Recognizing and Visualizing Maya Glyphs with Cnns
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bibliography
Bibliography Many books were read and researched in the compilation of Binford, L. R, 1983, Working at Archaeology. Academic Press, The Encyclopedic Dictionary of Archaeology: New York. Binford, L. R, and Binford, S. R (eds.), 1968, New Perspectives in American Museum of Natural History, 1993, The First Humans. Archaeology. Aldine, Chicago. HarperSanFrancisco, San Francisco. Braidwood, R 1.,1960, Archaeologists and What They Do. Franklin American Museum of Natural History, 1993, People of the Stone Watts, New York. Age. HarperSanFrancisco, San Francisco. Branigan, Keith (ed.), 1982, The Atlas ofArchaeology. St. Martin's, American Museum of Natural History, 1994, New World and Pacific New York. Civilizations. HarperSanFrancisco, San Francisco. Bray, w., and Tump, D., 1972, Penguin Dictionary ofArchaeology. American Museum of Natural History, 1994, Old World Civiliza Penguin, New York. tions. HarperSanFrancisco, San Francisco. Brennan, L., 1973, Beginner's Guide to Archaeology. Stackpole Ashmore, w., and Sharer, R. J., 1988, Discovering Our Past: A Brief Books, Harrisburg, PA. Introduction to Archaeology. Mayfield, Mountain View, CA. Broderick, M., and Morton, A. A., 1924, A Concise Dictionary of Atkinson, R J. C., 1985, Field Archaeology, 2d ed. Hyperion, New Egyptian Archaeology. Ares Publishers, Chicago. York. Brothwell, D., 1963, Digging Up Bones: The Excavation, Treatment Bacon, E. (ed.), 1976, The Great Archaeologists. Bobbs-Merrill, and Study ofHuman Skeletal Remains. British Museum, London. New York. Brothwell, D., and Higgs, E. (eds.), 1969, Science in Archaeology, Bahn, P., 1993, Collins Dictionary of Archaeology. ABC-CLIO, 2d ed. Thames and Hudson, London. Santa Barbara, CA. Budge, E. A. Wallis, 1929, The Rosetta Stone. Dover, New York. Bahn, P. -

Ancient Writing
Ancient Writing As early civilizations developed, societies became more complicated. Record keeping and communication demanded something beyond symbols and pictures to represent the spoken word. This resource explores the early writing systems of four ancient civilizations: Mesopotamia, Egypt, China, and Mesoamerica. You'll also learn about the Rosetta Stone, the 19th-century discovery that gave scholars the key that unlocked the language of ancient Egypt. Grade Level: Grades 3-5 Collection: Ancient Art, East Asian Art, Egyptian Art, Pre-Columbian Art Culture/Region: America, China, Egypt Subject Area: History and Social Science, Science, Visual Arts Activity Type: Art in Depth HOW ANCIENT WRITING BEGAN… AND ENDED As early civilizations developed, societies became more complicated. Record keeping and communication demanded something beyond symbols and pictures to represent the spoken word. This gallery explores the early writing systems of four ancient civilizations: Mesopotamia, Egypt, China, and Mesoamerica. Here you’ll also learn about the Rosetta Stone, the 19th-century discovery that gave scholars the key that unlocked the language of ancient Egypt. Why were writing systems developed? Communication – Sounds and speech needed to be visually represented. Correspondence – There was a desire to send notes, letters, and instructions. Recording – Bookkeeping tasks became important for counting crops, paying workers’ rations, and collecting taxes. Preservation – Personal stories, rituals, religious texts, hymns, literature, and history all needed to be recorded. Why did some writing systems disappear? Change – Corresponding cultures died out or were absorbed by others. Innovation – Newer, simpler systems replaced older systems. Conquest – Invaders or new rulers imposed their own writing systems. New Beginnings – New ways of writing developed with new belief systems. -

Maya Hieroglyphic Writing
MAYA HIEROGLYPHIC WRITING Workbook for a Short Course on Maya Hieroglyphic Writing Second Edition, 201 1 J. Kathryn Josserandt and Nicholas A. Hopkins Jaguar Tours 3007 Windy Hill Lane Tallahassee, 32308-4025 FL (850) 385-4344 [email protected] This material is based on work supported in partby Ihe NationalScience Foundation (NSF) under grants BNS-8305806 and BNS-8520749, administered by Ihe Institute for Cultural Ecology of Ihe Tropics (lCEr), and by Ihe National Endowment for Ihe Humanities (NEH), grants RT-20643-86 and RT-21090-89. Any findingsand conclusions or recommendationsexpressed in this publication do not necessarily reflect Ihe views of NSF, NEH, or ICEr. Workbook © Jaguar Tours 2011 CONTENTS Contents Credits and Sources for Figures iv Introductionand Acknowledgements v Bibliography vi Figure 1-1. Mesoamerican Languages x Figure 1-2. The Maya Area xi Figure 1-3. Chronology Chart for tbe Maya Area xii P ART The Classic Maya Maya Hieroglypbic Writing 1: and Figure 14. A FamilyTree of Mayan Languages 2 Mayan Languages 3 Chronology 3 Maya and Earlier Writing 4 Context and Content S Tbe Writing System 5 Figure 1-5. Logographic Signs 6 Figure 1-6. Phonetic Signs 6 Figure 1-7. Landa's "Alphabet" 6 Figure 1-8. A Maya Syllabary 8 Figure 1-9. Reading Order witbin tbe Glyph Block 10 Figure 1-10. Reading Order of Glypb Blocks 10 HieroglyphicTexts II Word Order II Figure 1-11. Examples of Classic Syntax 12 Figure 1-12. Unmarked and Marked Word Order 12 Figure 1-13. Backgrounding and Foregrounding 12-B Figure 1-14. -

Breaking the Maya Code : Michael D. Coe Interview (Night Fire Films)
BREAKING THE MAYA CODE Transcript of filmed interview Complete interview transcripts at www.nightfirefilms.org MICHAEL D. COE Interviewed April 6 and 7, 2005 at his home in New Haven, Connecticut In the 1950s archaeologist Michael Coe was one of the pioneering investigators of the Olmec Civilization. He later made major contributions to Maya epigraphy and iconography. In more recent years he has studied the Khmer civilization of Cambodia. He is the Charles J. MacCurdy Professor of Anthropology, Emeritus at Yale University, and Curator Emeritus of the Anthropology collection of Yale’s Peabody Museum of Natural History. He is the author of Breaking the Maya Code and numerous other books including The Maya Scribe and His World, The Maya and Angkor and the Khmer Civilization. In this interview he discusses: The nature of writing systems The origin of Maya writing The role of writing and scribes in Maya culture The status of Maya writing at the time of the Spanish conquest The impact for good and ill of Bishop Landa The persistence of scribal activity in the books of Chilam Balam and the Caste War Letters Early exploration in the Maya region and early publication of Maya texts The work of Constantine Rafinesque, Stephens and Catherwood, de Bourbourg, Ernst Förstemann, and Alfred Maudslay The Maya Corpus Project Cyrus Thomas Sylvanus Morley and the Carnegie Projects Eric Thompson Hermann Beyer Yuri Knorosov Tania Proskouriakoff His own early involvement with study of the Maya and the Olmec His personal relationship with Yuri -

The Writing Revolution
9781405154062_1_pre.qxd 8/8/08 4:42 PM Page iii The Writing Revolution Cuneiform to the Internet Amalia E. Gnanadesikan A John Wiley & Sons, Ltd., Publication 9781405154062_1_pre.qxd 8/8/08 4:42 PM Page iv This edition first published 2009 © 2009 Amalia E. Gnanadesikan Blackwell Publishing was acquired by John Wiley & Sons in February 2007. Blackwell’s publishing program has been merged with Wiley’s global Scientific, Technical, and Medical business to form Wiley-Blackwell. Registered Office John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, United Kingdom Editorial Offices 350 Main Street, Malden, MA 02148-5020, USA 9600 Garsington Road, Oxford, OX4 2DQ, UK The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, UK For details of our global editorial offices, for customer services, and for information about how to apply for permission to reuse the copyright material in this book please see our website at www.wiley.com/wiley-blackwell. The right of Amalia E. Gnanadesikan to be identified as the author of this work has been asserted in accordance with the Copyright, Designs and Patents Act 1988. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, except as permitted by the UK Copyright, Designs and Patents Act 1988, without the prior permission of the publisher. Wiley also publishes its books in a variety of electronic formats. Some content that appears in print may not be available in electronic books. Designations used by companies to distinguish their products are often claimed as trademarks. -

The Development of Writing and Preliterate Societies
The development of writing and preliterate societies Author: Cynthia Tung Persistent link: http://hdl.handle.net/2345/bc-ir:107209 This work is posted on eScholarship@BC, Boston College University Libraries. Boston College Electronic Thesis or Dissertation, 2015 Copyright is held by the author, with all rights reserved, unless otherwise noted. The development of writing and preliterate societies Cynthia Tung Advisor: MJ Connolly Program in Linguistics Slavic and Eastern Languages Department Boston College April 2015 Abstract This paper explores the question of script choice for a preliterate society deciding to write their language down for the first time through an exposition on types of writing systems and a brief history of a few writing systems throughout the world. Societies sometimes invented new scripts, sometimes adapted existing ones, and other times used a combination of both these techniques. Based on the covered scripts ranging from Mesopotamia to Asia to Europe to the Americas, I identify factors that influence the script decision including neighboring scripts, access to technology, and the circumstances of their introduction to writing. Much of the world uses the Roman alphabet and I present the argument that almost all preliterate societies beginning to write will choose to use a version of the Roman alphabet. However, the alphabet does not fit all languages equally well, and the paper closes out withan investigation into some of these inadequacies and how languages might resolve these issues. Contents 1 Introduction 5 2 What is writing? 6 2.1 Definition . 6 2.2 Types of writing . 6 2.2.1 Pictograms, logograms, and ideograms . -

Paths Into Script Formation in the Ancient Mediterranean Edited by Silvia Ferrara and Miguel Valério
STUDI MICENEI ED EGEO-ANATOLICI NUOVA SERIE SUPPLEMENTO 1 Paths into Script Formation in the Ancient Mediterranean edited by Silvia Ferrara and Miguel Valério Edizioni Quasar STUDI MICENEI ED EGEO-ANATOLICI NUOVA SERIE SUPPLEMENTO 1 è una pubblicazione del Consiglio Nazionale delle Ricerche, Roma ISBN 978-88-7140-898-9 Direttore / Editor-in-chief Anna D’Agata (CNR, Roma) Undertaken with the assistance of Institute for Aegean Prehistory (INSTAP), Philadelphia * Printed with the support of Gerda Henkel Stiftung, Düsseldorf * The editors are grateful to Judith Weingarten for revising the English of the original manuscript Immagine di copertina / Cover illustration Writing Travels the Sea, drawing by Miguel Valério based on signs from the Cretan Hieroglyphic, Byblos and Anatolian Hieroglyphic scripts Stampa e distribuzione / Printing and distribution Edizioni Quasar di Severino Tognon s.r.l. Via Ajaccio 41-43 – 00198 Roma tel. +39 0685358444, fax +39 0685833591 email: [email protected] www.edizioniquasar.it © 2018 CNR - Consiglio Nazionale delle Ricerche Autorizzazione Tribunale di Roma nr. 288/2014 del 31.12.2014 SOMMARIO Anna Lucia D’Agata Preface 7 Silvia Ferrara, Miguel Valério Introduction 9 Image-Bound Scripts at the Inception of Writing 1. Roeland P.-J.E. Decorte The Origins of Bronze Age Aegean Writing: Linear A, Cretan Hieroglyphic and a New Proposed Pathway of Script Formation 13 2. Mark Weeden Hieroglyphic Writing on Old Hittite Seals and Sealings? Towards a Material Basis for Further Research 51 Adaptations: Between Pictorialism and Schematism 3. Juan Pablo Vita, José Ángel Zamora The Byblos Script 75 4. Miguel Valério Cypro-Minoan: An Aegean-derived Syllabary on Cyprus (and Elsewhere) 103 5. -
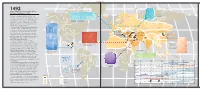
The Spread of the World's Major Writing Systems to 1492
Copyrighted Material 75° the1492 spread of the world’s major writing systems to 1492 Runic inscription Arctic Circle from Sweden, early The adoption of writing marks the end of a society’s 11th century ad. prehistory. Writing has been invented independently many times during world history and is a natural expression of the human capacity for abstract and symbolic thought. Roman inscription from the emperor Trajan’s reign in the Latin alphabet. Writing was a response to growing social and economic complexity and as such it is often considered one of the Ogam defining characteristics of civilization. Runic The earliest known writing system was the Sumerian Mongol pictographic script which developed c. 3400 bc. In the 45° 3rd millennium the pictographs were gradually refined Etruscan Chinese pictographic and simplified, developing into the cuneiform script. Latin Cyrillic alphabet Luvian Proto-Canaanite alphabet Chinese logographic The Sumerian scripts were adopted widely. Sumerian Phoenician-Canaanite alphabet hieroglyphic Korean Mycenaean Linear B Japanese pictographic was adopted by the Elamites and perhaps Sumerian pictographic alphabet Greek alphabet Aramaic script inspired the Indus valley pictographic script. Cuneiform Minoan hieroglyphic Cuneiform Indus was adopted by the Assyrians, Babylonians, Elamites Valley Tibetan Egyptian Elamite script Hittites and Persians among others. pictographic hieroglyphic Nabataean Despite its superficial similarity, the Egyptian Olmec Kufic Brahmic hieroglyphic script, which developed c. 3100 bc, was Epi-Olmec Tropic of Cancer Chinese cursive probably invented independently of Sumerian pictographic. Mixtec Egyptian hieroglyphic inscription script, used from from the 4th century bc. Its influence was limited to Nubia, Minoan Crete and the Zapotec Maya Sabaean Han dynasty times Hittite empire. -

Hieroglyphic Decipherment Guide
Table of Contents Chronological Periods ...........................................................................................1 Classic Period Maya Sites .....................................................................................2 Classic Period & Modern Maya Languages Map ..................................................3 Evolution of Mayan Languages Dendrogram .......................................................4 Reading Order .......................................................................................................6 Phonetic Syllables .................................................................................................7 Numbers ..............................................................................................................13 Dates — Sacred Almanac of 260 Days ...............................................................14 Dates — Solar Calendar of 365 Days .................................................................15 Dates — Long Count ...........................................................................................16 Dates — Supplementary Series: Lords of the Night ............................................17 Dates — Supplementary Series: Lunar Series ....................................................18 Correlation of Maya & Christian Dates ................................................................19 Verbs — Inflectional Endings ..............................................................................21 Verbs — Accession .............................................................................................22 -

SAT Online Practice Test 2 Edition 1.0
Ivy Global SAT Online Practice Test 2 Edition 1.0 PDF downloads are for single print use only: • To license this file for multiple prints, please email [email protected]. • Downloaded files may include a digital signature to track illegal distribution. • Report suspected piracy to [email protected] and earn a reward. Learn more about our new SAT products at: sat.ivyglobal.com SAT Online Practice Test 2 This publication was written and edited by the team at Ivy Global. Editor-in-Chief: Sarah Pike Producers: Lloyd Min and Junho Suh Editors: Sacha Azor, Corwin Henville, and Nathan Létourneau Contributors: Rebecca Anderson, Thea Bélanger-Polak, Grace Bueler, Alexandra Candib, Alex Dunne, Alex Emond, Bessie Fan, Ian Greig, Elizabeth Hilts, Mark Mendola, Geoffrey Morrison, Ward Pettibone, Arden Rogow-Bales, Kristin Rose, Rachel Schloss, Yolanda Song, and Nathan Tebokkel About the Publisher Ivy Global is a pioneering education company that delivers a wide range of educational services. E-mail: [email protected] Website: http://www.ivyglobal.com Edition 3.0 – Copyright 2017 by Ivy Global. All rights reserved. SAT is a registered trademark of the College Board, which is not affiliated with this book. Contents How to Use this Booklet ..................................................................................................................... 5 Practice Test ...................................................................................................................................... 9 Answers and Scoring ....................................................................................................................... 79 How to Use this Booklet How to Use this Booklet Welcome, students and parents! This booklet is intended to help students prepare for the SAT, a test administered by the College Board. It contains an overview of the SAT, a few basic test-taking tips, a full-length practice test, and an answer key with scoring directions. -

The Alphabet Tree Dren’S Puzzles
TUGboat, Volume 26 (2005), No. 3 199 A major intellectual step was the invention of Philology the rebus device. This is where the sounds cor- responding to pictograms are combined to form a word. We have all come across these, often as chil- The alphabet tree dren’s puzzles. For example, a picture of a bee Peter Wilson plus a picture of a tray can represent the word ‘be- tray’, or more obscurely a picture of a bee plus a 1 Introduction picure of a female deer can stand for the word ‘be- We got from via Akn and ’ k n to hind’. Even a single pictogram can suffice; for in- XPD stance a pictogram of the sun can be used for both ` k p A K N, and and @ ¼ à in only about 2000 the words ‘sun’ and ‘son’. Consequently symbols years. This is a short story of how that happened can be created that just stand for sounds and then and how we know what the strange symbols mean, they can be combined to form words. This can a k n a k n e.g., and . The fonts in all the markedly reduce the number of symbols required for examples were designed for use with TEX, especially a full writing system. Symbols representing sounds by humanities scholars, and are freely available. are called phonograms. Phonetic writing requires 1.1 Writing systems few glyphs. In these writing systems, the glyphs represent sounds. All writing systems are a com- The earliest known writing is from Sumeria dating bination of phonetic and logographic elements but from about 3400 bc. -

From the Editors
FROM THE EDITORS The present volume contains papers presented during the 3 rd Cracow Maya Conference convened by the Jagiellonian University and Polish Academy of Arts and Sciences in February 2013. The topic of the 3 rd CMC was devoted to the writing systems of Pre-Columbian Mesoamerica. During the symposium, which was held on the 21 st of February and that opened the event, there were various papers presented by scholars from different countries including Denmark, Finland, Germany, Mexico Poland, Russia and the United Kingdom. The symposium was followed by three-day long workshops concerning writing systems of the ancient Maya and central Mexico with special focus on Teotihuacan and Aztec writing. Subsequent to this event, we invited two more scholars working on the subject at hand, who have kindly accepted our invitation and contributed with their papers to the present volume. Mesoamerica has the distinction of being one of the cradles of writing systems in the world. The other such cradles are the Middle East (represented by Cuneiform and Egyptian Hieroglyphs), the Indus Valley (as exemplified by the Harappan seal tradition) and East Asia (especially the onset of writing associated with oracle bones during the Shang Dynasty) ( e.g. Allan 1999; Daniels and Bright 1996; Gardiner 1973; Glassner 2003; Houston 2008; Parpola 1994; Selden 2013; Woods 2010). Whereas debates still rage as to how the different writing systems of the Old World may have spurred analogous developments, it is clear that the writing systems of Mesoamerica represent independent script inventions from those of the Old World. As is characteristic of such hearths of literacy a series of writing systems are known in Mesoamerica that are to a greater or lesser degree derivatives of one another as daughter scripts of an earlier script, or parallel developments sharing the same underlying structure and constituent units.