Universitat Aut`Onoma De Barcelona Towards Objective Human Brain
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

RNA Expression Patterns in Serum Microvesicles from Patients With
Noerholm et al. BMC Cancer 2012, 12:22 http://www.biomedcentral.com/1471-2407/12/22 RESEARCHARTICLE Open Access RNA expression patterns in serum microvesicles from patients with glioblastoma multiforme and controls Mikkel Noerholm1,2*, Leonora Balaj1, Tobias Limperg1,3, Afshin Salehi1,4, Lin Dan Zhu1, Fred H Hochberg1, Xandra O Breakefield1, Bob S Carter1,4 and Johan Skog1,2 Abstract Background: RNA from exosomes and other microvesicles contain transcripts of tumour origin. In this study we sought to identify biomarkers of glioblastoma multiforme in microvesicle RNA from serum of affected patients. Methods: Microvesicle RNA from serum from patients with de-novo primary glioblastoma multiforme (N = 9) and normal controls (N = 7) were analyzed by microarray analysis. Samples were collected according to protocols approved by the Institutional Review Board. Differential expressions were validated by qRT-PCR in a separate set of samples (N = 10 in both groups). Results: Expression profiles of microvesicle RNA correctly separated individuals in two groups by unsupervised clustering. The most significant differences pertained to down-regulated genes (121 genes > 2-fold down) in the glioblastoma multiforme patient microvesicle RNA, validated by qRT-PCR on several genes. Overall, yields of microvesicle RNA from patients was higher than from normal controls, but the additional RNA was primarily of size < 500 nt. Gene ontology of the down-regulated genes indicated these are coding for ribosomal proteins and genes related to ribosome production. Conclusions: Serum microvesicle RNA from patients with glioblastoma multiforme has significantly down- regulated levels of RNAs coding for ribosome production, compared to normal healthy controls, but a large overabundance of RNA of unknown origin with size < 500 nt. -
Supp Table 1.Pdf
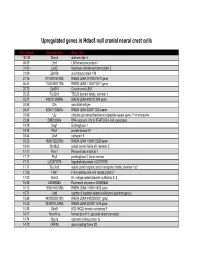
Upregulated genes in Hdac8 null cranial neural crest cells fold change Gene Symbol Gene Title 134.39 Stmn4 stathmin-like 4 46.05 Lhx1 LIM homeobox protein 1 31.45 Lect2 leukocyte cell-derived chemotaxin 2 31.09 Zfp108 zinc finger protein 108 27.74 0710007G10Rik RIKEN cDNA 0710007G10 gene 26.31 1700019O17Rik RIKEN cDNA 1700019O17 gene 25.72 Cyb561 Cytochrome b-561 25.35 Tsc22d1 TSC22 domain family, member 1 25.27 4921513I08Rik RIKEN cDNA 4921513I08 gene 24.58 Ofa oncofetal antigen 24.47 B230112I24Rik RIKEN cDNA B230112I24 gene 23.86 Uty ubiquitously transcribed tetratricopeptide repeat gene, Y chromosome 22.84 D8Ertd268e DNA segment, Chr 8, ERATO Doi 268, expressed 19.78 Dag1 Dystroglycan 1 19.74 Pkn1 protein kinase N1 18.64 Cts8 cathepsin 8 18.23 1500012D20Rik RIKEN cDNA 1500012D20 gene 18.09 Slc43a2 solute carrier family 43, member 2 17.17 Pcm1 Pericentriolar material 1 17.17 Prg2 proteoglycan 2, bone marrow 17.11 LOC671579 hypothetical protein LOC671579 17.11 Slco1a5 solute carrier organic anion transporter family, member 1a5 17.02 Fbxl7 F-box and leucine-rich repeat protein 7 17.02 Kcns2 K+ voltage-gated channel, subfamily S, 2 16.93 AW493845 Expressed sequence AW493845 16.12 1600014K23Rik RIKEN cDNA 1600014K23 gene 15.71 Cst8 cystatin 8 (cystatin-related epididymal spermatogenic) 15.68 4922502D21Rik RIKEN cDNA 4922502D21 gene 15.32 2810011L19Rik RIKEN cDNA 2810011L19 gene 15.08 Btbd9 BTB (POZ) domain containing 9 14.77 Hoxa11os homeo box A11, opposite strand transcript 14.74 Obp1a odorant binding protein Ia 14.72 ORF28 open reading -

A B-Cell Receptor-Related Gene Signature Predicts Survival in Mantle
Published Ahead of Print on February 22, 2018, as doi:10.3324/haematol.2017.184325. Copyright 2018 Ferrata Storti Foundation. A B-cell receptor-related gene signature predicts survival in mantle cell lymphoma: results from the “Fondazione Italiana Linfomi” MCL-0208 trial by Riccardo Bomben, Simone Ferrero, Tiziana D'Agaro, Michele Dal Bo, Alessandro Re, Andrea Evangelista, Angelo Michele Carella, Alberto Zamò, Umberto Vitolo, Paola Omedè, Chiara Rusconi, Luca Arcaini, Luigi Rigacci, Stefano Luminari, Andrea Piccin, Delong Liu, Adrien Wiestner, Gianluca Gaidano, Sergio Cortelazzo, Marco Ladetto, and Valter Gattei Haematologica 2018 [Epub ahead of print] Citation: Riccardo Bomben, Simone Ferrero, Tiziana D'Agaro, Michele Dal Bo, Alessandro Re, Andrea Evangelista, Angelo Michele Carella, Alberto Zamò, Umberto Vitolo, Paola Omedè, Chiara Rusconi, Luca Arcaini, Luigi Rigacci, Stefano Luminari, Andrea Piccin, Delong Liu, Adrien Wiestner, Gianluca Gaidano, Sergio Cortelazzo, Marco Ladetto, and Valter Gattei. A B-cell receptor-related gene signature predicts survival in mantle cell lymphoma: results from the “Fondazione Italiana Linfomi” MCL-0208 trial. Haematologica. 2018; 103:xxx doi:10.3324/haematol.2017.184325 Publisher's Disclaimer. E-publishing ahead of print is increasingly important for the rapid dissemination of science. Haematologica is, therefore, E-publishing PDF files of an early version of manuscripts that have completed a regular peer review and have been accepted for publication. E-publishing of this PDF file has been approved by the authors. After having E-published Ahead of Print, manuscripts will then undergo technical and English editing, typesetting, proof correction and be presented for the authors' final approval; the final version of the manuscript will then appear in print on a regular issue of the journal. -

BMC Genomics Biomed Central
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Springer - Publisher Connector BMC Genomics BioMed Central Research article Open Access Dual activation of pathways regulated by steroid receptors and peptide growth factors in primary prostate cancer revealed by Factor Analysis of microarray data Juan Jose Lozano1,2,5, Marta Soler3, Raquel Bermudo3, David Abia1, Pedro L Fernandez4, Timothy M Thomson*3 and Angel R Ortiz*1,2 Address: 1Bioinformatics Unit, Centro de Biología Molecular "Severo Ochoa" (CSIC-UAM), Universidad Autónoma de Madrid, Cantoblanco, 28049 Madrid, Spain, 2Department of Physiology and Biophysics, Mount Sinai School of Medicine, One Gustave Levy Pl., New York, NY 10029, USA, 3Instituto de Biología Molecular, Consejo Superior de Investigaciones Científicas, c. Jordi Girona 18–26, 08034 Barcelona, Spain, 4Departament de Anatomía Patològica, Hospital Clínic, and Institut de Investigacions Biomèdiques August Pi i Sunyer, c. Villarroel 170, 08036 Barcelona, Spain and 5Center for Genome Regulation, Barcelona (Spain) Email: Juan Jose Lozano - [email protected]; Marta Soler - [email protected]; Raquel Bermudo - [email protected]; David Abia - [email protected]; Pedro L Fernandez - [email protected]; Timothy M Thomson* - [email protected]; Angel R Ortiz* - [email protected] * Corresponding authors Published: 17 August 2005 Received: 17 January 2005 Accepted: 17 August 2005 BMC Genomics 2005, 6:109 doi:10.1186/1471-2164-6-109 This article is available from: http://www.biomedcentral.com/1471-2164/6/109 © 2005 Lozano et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Aneuploidy: Using Genetic Instability to Preserve a Haploid Genome?
Health Science Campus FINAL APPROVAL OF DISSERTATION Doctor of Philosophy in Biomedical Science (Cancer Biology) Aneuploidy: Using genetic instability to preserve a haploid genome? Submitted by: Ramona Ramdath In partial fulfillment of the requirements for the degree of Doctor of Philosophy in Biomedical Science Examination Committee Signature/Date Major Advisor: David Allison, M.D., Ph.D. Academic James Trempe, Ph.D. Advisory Committee: David Giovanucci, Ph.D. Randall Ruch, Ph.D. Ronald Mellgren, Ph.D. Senior Associate Dean College of Graduate Studies Michael S. Bisesi, Ph.D. Date of Defense: April 10, 2009 Aneuploidy: Using genetic instability to preserve a haploid genome? Ramona Ramdath University of Toledo, Health Science Campus 2009 Dedication I dedicate this dissertation to my grandfather who died of lung cancer two years ago, but who always instilled in us the value and importance of education. And to my mom and sister, both of whom have been pillars of support and stimulating conversations. To my sister, Rehanna, especially- I hope this inspires you to achieve all that you want to in life, academically and otherwise. ii Acknowledgements As we go through these academic journeys, there are so many along the way that make an impact not only on our work, but on our lives as well, and I would like to say a heartfelt thank you to all of those people: My Committee members- Dr. James Trempe, Dr. David Giovanucchi, Dr. Ronald Mellgren and Dr. Randall Ruch for their guidance, suggestions, support and confidence in me. My major advisor- Dr. David Allison, for his constructive criticism and positive reinforcement. -

Identifying Lineage Relationships in Human T Cell Populations
Identifying lineage relationships in human T cell populations by Celia Lara Menckeberg A thesis submitted to The University of Birmingham for the degree of DOCTOR OF PHILOSOPHY School of Immunity and Infection College of Medical and Dental Sciences The University of Birmingham December 2010 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ii ABSTRACT CD4+ and CD8+ T cell populations can be divided into subpopulations based on expression of surface markers CCR7 and CD45RA. The resulting populations are referred to as naive, central memory, effector memory and effector memory RA+ (EMRA). The aim of this study was to identify potential lineage relationships between these subpopulations for both CD4+ and CD8+ T cells through microarray analysis. The genes found to distinguish between these subpopulations include many molecules with known functions in T cell differentiation, including CCR7, CD45RA, granzymes, L-selectin and TNF receptors. Several genes from the tetraspanin family of proteins were found to be differentially expressed at mRNA and protein level; suggesting a possible role for these genes in CD4+ and CD8+ T cell activation, migration and lysosomal function. -

View / Download 3.3 Mb
Identification of Mechanisms and Pathways Involved in MLL2-Mediated Tumorigenesis by Chun-Chi Chang Department of Pathology Duke University Date:_______________________ Approved: ___________________________ Yiping He, Supervisor ___________________________ Salvatore Pizzo ___________________________ Hai Yan Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in the Department of Pathology in the Graduate School of Duke University 2013 ABSTRACT Identification of Mechanisms and Pathways Involved in MLL2-Mediated Tumorigenesis by Chun-Chi Chang Department of Pathology Duke University Date:_______________________ Approved: ___________________________ Yiping He, Supervisor ___________________________ Salvatore Pizzo ___________________________ Hai Yan An abstract of a thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in the Department of Pathology in the Graduate School of Duke University 2013 Copyright by Chun-Chi Chang 2013 Abstract Myeloid/lymphoid or mixed-lineage leukemia (MLL)-family genes encode histone lysine methyltransferases that play important roles in epigenetic regulation of gene transcription, and these genes are frequently mutated in human cancers. While MLL1 and MLL4 have been the most extensively studied, MLL2 and its homolog MLL3 are not well-understood. Specifically, little is known regarding the extent of global MLL2 involvement in the regulation of gene expression and the mechanism underlying its alterations in mediating tumorigenesis. To study the role of MLL2 in tumorigenesis, we somatically knocked out MLL2 in a colorectal carcinoma cell line, HCT116. We observed that the MLL2 loss of function results in significant reduction of cell growth and multinuclear morphology. We further profiled MLL2 regulated genes and pathways by analyzing gene expression in MLL2 wild-type versus MLL2-null isogenic cell lines. -

The Genetics of Bipolar Disorder
Molecular Psychiatry (2008) 13, 742–771 & 2008 Nature Publishing Group All rights reserved 1359-4184/08 $30.00 www.nature.com/mp FEATURE REVIEW The genetics of bipolar disorder: genome ‘hot regions,’ genes, new potential candidates and future directions A Serretti and L Mandelli Institute of Psychiatry, University of Bologna, Bologna, Italy Bipolar disorder (BP) is a complex disorder caused by a number of liability genes interacting with the environment. In recent years, a large number of linkage and association studies have been conducted producing an extremely large number of findings often not replicated or partially replicated. Further, results from linkage and association studies are not always easily comparable. Unfortunately, at present a comprehensive coverage of available evidence is still lacking. In the present paper, we summarized results obtained from both linkage and association studies in BP. Further, we indicated new potential interesting genes, located in genome ‘hot regions’ for BP and being expressed in the brain. We reviewed published studies on the subject till December 2007. We precisely localized regions where positive linkage has been found, by the NCBI Map viewer (http://www.ncbi.nlm.nih.gov/mapview/); further, we identified genes located in interesting areas and expressed in the brain, by the Entrez gene, Unigene databases (http://www.ncbi.nlm.nih.gov/entrez/) and Human Protein Reference Database (http://www.hprd.org); these genes could be of interest in future investigations. The review of association studies gave interesting results, as a number of genes seem to be definitively involved in BP, such as SLC6A4, TPH2, DRD4, SLC6A3, DAOA, DTNBP1, NRG1, DISC1 and BDNF. -

Telomerase a Prognostic Marker and Therapeutic Target
Telomerase a prognostic marker and therapeutic target By Dipti S. Thakkar A thesis submitted to the University of Central Lancashire in partial fulfilment of the requirements for the degree of Doctor of Philosophy Month Year submitted: June 2010 1 Declaration I declare that while registered as a candidate for this degree I have not been registered as a candidate for any other award from an academic institution. The work present in this thesis, except where otherwise stated, is based on my own research and has not been submitted previously for any other award in this or any other University. DIPTI THAKKAR Signed 2 Abstract Malignant glioma is the most common and aggressive form of tumours and is usually refractory to therapy. Telomerase and its altered activity, distinguishing cancer cells, is an attractive molecular target in glioma therapeutics. The aim of this thesis was to silence telomerase at the genetic level with a view to highlight the changes caused in the cancer proteome and identify the potential downstream pathways controlled by telomerase in tumour progression and maintenance. A comprehensive proteomic study utilizing 2D-DIGE and MALDI-TOF were used to assess the effect of inhibiting two different regulatory mechanisms of telomerase in glioma. RNAi was used to target hTERT and Hsp90α. Inhibition of telomerase activity resulted in down regulation of various cytoskeletal proteins with correlative evidence of the involvement of telomerase in regulating the expression of vimentin. Vimentin plays an important role in tumour metastasis and is used as an indicator of glioma metastasis. Inhibition of telomerase via sihTERT results in the down regulation of vimentin expression in glioma cell lines in a grade specific manner. -

WO 2013/064702 A2 10 May 2013 (10.05.2013) P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization I International Bureau (10) International Publication Number (43) International Publication Date WO 2013/064702 A2 10 May 2013 (10.05.2013) P O P C T (51) International Patent Classification: AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, C12Q 1/68 (2006.01) BZ, CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, (21) International Application Number: HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KM, KN, KP, PCT/EP2012/071868 KR, KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, (22) International Filing Date: ME, MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, 5 November 20 12 (05 .11.20 12) NO, NZ, OM, PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SC, SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, (25) Filing Language: English TM, TN, TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, (26) Publication Language: English ZM, ZW. (30) Priority Data: (84) Designated States (unless otherwise indicated, for every 1118985.9 3 November 201 1 (03. 11.201 1) GB kind of regional protection available): ARIPO (BW, GH, 13/339,63 1 29 December 201 1 (29. 12.201 1) US GM, KE, LR, LS, MW, MZ, NA, RW, SD, SL, SZ, TZ, UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, RU, TJ, (71) Applicant: DIAGENIC ASA [NO/NO]; Grenseveien 92, TM), European (AL, AT, BE, BG, CH, CY, CZ, DE, DK, N-0663 Oslo (NO). -

Human Social Genomics in the Multi-Ethnic Study of Atherosclerosis
Getting “Under the Skin”: Human Social Genomics in the Multi-Ethnic Study of Atherosclerosis by Kristen Monét Brown A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Epidemiological Science) in the University of Michigan 2017 Doctoral Committee: Professor Ana V. Diez-Roux, Co-Chair, Drexel University Professor Sharon R. Kardia, Co-Chair Professor Bhramar Mukherjee Assistant Professor Belinda Needham Assistant Professor Jennifer A. Smith © Kristen Monét Brown, 2017 [email protected] ORCID iD: 0000-0002-9955-0568 Dedication I dedicate this dissertation to my grandmother, Gertrude Delores Hampton. Nanny, no one wanted to see me become “Dr. Brown” more than you. I know that you are standing over the bannister of heaven smiling and beaming with pride. I love you more than my words could ever fully express. ii Acknowledgements First, I give honor to God, who is the head of my life. Truly, without Him, none of this would be possible. Countless times throughout this doctoral journey I have relied my favorite scripture, “And we know that all things work together for good, to them that love God, to them who are called according to His purpose (Romans 8:28).” Secondly, I acknowledge my parents, James and Marilyn Brown. From an early age, you two instilled in me the value of education and have been my biggest cheerleaders throughout my entire life. I thank you for your unconditional love, encouragement, sacrifices, and support. I would not be here today without you. I truly thank God that out of the all of the people in the world that He could have chosen to be my parents, that He chose the two of you.