Paleoproterozoic Sterol Biosynthesis and the Rise of Oxygen
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Protein Expression Profile of Gluconacetobacter Diazotrophicus PAL5, a Sugarcane Endophytic Plant Growth-Promoting Bacterium
Proteomics 2008, 8, 1631–1644 DOI 10.1002/pmic.200700912 1631 RESEARCH ARTICLE Protein expression profile of Gluconacetobacter diazotrophicus PAL5, a sugarcane endophytic plant growth-promoting bacterium Leticia M. S. Lery1, 2, Ana Coelho1, 3, Wanda M. A. von Kruger1, 2, Mayla S. M. Gonc¸alves1, 3, Marise F. Santos1, 4, Richard H. Valente1, 5, Eidy O. Santos1, 3, Surza L. G. Rocha1, 5, Jonas Perales1, 5, Gilberto B. Domont1, 4, Katia R. S. Teixeira1, 6 and Paulo M. Bisch1, 2 1 Rio de Janeiro Proteomics Network, Rio de Janeiro, Brazil 2 Unidade Multidisciplinar de Genômica, Instituto de Biofísica Carlos Chagas Filho, Universidade Federal do Rio de Janeiro, Rio de Janeiro, Brazil 3 Departamento de Genética, Instituto de Biologia, Universidade Federal do Rio de Janeiro, Rio de Janeiro, Brazil 4 Laboratório de Química de Proteínas, Departamento de Bioquímica, Instituto de Química, Universidade Federal do Rio de Janeiro, Rio de Janeiro, Brazil 5 Laboratório de Toxinologia, Departamento de Fisiologia e Farmacodinâmica- Instituto Oswaldo Cruz- Fundac¸ão Oswaldo Cruz, Rio de Janeiro, Rio de Janeiro, Brazil 6 Laboratório de Genética e Bioquímica, Embrapa Agrobiologia, Seropédica, Brazil This is the first broad proteomic description of Gluconacetobacter diazotrophicus, an endophytic Received: September 25, 2007 bacterium, responsible for the major fraction of the atmospheric nitrogen fixed in sugarcane in Revised: December 18, 2007 tropical regions. Proteomic coverage of G. diazotrophicus PAL5 was obtained by two independent Accepted: December 19, 2007 approaches: 2-DE followed by MALDI-TOF or TOF-TOF MS and 1-DE followed by chromatog- raphy in a C18 column online coupled to an ESI-Q-TOF or ESI-IT mass spectrometer. -

The Phylogenetic Extent of Metabolic Enzymes and Pathways José Manuel Peregrin-Alvarez, Sophia Tsoka, Christos A
Downloaded from genome.cshlp.org on October 8, 2021 - Published by Cold Spring Harbor Laboratory Press Letter The Phylogenetic Extent of Metabolic Enzymes and Pathways José Manuel Peregrin-Alvarez, Sophia Tsoka, Christos A. Ouzounis1 Computational Genomics Group, The European Bioinformatics Institute, EMBL Cambridge Outstation, Cambridge CB10 1SD, UK The evolution of metabolic enzymes and pathways has been a subject of intense study for more than half a century. Yet, so far, previous studies have focused on a small number of enzyme families or biochemical pathways. Here, we examine the phylogenetic distribution of the full-known metabolic complement of Escherichia coli, using sequence comparison against taxa-specific databases. Half of the metabolic enzymes have homologs in all domains of life, representing families involved in some of the most fundamental cellular processes. We thus show for the first time and in a comprehensive way that metabolism is conserved at the enzyme level. In addition, our analysis suggests that despite the sequence conservation and the extensive phylogenetic distribution of metabolic enzymes, their groupings into biochemical pathways are much more variable than previously thought. One of the fundamental tenets in molecular biology was ex- reliable source of metabolic information. The EcoCyc data- pressed by Monod, in his famous phrase “What is true for base holds information about the full genome and all known Escherichia coli is true for the elephant” (Jacob 1988). For a metabolic pathways of Escherichia coli (Karp et al. 2000). Re- long time, this statement has inspired generations of molecu- cently, the database has been used to represent computational lar biologists, who have used Bacteria as model organisms to predictions of other organisms (Karp 2001). -

WO 2013/180584 Al 5 December 2013 (05.12.2013) P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2013/180584 Al 5 December 2013 (05.12.2013) P O P C T (51) International Patent Classification: AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, C12N 1/21 (2006.01) C12N 15/74 (2006.01) BZ, CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, C12N 15/52 (2006.01) C12P 5/02 (2006.01) DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, C12N 15/63 (2006.01) HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KN, KP, KR, KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, ME, (21) International Application Number: MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, PCT/NZ20 13/000095 OM, PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SC, (22) International Filing Date: SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, 4 June 2013 (04.06.2013) TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. (25) Filing Language: English (84) Designated States (unless otherwise indicated, for every kind of regional protection available): ARIPO (BW, GH, (26) Publication Language: English GM, KE, LR, LS, MW, MZ, NA, RW, SD, SL, SZ, TZ, (30) Priority Data: UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, RU, TJ, 61/654,412 1 June 2012 (01 .06.2012) US TM), European (AL, AT, BE, BG, CH, CY, CZ, DE, DK, EE, ES, FI, FR, GB, GR, HR, HU, IE, IS, IT, LT, LU, LV, (71) Applicant: LANZATECH NEW ZEALAND LIMITED MC, MK, MT, NL, NO, PL, PT, RO, RS, SE, SI, SK, SM, [NZ/NZ]; 24 Balfour Road, Parnell, Auckland, 1052 (NZ). -

B Number Gene Name Mrna Intensity Mrna Present # of Tryptic
list list sample) short list predicted B number Gene name assignment mRNA present mRNA intensity Gene description Protein detected - Membrane protein detected (total list) detected (long list) membrane sample Proteins detected - detected (short list) # of tryptic peptides # of tryptic peptides # of tryptic peptides # of tryptic peptides # of tryptic peptides Functional category detected (membrane Protein detected - total Protein detected - long b0003 thrB 6781 P 9 P 3 3 P 3 0 homoserine kinase Metabolism of small molecules b0004 thrC 15039 P 18 P 10 P 11 P 10 0 threonine synthase Metabolism of small molecules b0008 talB 20561 P 20 P 13 P 16 P 13 0 transaldolase B Metabolism of small molecules b0009 mog 1296 P 7 0 0 0 0 required for the efficient incorporation of molybdate into molybdoproteins Metabolism of small molecules b0014 dnaK 13283 P 32 P 23 P 24 P 23 0 chaperone Hsp70; DNA biosynthesis; autoregulated heat shock proteins Cell processes b0031 dapB 2348 P 16 P 3 3 P 3 0 dihydrodipicolinate reductase Metabolism of small molecules b0032 carA 9312 P 14 P 8 P 8 P 8 0 carbamoyl-phosphate synthetase, glutamine (small) subunit Metabolism of small molecules b0048 folA 1588 P 7 P 1 2 P 1 0 dihydrofolate reductase type I; trimethoprim resistance Metabolism of small molecules peptidyl-prolyl cis-trans isomerase (PPIase), involved in maturation of outer b0053 surA 3825 P 19 P 4 P 5 P 4 P(m) 1 GenProt membrane proteins (1st module) Cell processes b0054 imp 2737 P 42 P 5 0 0 P(m) 5 GenProt organic solvent tolerance Cell processes b0071 leuD 4770 -

B Number Gene Name Mrna Intensity Mrna
sample) total list predicted B number Gene name assignment mRNA present mRNA intensity Gene description Protein detected - Membrane protein membrane sample detected (total list) Proteins detected - Functional category # of tryptic peptides # of tryptic peptides # of tryptic peptides detected (membrane b0002 thrA 13624 P 39 P 18 P(m) 2 aspartokinase I, homoserine dehydrogenase I Metabolism of small molecules b0003 thrB 6781 P 9 P 3 0 homoserine kinase Metabolism of small molecules b0004 thrC 15039 P 18 P 10 0 threonine synthase Metabolism of small molecules b0008 talB 20561 P 20 P 13 0 transaldolase B Metabolism of small molecules chaperone Hsp70; DNA biosynthesis; autoregulated heat shock b0014 dnaK 13283 P 32 P 23 0 proteins Cell processes b0015 dnaJ 4492 P 13 P 4 P(m) 1 chaperone with DnaK; heat shock protein Cell processes b0029 lytB 1331 P 16 P 2 0 control of stringent response; involved in penicillin tolerance Global functions b0032 carA 9312 P 14 P 8 0 carbamoyl-phosphate synthetase, glutamine (small) subunit Metabolism of small molecules b0033 carB 7656 P 48 P 17 0 carbamoyl-phosphate synthase large subunit Metabolism of small molecules b0048 folA 1588 P 7 P 1 0 dihydrofolate reductase type I; trimethoprim resistance Metabolism of small molecules peptidyl-prolyl cis-trans isomerase (PPIase), involved in maturation of b0053 surA 3825 P 19 P 4 P(m) 1 GenProt outer membrane proteins (1st module) Cell processes b0054 imp 2737 P 42 P 5 P(m) 5 GenProt organic solvent tolerance Cell processes b0071 leuD 4770 P 10 P 9 0 isopropylmalate -

Terpene Production in the Peel of Sweet Orange Fruits
Genetics and Molecular Biology, 30, 3 (suppl), 841-847 (2007) Copyright by the Brazilian Society of Genetics. Printed in Brazil www.sbg.org.br Research Article Terpene production in the peel of sweet orange fruits Marco A. Takita1,2, Irving J. Berger1, Ana Carolina Basílio-Palmieri1, Kleber M. Borges1, Juliana M. de Souza1 and Maria L.N.P. Targon1 1Centro APTA Citros Sylvio Moreira, Instituto Agronômico de Campinas, Cordeirópolis, SP, Brazil. 2Centro de Pesquisa e Desenvolvimento de Recursos Genéticos Vegetais, Instituto Agronômico de Campinas, Campinas, SP, Brazil. Abstract Terpenoids constitute the largest and most diverse class of natural products. They are important factors for aroma and flavor, and their synthesis is basically done from two compounds: isopentenyl diphosphate and dimethylallyl diphosphate. Isopentenyl diphosphate is synthesized through two different pathways, one that occurs in the cyto- plasm and one in the plastid. With the sequencing of ESTs from citrus, we were able to perform in silico analyses on the pathways that lead to the synthesis of terpenes as well as on the terpene synthases present in sweet orange. Moreover, expression analysis using real-time qPCR was performed to verify the expression pattern of a terpene synthase in plants. The results show that all the pathways for isopentenyl diphosphate are present in citrus and a high expression of terpene synthases seems to have an important role in the constitution of the essential oils of cit- rus. Key words: EST, fruit, terpenoids, orange, essential oil. Received: September 21, 2006; Accepted: July 13, 2007. Introduction ecological, providing defense against herbivores or patho- Citriculture plays a fundamental role in Brazilian ag- gens, attracting animals that disperse pollen and seeds, or ribusiness. -

Product Sheet Info
Master Clone List for NR-19279 ® Vibrio cholerae Gateway Clone Set, Recombinant in Escherichia coli, Plates 1-46 Catalog No. NR-19279 Table 1: Vibrio cholerae Gateway® Clones, Plate 1 (NR-19679) Clone ID Well ORF Locus ID Symbol Product Accession Position Length Number 174071 A02 367 VC2271 ribD riboflavin-specific deaminase NP_231902.1 174346 A03 336 VC1877 lpxK tetraacyldisaccharide 4`-kinase NP_231511.1 174354 A04 342 VC0953 holA DNA polymerase III, delta subunit NP_230600.1 174115 A05 388 VC2085 sucC succinyl-CoA synthase, beta subunit NP_231717.1 174310 A06 506 VC2400 murC UDP-N-acetylmuramate--alanine ligase NP_232030.1 174523 A07 132 VC0644 rbfA ribosome-binding factor A NP_230293.2 174632 A08 322 VC0681 ribF riboflavin kinase-FMN adenylyltransferase NP_230330.1 174930 A09 433 VC0720 phoR histidine protein kinase PhoR NP_230369.1 174953 A10 206 VC1178 conserved hypothetical protein NP_230823.1 174976 A11 213 VC2358 hypothetical protein NP_231988.1 174898 A12 369 VC0154 trmA tRNA (uracil-5-)-methyltransferase NP_229811.1 174059 B01 73 VC2098 hypothetical protein NP_231730.1 174075 B02 82 VC0561 rpsP ribosomal protein S16 NP_230212.1 174087 B03 378 VC1843 cydB-1 cytochrome d ubiquinol oxidase, subunit II NP_231477.1 174099 B04 383 VC1798 eha eha protein NP_231433.1 174294 B05 494 VC0763 GTP-binding protein NP_230412.1 174311 B06 314 VC2183 prsA ribose-phosphate pyrophosphokinase NP_231814.1 174603 B07 108 VC0675 thyA thymidylate synthase NP_230324.1 174474 B08 466 VC1297 asnS asparaginyl-tRNA synthetase NP_230942.2 174933 B09 198 -

Stem Cells® Original Article
® Stem Cells Original Article Properties of Pluripotent Human Embryonic Stem Cells BG01 and BG02 XIANMIN ZENG,a TAKUMI MIURA,b YONGQUAN LUO,b BHASKAR BHATTACHARYA,c BRIAN CONDIE,d JIA CHEN,a IRENE GINIS,b IAN LYONS,d JOSEF MEJIDO,c RAJ K. PURI,c MAHENDRA S. RAO,b WILLIAM J. FREEDa aCellular Neurobiology Research Branch, National Institute on Drug Abuse, Department of Health and Human Services (DHHS), Baltimore, Maryland, USA; bLaboratory of Neuroscience, National Institute of Aging, DHHS, Baltimore, Maryland, USA; cLaboratory of Molecular Tumor Biology, Division of Cellular and Gene Therapies, Center for Biologics Evaluation and Research, Food and Drug Administration, Bethesda, Maryland, USA; dBresaGen Inc., Athens, Georgia, USA Key Words. Embryonic stem cells · Differentiation · Microarray ABSTRACT Human ES (hES) cell lines have only recently been compared with pooled human RNA. Ninety-two of these generated, and differences between human and mouse genes were also highly expressed in four other hES lines ES cells have been identified. In this manuscript we (TE05, GE01, GE09, and pooled samples derived from describe the properties of two human ES cell lines, GE01, GE09, and GE07). Included in the list are genes BG01 and BG02. By immunocytochemistry and reverse involved in cell signaling and development, metabolism, transcription polymerase chain reaction, undifferenti- transcription regulation, and many hypothetical pro- ated cells expressed markers that are characteristic of teins. Two focused arrays designed to examine tran- ES cells, including SSEA-3, SSEA-4, TRA-1-60, TRA-1- scripts associated with stem cells and with the 81, and OCT-3/4. Both cell lines were readily main- transforming growth factor-β superfamily were tained in an undifferentiated state and could employed to examine differentially expressed genes. -

Product Datasheet FDPS Overexpression
Product Datasheet FDPS Overexpression Lysate NBP2-04211 Unit Size: 0.1 mg Store at -80C. Avoid freeze-thaw cycles. Protocols, Publications, Related Products, Reviews, Research Tools and Images at: www.novusbio.com/NBP2-04211 Updated 3/17/2020 v.20.1 Earn rewards for product reviews and publications. Submit a publication at www.novusbio.com/publications Submit a review at www.novusbio.com/reviews/destination/NBP2-04211 Page 1 of 2 v.20.1 Updated 3/17/2020 NBP2-04211 FDPS Overexpression Lysate Product Information Unit Size 0.1 mg Concentration The exact concentration of the protein of interest cannot be determined for overexpression lysates. Please contact technical support for more information. Storage Store at -80C. Avoid freeze-thaw cycles. Buffer RIPA buffer Target Molecular Weight 48.1 kDa Product Description Description Transient overexpression lysate of farnesyl diphosphate synthase (farnesyl pyrophosphate synthetase, dimethylallyltranstransferase, geranyltranstransferase) (FDPS), transcript variant 1 The lysate was created in HEK293T cells, using Plasmid ID RC203499 and based on accession number NM_002004. The protein contains a C-MYC/DDK Tag. Gene ID 2224 Gene Symbol FDPS Species Human Notes HEK293T cells in 10-cm dishes were transiently transfected with a non-lipid polymer transfection reagent specially designed and manufactured for large volume DNA transfection. Transfected cells were cultured for 48hrs before collection. The cells were lysed in modified RIPA buffer (25mM Tris-HCl pH7.6, 150mM NaCl, 1% NP-40, 1mM EDTA, 1xProteinase inhibitor cocktail mix, 1mM PMSF and 1mM Na3VO4, and then centrifuged to clarify the lysate. Protein concentration was measured by BCA protein assay kit.This product is manufactured by and sold under license from OriGene Technologies and its use is limited solely for research purposes. -

For Personal Use. Only Reproduce with Permission from the Lancet
Correlation to non-HGNT Accesion group 2 Description AA897204 1.479917 ESTs T85111 1.286576 null T60168 | AI821353 1.274487 thyroid transcription factor 1 AA600173 1.183065 ubiquitin-conjugating enzyme E2A (RAD6 homolog) R55745 1.169339 ELAV (embryonic lethal, abnormal vision, Drosophila)-like 4 (Hu antigen D) AA400492 1.114935 ESTs AA864791 1.088826 hypothetical protein FLJ21313 N53758 1.070402 EST AI216628 1.067763 ESTs AI167637 1.058561 ESTs AA478265 1.056331 similar to transmembrane receptor Unc5H1 AA969924 1.039315 EST AI074650 1.039043 hypothetical protein FLJ13842 R20763 1.035807 ELAV (embryonic lethal, abnormal vision, Drosophila)-like 3 (Hu antigen C) AI347081 1.034518 Ca2+-dependent activator protein for secretion R44386 1.028005 ESTs AA976699 1.027227 chromogranin A (parathyroid secretory protein 1) AA634475 1.026766 KIAA1796 protein AA496809 1.02432 SWI/SNF related, matrix associated, actin dependent regulator of chromatin, subfamily a, member 1 H16572 1.013059 null H29013 1.002117 seizure related 6 homolog (mouse)-like AI299731 1.001053 Homo sapiens nanos mRNA, partial cds AA400194 0.9950039 EST AI216537 | AI820870 0.9737153 Homo sapiens cDNA FLJ39674 fis, clone SMINT2009505 AA426408 0.9728649 type I transmembrane receptor (seizure-related protein) AA971742 | AI733380 0.9707561 achaete-scute complex-like 1 (Drosophila) R41450 0.9655133 ESTs AA487505 0.9636143 immunoglobulin superfamily, member 4 AA404337 0.957686 thymus high mobility group box protein TOX N68578 0.9552571 ESTs R45008 0.9422938 ELAV (embryonic lethal, abnormal -
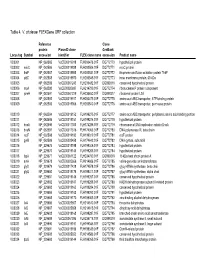
Table 4. V. Cholerae Flexgene ORF Collection
Table 4. V. cholerae FLEXGene ORF collection Reference Clone protein PlasmID clone GenBank Locus tag Symbol accession identifier FLEX clone name accession Product name VC0001 NP_062585 VcCD00019918 FLH200476.01F DQ772770 hypothetical protein VC0002 mioC NP_062586 VcCD00019938 FLH200506.01F DQ772771 mioC protein VC0003 thdF NP_062587 VcCD00019958 FLH200531.01F DQ772772 thiophene and furan oxidation protein ThdF VC0004 yidC NP_062588 VcCD00019970 FLH200545.01F DQ772773 inner membrane protein, 60 kDa VC0005 NP_062589 VcCD00061243 FLH236482.01F DQ899316 conserved hypothetical protein VC0006 rnpA NP_062590 VcCD00025697 FLH214799.01F DQ772774 ribonuclease P protein component VC0007 rpmH NP_062591 VcCD00061229 FLH236450.01F DQ899317 ribosomal protein L34 VC0008 NP_062592 VcCD00019917 FLH200475.01F DQ772775 amino acid ABC transporter, ATP-binding protein VC0009 NP_062593 VcCD00019966 FLH200540.01F DQ772776 amino acid ABC transproter, permease protein VC0010 NP_062594 VcCD00019152 FLH199275.01F DQ772777 amino acid ABC transporter, periplasmic amino acid-binding portion VC0011 NP_062595 VcCD00019151 FLH199274.01F DQ772778 hypothetical protein VC0012 dnaA NP_062596 VcCD00017363 FLH174286.01F DQ772779 chromosomal DNA replication initiator DnaA VC0013 dnaN NP_062597 VcCD00017316 FLH174063.01F DQ772780 DNA polymerase III, beta chain VC0014 recF NP_062598 VcCD00019182 FLH199319.01F DQ772781 recF protein VC0015 gyrB NP_062599 VcCD00025458 FLH174642.01F DQ772782 DNA gyrase, subunit B VC0016 NP_229675 VcCD00019198 FLH199346.01F DQ772783 hypothetical protein -

O O2 Enzymes Available from Sigma Enzymes Available from Sigma
COO 2.7.1.15 Ribokinase OXIDOREDUCTASES CONH2 COO 2.7.1.16 Ribulokinase 1.1.1.1 Alcohol dehydrogenase BLOOD GROUP + O O + O O 1.1.1.3 Homoserine dehydrogenase HYALURONIC ACID DERMATAN ALGINATES O-ANTIGENS STARCH GLYCOGEN CH COO N COO 2.7.1.17 Xylulokinase P GLYCOPROTEINS SUBSTANCES 2 OH N + COO 1.1.1.8 Glycerol-3-phosphate dehydrogenase Ribose -O - P - O - P - O- Adenosine(P) Ribose - O - P - O - P - O -Adenosine NICOTINATE 2.7.1.19 Phosphoribulokinase GANGLIOSIDES PEPTIDO- CH OH CH OH N 1 + COO 1.1.1.9 D-Xylulose reductase 2 2 NH .2.1 2.7.1.24 Dephospho-CoA kinase O CHITIN CHONDROITIN PECTIN INULIN CELLULOSE O O NH O O O O Ribose- P 2.4 N N RP 1.1.1.10 l-Xylulose reductase MUCINS GLYCAN 6.3.5.1 2.7.7.18 2.7.1.25 Adenylylsulfate kinase CH2OH HO Indoleacetate Indoxyl + 1.1.1.14 l-Iditol dehydrogenase L O O O Desamino-NAD Nicotinate- Quinolinate- A 2.7.1.28 Triokinase O O 1.1.1.132 HO (Auxin) NAD(P) 6.3.1.5 2.4.2.19 1.1.1.19 Glucuronate reductase CHOH - 2.4.1.68 CH3 OH OH OH nucleotide 2.7.1.30 Glycerol kinase Y - COO nucleotide 2.7.1.31 Glycerate kinase 1.1.1.21 Aldehyde reductase AcNH CHOH COO 6.3.2.7-10 2.4.1.69 O 1.2.3.7 2.4.2.19 R OPPT OH OH + 1.1.1.22 UDPglucose dehydrogenase 2.4.99.7 HO O OPPU HO 2.7.1.32 Choline kinase S CH2OH 6.3.2.13 OH OPPU CH HO CH2CH(NH3)COO HO CH CH NH HO CH2CH2NHCOCH3 CH O CH CH NHCOCH COO 1.1.1.23 Histidinol dehydrogenase OPC 2.4.1.17 3 2.4.1.29 CH CHO 2 2 2 3 2 2 3 O 2.7.1.33 Pantothenate kinase CH3CH NHAC OH OH OH LACTOSE 2 COO 1.1.1.25 Shikimate dehydrogenase A HO HO OPPG CH OH 2.7.1.34 Pantetheine kinase UDP- TDP-Rhamnose 2 NH NH NH NH N M 2.7.1.36 Mevalonate kinase 1.1.1.27 Lactate dehydrogenase HO COO- GDP- 2.4.1.21 O NH NH 4.1.1.28 2.3.1.5 2.1.1.4 1.1.1.29 Glycerate dehydrogenase C UDP-N-Ac-Muramate Iduronate OH 2.4.1.1 2.4.1.11 HO 5-Hydroxy- 5-Hydroxytryptamine N-Acetyl-serotonin N-Acetyl-5-O-methyl-serotonin Quinolinate 2.7.1.39 Homoserine kinase Mannuronate CH3 etc.