Virtual Instruction Set Computing for Heterogeneous Systems ∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Arithmetic and Logic Unit (ALU)
Computer Arithmetic: Arithmetic and Logic Unit (ALU) Arithmetic & Logic Unit (ALU) • Part of the computer that actually performs arithmetic and logical operations on data • All of the other elements of the computer system are there mainly to bring data into the ALU for it to process and then to take the results back out • Based on the use of simple digital logic devices that can store binary digits and perform simple Boolean logic operations ALU Inputs and Outputs Integer Representations • In the binary number system arbitrary numbers can be represented with: – The digits zero and one – The minus sign (for negative numbers) – The period, or radix point (for numbers with a fractional component) – For purposes of computer storage and processing we do not have the benefit of special symbols for the minus sign and radix point – Only binary digits (0,1) may be used to represent numbers Integer Representations • There are 4 commonly known (1 not common) integer representations. • All have been used at various times for various reasons. 1. Unsigned 2. Sign Magnitude 3. One’s Complement 4. Two’s Complement 5. Biased (not commonly known) 1. Unsigned • The standard binary encoding already given. • Only positive value. • Range: 0 to ((2 to the power of N bits) – 1) • Example: 4 bits; (2ˆ4)-1 = 16-1 = values 0 to 15 Semester II 2014/2015 8 1. Unsigned (Cont’d.) Semester II 2014/2015 9 2. Sign-Magnitude • All of these alternatives involve treating the There are several alternative most significant (leftmost) bit in the word as conventions used to -

FUNDAMENTALS of COMPUTING (2019-20) COURSE CODE: 5023 502800CH (Grade 7 for ½ High School Credit) 502900CH (Grade 8 for ½ High School Credit)
EXPLORING COMPUTER SCIENCE NEW NAME: FUNDAMENTALS OF COMPUTING (2019-20) COURSE CODE: 5023 502800CH (grade 7 for ½ high school credit) 502900CH (grade 8 for ½ high school credit) COURSE DESCRIPTION: Fundamentals of Computing is designed to introduce students to the field of computer science through an exploration of engaging and accessible topics. Through creativity and innovation, students will use critical thinking and problem solving skills to implement projects that are relevant to students’ lives. They will create a variety of computing artifacts while collaborating in teams. Students will gain a fundamental understanding of the history and operation of computers, programming, and web design. Students will also be introduced to computing careers and will examine societal and ethical issues of computing. OBJECTIVE: Given the necessary equipment, software, supplies, and facilities, the student will be able to successfully complete the following core standards for courses that grant one unit of credit. RECOMMENDED GRADE LEVELS: 9-12 (Preference 9-10) COURSE CREDIT: 1 unit (120 hours) COMPUTER REQUIREMENTS: One computer per student with Internet access RESOURCES: See attached Resource List A. SAFETY Effective professionals know the academic subject matter, including safety as required for proficiency within their area. They will use this knowledge as needed in their role. The following accountability criteria are considered essential for students in any program of study. 1. Review school safety policies and procedures. 2. Review classroom safety rules and procedures. 3. Review safety procedures for using equipment in the classroom. 4. Identify major causes of work-related accidents in office environments. 5. Demonstrate safety skills in an office/work environment. -

The Central Processing Unit(CPU). the Brain of Any Computer System Is the CPU
Computer Fundamentals 1'stage Lec. (8 ) College of Computer Technology Dept.Information Networks The central processing unit(CPU). The brain of any computer system is the CPU. It controls the functioning of the other units and process the data. The CPU is sometimes called the processor, or in the personal computer field called “microprocessor”. It is a single integrated circuit that contains all the electronics needed to execute a program. The processor calculates (add, multiplies and so on), performs logical operations (compares numbers and make decisions), and controls the transfer of data among devices. The processor acts as the controller of all actions or services provided by the system. Processor actions are synchronized to its clock input. A clock signal consists of clock cycles. The time to complete a clock cycle is called the clock period. Normally, we use the clock frequency, which is the inverse of the clock period, to specify the clock. The clock frequency is measured in Hertz, which represents one cycle/second. Hertz is abbreviated as Hz. Usually, we use mega Hertz (MHz) and giga Hertz (GHz) as in 1.8 GHz Pentium. The processor can be thought of as executing the following cycle forever: 1. Fetch an instruction from the memory, 2. Decode the instruction (i.e., determine the instruction type), 3. Execute the instruction (i.e., perform the action specified by the instruction). Execution of an instruction involves fetching any required operands, performing the specified operation, and writing the results back. This process is often referred to as the fetch- execute cycle, or simply the execution cycle. -

Computer Monitor and Television Recycling
Computer Monitor and Television Recycling What is the problem? Televisions and computer monitors can no longer be discarded in the normal household containers or commercial dumpsters, effective April 10, 2001. Televisions and computer monitors may contain picture tubes called cathode ray tubes (CRT’s). CRT’s can contain lead, cadmium and/or mercury. When disposed of in a landfill, these metals contaminate soil and groundwater. Some larger television sets may contain as much as 15 pounds of lead. A typical 15‐inch CRT computer monitor contains 1.5 pounds of lead. The State Department of Toxic Substances Control has determined that televisions and computer monitors can no longer be disposed with typical household trash, or recycled with typical household recyclables. They are considered universal waste that needs to be disposed of through alternate ways. CRTs should be stored in a safe manner that prevents the CRT from being broken and the subsequent release of hazardous waste into the environment. Locations that will accept televisions, computers, and other electronic waste (e‐waste): If the product still works, trying to find someone that can still use it (donating) is the best option before properly disposing of an electronic product. Non‐profit organizations, foster homes, schools, and places like St. Vincent de Paul may be possible examples of places that will accept usable products. Or view the E‐waste Recycling List at http://www.mercedrecycles.com/pdf's/EwasteRecycling.pdf Where can businesses take computer monitors, televisions, and other electronics? Businesses located within Merced County must register as a Conditionally Exempt Small Quantity Generator (CESQG) prior to the delivery of monitors and televisions to the Highway 59 Landfill. -

Console Games in the Age of Convergence
Console Games in the Age of Convergence Mark Finn Swinburne University of Technology John Street, Melbourne, Victoria, 3122 Australia +61 3 9214 5254 mfi [email protected] Abstract In this paper, I discuss the development of the games console as a converged form, focusing on the industrial and technical dimensions of convergence. Starting with the decline of hybrid devices like the Commodore 64, the paper traces the way in which notions of convergence and divergence have infl uenced the console gaming market. Special attention is given to the convergence strategies employed by key players such as Sega, Nintendo, Sony and Microsoft, and the success or failure of these strategies is evaluated. Keywords Convergence, Games histories, Nintendo, Sega, Sony, Microsoft INTRODUCTION Although largely ignored by the academic community for most of their existence, recent years have seen video games attain at least some degree of legitimacy as an object of scholarly inquiry. Much of this work has focused on what could be called the textual dimension of the game form, with works such as Finn [17], Ryan [42], and Juul [23] investigating aspects such as narrative and character construction in game texts. Another large body of work focuses on the cultural dimension of games, with issues such as gender representation and the always-controversial theme of violence being of central importance here. Examples of this approach include Jenkins [22], Cassell and Jenkins [10] and Schleiner [43]. 45 Proceedings of Computer Games and Digital Cultures Conference, ed. Frans Mäyrä. Tampere: Tampere University Press, 2002. Copyright: authors and Tampere University Press. Little attention, however, has been given to the industrial dimension of the games phenomenon. -

What Is a Microprocessor?
Behavior Research Methods & Instrumentation 1978, Vol. 10 (2),238-240 SESSION VII MICROPROCESSORS IN PSYCHOLOGY: A SYMPOSIUM MISRA PAVEL, New York University, Presider What is a microprocessor? MISRA PAVEL New York University, New York, New York 10003 A general introduction to microcomputer terminology and concepts is provided. The purpose of this introduction is to provide an overview of this session and to introduce the termi MICROPROCESSOR SYSTEM nology and some of the concepts that will be discussed in greater detail by the rest of the session papers. PERIPNERILS EIPERI MENT II A block diagram of a typical small computer system USS PRINIER KErBOARD INIERfICE is shown in Figure 1. Four distinct blocks can be STDRIGE distinguished: (1) the central processing unit (CPU); (2) external memory; (3) peripherals-mass storage, CONTROL standard input/output, and man-machine interface; 0111 BUS (4) special purpose (experimental) interface. IODiISS The different functional units in the system shown here are connected, more or less in parallel, by a number CENTKll ElIEBUL of lines commonly referred to as a bus. The bus mediates PROCESSING ME MOil transfer of information among the units by carrying UN IT address information, data, and control signals. For example, when the CPU transfers data to memory, it activates appropriate control lines, asserts the desired Figure 1. Block diagram of a smaIl computer system. destination memory address, and then outputs data on the bus. Traditionally, the entire system was built from a CU multitude of relatively simple components mounted on interconnected printed circuit cards. With the advances of integrated circuit technology, large amounts of circuitry were squeezed into a single chip. -
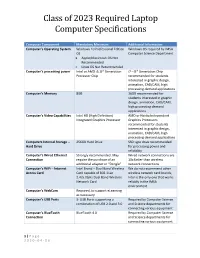
Class of 2023 Required Laptop Computer Specifications
Class of 2023 Required Laptop Computer Specifications Computer Component Mandatory Minimum Additional Information Computer’s Operating System Windows 10 Professional Edition Windows OS required by IMSA OS Computer Science Department Apple/Macintosh OS Not Recommended Linux OS Not Recommended Computer’s processing power Intel or AMD i5, 8th Generation i7 – 8th Generation Chip Processor Chip recommended for students interested in graphic design, animation, CAD/CAM, high processing demand applications Computer’s Memory 8GB 16GB recommended for students interested in graphic design, animation, CAD/CAM, high processing demand applications Computer’s Video Capabilities Intel HD (High Definition) AMD or Nvidia Independent Integrated Graphics Processor Graphics Processors recommended for students interested in graphic design, animation, CAD/CAM, high processing demand applications Computers Internal Storage – 256GB Hard Drive SSD type drive recommended Hard Drive for processing power and reliability Computer’s Wired Ethernet Strongly recommended. May Wired network connections are Connection require the purchase of an 10x faster than wireless additional adapter or “Dongle” network connections Computer’s WiFi – Internet Intel Brand – Dual Band Wireless We do not recommend other Access Card Card capable of 802.11ac wireless network card brands, 2.4/5.0GHz Dual Band Wireless Intel is the only one that works Network Card reliably in the IMSA environment Computer’s WebCam Required, to support eLearning as necessary Computer’s USB Ports 3- USB Ports -

The History of Computing in the History of Technology
The History of Computing in the History of Technology Michael S. Mahoney Program in History of Science Princeton University, Princeton, NJ (Annals of the History of Computing 10(1988), 113-125) After surveying the current state of the literature in the history of computing, this paper discusses some of the major issues addressed by recent work in the history of technology. It suggests aspects of the development of computing which are pertinent to those issues and hence for which that recent work could provide models of historical analysis. As a new scientific technology with unique features, computing in turn can provide new perspectives on the history of technology. Introduction record-keeping by a new industry of data processing. As a primary vehicle of Since World War II 'information' has emerged communication over both space and t ime, it as a fundamental scientific and technological has come to form the core of modern concept applied to phenomena ranging from information technolo gy. What the black holes to DNA, from the organization of English-speaking world refers to as "computer cells to the processes of human thought, and science" is known to the rest of western from the management of corporations to the Europe as informatique (or Informatik or allocation of global resources. In addition to informatica). Much of the concern over reshaping established disciplines, it has information as a commodity and as a natural stimulated the formation of a panoply of new resource derives from the computer and from subjects and areas of inquiry concerned with computer-based communications technolo gy. -

Lecture-1 an Overview of Microprocessor the First
Lecture-1 An Overview of Microprocessor The first question that comes in one’s mind is "What is a microprocessor?”. Let us start with a more familiar term computer. A digital computer is an electronic machine capable of quickly performing a wide variety of tasks. They can be used to compile, correlate, sort, merge and store data as well as perform complex calculations at much faster rate than human being by means of stored instructions. A digital computer is different from a general purpose calculator in a sense that digital computer is capable of operating according to the instructions that are stored within the computer whereas a calculator must be given instructions on a step by step basis to perform calculations. By this definition a programmable calculator can be considered a computer. Historically, digital computers have been categorized according to the size using the words large, medium, minicomputer and microcomputer. In the early years of development, the emphasis was on large and more powerful computers. Large and medium sized computers were designed to solve complex scientific and engineering problems. In early stage of development these computers were accessible and affordable only to large corporations, big universities and government agencies. Later on, minicomputers were made available for use in office, small collage, medium size business organization, small factory etc. As the technology has advanced from SSI to VLSI & SLSI, the face of the computer has changed gradually and it became possible to build the entire central processing unit (CPU) on a single-chip known as microprocessor. A control processing unit (CPU) with its related timing functions on a single chip known as microprocessor. -

Integrated Circuit Design Macmillan New Electronics Series Series Editor: Paul A
Integrated Circuit Design Macmillan New Electronics Series Series Editor: Paul A. Lynn Paul A. Lynn, Radar Systems A. F. Murray and H. M. Reekie, Integrated Circuit Design Integrated Circuit Design Alan F. Murray and H. Martin Reekie Department of' Electrical Engineering Edinhurgh Unit·ersity Macmillan New Electronics Introductions to Advanced Topics M MACMILLAN EDUCATION ©Alan F. Murray and H. Martin Reekie 1987 All rights reserved. No reproduction, copy or transmission of this publication may be made without written permission. No paragraph of this publication may be reproduced, copied or transmitted save with written permission or in accordance with the provisions of the Copyright Act 1956 (as amended), or under the terms of any licence permitting limited copying issued by the Copyright Licensing Agency, 7 Ridgmount Street, London WC1E 7AE. Any person who does any unauthorised act in relation to this publication may be liable to criminal prosecution and civil claims for damages. First published 1987 Published by MACMILLAN EDUCATION LTD Houndmills, Basingstoke, Hampshire RG21 2XS and London Companies and representatives throughout the world British Library Cataloguing in Publication Data Murray, A. F. Integrated circuit design.-(Macmillan new electronics series). 1. Integrated circuits-Design and construction I. Title II. Reekie, H. M. 621.381'73 TK7874 ISBN 978-0-333-43799-5 ISBN 978-1-349-18758-4 (eBook) DOI 10.1007/978-1-349-18758-4 To Glynis and Christa Contents Series Editor's Foreword xi Preface xii Section I 1 General Introduction -

Lab 7 Mosfet Characteristics and Applications
LAB 7 MOSFET CHARACTERISTICS AND APPLICATIONS Objective In this experiment you will study the i-v characteristics of an MOS transistor. You will use the MOSFET as a variable resistor and as a switch. BACKGROUND The MOS (metal-oxide- semiconductor) transistor (or MOSFET) is the basic building block of most computer chips, as well as of chips that include analog and digital circuits. In this lab, we will work with what is called an n-channel MOS transistor. The internal structure and operation of this device, as well as of its complement, the p-channel MOSFET are studied in semiconductor device courses. Here we will concern ourselves only with external i-v behavior. A common symbol for the n-channel MOS transistor is shown in Fig. 1(a). Of the terminals shown, the ones we will focus on are the source, the drain, and the gate. In the transistor we will be working with in this lab, the fourth terminal, labeled body in Fig. 1(a), is not accessible externally; rather, it is internally connected to the source, as shown by the broken line. For simplicity, then, we will use the symbol shown in Fig. 1 (b). (a) (b) Figure 1. MOSFET transistor To study the MOS transistor, we can connect two external voltage sources to it, as shown in Fig. 2. These provide the drain-source voltage vDS and the gate-source voltage vGS. The voltage vDS may cause a drain-to-source current iDS as shown, provided that there is a path for this current from the drain (through the device) to the source. -

5 Computer Organization
5 Computer Organization Source: Foundations of Computer Science Cengage Learning 5.1 Objectives After studying this chapter, students should be able to: List the three subsystems of a computer. Describe the role of the central processing unit (CPU). Describe the fetch-decode-execute phases of a cycle. Describe the main memory and its addressing space. Define the input/output subsystem. Understand the interconnection of subsystems. Describe different methods of input/output addressing. Distinguish the two major trends in the design of computers. Understand how computer throughput can be improved using pipelining and parallel processing. 5.2 1 A computer can be divided into three broad categories or subsystem: the central processing unit (CPU), the main memory and the input/output subsystem. 5.3 5-1 CENTRAL PROCESSING UNIT The central processing unit (CPU) performs operations on data. In most architectures it has three parts: an arithmetic logic unit (ALU), a control unit and a set of registers, fast storage locations. 5.4 2 The arithmetic logic unit (ALU) The arithmetic logic unit (ALU) performs logic, shift, and arithmetic operations on data. Logic operations: NOT, AND, OR, and XOR. Shift operations: logic shift operations and arithmetic shift operations Arithmetic operations: arithmetic operations on integers and reals. 5.5 Registers Registers are fast stand-alone storage locations that hold data temporarily. Multiple registers are needed to facilitate the operation of the CPU. Data registers Instruction register Program counter The control unit The control unit controls the operation of each subsystem. Controlling is achieved through signals sent from the control unit to other subsystems.