Internationalized Domain Names-Tamil
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

75 Characters Maximum
Kannada Script LGR Proposal Introduction, Current Analysis and Next Steps Dr. U.B. Pavanaja NBGP F2F Meeting, Colombo 14 December 2017 | 1 Agenda 1 2 3 Introduction to Repertoire Analysis Within Script Kannada Script Variants 4 5 6 Cross-Script WLE Rules Current Status and Variants Next Steps for Completion | 2 Introduction to Kannada Script Population – there are about 60 million speakers of Kannada language which uses Kannada script. Geographical area - Kannada is spoken predominantly by the people of Karnataka State of India. It is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad Languages written in Kannada script – Kannada, Tulu, Kodava (Coorgi), Konkani, Havyaka, Sanketi, Beary (byaari), Arebaase, Koraga | 3 Classification of Characters Swaras (vowels) Letter ಅ ಆ ಇ ಈ ಉ ಊ ಋ ಎ ಏ ಐ ಒ ಓ ಔ Vowel sign/ N/Aಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ matra Yogavahas In Kannada, all consonants Anusvara ಅಂ (vyanjanas) when written as ಕ (ka), ಖ (kha), ಗ (ga), etc. actually have a built-in vowel sign (matra) Visarga ಅಃ of vowel ಅ (a) in them. | 4 Classification of Characters Vargeeya vyanjana (structured consonants) voiceless voiceless aspirate voiced voiced aspirate nasal Velars ಕ ಖ ಗ ಘ ಙ Palatals ಚ ಛ ಜ ಝ ಞ Retroflex ಟ ಠ ಡ ಢ ಣ Dentals ತ ಥ ದ ಧ ನ Labials ಪ ಫ ಬ ಭ ಮ Avargeeya vyanjana (unstructured consonants) ಯ ರ ಱ (obsolete) ಲ ವ ಶ ಷ ಸ ಹ ಳ ೞ (obsolete) | 5 Repertoire Included-1 Sr. Unicode Glyph Character Name Unicode Indic Ref Widespread No. Code General Syllabic use ? Point Category Category [Yes/No] 1 0C82 ಂ KANNADA SIGN ANUSVARA Mc Anusvara Yes 2 0C83 ಂ KANNADA SIGN VISARGA Mc Visarga Yes 3 0C85 ಅ KANNADA LETTER A Lo Vowel Yes 4 0C86 ಆ KANNADA LETTER AA Lo Vowel Yes 5 0C87 ಇ KANNADA LETTER I Lo Vowel Yes 6 0C88 ಈ KANNADA LETTER II Lo Vowel Yes 7 0C89 ಉ KANNADA LETTER U Lo Vowel Yes 8 0C8A ಊ KANNADA LETTER UU Lo Vowel Yes KANNADA LETTER VOCALIC 9 0C8B ಋ R Lo Vowel Yes 10 0C8E ಎ KANNADA LETTER E Lo Vowel Yes | 6 Repertoire Included-2 Sr. -

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -

Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-04-22 Document version: 2.7 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract This document lays down the Label Generation Ruleset for Gurmukhi script. Three main components of the Gurmukhi Script LGR i.e. Code point repertoire, Variants and Whole Label Evaluation Rules have been described in detail here. All these components have been incorporated in a machine-readable format in the accompanying XML file named "proposal-gurmukhi-lgr-22apr19-en.xml". In addition, a document named “gurmukhi-test-labels-22apr19-en.txt” has been provided. It provides a list of labels which can produce variants as laid down in Section 6 of this document and it also provides valid and invalid labels as per the Whole Label Evaluation laid down in Section 7. 2. Script for which the LGR is proposed ISO 15924 Code: Guru ISO 15924 Key N°: 310 ISO 15924 English Name: Gurmukhi Latin transliteration of native script name: gurmukhī Native name of the script: ਗੁਰਮੁਖੀ Maximal Starting Repertoire [MSR] version: 4 1 3. Background on Script and Principal Languages Using It 3.1. The Evolution of the Script Like most of the North Indian writing systems, the Gurmukhi script is a descendant of the Brahmi script. The Proto-Gurmukhi letters evolved through the Gupta script from 4th to 8th century, followed by the Sharda script from 8th century onwards and finally adapted their archaic form in the Devasesha stage of the later Sharda script, dated between the 10th and 14th centuries. -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

"9-41516)9? "9787:)4 ;7 -6+7,- )=1 16 ;0- & $
L2/20-256 "9-41516)9?"9787:)4;7-6+7,-)=116;0-&$ ᭛᭜᭛ <;079 ,1;?))?<"-9,)6)215-14,7;3755/5)14+75 40)5 <9=)6:)0140)56<9=)6:)0/5)14+75 );- ;0$-8;-5*-9 6;97,<+;176 ,=:#6L>H8G>EI>H6=>HIDG>86AG6=B>76H:9H8G>EI;DJC9>CK6G>DJH>CH8G>EI>DCH6C96GI:;68IHEGD9J8:97:IL::CI=: I=6C9I=: I=8:CIJGN>C>CHJA6G+DJI=:6HIH>6A6G<:EDGI>DCD;>IH8DGEJH>H;DJC9>C"6K67JI#6L>B6I:G>6AH =6K:6AHD7::C;DJC9>C+JB6IG6%6A6N(:C>CHJA66A>6C9I=:(=>A>EE>C:H,=:H8G>EI>H;G:FJ:CIAN6HHD8>6I:9L>I= I=:'A9"6K6C:H:A6C<J6<:7JIB6I:G>6AHLG>II:C>C+6CH@G>I'A9%6A6N'A96A>C:H:6C9'A9+JC96C:H:A6C<J6<: =6H6AHD7::C;DJC9>CI=:#6L>H8G>EIGDBI=:B>9I=8:CIJGNH>BEA:;JC8I>DC6A#6L>L6HL>9:ANJH:9IDG:8DG9 A6C9 <G6CIH GDN6A :9>8IH 6C9 H>B>A6G 8=6C8:GN 9D8JB:CIH ,DL6G9H I=: :C9 D; I=: ;>GHI B>AA:CC>JB I=: H8G>EI 7:86B:>C8G:6H>C<AN9:8DG6I>K:6C986AA><G6E=>89J:ID>IHJH:6HI=:B6>CK:=>8A:D;'A9"6K6C:H:A>I:G6GNA6C<J6<: L>I=ADC<A6HI>C<A:<68N>CI=:A>I:G6GNIG69>I>DCD;I=:BD9:GC"6K6C:H:6C96A>C:H:A6C<J6<:H$6I:G#6L>H=DLH B6CNK6G>6I>DCHDK:G6L>9:<:D<G6E=>89>HIG>7JI>DC'K:GI>B:I=:H:K6G>6CIH=6K::KDAK:9>G:8IANDG>C9>G:8IAN >CIDI=:B6CNBD9:GCG6=B>8H8G>EIHD;>CHJA6G+H>6HJ8=6H6A>C:H:6I6@"6K6C:H:$DCI6G6:I8 /=>A:I=:68I>K:JH:D;#6L>H8G>EI=6H7::CG:EA68:97NDI=:GH8G>EIHH>C8:I=: I=8:CIJGNI=:G:6G:6CJB7:GD; BD9:GC96N:CI=JH>6HIH6C98DBBJC>I>:HL=DJH:I=:H8G>EIID96N;DGDI=:GEJGEDH:HI=6C6C8>:CIG:EGD9J8I>DC ;DG:M6BEA:ID8=6I>CHD8>6A6EEA>86I>DC6C98G:6I:>B6<:EDHIH!CI=>HG:K>K6AINE:D;JH:I=:#6L>H8G>EIB6N7: JH:9IDLG>I:A6C<J6<:HI=6I6G:CDI;DJC9>C‘6JI=:CI>8’#6L>8DGEJHHJ8=6HI=:BD9:GC"6K6C:H:A6C<J6<:DG I=: !C9DC:H>6C A6C<J6<: H#6L>=6H CDI 7::C :C8D9:9>C I=: -C>8D9: N:I I=: -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -
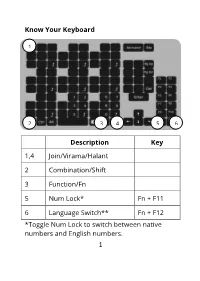
Know Your Keyboard Description Key 1,4 Join/Virama/Halant 2
Know Your Keyboard 1 2 3 4 5 6 Description Key 1,4 Join/Virama/Halant 2 Combination/Shift 3 Function/Fn 5 Num Lock* Fn + F11 6 Language Switch** Fn + F12 *Toggle Num Lock to switch between native numbers and English numbers. 1 ** Language Switch works on Windows, Linux and Android. For macOS, a configuration in settings is required. Note: If numbers are appearing in English, turn off Num Lock. Connecting Your Keyboard To Computer – Plug-in the cable to USB port on your computer. To Android Phone/Tablet 3 2 1 Use USB-to-OTG connector to plug-in keyboard. 2 Language and Layout You can use one keyboard to type multiple languages. You need to install at least one language to type. Language Layout Bengali Ka-Naada Bengali Keyboard Assamese Devanagari Sanskrit Hindi Ka-Naada Hindi Keyboard Marathi Neapli English Ka-Naada English Keyboard Guajarati Ka-Naada Guajarati Keyboard Kannada Ka-Naada Kannada Keyboard Malayalam Ka-Naada Malayalam Keyboard Tulu Odiya Ka-Naada Odiya Keyboard Panjabi Ka-Naada Gurmukhi Keyboard Telugu Ka-Naada Telugu Keyboard 3 Note: You need to switch to Ka-Naada input language before typing. Note: To switch between the languages you’re using, repeatedly press Language Switch key to cycle through all your installed languages. Language Pack Installation Go to https://ka-naada.com/downloads/ and click on the “Download” button in front of your operating system. Installation – Windows 1. Open your “Downloads” folder and locate “kanaada_keyboards.zip”. 2. Right click on zip file and choose “Extract Here” from the option menu. 3. -

Analysis of Comments for Telugu Script LGR Proposal for the Root Zone Revision: June 30, 2019
Neo-Brahmi Generation Panel: Analysis of comments for Telugu script LGR Proposal for the Root Zone Revision: June 30, 2019 Neo-Brahmi Generation Panel (NBGP) published the Telugu script LGR Propsoal for the Root Zone for public comment on 8 August 2018. This document is an additional document of the public comment report, collecting NBGP analyses as well as the concluded responses. There is 1 (one) comment submission. The analysis is as follow: No. 1 From Liang Hai Subject A Quick review of the Telugu proposal Comment 2, “telɯgɯ”: This is probably a phonetic transcription, not an accurate transliteration that should be used in this document. NBGP The NBGP acknowledges the comment. Analysis NBGP Updated the proposal in section 2 to use ‘Telugu’ Response Comment 3.5, “… and 16 dependent signs”: 15. NBGP There are 16 Matras: 14 Matras are in the repertoire, 2 Matras are Analysis excluded from the repertoire. NBGP No action required. Response Comment 3.5.1: Vocalic l should be categorized with vocalic rr and vocalic ll. Transliteration of vocalic ll is wrong. NBGP Agree. Analysis NBGP Update as suggested. Response 1 Comment 3.5.1, R1, “ca= a consonant with an inherent ‘a’”: When discussing text encoding, Indic consonants naturally are with an inherent vowel. Try to distinguish phonetic seQuence and written forms and encoded character sequence. The 3 lines under R1 are not helpful. NBGP The comment does not affect the normative part of the LGR. Analysis NBGP No action required. Response Comment 3.5.3: The introduction of arasunna usage is unclear. Is it commonly used today or not? NBGP The arsunna is not used frequently and it is not in the MSR. -

The Unicode Standard, Version 4.0--Online Edition
This PDF file is an excerpt from The Unicode Standard, Version 4.0, issued by the Unicode Consor- tium and published by Addison-Wesley. The material has been modified slightly for this online edi- tion, however the PDF files have not been modified to reflect the corrections found on the Updates and Errata page (http://www.unicode.org/errata/). For information on more recent versions of the standard, see http://www.unicode.org/standard/versions/enumeratedversions.html. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The Unicode® Consortium is a registered trademark, and Unicode™ is a trademark of Unicode, Inc. The Unicode logo is a trademark of Unicode, Inc., and may be registered in some jurisdictions. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

N4185 Preliminary Proposal to Encode Siddham in ISO/IEC 10646
ISO/IEC JTC1/SC2/WG2 N4185 L2/12-011R 2012-05-03 Preliminary Proposal to Encode Siddham in ISO/IEC 10646 Anshuman Pandey Department of History University of Michigan Ann Arbor, Michigan, U.S.A. [email protected] May 3, 2012 1 Introduction This is a preliminary proposal to encode the Siddham script in the Universal Character Set (ISO/IEC 10646). It is a collaborative effort between the Script Encoding Initiative (SEI) at the University of California, Berke- ley and the Shingon Buddhist International Institute, Fresno, California. Feedback is requested from experts and users of the script. Comments may be submitted to the author at the email address given above. Siddham is a Brahmi-based writing system that originated in India, but which is used primarily in East Asia. At present it is associated with esoteric Buddhist traditions in Japan. Nevertheless, Siddham is structurally an Indic script and its proposed encoding adheres to the UCS model for Brahmi-based writing systems, such as Devanagari and similar scripts. The technical description for Siddham given here may differ from the traditional analysis and philosophical interpretations of the script and its constituent characters and glyphs. An attempt has been made to encode all distinct characters attested in Siddham records, although more characters may be uncovered through additional research. The characters that are proposed for encoding have been analyzed in accordance with the character-glyph model of the UCS. As a result, the proposed encoding may contain characters that are not part of traditional character repertoires. It may also exclude characters that are traditionally regarded as independent letters, such as conjuncts, which are to be represented in the manner specified by the UCS encoding model. -

Introduction to Old Javanese Language and Literature: a Kawi Prose Anthology
THE UNIVERSITY OF MICHIGAN CENTER FOR SOUTH AND SOUTHEAST ASIAN STUDIES THE MICHIGAN SERIES IN SOUTH AND SOUTHEAST ASIAN LANGUAGES AND LINGUISTICS Editorial Board Alton L. Becker John K. Musgrave George B. Simmons Thomas R. Trautmann, chm. Ann Arbor, Michigan INTRODUCTION TO OLD JAVANESE LANGUAGE AND LITERATURE: A KAWI PROSE ANTHOLOGY Mary S. Zurbuchen Ann Arbor Center for South and Southeast Asian Studies The University of Michigan 1976 The Michigan Series in South and Southeast Asian Languages and Linguistics, 3 Open access edition funded by the National Endowment for the Humanities/ Andrew W. Mellon Foundation Humanities Open Book Program. Library of Congress Catalog Card Number: 76-16235 International Standard Book Number: 0-89148-053-6 Copyright 1976 by Center for South and Southeast Asian Studies The University of Michigan Printed in the United States of America ISBN 978-0-89148-053-2 (paper) ISBN 978-0-472-12818-1 (ebook) ISBN 978-0-472-90218-7 (open access) The text of this book is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License: https://creativecommons.org/licenses/by-nc-nd/4.0/ I made my song a coat Covered with embroideries Out of old mythologies.... "A Coat" W. B. Yeats Languages are more to us than systems of thought transference. They are invisible garments that drape themselves about our spirit and give a predetermined form to all its symbolic expression. When the expression is of unusual significance, we call it literature. "Language and Literature" Edward Sapir Contents Preface IX Pronounciation Guide X Vowel Sandhi xi Illustration of Scripts xii Kawi--an Introduction Language ancf History 1 Language and Its Forms 3 Language and Systems of Meaning 6 The Texts 10 Short Readings 13 Sentences 14 Paragraphs..