18. on Defining Parts of Speech with Generative Grammar and Nsm
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Typological Differences Between English and Chinese Multi-Verb Constructions
Linguistics and Literature Studies 7(3): 110-115, 2019 http://www.hrpub.org DOI: 10.13189/lls.2019.070303 Typological Differences between English and Chinese Multi-verb Constructions Mengmeng Tang School of Foreign Studies, China University of Petroleum, China Copyright©2019 by authors, all rights reserved. Authors agree that this article remains permanently open access under the terms of the Creative Commons Attribution License 4.0 International License Abstract English and Chinese are different in the verbs in one temporal category, with fixed order and no composition of Multi-verb Constructions (MVCs), which conjunctions [25], a language phenomenon without a refer to a series of verbs appearing in a mono-clause, counterpart in English. without pauses or conjunctions. English MVCs contain a There has been a long-running discussion on Chinese finite verb which inflects with tense, combined with finite and non-finite verb distinctions (e.g., [5-8, 16-18, non-finite forms (e.g., The boss encouraged Jerry to attend 21-24, 27-30]). Although there has been a considerable the meeting). Chinese MVCs are in the form of bare verbs theoretical discussion of Chinese finiteness, no research or verbs with aspectual morphemes. From the perspective has been undertaken to date from the perspective of the of finiteness, this article analyzes the typological typological differences of semantic finiteness in Chinese differences of morphological finiteness in English and and morphological finiteness in English in MVCs. semantic finiteness in Chinese. Keywords Multi-verb Constructions, Finiteness 2. Multi-verb Constructions Verbs are the core of a sentence. Descriptive linguists and comparative syntacticians have examined the 1. -

Deixis and Reference Tracing in Tsova-Tush (PDF)
DEIXIS AND REFERENCE TRACKING IN TSOVA-TUSH A DISSERTATION SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAIʻI AT MĀNOA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN LINGUISTICS MAY 2020 by Bryn Hauk Dissertation committee: Andrea Berez-Kroeker, Chairperson Alice C. Harris Bradley McDonnell James N. Collins Ashley Maynard Acknowledgments I should not have been able to finish this dissertation. In the course of my graduate studies, enough obstacles have sprung up in my path that the odds would have predicted something other than a successful completion of my degree. The fact that I made it to this point is a testament to thekind, supportive, wise, and generous people who have picked me up and dusted me off after every pothole. Forgive me: these thank-yous are going to get very sappy. First and foremost, I would like to thank my Tsova-Tush host family—Rezo Orbetishvili, Nisa Baxtarishvili, and of course Tamar and Lasha—for letting me join your family every summer forthe past four years. Your time, your patience, your expertise, your hospitality, your sense of humor, your lovingly prepared meals and generously poured wine—these were the building blocks that supported all of my research whims. My sincerest gratitude also goes to Dantes Echishvili, Revaz Shankishvili, and to all my hosts and friends in Zemo Alvani. It is possible to translate ‘thank you’ as მადელ შუნ, but you have taught me that gratitude is better expressed with actions than with set phrases, sofor now I will just say, ღაზიშ ხილჰათ, ბედნიერ ხილჰათ, მარშმაკიშ ხილჰათ.. -

Instrumentality: the Core Meaning of the Coverb Yi 以 in Classical Chinese
Proceedings of the 20th North American Conference on Chinese Linguistics (NACCL-20). 2008. Volume 1. Edited by Marjorie K.M. Chan and Hana Kang. Columbus, Ohio: The Ohio State University. Pages 489-498. Instrumentality: The Core Meaning of the Coverb Yi 以 in Classical Chinese Sue-mei Wu 吳素美 Carnegie Mellon University Yi 以 is one of the most important and commonly used function words in Classical Chinese, and many researchers (e.g. Hsueh 1997, Pulleyblank 1995, Sun 1991, Wu 1994 and Wu 1997) have contributed to the discussion on yi's meanings and functions. The main issues in the current understanding of yi include its verb and coverb usages. Both usages have been thought to exhibit a range of meanings, and yi has been thought to be able to occur flexibly either before or after a verb phrase. In addition, yi is also thought to be a conjunction indicating the reason, purpose or result of an action. This study proposes that the verb yi fundamentally indicates instrumentality, and that the coverb yi, which is derived from the verb yi, still retains that fundamental notion of instrumentality. The notion of instrumentality has been extended in yi's coverb usage to indicate the means or reason by which an action occurs, or the time which an action occurs. Moreover, I will also argue that the yi phrase, when it occurs before a verb phrase, functions syntactically as a modifier to the verb phrase. When the yi phrase occurs after another verb phrase, however, the semantic emphasis has been deliberately put on the yi phrase, which then serves as the nucleus of the predicate. -

RELATIONAL NOUNS, PRONOUNS, and Resumptionw Relational Nouns, Such As Neighbour, Mother, and Rumour, Present a Challenge to Synt
Linguistics and Philosophy (2005) 28:375–446 Ó Springer 2005 DOI 10.1007/s10988-005-2656-7 ASH ASUDEH RELATIONAL NOUNS, PRONOUNS, AND RESUMPTIONw ABSTRACT. This paper presents a variable-free analysis of relational nouns in Glue Semantics, within a Lexical Functional Grammar (LFG) architecture. Rela- tional nouns and resumptive pronouns are bound using the usual binding mecha- nisms of LFG. Special attention is paid to the bound readings of relational nouns, how these interact with genitives and obliques, and their behaviour with respect to scope, crossover and reconstruction. I consider a puzzle that arises regarding rela- tional nouns and resumptive pronouns, given that relational nouns can have bound readings and resumptive pronouns are just a specific instance of bound pronouns. The puzzle is: why is it impossible for bound implicit arguments of relational nouns to be resumptive? The puzzle is highlighted by a well-known variety of variable-free semantics, where pronouns and relational noun phrases are identical both in category and (base) type. I show that the puzzle also arises for an established variable-based theory. I present an analysis of resumptive pronouns that crucially treats resumptives in terms of the resource logic linear logic that underlies Glue Semantics: a resumptive pronoun is a perfectly ordinary pronoun that constitutes a surplus resource; this surplus resource requires the presence of a resumptive-licensing resource consumer, a manager resource. Manager resources properly distinguish between resumptive pronouns and bound relational nouns based on differences between them at the level of semantic structure. The resumptive puzzle is thus solved. The paper closes by considering the solution in light of the hypothesis of direct compositionality. -

Chapter 1 Basic Categorial Syntax
Hardegree, Compositional Semantics, Chapter 1 : Basic Categorial Syntax 1 of 27 Chapter 1 Basic Categorial Syntax 1. The Task of Grammar ............................................................................................................ 2 2. Artificial versus Natural Languages ....................................................................................... 2 3. Recursion ............................................................................................................................... 3 4. Category-Governed Grammars .............................................................................................. 3 5. Example Grammar – A Tiny Fragment of English ................................................................. 4 6. Type-Governed (Categorial) Grammars ................................................................................. 5 7. Recursive Definition of Types ............................................................................................... 7 8. Examples of Types................................................................................................................. 7 9. First Rule of Composition ...................................................................................................... 8 10. Examples of Type-Categorial Analysis .................................................................................. 8 11. Quantifiers and Quantifier-Phrases ...................................................................................... 10 12. Compound Nouns -

Chinese: Parts of Speech
Chinese: Parts of Speech Candice Chi-Hang Cheung 1. Introduction Whether Chinese has the same parts of speech (or categories) as the Indo-European languages has been the subject of much debate. In particular, while it is generally recognized that Chinese makes a distinction between nouns and verbs, scholars’ opinions differ on the rest of the categories (see Chao 1968, Li and Thompson 1981, Zhu 1982, Xing and Ma 1992, inter alia). These differences in opinion are due partly to the scholars’ different theoretical backgrounds and partly to the use of different terminological conventions. As a result, scholars use different criteria for classifying words and different terminological conventions for labeling the categories. To address the question of whether Chinese possesses the same categories as the Indo-European languages, I will make reference to the familiar categories of the Indo-European languages whenever possible. In this chapter, I offer a comprehensive survey of the major categories in Chinese, aiming to establish the set of categories that are found both in Chinese and in the Indo-European languages, and those that are found only in Chinese. In particular, I examine the characteristic features of the major categories in Chinese and discuss in what ways they are similar to and different from the major categories in the Indo-European languages. Furthermore, I review the factors that contribute to the long-standing debate over the categorial status of adjectives, prepositions and localizers in Chinese. 2. Categories found both in Chinese and in the Indo-European languages This section introduces the categories that are found both in Chinese and in the Indo-European languages: nouns, verbs, adjectives, adverbs, prepositions and conjunctions. -

September 15 & 17 Class Summary: 24.902
September 15 & 17 class summary: 24.902 could not be replaced by depend, because depend bears the distinct feature [+ __ NP PP]. The week actually began with some unfinished business from last week, which is OK, painful detail. What is interesting to us is a constraint proposed by Chomsky on the contained in the previous summary. Then we moved on... ability of a subcategorization rule to control the environment in which it applies. 1. Preliminaries Chomsky claimed that the environment of the subcategorization rule for X makes A word often cares about its syntactic environment. A verb, for example, may reference to all and only the sisters of X. More simply still: the subcategorization property require two, one or zero complements, and (seemingly -- see below!) may specify the of X cares only about the sisters of X. syntactic category of its complement. Terminological note: As mentioned in class, a slightly different way of speaking has arisen in the field of syntax. We say that a verb like put "subcategorizes for" an NP and a • Examples: put requires NP PP, devour requiresNP, depend requires PP, eat takes an optional NP. PP. Likewise a verb like eat "subcategorizes for" an optional NP. • Chomsky's constraint has interesting implications for language acquisition. Granted (1) a. Sue put the book under the table. that a child must maintain some record of the syntactic environment in which lexical b. *Sue put the book. items occur (or else subcategorization information would not be acquired), Chomsky's c. *Sue put under the table. constraint suggests that this information is quite limited. -

Copular Constructions in Colloquial Singaporean English
Copular Constructions in Colloquial Singaporean English Honour School of Psychology, Philosophy, and Linguistics Paper C: Linguistic Project 2020 Candidate no. 1025395 Word count: 10,000 Contents List of abbreviations iv 1 Introduction 1 1.1 Language in Singapore ......................... 2 1.1.1 Early and colonial history ................... 2 1.1.2 Independence and language policies ............. 3 1.2 Colloquial Singaporean English .................... 4 1.2.1 Evolution of CSE ........................ 4 1.2.2 Status of CSE .......................... 5 1.3 Summary ................................ 6 2 Copular Constructions in Lexical-Functional Grammar 7 2.1 LFG analyses of copular constructions ................ 8 2.1.1 Single-tier analysis ....................... 9 2.1.2 Open complement double-tier analysis ............ 12 2.1.3 Closed complement double-tier analysis ........... 15 2.2 Copular constructions in SSE ..................... 17 2.3 Copular constructions in Chinese ................... 17 2.3.1 NP predicatives in Chinese .................. 17 2.3.2 AP predicatives in Chinese .................. 18 2.3.3 PP predicatives in Chinese .................. 19 2.3.4 LFG analyses of Chinese copular constructions ....... 20 2.4 Copular constructions in Malay .................... 21 2.4.1 NP predicatives in Malay ................... 21 2.4.2 AP predicatives in Malay ................... 22 2.4.3 PP predicatives in Malay ................... 22 2.4.4 LFG analyses of Malay copular constructions ........ 23 2.5 Copular constructions in CSE ..................... 23 2.6 Summary ................................ 25 ii Contents iii 3 Distribution of Copular Constructions in CSE 27 3.1 Introduction ............................... 27 3.2 Pilot study ............................... 29 3.2.1 Participants ........................... 29 3.2.2 Task ............................... 30 3.2.3 Results and discussion ..................... 31 3.3 Main study .............................. -
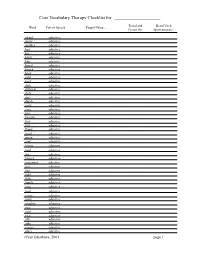
250 Word List
Core Vocabulary Therapy Checklist for ____________________ Tested and Heard Used Word Part of Speech Taught Using ... Passed On: Spontaneously: afraid adjective angry adjective another adjective bad adjective big adjective black adjective blue adjective bored adjective brown adjective busy adjective cold adjective cool adjective dark adjective different adjective dirty adjective dry adjective dumb adjective early adjective easy adjective fast adjective favorite adjective first adjective full adjective funny adjective good adjective green adjective grey adjective happy adjective hard adjective hot adjective hungry adjective important adjective last adjective late adjective light adjective little adjective lonely adjective long adjective mad adjective many adjective more adjective naughty adjective new adjective next adjective nice adjective old adjective only adjective orange adjective other adjective ©VanTatenhove, 2001 page 1 Core Vocabulary Therapy Checklist for ____________________ Word Part of Speech Taught Using ... Tested and Heard Used Passed On: Spontaneously: pink adjective purple adjective real adjective red adjective right adjective sad adjective same adjective sick adjective silly adjective sure adjective thirsty adjective tired adjective wet adjective white adjective wrong adjective yellow adjective adjective adjective adjective again adverb all right adverb almost adverb already adverb always adverb away adverb backwards adverb forward adverb here adverb indoors adverb just adverb maybe adverb much adverb never adverb not -

Remarks on the History of the Indo-European Infinitive Dorothy Disterheft University of South Carolina - Columbia, [email protected]
University of South Carolina Scholar Commons Faculty Publications Linguistics, Program of 1981 Remarks on the History of the Indo-European Infinitive Dorothy Disterheft University of South Carolina - Columbia, [email protected] Follow this and additional works at: https://scholarcommons.sc.edu/ling_facpub Part of the Linguistics Commons Publication Info Published in Folia Linguistica Historica, Volume 2, Issue 1, 1981, pages 3-34. Disterheft, D. (1981). Remarks on the History of the Indo-European Infinitive. Folia Linguistica Historica, 2(1), 3-34. DOI: 10.1515/ flih.1981.2.1.3 © 1981 Societas Linguistica Europaea. This Article is brought to you by the Linguistics, Program of at Scholar Commons. It has been accepted for inclusion in Faculty Publications by an authorized administrator of Scholar Commons. For more information, please contact [email protected]. Foli.lAfl//ui.tfcoFolia Linguistica HfltorlcGHistorica II/III/l 'P'P.pp. 8-U3—Z4 © 800£etruSocietae lAngu,.ticaLinguistica Etlropaea.Evropaea, 1981lt)8l REMARKSBEMARKS ONON THETHE HISTORYHISTOKY OFOF THETHE INDO-EUROPEANINDO-EUROPEAN INFINITIVEINFINITIVE i DOROTHYDOROTHY DISTERHEFTDISTERHEFT I 1.1. INTRODUCTIONINTRODUCTION WithWith thethe exceptfonexception ofof Indo-IranianIndo-Iranian (Ur)(Hr) andand CelticCeltic allall historicalhistorical Indo-EuropeanIndo-European (IE)(IE) subgroupssubgroups havehave a morphologicalIymorphologically distinctdistinct II infinitive.Infinitive. However,However, nono singlesingle proto-formproto-form cancan bebe reconstructedreconstructed -

Navajo Verb Stem Position and the Bipartite Structure of the Navajo
678 REMARKSANDREPLIES NavajoVerb Stem Positionand the BipartiteStructure of the NavajoConjunct Sector Ken Hale TheNavajo verb stem appears at the rightmost edge of the verb word. Innumerouscases it forms a lexicalconstituent with a preverb,occur- ringat theleftmost edge of thesurface verb word, much in themanner ofDutchand German verb-particle arrangements in verb-secondfinite clauses.In Navajothe initial and finalpositions are separated by eight morphemeorder ‘ ‘slots’’ recognizedin the Athabaskan literature (and describedin detail for Navajo in Young and Morgan 1987). A phono- logicalsolution to this and a numberof otherdeep-surface disparities isexploredhere, based on theinsights of earlierworks on theNavajo verb,including Speas 1984, 1990, McDonough 1996, 2000, and Rice 1989, 2000. Keywords: verbmorphology, morphosyntactic disparity, spell-out, Navajo,Athabaskan 1Verb Stem Position TheNavajo verb stem forms asinglelexical constituent with the prefixal, particle-like category called preverb inthe Athabaskan linguistic literature (see Rice2000). However, like particle- verbcombinations in Dutchand German verb-second clauses, the parts of thisconstituent in the Navajocounterpart are separated in the surface forms ofverbal projections in syntax. In the Navajoversion of thisarrangement, the preverb occupies the leftmost position in the verb word, andthe verb stem occupies the rightmost position. TheNavajo verb in (1) canbe used to illustrate the phenomenon. The verb is segmented intoits various parts in (2), and the components are identified in slightly greater detail in (3). (1) Sila´o t’o´o´’go´o´ ch’´õ shidinõ´daøzh.(Young and Morgan 1987:283) ‘Thepoliceman jerked me outdoors (to get me out of afight).’ (2) ch’´õ sh d n-´ daøzh PreverbObject Qualifier Mode/ SubjVoice V (stem) Iwishto dedicate thisarticle totheNavajo Language Academy, asmall groupof linguists and teachers devotedto Navajolanguage research andeducation. -

Unity and Diversity in Grammaticalization Scenarios
Unity and diversity in grammaticalization scenarios Edited by Walter Bisang Andrej Malchukov language Studies in Diversity Linguistics 16 science press Studies in Diversity Linguistics Chief Editor: Martin Haspelmath In this series: 1. Handschuh, Corinna. A typology of marked-S languages. 2. Rießler, Michael. Adjective attribution. 3. Klamer, Marian (ed.). The Alor-Pantar languages: History and typology. 4. Berghäll, Liisa. A grammar of Mauwake (Papua New Guinea). 5. Wilbur, Joshua. A grammar of Pite Saami. 6. Dahl, Östen. Grammaticalization in the North: Noun phrase morphosyntax in Scandinavian vernaculars. 7. Schackow, Diana. A grammar of Yakkha. 8. Liljegren, Henrik. A grammar of Palula. 9. Shimelman, Aviva. A grammar of Yauyos Quechua. 10. Rudin, Catherine & Bryan James Gordon (eds.). Advances in the study of Siouan languages and linguistics. 11. Kluge, Angela. A grammar of Papuan Malay. 12. Kieviet, Paulus. A grammar of Rapa Nui. 13. Michaud, Alexis. Tone in Yongning Na: Lexical tones and morphotonology. 14. Enfield, N. J (ed.). Dependencies in language: On the causal ontology of linguistic systems. 15. Gutman, Ariel. Attributive constructions in North-Eastern Neo-Aramaic. 16. Bisang, Walter & Andrej Malchukov (eds.). Unity and diversity in grammaticalization scenarios. ISSN: 2363-5568 Unity and diversity in grammaticalization scenarios Edited by Walter Bisang Andrej Malchukov language science press Walter Bisang & Andrej Malchukov (eds.). 2017. Unity and diversity in grammaticalization scenarios (Studies in Diversity Linguistics