22 Ultra-Conserved Elements in Vertebrate and Fly Genomes Mathias Drton Nicholas Eriksson Garmay Leung
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Podocyte Specific Knockdown of Klf15 in Podocin-Cre Klf15flox/Flox Mice Was Confirmed
SUPPLEMENTARY FIGURE LEGENDS Supplementary Figure 1: Podocyte specific knockdown of Klf15 in Podocin-Cre Klf15flox/flox mice was confirmed. (A) Primary glomerular epithelial cells (PGECs) were isolated from 12-week old Podocin-Cre Klf15flox/flox and Podocin-Cre Klf15+/+ mice and cultured at 37°C for 1 week. Real-time PCR was performed for Nephrin, Podocin, Synaptopodin, and Wt1 mRNA expression (n=6, ***p<0.001, Mann-Whitney test). (B) Real- time PCR was performed for Klf15 mRNA expression (n=6, *p<0.05, Mann-Whitney test). (C) Protein was also extracted and western blot analysis for Klf15 was performed. The representative blot of three independent experiments is shown in the top panel. The bottom panel shows the quantification of Klf15 by densitometry (n=3, *p<0.05, Mann-Whitney test). (D) Immunofluorescence staining for Klf15 and Wt1 was performed in 12-week old Podocin-Cre Klf15flox/flox and Podocin-Cre Klf15+/+ mice. Representative images from four mice in each group are shown in the left panel (X 20). Arrows show colocalization of Klf15 and Wt1. Arrowheads show a lack of colocalization. Asterisk demonstrates nonspecific Wt1 staining. “R” represents autofluorescence from RBCs. In the right panel, a total of 30 glomeruli were selected in each mouse and quantification of Klf15 staining in the podocytes was determined by the ratio of Klf15+ and Wt1+ cells to Wt1+ cells (n=6 mice, **p<0.01, unpaired t test). Supplementary Figure 2: LPS treated Podocin-Cre Klf15flox/flox mice exhibit a lack of recovery in proteinaceous casts and tubular dilatation after DEX administration. -

Endolysosomal Cation Channels and MITF in Melanocytes and Melanoma
biomolecules Review Endolysosomal Cation Channels and MITF in Melanocytes and Melanoma Carla Abrahamian and Christian Grimm * Walther Straub Institute of Pharmacology and Toxicology, Faculty of Medicine, Ludwig-Maximilians-University, 80336 Munich, Germany; [email protected] * Correspondence: [email protected] Abstract: Microphthalmia-associated transcription factor (MITF) is the principal transcription fac- tor regulating pivotal processes in melanoma cell development, growth, survival, proliferation, differentiation and invasion. In recent years, convincing evidence has been provided attesting key roles of endolysosomal cation channels, specifically TPCs and TRPMLs, in cancer, including breast cancer, glioblastoma, bladder cancer, hepatocellular carcinoma and melanoma. In this review, we provide a gene expression profile of these channels in different types of cancers and decipher their roles, in particular the roles of two-pore channel 2 (TPC2) and TRPML1 in melanocytes and melanoma. We specifically discuss the signaling cascades regulating MITF and the relationship between endolysosomal cation channels, MAPK, canonical Wnt/GSK3 pathways and MITF. Keywords: TPC; two-pore; lysosome; TPC1; TPC2; TRPML; mucolipin; MCOLN; TRPML1; MITF; melanocytes; melanoma; mTOR; TFEB; calcium Citation: Abrahamian, C.; Grimm, C. 1. Introduction Endolysosomal Cation Channels and Melanocytes are neural-crest derived cells that produce melanin, the primary de- MITF in Melanocytes and Melanoma. terminant of skin color. Melanin is also found in hair, in the iris of the eye, and in the Biomolecules 2021, 11, 1021. https:// stria vascularis of the inner ear and, to a lesser degree, in a broad range of other tissues doi.org/10.3390/biom11071021 throughout the body [1]. There are two major types of melanin called eumelanin (dark, brown, black) and pheomelanin (yellow, red, light brown). -

Association of Gene Ontology Categories with Decay Rate for Hepg2 Experiments These Tables Show Details for All Gene Ontology Categories
Supplementary Table 1: Association of Gene Ontology Categories with Decay Rate for HepG2 Experiments These tables show details for all Gene Ontology categories. Inferences for manual classification scheme shown at the bottom. Those categories used in Figure 1A are highlighted in bold. Standard Deviations are shown in parentheses. P-values less than 1E-20 are indicated with a "0". Rate r (hour^-1) Half-life < 2hr. Decay % GO Number Category Name Probe Sets Group Non-Group Distribution p-value In-Group Non-Group Representation p-value GO:0006350 transcription 1523 0.221 (0.009) 0.127 (0.002) FASTER 0 13.1 (0.4) 4.5 (0.1) OVER 0 GO:0006351 transcription, DNA-dependent 1498 0.220 (0.009) 0.127 (0.002) FASTER 0 13.0 (0.4) 4.5 (0.1) OVER 0 GO:0006355 regulation of transcription, DNA-dependent 1163 0.230 (0.011) 0.128 (0.002) FASTER 5.00E-21 14.2 (0.5) 4.6 (0.1) OVER 0 GO:0006366 transcription from Pol II promoter 845 0.225 (0.012) 0.130 (0.002) FASTER 1.88E-14 13.0 (0.5) 4.8 (0.1) OVER 0 GO:0006139 nucleobase, nucleoside, nucleotide and nucleic acid metabolism3004 0.173 (0.006) 0.127 (0.002) FASTER 1.28E-12 8.4 (0.2) 4.5 (0.1) OVER 0 GO:0006357 regulation of transcription from Pol II promoter 487 0.231 (0.016) 0.132 (0.002) FASTER 6.05E-10 13.5 (0.6) 4.9 (0.1) OVER 0 GO:0008283 cell proliferation 625 0.189 (0.014) 0.132 (0.002) FASTER 1.95E-05 10.1 (0.6) 5.0 (0.1) OVER 1.50E-20 GO:0006513 monoubiquitination 36 0.305 (0.049) 0.134 (0.002) FASTER 2.69E-04 25.4 (4.4) 5.1 (0.1) OVER 2.04E-06 GO:0007050 cell cycle arrest 57 0.311 (0.054) 0.133 (0.002) -

(12) Patent Application Publication (10) Pub. No.: US 2006/0088532 A1 Alitalo Et Al
US 20060O88532A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2006/0088532 A1 Alitalo et al. (43) Pub. Date: Apr. 27, 2006 (54) LYMPHATIC AND BLOOD ENDOTHELIAL Related U.S. Application Data CELL GENES (60) Provisional application No. 60/363,019, filed on Mar. (76) Inventors: Kari Alitalo, Helsinki (FI); Taija 7, 2002. Makinen, Helsinki (FI); Tatiana Petrova, Helsinki (FI); Pipsa Publication Classification Saharinen, Helsinki (FI); Juha Saharinen, Helsinki (FI) (51) Int. Cl. A6IR 48/00 (2006.01) Correspondence Address: A 6LX 39/395 (2006.01) MARSHALL, GERSTEIN & BORUN LLP A6II 38/18 (2006.01) 233 S. WACKER DRIVE, SUITE 6300 (52) U.S. Cl. .............................. 424/145.1: 514/2: 514/44 SEARS TOWER (57) ABSTRACT CHICAGO, IL 60606 (US) The invention provides polynucleotides and genes that are (21) Appl. No.: 10/505,928 differentially expressed in lymphatic versus blood vascular endothelial cells. These genes are useful for treating diseases (22) PCT Filed: Mar. 7, 2003 involving lymphatic vessels, such as lymphedema, various inflammatory diseases, and cancer metastasis via the lym (86). PCT No.: PCT/USO3FO6900 phatic system. Patent Application Publication Apr. 27, 2006 Sheet 1 of 2 US 2006/0088532 A1 integrin O9 integrin O1 KIAAO711 KAAO644 ApoD Fig. 1 Patent Application Publication Apr. 27, 2006 Sheet 2 of 2 US 2006/0088532 A1 CN g uueleo-gº US 2006/0O88532 A1 Apr. 27, 2006 LYMPHATIC AND BLOOD ENDOTHELLAL CELL lymphatic vessels, such as lymphangiomas or lymphang GENES iectasis. Witte, et al., Regulation of Angiogenesis (eds. Goldber, I. D. & Rosen, E. M.) 65-112 (Birkauser, Basel, BACKGROUND OF THE INVENTION Switzerland, 1997). -

Analysis of Early Changes in DNA Methylation in Synovial Fibroblasts
www.nature.com/scientificreports OPEN Analysis of early changes in DNA methylation in synovial fbroblasts of RA patients before diagnosis Received: 14 November 2017 Emmanuel Karouzakis1, Karim Raza2,4, Christoph Kolling 3, Christopher D. Buckley 2, Accepted: 26 March 2018 Stefen Gay1, Andrew Filer2,5 & Caroline Ospelt1 Published: xx xx xxxx DNA methylation is an important epigenetic modifcation that is known to be altered in rheumatoid arthritis synovial fbroblasts (RASF). Here, we compared the status of promoter DNA methylation of SF from patients with very early RA with SF from patients with resolving arthritis, fully established RA and from non-arthritic patients. DNA was hybridized to Infnium Human methylation 450k and 850k arrays and diferential methylated genes and pathways were identifed. We could identify a signifcant number of CpG sites that difered between the SF of diferent disease stages, showing that epigenetic changes in SF occur early in RA development. Principal component analysis confrmed that the diferent groups of SF were separated according to their DNA methylation state. Furthermore, pathway analysis showed that important functional pathways were altered in both very early and late RASF. By focusing our analysis on CpG sites in CpG islands within promoters, we identifed genes that have signifcant hypermethylated promoters in very early RASF. Our data show that changes in DNA methylation difer in RASF compared to other forms of arthritis and occur at a very early, clinically yet unspecifc stage of disease. The identifed diferential methylated genes might become valuable prognostic biomarkers for RA development. Rheumatoid arthritis (RA) is a chronic, destructive autoimmune arthritis that afects 0.5–1% of the population worldwide. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Mitf and Tfe3, Two Members of the Mitf-Tfe Family of Bhlh-Zip Transcription Factors, Have Important but Functionally Redundant Roles in Osteoclast Development
Mitf and Tfe3, two members of the Mitf-Tfe family of bHLH-Zip transcription factors, have important but functionally redundant roles in osteoclast development Eiri´kur Steingri´msson*†, Lino Tessarollo‡, Bhavani Pathak§¶, Ling Houʈ**, Heinz Arnheiterʈ, Neal G. Copeland§, and Nancy A. Jenkins§ *Department of Biochemistry and Molecular Biology, Faculty of Medicine, University of Iceland, 101 Reykjavik, Iceland; ‡Neural Development Group and §Mouse Cancer Genetics Program, National Cancer Institute, Frederick, MD 21702-1201; and ʈLaboratory of Developmental Neurogenetics, National Institute of Neurological Disorders and Stroke, National Institutes of Health, Bethesda, MD 20892 Communicated by Liane B. Russell, Oak Ridge National Laboratory, Oak Ridge, TN, February 6, 2002 (received for review December 1, 2001) The Mitf-Tfe family of basic helix–loop–helix-leucine zipper (bHLH- neuroepithelial-derived retinal pigment epithelium of the eye, Zip) transcription factors encodes four family members: Mitf, Tfe3, ultimately resulting in microphthalmia, and some Mitf mutations Tfeb, and Tfec. In vitro, each protein in the family can bind DNA as result in a reduction in mast cell numbers. Thus, the Mitf a homo- or heterodimer with other family members. Mutational mutations are pleiotropic, affect many different cell types, and studies in mice have shown that Mitf is essential for melanocyte can be arranged in an allelic series (4). and eye development, whereas Tfeb is required for placental A mutation has been made in the Tfeb gene (TfebFcr) and vascularization. Here, we uncover a role for Tfe3 in osteoclast results in embryonic lethality because of defects in placental development, a role that is functionally redundant with Mitf. -

Identi Cation of Potential Biomarkers and Pathways
Identication of Potential Biomarkers and Pathways in Neonatal Hypoxic-Ischemic Brain Injury: Based on Bioinformatics Technology Shangbin Li The First Hospital of Hebei Medical University Shuangshuang Li Chengdu University of Traditional Chinese Medicine Qian Zhao The First Hospital of Hebei Medical University Jiayu Huang The First Hospital of Hebei Medical University Jinfeng Meng The First Hospital of Hebei Medical University Weichen Yan The First Hospital of Hebei Medical University Jie Wang The First Hospital of Hebei Medical University Changjun Ren ( [email protected] ) The First Hospital of Hebei Medical University Ling Hao The First Hospital of Hebei Medical University Research Article Keywords: neonatal hypoxic-ischemic brain injury, inammatory response, immune response, differentially expressed genes, bioinformatics analysis Posted Date: August 5th, 2021 DOI: https://doi.org/10.21203/rs.3.rs-777916/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 1/22 Abstract Background Neonatal hypoxic-ischemic brain damage (HIBD) is one of the most common serious diseases in newborns, with a high mortality and disability rate. This study aims to use the bioinformatics analysis to identify potential hematologic/immune systems tissue-specic genes and related signaling pathways neonatal HIBD. Methods Microarray datasets in HIBD were downloaded from the Gene Expression Omnibus database, and DEGs were identied by R software.Enrichment analyses were performed and protein–protein interaction networks were constructed to understand the functions and enriched pathways of DEGs and to identify central genes and key modules. Results In the cerebral cortex tissue with HIBD, 2598 DEGs were identied, including 2362 up-regulated and 236 down-regulated DEGs. -
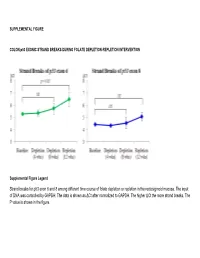
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

WO 2012/054896 Al
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number ι (43) International Publication Date ¾ ί t 2 6 April 2012 (26.04.2012) WO 2012/054896 Al (51) International Patent Classification: AO, AT, AU, AZ, BA, BB, BG, BH, BR, BW, BY, BZ, C12N 5/00 (2006.01) C12N 15/00 (2006.01) CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, DO, C12N 5/02 (2006.01) DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KM, KN, KP, (21) International Application Number: KR, KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, PCT/US201 1/057387 ME, MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, (22) International Filing Date: NO, NZ, OM, PE, PG, PH, PL, PT, QA, RO, RS, RU, 2 1 October 201 1 (21 .10.201 1) RW, SC, SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, (25) Filing Language: English ZM, ZW. (26) Publication Language: English (84) Designated States (unless otherwise indicated, for every (30) Priority Data: kind of regional protection available): ARIPO (BW, GH, 61/406,064 22 October 2010 (22.10.2010) US GM, KE, LR, LS, MW, MZ, NA, RW, SD, SL, SZ, TZ, 61/415,244 18 November 2010 (18.1 1.2010) US UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, MD, RU, TJ, TM), European (AL, AT, BE, BG, CH, CY, CZ, (71) Applicant (for all designated States except US): BIO- DE, DK, EE, ES, FI, FR, GB, GR, HR, HU, IE, IS, IT, TIME INC. -

BMC Biology Biomed Central
BMC Biology BioMed Central Research article Open Access Classification and nomenclature of all human homeobox genes PeterWHHolland*†1, H Anne F Booth†1 and Elspeth A Bruford2 Address: 1Department of Zoology, University of Oxford, South Parks Road, Oxford, OX1 3PS, UK and 2HUGO Gene Nomenclature Committee, European Bioinformatics Institute (EMBL-EBI), Wellcome Trust Genome Campus, Hinxton, Cambridgeshire, CB10 1SA, UK Email: Peter WH Holland* - [email protected]; H Anne F Booth - [email protected]; Elspeth A Bruford - [email protected] * Corresponding author †Equal contributors Published: 26 October 2007 Received: 30 March 2007 Accepted: 26 October 2007 BMC Biology 2007, 5:47 doi:10.1186/1741-7007-5-47 This article is available from: http://www.biomedcentral.com/1741-7007/5/47 © 2007 Holland et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: The homeobox genes are a large and diverse group of genes, many of which play important roles in the embryonic development of animals. Increasingly, homeobox genes are being compared between genomes in an attempt to understand the evolution of animal development. Despite their importance, the full diversity of human homeobox genes has not previously been described. Results: We have identified all homeobox genes and pseudogenes in the euchromatic regions of the human genome, finding many unannotated, incorrectly annotated, unnamed, misnamed or misclassified genes and pseudogenes. -

MITF: Master Regulator of Melanocyte Development and Melanoma Oncogene
Review TRENDS in Molecular Medicine Vol.12 No.9 MITF: master regulator of melanocyte development and melanoma oncogene Carmit Levy, Mehdi Khaled and David E. Fisher Melanoma Program and Department of Pediatric Hematology and Oncology, Dana-Farber Cancer Institute, Children’s Hospital Boston, 44 Binney Street, Boston, MA 02115, USA Microphthalmia-associated transcription factor (MITF) between MITF and TFE3 in the development of the acts as a master regulator of melanocyte development, osteoclast lineage [8]. From these analyses, it seems that function and survival by modulating various differentia- MITF is the only MiT family member that is functionally tion and cell-cycle progression genes. It has been essential for normal melanocytic development. demonstrated that MITF is an amplified oncogene in a MITF is thought to mediate significant differentiation fraction of human melanomas and that it also has an effects of the a-melanocyte-stimulating hormone (a-MSH) oncogenic role in human clear cell sarcoma. However, [9,10] by transcriptionally regulating enzymes that are MITF also modulates the state of melanocyte differentia- essential for melanin production in differentiated melano- tion. Several closely related transcription factors also cytes [11]. Although these data implicate MITF in both the function as translocated oncogenes in various human survival and differentiation of melanocytes, little is known malignancies. These data place MITF between instruct- about the biochemical regulatory pathways that control ing melanocytes towards terminal differentiation and/or MITF in its different roles. pigmentation and, alternatively, promoting malignant behavior. In this review, we survey the roles of MITF as a Transcriptional and post-translational MITF regulation master lineage regulator in melanocyte development The MITF gene has a multi-promoter organization in and its emerging activities in malignancy.