Targeted Deep Sequencing in Multiple-Affected Sibships of European Ancestry Identifies
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genes Retina/RPE Choroid Sclera
Supplementary Materials: Genes Retina/RPE Choroid Sclera Fold Change p-value Fold Change p-value Fold Change p-value PPFIA2 NS NS 2.35 1.3X10-3 1.5 1.6X10-3 PTPRF 1.24 2.65X10-5 6.42 7X10-4 1.11 1X10-4 1.19 2.65X10-5 NS NS 1.11 3.3X10-3 PTPRR 1.44 2.65X10-5 3.04 4.7X10-3 NS NS Supplementary Table S1. Genes Differentially Expressed Related to Candidate Genes from Association. Genes selected for follow up validation by real time quantitative PCR. Multiple values for each gene indicate multiple probes within the same gene. NS indicates the fold change was not statistically significant. Gene/SNP Assay ID rs4764971 C__30866249_10 rs7134216 C__30023434_10 rs17306116 C__33218892_10 rs3803036 C__25749934_20 rs824311 C___8342112_10 PPFIA2 Hs00170308_m1 PTPRF Hs00160858_m1 PTPRR Hs00373136_m1 18S Hs03003631_g1 GAPDH Hs02758991_g1 Supplementary Table S2. Taqman® Genotyping and Gene Expression Assay Identification Numbers. SNP Chimp Orangutan Rhesus Marmoset Mouse Rat Cow Pig Guinea Pig Dog Elephant Opossum Chicken rs3803036 X X X X X X X X X X X X X rs1520562 X X X X X X rs1358228 X X X X X X X X X X X rs17306116 X X X X X X rs790436 X X X X X X X rs1558726 X X X X X X X X rs741525 X X X X X X X X rs7134216 X X X X X X rs4764971 X X X X X X X Supplementary Table S3. Conservation of Top SNPs from Association. X indicates SNP is conserved. -

Datasheet Blank Template
SAN TA C RUZ BI OTEC HNOL OG Y, INC . MTMR3 (N-20): sc-47187 BACKGROUND RECOMMENDED SECONDARY REAGENTS Myotubularin and the myotubularin-related proteins (MTMR1-9) belong to a To ensure optimal results, the following support (secondary) reagents are highly conserved family of eukaryotic phosphatases. They are protein tyrosine recommended: 1) Western Blotting: use donkey anti-goat IgG-HRP: sc-2020 phosphatases that utilize inositol phospholipids, rather than phosphoproteins, (dilution range: 1:2000-1:100,000) or Cruz Marker™ compatible donkey as substrates. MTMR family members hydrolyze both Phosphatidylinositol anti- goat IgG-HRP: sc-2033 (dilution range: 1:2000-1:5000), Cruz Marker™ 3-phosphate (PtdIns3P) and PtdIns P2. MTMR2 interacts with MTMR5, an Molecular Weight Standards: sc-2035, TBS Blotto A Blocking Reagent: inactive family member that increases the enzymatic activity of MTMR2 and sc-2333 and Western Blotting Luminol Reagent: sc-2048. 2) Immunoprecip- dictates its subcellular localization. Mutations in MTMR2 cause autosomal itation: use Protein A/G PLUS-Agarose: sc-2003 (0.5 ml agarose/2.0 ml). recessive Charcot-Marie-Tooth type 4B1 (CMT4B1), which is characterized 3) Immunofluorescence: use donkey anti-goat IgG-FITC: sc-2024 (dilution by reduced nerve conduction velocities, focally folded myelin sheaths and range: 1:100-1:400) or donkey anti-goat IgG-TR: sc-2783 (dilution range: demyelination. MTMR3 and MTMR4 can either interact with each other or self 1:100-1:400) with UltraCruz™ Mounting Medium: sc-24941. associate. MTMR6 regulates the activity of the calcium-activated potassium channel 3.1. MTMR9 regulates the activity of MTMR7 and MTMR8. -
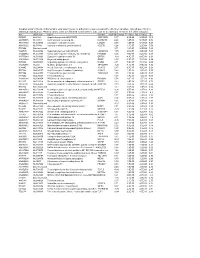
Supplementary File 2A Revised
Supplementary file 2A. Differentially expressed genes in aldosteronomas compared to all other samples, ranked according to statistical significance. Missing values were not allowed in aldosteronomas, but to a maximum of five in the other samples. Acc UGCluster Name Symbol log Fold Change P - Value Adj. P-Value B R99527 Hs.8162 Hypothetical protein MGC39372 MGC39372 2,17 6,3E-09 5,1E-05 10,2 AA398335 Hs.10414 Kelch domain containing 8A KLHDC8A 2,26 1,2E-08 5,1E-05 9,56 AA441933 Hs.519075 Leiomodin 1 (smooth muscle) LMOD1 2,33 1,3E-08 5,1E-05 9,54 AA630120 Hs.78781 Vascular endothelial growth factor B VEGFB 1,24 1,1E-07 2,9E-04 7,59 R07846 Data not found 3,71 1,2E-07 2,9E-04 7,49 W92795 Hs.434386 Hypothetical protein LOC201229 LOC201229 1,55 2,0E-07 4,0E-04 7,03 AA454564 Hs.323396 Family with sequence similarity 54, member B FAM54B 1,25 3,0E-07 5,2E-04 6,65 AA775249 Hs.513633 G protein-coupled receptor 56 GPR56 -1,63 4,3E-07 6,4E-04 6,33 AA012822 Hs.713814 Oxysterol bining protein OSBP 1,35 5,3E-07 7,1E-04 6,14 R45592 Hs.655271 Regulating synaptic membrane exocytosis 2 RIMS2 2,51 5,9E-07 7,1E-04 6,04 AA282936 Hs.240 M-phase phosphoprotein 1 MPHOSPH -1,40 8,1E-07 8,9E-04 5,74 N34945 Hs.234898 Acetyl-Coenzyme A carboxylase beta ACACB 0,87 9,7E-07 9,8E-04 5,58 R07322 Hs.464137 Acyl-Coenzyme A oxidase 1, palmitoyl ACOX1 0,82 1,3E-06 1,2E-03 5,35 R77144 Hs.488835 Transmembrane protein 120A TMEM120A 1,55 1,7E-06 1,4E-03 5,07 H68542 Hs.420009 Transcribed locus 1,07 1,7E-06 1,4E-03 5,06 AA410184 Hs.696454 PBX/knotted 1 homeobox 2 PKNOX2 1,78 2,0E-06 -

Lineage-Specific Programming Target Genes Defines Potential for Th1 Temporal Induction Pattern of STAT4
Downloaded from http://www.jimmunol.org/ by guest on October 1, 2021 is online at: average * The Journal of Immunology published online 26 August 2009 from submission to initial decision 4 weeks from acceptance to publication J Immunol http://www.jimmunol.org/content/early/2009/08/26/jimmuno l.0901411 Temporal Induction Pattern of STAT4 Target Genes Defines Potential for Th1 Lineage-Specific Programming Seth R. Good, Vivian T. Thieu, Anubhav N. Mathur, Qing Yu, Gretta L. Stritesky, Norman Yeh, John T. O'Malley, Narayanan B. Perumal and Mark H. Kaplan Submit online. Every submission reviewed by practicing scientists ? is published twice each month by http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://www.jimmunol.org/content/suppl/2009/08/26/jimmunol.090141 1.DC1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* • Why • • Material Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2009 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of October 1, 2021. Published August 26, 2009, doi:10.4049/jimmunol.0901411 The Journal of Immunology Temporal Induction Pattern of STAT4 Target Genes Defines Potential for Th1 Lineage-Specific Programming1 Seth R. Good,2* Vivian T. Thieu,2† Anubhav N. Mathur,† Qing Yu,† Gretta L. -

MTMR3 Is Upregulated in Patients with Breast Cancer and Regulates Proliferation, Cell Cycle Progression and Autophagy in Breast Cancer Cells
ONCOLOGY REPORTS 42: 1915-1923, 2019 MTMR3 is upregulated in patients with breast cancer and regulates proliferation, cell cycle progression and autophagy in breast cancer cells ZHAN WANG1*, MIN ZHANG1*, RONG SHAN1, YU-JIE WANG1, JUAN CHEN2, JUAN HUANG3, LUN-QUAN SUN4 and WEI-BING ZHOU1 1Department of Oncology, 2Department of Pharmacy, 3Hunan Province Clinic Meditech Research Center for Breast Cancer, and 4Center for Molecular Medicine, Xiangya Hospital, Central South University, Changsha, Hunan 410008, P.R. China Received April 9, 2019; Accepted July 23, 2019 DOI: 10.3892/or.2019.7292 Abstract. As a member of the myotubularin family, myotu- Introduction bularin related protein 3 (MTMR3) has been demonstrated to participate in tumor development, including oral and colon Breast cancer is the second leading cause of cancer-related cancer. However, little is known about its functional roles in deaths in women, and the incidence of breast is estimated breast cancer. In the present study, the expression of MTMR3 in to increase by ~0.5% annually (1,2). Despite enormous breast cancer was evaluated by immunohistochemical staining progress on breast cancer therapy, 20% of patients eventu- of tumor tissues from 172 patients. Online data was then ally die of their disease (3,4). Multiple studies have revealed used for survival analysis from the PROGgeneV2 database. that breast cancer is a heterogeneous and complex disease, In vitro, MTMR3 expression was silenced in MDA-MB-231 whose pathophysiology cannot be explained by one or several cells via lentiviral shRNA transduction. MTT, colony forma- mechanisms (5). A number of reliable biological markers have tion and flow cytometry assays were performed in the control been found to predict the risk of recurrence and metastasis and MTMR3-silenced cells to evaluate the cell growth, of breast cancer. -

Abnormal Spermatogenesis and Reduced Fertility in Transition Nuclear Protein 1-Deficient Mice
Abnormal spermatogenesis and reduced fertility in transition nuclear protein 1-deficient mice Y. Eugene Yu*†,Yun Zhang*, Emmanual Unni*‡, Cynthia R. Shirley*, Jian M. Deng§, Lonnie D. Russell¶, Michael M. Weil*, Richard R. Behringer§, and Marvin L. Meistrich*ʈ Departments of *Experimental Radiation Oncology, and §Molecular Genetics, University of Texas M. D. Anderson Cancer Center, Houston, TX 77030-4095; and ¶Department of Physiology, Southern Illinois University, School of Medicine, Carbondale, IL 62901 Edited by Richard D. Palmiter, University of Washington School of Medicine, Seattle, WA, and approved February 22, 2000 (received for review May 3, 1999) Transition nuclear proteins (TPs), the major proteins found in (15), suggesting some functional relationship between the three chromatin of condensing spermatids, are believed to be important proteins exists. Tnp1, however, is on a separate chromosome and for histone displacement and chromatin condensation during is not clearly related to the other three proteins. mammalian spermatogenesis. We generated mice lacking the ma- In vitro, TP1 decreases the melting temperature of DNA (16) jor TP, TP1, by targeted deletion of the Tnp1 gene in mouse and relaxes the DNA in nucleosomal core particles (17), which embryonic stem cells. Surprisingly, testis weights and sperm pro- led to the proposal that TP1 reduces the interaction of DNA duction were normal in the mutant mice, and only subtle abnor- with the nucleosome core. In contrast, TP2 increases the malities were observed in sperm morphology. Electron microscopy melting temperature of DNA and compacts the DNA in revealed large rod-like structures in the chromatin of mutant step nucleosomal cores, suggesting that it is a DNA-condensing 13 spermatids, in contrast to the fine chromatin fibrils observed in protein (18). -

MTMR3 Risk Allele Enhances Innate Receptor-Induced Signaling and Cytokines by Decreasing Autophagy and Increasing Caspase-1 Activation
MTMR3 risk allele enhances innate receptor-induced signaling and cytokines by decreasing autophagy and increasing caspase-1 activation Amit Lahiri, Matija Hedl, and Clara Abraham1 Department of Medicine, Yale University, New Haven, CT 06511 Edited by David Artis, Weill Cornell Medical College, New York, NY, and accepted by the Editorial Board July 10, 2015 (received for review January 27, 2015) Inflammatory bowel disease (IBD) is characterized by dysregulated primary human cells, where responses can be dramatically different host:microbial interactions and cytokine production. Host pattern (8), has not been examined. Given the importance of PRR regu- recognition receptors (PRRs) are critical in regulating these interactions. lation in intestinal tissues and the ability of autophagy to modulate Multiple genetic loci are associated with IBD, but altered functions for PRR-initiated outcomes, we hypothesized that MTMR3 would most, including in the rs713875 MTMR3/HORMAD2/LIF/OSM region, are regulate PRR-induced autophagy and thereby PRR-induced sig- unknown. We identified a previously undefined role for myotubularin- naling and cytokine secretion. We further hypothesized that the related protein 3 (MTMR3) in amplifying PRR-induced cytokine secre- IBD-associated polymorphisms in the MTMR3/HORMAD2/LIF/ tion in human macrophages and defined MTMR3-initiated mechanisms OSM region would modulate these outcomes. contributing to this amplification. MTMR3 decreased PRR-induced In this study, we identified a role for MTMR3 in PRR-initiated phosphatidylinositol 3-phosphate (PtdIns3P) and autophagy levels, responses in primary human macrophages. Upon PRR stimulation, β thereby increasing PRR-induced caspase-1 activation, autocrine IL-1 MTMR3 decreased PtdIns3P levels and autophagy, which in turn κ secretion, NF B signaling, and, ultimately, overall cytokine secretion. -

Supplementary Table 1
Supplementary Table 1. 492 genes are unique to 0 h post-heat timepoint. The name, p-value, fold change, location and family of each gene are indicated. Genes were filtered for an absolute value log2 ration 1.5 and a significance value of p ≤ 0.05. Symbol p-value Log Gene Name Location Family Ratio ABCA13 1.87E-02 3.292 ATP-binding cassette, sub-family unknown transporter A (ABC1), member 13 ABCB1 1.93E-02 −1.819 ATP-binding cassette, sub-family Plasma transporter B (MDR/TAP), member 1 Membrane ABCC3 2.83E-02 2.016 ATP-binding cassette, sub-family Plasma transporter C (CFTR/MRP), member 3 Membrane ABHD6 7.79E-03 −2.717 abhydrolase domain containing 6 Cytoplasm enzyme ACAT1 4.10E-02 3.009 acetyl-CoA acetyltransferase 1 Cytoplasm enzyme ACBD4 2.66E-03 1.722 acyl-CoA binding domain unknown other containing 4 ACSL5 1.86E-02 −2.876 acyl-CoA synthetase long-chain Cytoplasm enzyme family member 5 ADAM23 3.33E-02 −3.008 ADAM metallopeptidase domain Plasma peptidase 23 Membrane ADAM29 5.58E-03 3.463 ADAM metallopeptidase domain Plasma peptidase 29 Membrane ADAMTS17 2.67E-04 3.051 ADAM metallopeptidase with Extracellular other thrombospondin type 1 motif, 17 Space ADCYAP1R1 1.20E-02 1.848 adenylate cyclase activating Plasma G-protein polypeptide 1 (pituitary) receptor Membrane coupled type I receptor ADH6 (includes 4.02E-02 −1.845 alcohol dehydrogenase 6 (class Cytoplasm enzyme EG:130) V) AHSA2 1.54E-04 −1.6 AHA1, activator of heat shock unknown other 90kDa protein ATPase homolog 2 (yeast) AK5 3.32E-02 1.658 adenylate kinase 5 Cytoplasm kinase AK7 -

Epigenetic Mechanisms Are Involved in the Oncogenic Properties of ZNF518B in Colorectal Cancer
Epigenetic mechanisms are involved in the oncogenic properties of ZNF518B in colorectal cancer Francisco Gimeno-Valiente, Ángela L. Riffo-Campos, Luis Torres, Noelia Tarazona, Valentina Gambardella, Andrés Cervantes, Gerardo López-Rodas, Luis Franco and Josefa Castillo SUPPLEMENTARY METHODS 1. Selection of genomic sequences for ChIP analysis To select the sequences for ChIP analysis in the five putative target genes, namely, PADI3, ZDHHC2, RGS4, EFNA5 and KAT2B, the genomic region corresponding to the gene was downloaded from Ensembl. Then, zoom was applied to see in detail the promoter, enhancers and regulatory sequences. The details for HCT116 cells were then recovered and the target sequences for factor binding examined. Obviously, there are not data for ZNF518B, but special attention was paid to the target sequences of other zinc-finger containing factors. Finally, the regions that may putatively bind ZNF518B were selected and primers defining amplicons spanning such sequences were searched out. Supplementary Figure S3 gives the location of the amplicons used in each gene. 2. Obtaining the raw data and generating the BAM files for in silico analysis of the effects of EHMT2 and EZH2 silencing The data of siEZH2 (SRR6384524), siG9a (SRR6384526) and siNon-target (SRR6384521) in HCT116 cell line, were downloaded from SRA (Bioproject PRJNA422822, https://www.ncbi. nlm.nih.gov/bioproject/), using SRA-tolkit (https://ncbi.github.io/sra-tools/). All data correspond to RNAseq single end. doBasics = TRUE doAll = FALSE $ fastq-dump -I --split-files SRR6384524 Data quality was checked using the software fastqc (https://www.bioinformatics.babraham. ac.uk /projects/fastqc/). The first low quality removing nucleotides were removed using FASTX- Toolkit (http://hannonlab.cshl.edu/fastxtoolkit/). -

Machado Renatoassis M.Pdf
RENATO ASSIS MACHADO “ASSOCIAÇÃO DOS POLIMORFISMOS NOS GENES HOXD1, TNP1, MSX1, TCOF1, FGFR1, COL2A1, WNT3 E TIMP3 COM FISSURAS DE LÁBIO E/OU PALATO NÃO-SINDRÔMICA EM UMA POPULAÇÃO BRASILEIRA” PIRACICABA 2015 i ii UNIVERSIDADE ESTADUAL DE CAMPINAS FACULDADE DE ODONTOLOGIA DE PIRACICABA RENATO ASSIS MACHADO “ASSOCIAÇÃO DOS POLIMORFISMOS NOS GENES HOXD1, TNP1, MSX1, TCOF1, FGFR1, COL2A1, WNT3 E TIMP3 COM FISSURAS DE LÁBIO E/OU PALATO NÃO-SINDRÔMICA EM UMA POPULAÇÃO BRASILEIRA” Dissertação apresentada à Faculdade de Odontologia de Piracicaba da Universidade Estadual de Campinas para a obtenção do título de Mestre em Estomatopatologia, na Área de Patologia. Orientador: Prof. Dr. Ricardo Della Coletta Coorientador: Prof. Dr. Hercilio Martelli Junior Este exemplar corresponde a versão final da dissertação defendida por Renato Assis Machado e orientada pelo Prof. Dr. Ricardo Della Coletta. ____________________________________ Assinatura do orientador PIRACICABA 2015 iii Ficha catalográfica Universidade Estadual de Campinas Biblioteca da Faculdade de Odontologia de Piracicaba Marilene Girello - CRB 8/6159 Machado, Renato Assis, 1989- M18a MacAssociação dos polimorfismos nos genes HOXD1, TNP1, MSX1, TCOF1, FGFR1, COL2A1, WNT3 e TIMP3 com fissuras de lábio e/ou palato não- sindrômica em uma população brasileira / Renato Assis Machado. – Piracicaba, SP : [s.n.], 2015. MacOrientador: Ricardo Della Coletta. MacCoorientador: Hercilio Martelli Junior. MacDissertação (mestrado) – Universidade Estadual de Campinas, Faculdade de Odontologia de Piracicaba. -

Induction of Therapeutic Tissue Tolerance Foxp3 Expression Is
Downloaded from http://www.jimmunol.org/ by guest on October 2, 2021 is online at: average * The Journal of Immunology , 13 of which you can access for free at: 2012; 189:3947-3956; Prepublished online 17 from submission to initial decision 4 weeks from acceptance to publication September 2012; doi: 10.4049/jimmunol.1200449 http://www.jimmunol.org/content/189/8/3947 Foxp3 Expression Is Required for the Induction of Therapeutic Tissue Tolerance Frederico S. Regateiro, Ye Chen, Adrian R. Kendal, Robert Hilbrands, Elizabeth Adams, Stephen P. Cobbold, Jianbo Ma, Kristian G. Andersen, Alexander G. Betz, Mindy Zhang, Shruti Madhiwalla, Bruce Roberts, Herman Waldmann, Kathleen F. Nolan and Duncan Howie J Immunol cites 35 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription http://www.jimmunol.org/content/suppl/2012/09/17/jimmunol.120044 9.DC1 This article http://www.jimmunol.org/content/189/8/3947.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2012 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of October 2, 2021. -

Lineage-Specific Effector Signatures of Invariant NKT Cells Are Shared Amongst Δγ T, Innate Lymphoid, and Th Cells
Downloaded from http://www.jimmunol.org/ by guest on September 26, 2021 δγ is online at: average * The Journal of Immunology , 10 of which you can access for free at: 2016; 197:1460-1470; Prepublished online 6 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600643 http://www.jimmunol.org/content/197/4/1460 Lineage-Specific Effector Signatures of Invariant NKT Cells Are Shared amongst T, Innate Lymphoid, and Th Cells You Jeong Lee, Gabriel J. Starrett, Seungeun Thera Lee, Rendong Yang, Christine M. Henzler, Stephen C. Jameson and Kristin A. Hogquist J Immunol cites 41 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription http://www.jimmunol.org/content/suppl/2016/07/06/jimmunol.160064 3.DCSupplemental This article http://www.jimmunol.org/content/197/4/1460.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 26, 2021. The Journal of Immunology Lineage-Specific Effector Signatures of Invariant NKT Cells Are Shared amongst gd T, Innate Lymphoid, and Th Cells You Jeong Lee,* Gabriel J.