Fabrication and Characterization of Gate-All-Around Stacked-Nanowire/Nanosheet MOS Transistors Realized by a Gate-Last Approach for Sub-7 Nm Technology Nodes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Performance and Energy Efficient Network-On-Chip Architectures
Linköping Studies in Science and Technology Dissertation No. 1130 Performance and Energy Efficient Network-on-Chip Architectures Sriram R. Vangal Electronic Devices Department of Electrical Engineering Linköping University, SE-581 83 Linköping, Sweden Linköping 2007 ISBN 978-91-85895-91-5 ISSN 0345-7524 ii Performance and Energy Efficient Network-on-Chip Architectures Sriram R. Vangal ISBN 978-91-85895-91-5 Copyright Sriram. R. Vangal, 2007 Linköping Studies in Science and Technology Dissertation No. 1130 ISSN 0345-7524 Electronic Devices Department of Electrical Engineering Linköping University, SE-581 83 Linköping, Sweden Linköping 2007 Author email: [email protected] Cover Image A chip microphotograph of the industry’s first programmable 80-tile teraFLOPS processor, which is implemented in a 65-nm eight-metal CMOS technology. Printed by LiU-Tryck, Linköping University Linköping, Sweden, 2007 Abstract The scaling of MOS transistors into the nanometer regime opens the possibility for creating large Network-on-Chip (NoC) architectures containing hundreds of integrated processing elements with on-chip communication. NoC architectures, with structured on-chip networks are emerging as a scalable and modular solution to global communications within large systems-on-chip. NoCs mitigate the emerging wire-delay problem and addresses the need for substantial interconnect bandwidth by replacing today’s shared buses with packet-switched router networks. With on-chip communication consuming a significant portion of the chip power and area budgets, there is a compelling need for compact, low power routers. While applications dictate the choice of the compute core, the advent of multimedia applications, such as three-dimensional (3D) graphics and signal processing, places stronger demands for self-contained, low-latency floating-point processors with increased throughput. -

Lecture 5: Scaled MOSFETS for Ics
Lecture 5: Scaled MOSFETS for ICs MSE 6001, Semiconductor Materials Lectures Fall 2006 5 MOSFETS and scaling Silicon is a mediocre semiconductor, and several other semiconductors have better electrical and optical properties. However, the very high quality of the electrical properties of the silicon-silicon dioxide interface allows very good metal-oxide-semiconductor field-effect transistors (MOSFETs) to be fabricated. These devices have several properties, such as operation frequency and power con- sumption, that improve as their size is scaled down to smaller dimensions, which also allows more transistors to be packed onto a chip. The smaller sizes are achieved using higher-resolution pho- tolithography, which is improved by steadily improving the fabrication technologies. The trends of steadily improving performance and greater integration density with time are generically refered to A 70 Mbit SRAM test vehicle with >as0.5 “Moore’s billion trans Law”.istors Of course, scaling has to end eventually, somewhere before the scale of atoms and incorporating all of the features described in this paper has been fabricated on this technologyis. reached.The aggressive de- sign rules allow for a small 0.57Pm2 6-T SRAM cell that is also compatible with high performance logic processing. A top view of the cell after poly patterni5.1ng is show Basicn in Figur MOSFETe 12. In addition to small size, this cell has a robust static noise margin down to 0.7V VDD to alloMOSFETsw low voltage turnopera- on and off via the non-linear gate capacitor between the gate electrode and the tion (Fig. 13). Figure 14 is a Shmosubstrate.o plot for the The 70 M MOSFETb of Fig. -

By Erika Azabache Villar a Thesis Submitted in Partial Fulfillment of The
SMALLER/FASTER DELTA-SIGMA DIGITAL PIXEL SENSORS by Erika Azabache Villar A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Integrated Circuits and Systems Department of Electrical and Computer Engineering University of Alberta c Erika Azabache Villar, 2016 Abstract A digital pixel sensor (DPS) array is an image sensor where each pixel has an analog-to-digital converter (ADC). Recently, a logarithmic delta-sigma (ΔΣ) DPS array, using first-order ΔΣ ADCs, achieved wide dynamic range and high signal-to-noise-and-distortion ratios at video rates, requirements that are difficult to meet using conventional image sensors. However, this state-of-the-art ΔΣ DPS design is either too large for some applications, such as optical imag- ing, or too slow for others, such as gamma imaging. Consequently, this master’s thesis investi- gates smaller or faster ΔΣ DPS designs, relative to the state of the art. All designs are validated through simulations. Commercial image sensors, for optical and gamma imaging, are used as targeted baselines to establish competitive specifications. To achieve a smaller pixel, process scaling is exploited. Three logarithmic ΔΣ DPS designs are presented for 180, 130, and 65 nm fabrication processes, demonstrating a path to competitiveness for the optical imaging market. Decimator and readout circuits are improved, compared to previous work, while reducing area, and capacitors in the modulator prove to be the limiting factor in deep-submicron processes. Area trends are used to construct a roadmap to even smaller pixels. To achieve a faster pixel, a higher-order ΔΣ architecture is exploited. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -
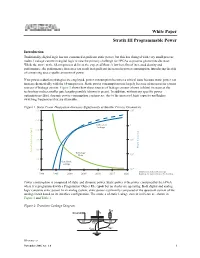
Stratix III Programmable Power
White Paper Stratix III Programmable Power Introduction Traditionally, digital logic has not consumed significant static power, but this has changed with very small process nodes. Leakage current in digital logic is now the primary challenge for FPGAs as process geometries decrease. While the move to the 65-nm process delivers the expected Moore's law benefits of increased density and performance, the performance increases can result in significant increases in power consumption, introducing the risk of consuming unacceptable amounts of power. If no power-reduction strategies are employed, power consumption becomes a critical issue because static power can increase dramatically with the 65-nm process. Static power consumption rises largely because of increases in various sources of leakage current. Figure 1 shows how these sources of leakage current (shown in blue) increase as the technology makes smaller gate lengths possible (shown in green). In addition, without any specific power optimization effort, dynamic power consumption can increase due to the increased logic capacity and higher switching frequencies that are attainable. Figure 1. Static Power Dissipation Increases Significantly at Smaller Process Geometries 300 100 250 Subthreshold 1 Leakage 200 150 10-2 Power Dissipation 100 Physical Gate Length [nm] Technology -4 Node 10 50 Gate-Oxide Leakage 0 10-6 Data from International Technology 1990 1995 2000 2005 2010 2015 2020 Roadmap for Semiconductors ITRS Roadmap Power consumption is composed of static and dynamic power. Static power is the power consumed by the FPGA when it is programmed with a Programmer Object File (.pof) but no clocks are operating. Both digital and analog logic consume static power. -

Design and Analysis of Integrated CMOS High-Voltage Drivers in Low-Voltage Technologies
Design and Analysis of Integrated CMOS High-Voltage Drivers in Low-Voltage Technologies Von der Fakultat¨ fur¨ MINT – Mathematik, Informatik, Physik, Elektro- und Informationstechnik der Brandenburgischen Technischen Universitat¨ Cottbus-Senftenberg zur Erlangung des akademischen Grades eines Doktors der Ingenieurwissenschaften (Dr.-Ing.) genehmigte Dissertation vorgelegt von M.Sc. Dipl.-Ing. Sara Toktam Pashmineh Azar geboren am 20.11.1972 in Torbat Heydarieh Gutachter: Prof. Dr.-Ing. Matthias Rudolph (Vorsitzender der Prufungskommission)¨ Gutachter: Prof. Dr.-Ing. Dirk Killat Gutachter: Prof. Dr.-Ing. Klaus Hofmann (Technische Universitat¨ Darmstadt) Tag der mundlichen¨ Prufung:¨ 10.07.2017 Selbstst¨andigkeitserkl¨arung Die Verfasserin erkl¨art, dass sie die vorliegende Arbeit selbst¨andig, ohne fremde Hilfe und ohne Benutzung anderer als die angegebenen Hilfsmittel angefertigt hat. Die aus frem- den Quellen (einschließlich elektronischer Quellen) direkt oder indirektubernommenen ¨ Gedanken sind ausnahmslos als solche kenntlich gemacht. Die Arbeit ist in gleicher oder ¨ahnlicher Form oder auszugsweise im Rahmen einer anderen Pr¨ufung noch nicht vorgelegt worden. Cottbus, Abstract With scaling technology, the nominal I/O voltage of standard transistors has been re- duced from 5.0 V in 0.25-μm processes to 2.5 V in 65-nm. However, the supply voltages of some applications cannot be reduced at the same rate as that of shrinking technolo- gies. Since high-voltage (HV-) compatible transistors are not available for some recent technologies and need time to be designed after developing a new process technology, de- signing HV-circuits based on stacked transistors has better benefits because such circuits offer technology independence and full integration with digital circuits to provide system- on-chip solutions. -

WP Microelectronics and Interconnections
Advanced European Infrastructures for Detectors at Accelerators FirSecondst Ann Annualual MeMeetingeting: WPWP44 St Statusatus R Reporteport ChrisChristophetophe de LA TA ILdeLE (laCN TailleRS/IN2P(CNRS/IN2P3)3) Valerio RE (INFN ) Valerio Re (INFN/Univ. Bergamo) LPNHE, Paris, April 7, 2017 DESY, Hamburg, June 17, 2016 This project has received funding from the European Union’s Horizon 2020 Research and Innovation programme under Grant Agreement no. 654168. WP4: microelectronics and interconnections • WP Coordinators: Christophe de la Taille, Valerio Re • Goal : provide chips and interconnections to detectors developed by other WPs • Task 1: Scientific coordination (CNRS-OMEGA, INFN-UNIBG) • Task 2 : 65 nm chips for trackers (CERN) • Fine pitch, low power, advanced digital processing • Task 3 : SiGe 130nm for calorimeters/gaseous (IN2P3) • Highly integrated charge and time measurement • Task 4 : interconnections between 65 nm chips and pixel sensors (INFN) • TSVs in 65 nm CMOS wafers, bonding of 65 nm chips to sensors, exploration of fine pitch bonding processes AIDA WP4 milestones MS4.1 Architectural review of deliverable chips in 65nm run M14 (accomplished) MS4.2 Final design review of 65nm M30 (October 2017) MS4.3 Test report of deliverable D4.1 M46 (February 2019) MS4.4 Selection of SiGe foundry M14 (accomplished) MS4.5 Final design review of deliverable chips in SiGe run M30 (October 2017) MS4.6 Test report of deliverable D4.2 M46 MS4.7 Selection of TSV process M14 (accomplished) MS4.8 Final design review of deliverable D4.3 (TSV -

Madison Processor
TheThe RoadRoad toto BillionBillion TransistorTransistor ProcessorProcessor ChipsChips inin thethe NearNear FutureFuture DileepDileep BhandarkarBhandarkar RogerRoger GolliverGolliver Intel Corporation April 22th, 2003 Copyright © 2002 Intel Corporation. Outline yy SemiconductorSemiconductor TechnologyTechnology EvolutionEvolution yy Moore’sMoore’s LawLaw VideoVideo yy ParallelismParallelism inin MicroprocessorsMicroprocessors TodayToday yy MultiprocessorMultiprocessor SystemsSystems yy TheThe PathPath toto BillionBillion TransistorsTransistors yy SummarySummary ©2002, Intel Corporation Intel, the Intel logo, Pentium, Itanium and Xeon are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries *Other names and brands may be claimed as the property of others BirthBirth ofof thethe RevolutionRevolution ---- TheThe IntelIntel 40044004 IntroducedIntroduced NovemberNovember 15,15, 19711971 108108 KHz,KHz, 5050 KIPsKIPs ,, 23002300 1010μμ transistorstransistors 20012001 –– Pentium®Pentium® 44 ProcessorProcessor Introduced November 20, 2000 @1.5 GHz core, 400 MT/s bus 42 Million 0.18µ transistors August 27, 2001 @2 GHz, 400 MT/s bus 640 SPECint_base2000* 704 SPECfp_base2000* SourceSource:: hhtttptp:/://www/www.specbench.org/cpu2000/results/.specbench.org/cpu2000/results/ 3030 YearsYears ofof ProgressProgress yy40044004 toto PentiumPentium®® 44 processorprocessor –– TransistorTransistor count:count: 20,000x20,000x increaseincrease –– Frequency:Frequency: 20,000x20,000x increaseincrease -

45 Nm Process
INTEL FIRST TO DEMONSTRATE WORKING 45 nm CHIPS New Technology Will Improve Energy Efficiency and Boost Capabilities of Future Intel Platforms Mark Bohr Intel Senior Fellow Director of Process Architecture & Integration January 2006 1 65 nm Status • Announced shipping 65nm for revenue in Oct. 2005 • Two 65nm/300mm fabs shipping in volume (D1D and Fab 12); with two more coming in 2006 • Intel has shipped more than a million dual- core processors made on 65nm process technology • CPU shipment cross-over from 90nm to 65nm projected for Q3/06 2 What are We Announcing Today? • Intel is first to reach an important milestone in the development of 45 nm logic technology • Fully functional 153 Mbit SRAM chips have been made with >1 billion transistors each • The memory cell size on these SRAM chips is 0.346 μm2, almost half the size of the 65 nm cell • This milestone demonstrates that Intel is on track for delivery of its 45 nm logic technology in 2H 2007 3 45 nm Technology Benefits Compared to today’s 65 nm technology, the 45 nm technology will provide the following product benefits: ~2x improvement in transistor density, for either smaller chip size or increased transistor count >20% improvement in transistor switching speed or >5x reduction in leakage power >30% reduction in transistor switching power This process technology will provide the foundation to deliver improved performance/Watt that will enhance the user experience 4 Intel's Logic Technology Evolution Process Name P1262 P1264 P1266 P1268 Lithography 90 nm 65 nm 45 nm 32 nm 1st Production -

DELAY SIMULATIONS Asha G H1, Dr
ESTIMATION OF FRINGING CAPACITANCE USING RC – DELAY SIMULATIONS Asha G H1, Dr. Deepali Koppad2 1Associate Professor, Dept. of Electronics & Communication Engineering, Malnad College of Engineering, Hassan India 2Professor, Dept. of Electronics and Communication, PES University, Bangalore, India Abstract As transistors become smaller, they switch I. INTRODUCTION faster, dissipate less power, and are cheaper to manufacture! Since 1995, as the technical challenges have become greater, the pace of innovation has actually accelerated because of ferocious competition across the industry. Designers need to be able to predict the effect of this feature size scaling on chip performance to plan future products, ensure existing products will scale gracefully to Fig. 1. Capacitances associated with a MOS - future processes for cost reduction, and Device anticipate looming design challenges. Scaled For a fully scaled 70 nm gate length MOSFETs transistors are steadily improving in delay, following the technology Roadmap having a gate but scaled global wires are getting worse. length down to 70 nm, the source/drain junction Increased gate leakage is one of the main depths fixed at 35 nm, peak channel doping limiting factors for aggressive scaling of Si02 concentration of 1.5 X 10l8 cm-3 and a threshold for deep sub-micron CMOS technology. voltage of 0.2V, all the capacitances associated Extracted gate to source/drain fringing with the device, which are extracted from direct capacitances using a highly accurate 3D Monte- Carlo simulations are shown in Fig. 1. capacitance extractor [1] has shown that the The fringing capacitance Cf is the parallel inner fringing capacitances between the gate combination of fringing capacitance on the outer and the source/drain play a key role in side Cof and the fringing capacitance on the inner degrading the short channel performance in side Cif between the gate and source/drain the case of MOSFETs with high-K gate junctions, defined as in equation (1). -

Xilinx, Power Consumption in 65Nm Fpgas, White Paper
White Paper: Virtex-5 FPGAs R WP246 (v1.2) February 1, 2007 Power Consumption in 65 nm FPGAs By: Derek Curd With the introduction of the Virtex™-5 family, Xilinx is once again leading the charge to deliver new technologies and capabilities to FPGA consumers. The move to 65 nm FPGAs promises to deliver many of the benefits traditionally associated with smaller process geometries: lower cost, higher performance, and greater logic capacity. However, along with these benefits, the 65 nm process node brings with it new challenges. This white paper addresses one of those challenges, power consumption in 65 nm FPGAs. As with the Virtex-4 family, Xilinx has implemented a number of process and architectural innovations in Virtex-5 devices to ensure that static power consumption is minimized and that the dynamic power benefits of moving to a new process node are fully realized. © 2006–2007 Xilinx, Inc. All rights reserved. All Xilinx trademarks, registered trademarks, patents, and further disclaimers are as listed at http://www.xilinx.com/legal.htm. All other trademarks and registered trademarks are the property of their respective owners. All specifications are subject to change without notice. NOTICE OF DISCLAIMER: Xilinx is providing this design, code, or information "as is." By providing the design, code, or information as one possible implementation of this feature, application, or standard, Xilinx makes no representation that this implementation is free from any claims of infringement. You are responsible for obtaining any rights you may require for your implementation. Xilinx expressly disclaims any warranty whatsoever with respect to the adequacy of the implementation, including but not limited to any warranties or representations that this implementation is free from claims of infringement and any implied warranties of merchantability or fitness for a particular purpose. -

Perspectives of 65Nm CMOS Technologies for High Performance Front-End Electronics in Future Applications
Perspectives of 65nm CMOS technologies for high performance front-end electronics in future applications G. Traversia, L. Gaionia, M. Manghisonia, L. Rattib, V. Rea aUniversità degli Studi di Bergamo and INFN Pavia bUniversità degli Studi di Pavia and INFN Pavia 21th International Workshop on Vertex Detectors, 16-21 September, 2012, Jeju, Korea Motivations Pixelated detectors in cutting-edge scientific experiments at high luminosity particle accelerators and advanced X-ray sources will need to fulfill very stringent requirements on pixel pitch, material budget, readout speed and radiation tolerance Designers are currently considering two different approaches: moving to higher density 2D technology nodes moving to technologies with vertical integration techniques (3D-IC) The 65nm is starting to be considered as a new attractive solution in view of the development of high-density, high-performance, mixed-signal readout circuits In the nanometer range, the impact of new dielectric materials and processing techniques (e.g.: silicon strain, gate oxide nitridation) on the analog behavior of MOSFETs has to be carefully evaluated 21th International Workshop on Vertex Detectors, 16-21 September, 2012, Jeju, Korea 2 65 nm process options Several variants of the 65nm process technology are available High Speed: highest possible speed at the price o f v e r y h i g h l e a k a g e c u r r e n t ( f o r microprocessors, fast DSP, …). Lower operation voltage (Vdd=1V), low threshold voltage devices General Purpose: speed is not critical -> leakage current one order of magnitude lower than HS Low Power (or Low Leakage): thicker gate oxide Low Moderate Fast thickness, Vdd=1.2V, higher threshold voltage (-50%) (0%) (+50%) devices (for low power applications) The characterization results of the 65nm technology shown in this talk are referred to a Low Power option (compared with 90nm LP, 90nm GP and 130nm GP from different foundries) “SEE and TID.