write Web drivers in pure JavaScript that talk signed to control games has the potential to become large and in- to Human Interface Device (hid) devices via the hid protocol. One tractable if approached in full generality. The authors of the spec- such example of a driver has been realized in the project Joy-Con- i.cation explicitly chose to narrow the scope to provide a useful Webhid, which allows for fun pastimes like playing the Google subset of functionality that can be widely implemented and that is Chrome browser’s o&ine dinosaur game by jumping. This works broadly useful. Speci.cally, they chose to only support the func- thanks to the accelerometers built into Joy-Con controllers whose tionality required to support gamepads. Support for gamepads re- signals are read out by the driver and used to control the game quires two input types: buttons and axes. -
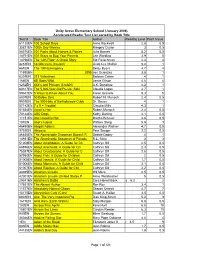
Test # Book Title Author Reading Level Point Value 61130EN 100
Unity Grove Elementary School (January 2006) Accelerated Reader Test List sorted by Book Title Test # Book Title Author Reading Level Point Value 61130EN 100 School Days Anne Rockwell 2.8 0.5 35821EN 100th Day Worries Margery Cuyler 3 0.5 56576EN 101 Facts About Horses & Ponies Julia Barnes 5.2 0.5 18751EN 101 Ways to Bug Your Parents Lee Wardlaw 3.9 5 14796EN The 13th Floor: A Ghost Story Sid Fleischman 4.4 4 8251EN 18-Wheelers (Cruisin') Linda Lee Maifair 5.2 1 661EN The 18th Emergency Betsy Byars 4.7 4 11592EN 2095 Jon Scieszka 3.8 1 6201EN 213 Valentines Barbara Cohen 4 1 166EN 4B Goes Wild Jamie Gilson 4.6 4 8252EN 4X4's and Pickups (Cruisin') A.K. Donahue 4.2 1 60317EN The 5,000-Year-Old Puzzle: Solvi Claudia Logan 4.7 1 59347EN 5 Ways to Know About You Karen Gravelle 8.3 5 8001EN 50 Below Zero Robert N. Munsch 2.4 0.5 9001EN The 500 Hats of Bartholomew Cubb Dr. Seuss 4 1 57142EN 7 x 9 = Trouble! Claudia Mills 4.3 1 51654EN Aaron's Hair Robert Munsch 2.4 0.5 70144EN ABC Dogs Kathy Darling 4.1 0.5 11151EN Abe Lincoln's Hat Martha Brenner 2.6 0.5 101EN Abel's Island William Steig 5.9 3 46490EN Abigail Adams Alexandra Wallner 4.7 0.5 9751EN Abiyoyo Pete Seeger 2.2 0.5 86635EN The Abominable Snowman Doesn't R Debbie Dadey 4 1 14931EN The Abominable Snowman of Pasade R.L. -

ED297505.Pdf
DOCUMENT RESUME ED 297 505 EC 210 356 AUTHOR Borden, Peter A., Ed.; Vanderheiden, Gregg C., Ed. TITLE Communication, Control, and Computer Access for Disabled and Elderly Individuals. ResourceBook 4: Update to Books I,2, and 3. INSTITUTION Wisconsin Univ., Madison. Trace Center. SPONS AGENCY National Inst. on Disability and Rehabilitation Research (ED/OSERS), Washington, DC. REPORT NO ISBN-0-945459-00-9 PUB DATE 88 GRANT G008300045 NOTE 385p.; A product of the Research and Pevelopment Center on Communications, Control, and Computer Access for Handicapped Individuals. For ResourceBooks 1-3, see ED 283 305-307. AVAILABLE FROM Trace Research and Development Center, S-151 Waisman Center, 1500 Highland Ave., Madison, WI 53705-2280 ($18.50). PUB TYPE Reference Materials Directories/Catalogs (132) EDRS PRICE MFO1 /PC16 Plus Postage. DESCRIPTORS *Accessibility (for Disabled); Braille; *Communication (Thought Transfer); Communication Aids (for Disabled); Computer Assisted Instruction; Computer Managed Instruction; Computer Printers; *Computer Software; *Disabilities; *Electronic Control; Input Output Devices; Keyboarding (Data Entry); Microcomputers; *Older Adults; Rehabilitation; Resources; Speech Synthesizers; Telecommunications IDENTIFIERS *Augmentative Communication Systems ABSTRACT This update to the three-volume first edition of the "Rehab/Education ResourceBook Series" describes special software and products pertaining to communication, control, and computer access, designed specifically for the needs of disabled and elderly people. The -
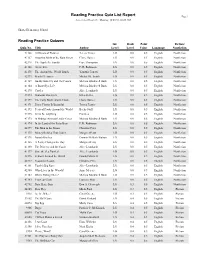
AR List by Book Level
Reading Practice Quiz List Report Page 1 Accelerated Reader®: Monday, 10/04/10, 08:24 AM Shasta Elementary School Reading Practice Quizzes Int. Book Point Fiction/ Quiz No. Title Author Level Level Value Language Nonfiction 41166 All Kinds of Flowers Teresa Turner LG 0.0 0.5 English Nonfiction 41167 Amazing Birds of the Rain Forest Claire Daniel LG 0.0 0.5 English Nonfiction 42378 The Apple Pie Family Gare Thompson LG 0.0 0.5 English Nonfiction 41168 Arctic Life F. R. Robinson LG 0.0 0.5 English Nonfiction 41178 The Around-the-World Lunch Yanitzia Canetti LG 0.0 0.5 English Nonfiction 42373 Beach Creatures Michael K. Smith LG 0.0 0.5 English Nonfiction 41169 Buddy Butterfly and His Cousin Melissa Blackwell Burke LG 0.0 0.5 English Nonfiction 41164 A Butterfly's Life Melissa Blackwell Burke LG 0.0 0.5 English Nonfiction 41170 Castles Alice Leonhardt LG 0.0 0.5 English Nonfiction 42374 Dinosaur Fun Facts Ellen Keller LG 0.0 0.5 English Nonfiction 41179 The Early Bird's Alarm Clock Claire Daniel LG 0.0 0.5 English Nonfiction 41171 Every Flower Is Beautiful Teresa Turner LG 0.0 0.5 English Nonfiction 41172 Festival Foods Around the World Becky Stull LG 0.0 0.5 English Nonfiction 42375 I Can Be Anything Ena Keo LG 0.0 0.5 English Nonfiction 41173 In Hiding: Animals Under Cover Melissa Blackwell Burke LG 0.0 0.5 English Nonfiction 41174 In the Land of the Polar Bear F. R. -
Test # Book Title Author Reading Level Point Value 7659EN
Unity Grove Elementary School (March 2007) Accelerated Reader Test List sorted by Author's last name Test # Book Title Author Reading Level Point Value 7659EN Borreguita and the Coyote Verna Aardema 3.1 0.5 9758EN Bringing the Rain to Kapiti Plai Verna Aardema 4.6 0.5 5550EN Why Mosquitoes Buzz in People's Verna Aardema 4 0.5 5365EN Great Summer Olympic Moments Nathan Aaseng 7.9 2 5366EN Great Winter Olympic Moments Nathan Aaseng 7.4 2 25533EN Sports Great Michael Jordan (Rev Nathan Aaseng 6.2 2 59553EN Bad Dog, Dodger! Barbara Abercrombi 2.6 0.5 109836E N Christopher Columbus and the Voy Dan Abnett 3.5 0.5 109839E N Hernán Cortés and the Fall of th Dan Abnett 3.4 0.5 66660EN John F. Kennedy and PT109 Philip Abraham 4.9 0.5 51153EN The U.S. Marine Corps at War Melissa Abramovitz 5.9 0.5 51154EN The U.S. Navy at War Melissa Abramovitz 5.6 0.5 12492EN The Night Crossing Karen Ackerman 5.3 1 5490EN Song and Dance Man Karen Ackerman 4 0.5 1038EN Daniel's Mystery Egg Alma Flor Ada 1.6 0.5 64100EN Daniel's Pet Alma Flor Ada 0.5 0.5 60902EN I Love Saturdays Y Domingos Alma Flor Ada 3.2 0.5 110197E N Usher Colleen Adams 6 0.5 5014EN Ghost Brother C.S. Adler 4.2 5 480EN The Magic of the Glits C.S. Adler 5.5 3 49786EN One Unhappy Horse C.S. Adler 4.4 5 8690EN Willie, the Frog Prince C.S. -

Postmortems from Game Developers.Pdf
POSTMORTEMS FROM Austin Grossman, editor San Francisco, CA • New York, NY • Lawrence, KS Published by CMP Books an imprint of CMP Media LLC Main office: 600 Harrison Street, San Francisco, CA 94107 USA Tel: 415-947-6615; fax: 415-947-6015 Editorial office: 1601 West 23rd Street, Suite 200, Lawrence, KS 66046 USA www.cmpbooks.com email: [email protected] Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where CMP is aware of a trademark claim, the product name appears in initial capital letters, in all capital letters, or in accordance with the vendor’s capitalization preference. Readers should contact the appropriate companies for more complete information on trademarks and trademark registrations. All trademarks and registered trademarks in this book are the property of their respective holders. Copyright © 2003 by CMP Media LLC, except where noted otherwise. Published by CMP Books, CMP Media LLC. All rights reserved. Printed in the United States of America. No part of this publication may be reproduced or distributed in any form or by any means, or stored in a database or retrieval system, without the prior written permission of the publisher; with the exception that the program listings may be entered, stored, and executed in a computer system, but they may not be reproduced for publication. The publisher does not offer any warranties and does not guarantee the accuracy, adequacy, or complete- ness of any information herein and is not responsible for any errors or omissions. The publisher assumes no liability for damages resulting from the use of the information in this book or for any infringement of the intellectual property rights of third parties that would result from the use of this information. -

Anukriti 2016
2016 AMITY UNIVERSITY VISION Building a nation and the society through providing total, integrated and trans- cultural quality education and be the global front runner in value education and nurturing the talent in which modernity blends with tradition. MISSION To provide education at all levels in all disciplines of modern times and the futuristic and emerging frontier areas of knowledge, and research and to develop the overall personality of students by making them not only excellent professionals but also good individuals, with understanding and regards for human values, pride in their heritage and culture, a sense of right and wrong and yearning for perfection and imbibe attributes of courage of conviction and action. Taking the Vision of Amity Business School forward under the guidance of Dr. Ashok K. Chauhan Founder President Heartiest Gratitude for Supporting & Trusting Our Efforts Shri Atul Chauhan President RBEF & Chancellor, Amity University Uttar Pradesh From the Desk of Dean-FMS & Director-Amity Business School Editor-in-Chief Dear Readers, Educatio is the ost powerful weapon which you can use to change the world - Nelson Mandela The aforementioned words of late Nelson Mandela inspire us to introduce new changes in the education system for continuous improvement. Amity being forerunners in education has always been an early adopter of revolutioary ideas like Choie Based Credit “yste or Outcome Based Education’. Outcome-based education will change the focus of curriculum from the content to the student, as all students can learn and succeed, but not on the same day or in the same way. Through these learner centric initiatives, the perception of what it means to be truly educated will change. -

Week Closure April 20Th-24Th
Week Closure April 20th-24th Thematic Unit: Our Planet-Earth Monday Reading: Trashy Town/Our Earth: Making Less Trash Scholastic . Use Scholastic Website https://bookflix.digital.scholastic.com/home?authCtx=U.794217314 . Select Family and Community . Select Trashy Town/Our Earth: Making Less Trash Watch/Read Both Stories Complete ONE of the following: Word Match, Fact or Fiction?, or Which Came First? o Submit a picture (ClassDojo) of completion Use Draw What You Saw Recording sheet and complete the following: o Draw one thing (with labels) from each story o Submit a scanned copy ([email protected]) or picture to ClassDojo . Complete 15 minutes of iReady reading minutes o Science: Everyday is Earth Day Starfall . Use Starfall website www.starfall.com o Username and Password was provided on ClassDojo . Select grades 1-3 . Select Earth symbol on right hand side o Practice reading the words independently, and then click to listen to them. o Sort the items to be recycled . Submit a photo to ClassDojo of you working on the activity. o Math: Sort by Shape Starfall . Use Starfall website www.starfall.com o Username and Password was provided on ClassDojo Select grades 1-3 o Select Geometry and Measurement (bottom left) o Select Button Sort (bottom left) o Complete activity at each level (easy, then medium, then hard) . Submit a photo to ClassDojo of working one lesson . Complete 15 minutes of iReady math minutes Tuesday Reading: Joseph Had a Little Overcoat/Recycle That! Scholastic . Use Scholastic Website https://bookflix.digital.scholastic.com/home?authCtx=U.794217314 . Select Earth and Sky .