Memory Design: System on Chip and Board Based Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 3 Semiconductor Memories
Chapter 3 Semiconductor Memories Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Introduction Random Access Memories Content Addressable Memories Read Only Memories Flash Memories Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 2 Overview of Memory Types Semiconductor Memories Read/Write Memory or Random Access Memory (RAM) Read Only Memory (ROM) Random Access Non-Random Access Memory (RAM) Memory (RAM) •Mask (Fuse) ROM •Programmable ROM (PROM) •Erasable PROM (EPROM) •Static RAM (SRAM) •FIFO/LIFO •Electrically EPROM (EEPROM) •Dynamic RAM (DRAM) •Shift Register •Flash Memory •Register File •Content Addressable •Ferroelectric RAM (FRAM) Memory (CAM) •Magnetic RAM (MRAM) Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 3 Memory Elements – Memory Architecture Memory elements may be divided into the following categories Random access memory Serial access memory Content addressable memory Memory architecture 2m+k bits row decoder row decoder 2n-k words row decoder row decoder column decoder k column mux, n-bit address sense amp, 2m-bit data I/Os write buffers Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 4 1-D Memory Architecture S0 S0 Word0 Word0 S1 S1 Word1 Word1 S2 S2 Word2 Word2 A0 S3 S3 A1 Decoder Ak-1 Sn-2 Storage Sn-2 Wordn-2 element Wordn-2 Sn-1 Sn-1 Wordn-1 Wordn-1 m-bit m-bit Input/Output Input/Output n select signals are reduced n select signals: S0-Sn-1 to k address signals: A0-Ak-1 Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 5 Memory Architecture S0 Word0 Wordi-1 S1 A0 A1 Ak-1 Row Decoder Sn-1 Wordni-1 A 0 Column Decoder Aj-1 Sense Amplifier Read/Write Circuit m-bit Input/Output Advanced Reliable Systems (ARES) Lab. -

Memory & Devices
Memory & Devices Memory • Random Access Memory (vs. Serial Access Memory) • Different flavors at different levels – Physical Makeup (CMOS, DRAM) – Low Level Architectures (FPM,EDO,BEDO,SDRAM, DDR) • Cache uses SRAM: Static Random Access Memory – No refresh (6 transistors/bit vs. 1 transistor • Main Memory is DRAM: Dynamic Random Access Memory – Dynamic since needs to be refreshed periodically (1% time) – Addresses divided into 2 halves (Memory as a 2D matrix): • RAS or Row Access Strobe • CAS or Column Access Strobe Random-Access Memory (RAM) Key features – RAM is packaged as a chip. – Basic storage unit is a cell (one bit per cell). – Multiple RAM chips form a memory. Static RAM (SRAM) – Each cell stores bit with a six-transistor circuit. – Retains value indefinitely, as long as it is kept powered. – Relatively insensitive to disturbances such as electrical noise. – Faster and more expensive than DRAM. Dynamic RAM (DRAM) – Each cell stores bit with a capacitor and transistor. – Value must be refreshed every 10-100 ms. – Sensitive to disturbances. – Slower and cheaper than SRAM. Semiconductor Memory Types Static RAM • Bits stored in transistor “latches” à no capacitors! – no charge leak, no refresh needed • Pro: no refresh circuits, faster • Con: more complex construction, larger per bit more expensive transistors “switch” faster than capacitors charge ! • Cache Static RAM Structure 1 “NOT ” 1 0 six transistors per bit 1 0 (“flip flop”) 0 1 0/1 = example 0 Static RAM Operation • Transistor arrangement (flip flop) has 2 stable logic states • Write 1. signal bit line: High à 1 Low à 0 2. address line active à “switch” flip flop to stable state matching bit line • Read no need 1. -
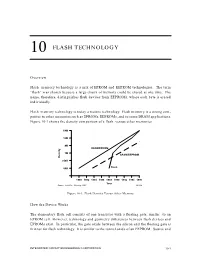
Section 10 Flash Technology
10 FLASH TECHNOLOGY Overview Flash memory technology is a mix of EPROM and EEPROM technologies. The term “flash” was chosen because a large chunk of memory could be erased at one time. The name, therefore, distinguishes flash devices from EEPROMs, where each byte is erased individually. Flash memory technology is today a mature technology. Flash memory is a strong com- petitor to other memories such as EPROMs, EEPROMs, and to some DRAM applications. Figure 10-1 shows the density comparison of a flash versus other memories. 64M 16M 4M DRAM/EPROM 1M SRAM/EEPROM Density 256K Flash 64K 1980 1982 1984 1986 1988 1990 1992 1994 1996 Year Source: Intel/ICE, "Memory 1996" 18613A Figure 10-1. Flash Density Versus Other Memory How the Device Works The elementary flash cell consists of one transistor with a floating gate, similar to an EPROM cell. However, technology and geometry differences between flash devices and EPROMs exist. In particular, the gate oxide between the silicon and the floating gate is thinner for flash technology. It is similar to the tunnel oxide of an EEPROM. Source and INTEGRATED CIRCUIT ENGINEERING CORPORATION 10-1 Flash Technology drain diffusions are also different. Figure 10-2 shows a comparison between a flash cell and an EPROM cell with the same technology complexity. Due to thinner gate oxide, the flash device will be more difficult to process. CMOS Flash Cell CMOS EPROM Cell Mag. 10,000x Mag. 10,000x Flash Memory Cell – Larger transistor – Thinner floating gate – Thinner oxide (100-200Å) Photos by ICE 17561A Figure 10-2. -

Error Detection and Correction Methods for Memories Used in System-On-Chip Designs
International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 – 8958, Volume-8, Issue-2S2, January 2019 Error Detection and Correction Methods for Memories used in System-on-Chip Designs Gunduru Swathi Lakshmi, Neelima K, C. Subhas ABSTRACT— Memory is the basic necessity in any SoC Static Random Access Memory (SRAM): It design. Memories are classified into single port memory and consists of a latch or flipflop to store each bit of multiport memory. Multiport memory has ability to source more memory and it does not required any refresh efficient execution of operation and high speed performance operation. SRAM is mostly used in cache memory when compared to single port. Testing of semiconductor memories is increasing because of high density of current in the and in hand-held devices. It has advantages like chips. Due to increase in embedded on chip memory and memory high speed and low power consumption. It has density, the number of faults grow exponentially. Error detection drawback like complex structure and expensive. works on concept of redundancy where extra bits are added for So, it is not used for high capacity applications. original data to detect the error bits. Error correction is done in Read Only Memory (ROM): It is a non-volatile memory. two forms: one is receiver itself corrects the data and other is It can only access data but cannot modify data. It is of low receiver sends the error bits to sender through feedback. Error detection and correction can be done in two ways. One is Single cost. Some applications of ROM are scanners, ID cards, Fax bit and other is multiple bit. -

Nanotechnology ? Nram (Nano Random Access
International Journal Of Engineering Research and Technology (IJERT) IFET-2014 Conference Proceedings INTERFACE ECE T14 INTRACT – INNOVATE - INSPIRE NANOTECHNOLOGY – NRAM (NANO RANDOM ACCESS MEMORY) RANJITHA. T, SANDHYA. R GOVERNMENT COLLEGE OF TECHNOLOGY, COIMBATORE 13. containing elements, nanotubes, are so small, NRAM technology will Abstract— NRAM (Nano Random Access Memory), is one of achieve very high memory densities: at least 10-100 times our current the important applications of nanotechnology. This paper has best. NRAM will operate electromechanically rather than just been prepared to cull out answers for the following crucial electrically, setting it apart from other memory technologies as a questions: nonvolatile form of memory, meaning data will be retained even What is NRAM? when the power is turned off. The creators of the technology claim it What is the need of it? has the advantages of all the best memory technologies with none of How can it be made possible? the disadvantages, setting it up to be the universal medium for What is the principle and technology involved in NRAM? memory in the future. What are the advantages and features of NRAM? The world is longing for all the things it can use within its TECHNOLOGY palm. As a result nanotechnology is taking its head in the world. Nantero's technology is based on a well-known effect in carbon Much of the electronic gadgets are reduced in size and increased nanotubes where crossed nanotubes on a flat surface can either be in efficiency by the nanotechnology. The memory storage devices touching or slightly separated in the vertical direction (normal to the are somewhat large in size due to the materials used for their substrate) due to Van der Waal's interactions. -

What Is Cloud-Based Backup and Recovery?
White paper Cover Image Pick an image that is accurate and relevant to the content, in a glance, the image should be able to tell the story of the asset 550x450 What is cloud-based backup and recovery? Q120-20057 Executive Summary Companies struggle with the challenges of effective backup and recovery. Small businesses lack dedicated IT resources to achieve and manage a comprehensive data protection platform, and enterprise firms often lack the budget and resources for implementing truly comprehensive data protection. Cloud-based backup and recovery lets companies lower their Cloud-based backup and recovery lets data protection cost or expand their capabilities without raising costs or administrative overhead. Firms of all sizes can companies lower their data protection benefit from cloud-based backup and recovery by eliminating cost or expand their capabilities without on-premises hardware and software infrastructure for data raising costs or administrative overhead.” protection, and simplifying their backup administration, making it something every company should consider. Partial or total cloud backup is a good fit for most companies given not only its cost-effectiveness, but also its utility. Many cloud- based backup vendors offer continuous snapshots of virtual machines, applications, and changed data. Some offer recovery capabilities for business-critical applications such as Microsoft Office 365. Others also offer data management features such as analytics, eDiscovery and regulatory compliance. This report describes the history of cloud-based backup and recovery, its features and capabilities, and recommendations for companies considering a cloud-based data protection solution. What does “backup and recovery” mean? There’s a difference between “backup and recovery” and “disaster recovery.” Backup and recovery refers to automated, regular file storage that enables data recovery and restoration following a loss. -

DDR and DDR2 SDRAM Controller Compiler User Guide
DDR and DDR2 SDRAM Controller Compiler User Guide 101 Innovation Drive Software Version: 9.0 San Jose, CA 95134 Document Date: March 2009 www.altera.com Copyright © 2009 Altera Corporation. All rights reserved. Altera, The Programmable Solutions Company, the stylized Altera logo, specific device designations, and all other words and logos that are identified as trademarks and/or service marks are, unless noted otherwise, the trademarks and service marks of Altera Corporation in the U.S. and other countries. All other product or service names are the property of their respective holders. Altera products are protected under numerous U.S. and foreign patents and pending ap- plications, maskwork rights, and copyrights. Altera warrants performance of its semiconductor products to current specifications in accordance with Altera's standard warranty, but reserves the right to make changes to any products and services at any time without notice. Altera assumes no responsibility or liability arising out of the application or use of any information, product, or service described herein except as expressly agreed to in writing by Altera Corporation. Altera customers are advised to obtain the latest version of device specifications before relying on any published information and before placing orders for products or services. UG-DDRSDRAM-10.0 Contents Chapter 1. About This Compiler Release Information . 1–1 Device Family Support . 1–1 Features . 1–2 General Description . 1–2 Performance and Resource Utilization . 1–4 Installation and Licensing . 1–5 OpenCore Plus Evaluation . 1–6 Chapter 2. Getting Started Design Flow . 2–1 SOPC Builder Design Flow . 2–1 DDR & DDR2 SDRAM Controller Walkthrough . -

AXP Internal 2-Apr-20 1
2-Apr-20 AXP Internal 1 2-Apr-20 AXP Internal 2 2-Apr-20 AXP Internal 3 2-Apr-20 AXP Internal 4 2-Apr-20 AXP Internal 5 2-Apr-20 AXP Internal 6 Class 6 Subject: Computer Science Title of the Book: IT Planet Petabyte Chapter 2: Computer Memory GENERAL INSTRUCTIONS: • Exercises to be written in the book. • Assignment questions to be done in ruled sheets. • You Tube link is for the explanation of Primary and Secondary Memory. YouTube Link: ➢ https://youtu.be/aOgvgHiazQA INTRODUCTION: ➢ Computer can store a large amount of data safely in their memory for future use. ➢ A computer’s memory is measured either in Bits or Bytes. ➢ The memory of a computer is divided into two categories: Primary Memory, Secondary Memory. ➢ There are two types of Primary Memory: ROM and RAM. ➢ Cache Memory is used to store program and instructions that are frequently used. EXPLANATION: Computer Memory: Memory plays a very important role in a computer. It is the basic unit where data and instructions are stored temporarily. Memory usually consists of one or more chips on the mother board, or you can say it consists of electronic components that store instructions waiting to be executed by the processor, data needed by those instructions, and the results of processing the data. Memory Units: Computer memory is measured in bits and bytes. A bit is the smallest unit of information that a computer can process and store. A group of 4 bits is known as nibble, and a group of 8 bits is called byte. -

Embedded DRAM
Embedded DRAM Raviprasad Kuloor Semiconductor Research and Development Centre, Bangalore IBM Systems and Technology Group DRAM Topics Introduction to memory DRAM basics and bitcell array eDRAM operational details (case study) Noise concerns Wordline driver (WLDRV) and level translators (LT) Challenges in eDRAM Understanding Timing diagram – An example References Slide 1 Acknowledgement • John Barth, IBM SRDC for most of the slides content • Madabusi Govindarajan • Subramanian S. Iyer • Many Others Slide 2 Topics Introduction to memory DRAM basics and bitcell array eDRAM operational details (case study) Noise concerns Wordline driver (WLDRV) and level translators (LT) Challenges in eDRAM Understanding Timing diagram – An example Slide 3 Memory Classification revisited Slide 4 Motivation for a memory hierarchy – infinite memory Memory store Processor Infinitely fast Infinitely large Cycles per Instruction Number of processor clock cycles (CPI) = required per instruction CPI[ ∞ cache] Finite memory speed Memory store Processor Finite speed Infinite size CPI = CPI[∞ cache] + FCP Finite cache penalty Locality of reference – spatial and temporal Temporal If you access something now you’ll need it again soon e.g: Loops Spatial If you accessed something you’ll also need its neighbor e.g: Arrays Exploit this to divide memory into hierarchy Hit L2 L1 (Slow) Processor Miss (Fast) Hit Register Cache size impacts cycles-per-instruction Access rate reduces Slower memory is sufficient Cache size impacts cycles-per-instruction For a 5GHz -

MSP430 Flash Memory Characteristics (Rev. B)
Application Report SLAA334B–September 2006–Revised August 2018 MSP430 Flash Memory Characteristics ........................................................................................................................ MSP430 Applications ABSTRACT Flash memory is a widely used, reliable, and flexible nonvolatile memory to store software code and data in a microcontroller. Failing to handle the flash according to data-sheet specifications can result in unreliable operation of the application. This application report explains the physics behind these specifications and also gives recommendations for the correct management of flash memory on MSP430™ microcontrollers (MCUs). All examples are based on the flash memory used in the MSP430F1xx, MSP430F2xx, and MSP430F4xx microcontroller families. Contents 1 Flash Memory ................................................................................................................ 2 2 Simplified Flash Memory Cell .............................................................................................. 2 3 Flash Memory Parameters ................................................................................................. 3 3.1 Data Retention ...................................................................................................... 3 3.2 Flash Endurance.................................................................................................... 5 3.3 Cumulative Program Time......................................................................................... 5 4 -

Solving High-Speed Memory Interface Challenges with Low-Cost Fpgas
SOLVING HIGH-SPEED MEMORY INTERFACE CHALLENGES WITH LOW-COST FPGAS A Lattice Semiconductor White Paper May 2005 Lattice Semiconductor 5555 Northeast Moore Ct. Hillsboro, Oregon 97124 USA Telephone: (503) 268-8000 www.latticesemi.com Introduction Memory devices are ubiquitous in today’s communications systems. As system bandwidths continue to increase into the multi-gigabit range, memory technologies have been optimized for higher density and performance. In turn, memory interfaces for these new technologies pose stiff challenges for designers. Traditionally, memory controllers were embedded in processors or as ASIC macrocells in SoCs. With shorter time-to-market requirements, designers are turning to programmable logic devices such as FPGAs to manage memory interfaces. Until recently, only a few FPGAs supported the building blocks to interface reliably to high-speed, next generation devices, and typically these FPGAs were high-end, expensive devices. However, a new generation of low-cost FPGAs has emerged, providing the building blocks, high-speed FPGA fabric, clock management resources and the I/O structures needed to implement next generation DDR2, QDR2 and RLDRAM memory controllers. Memory Applications Memory devices are an integral part of a variety of systems. However, different applications have different memory requirements. For networking infrastructure applications, the memory devices required are typically high-density, high-performance, high-bandwidth memory devices with a high degree of reliability. In wireless applications, low-power memory is important, especially for handset and mobile devices, while high-performance is important for base-station applications. Broadband access applications typically require memory devices in which there is a fine balance between cost and performance. -

Semiconductor Memories
Semiconductor Memories Prof. MacDonald Types of Memories! l" Volatile Memories –" require power supply to retain information –" dynamic memories l" use charge to store information and require refreshing –" static memories l" use feedback (latch) to store information – no refresh required l" Non-Volatile Memories –" ROM (Mask) –" EEPROM –" FLASH – NAND or NOR –" MRAM Memory Hierarchy! 100pS RF 100’s of bytes L1 1nS SRAM 10’s of Kbytes 10nS L2 100’s of Kbytes SRAM L3 100’s of 100nS DRAM Mbytes 1us Disks / Flash Gbytes Memory Hierarchy! l" Large memories are slow l" Fast memories are small l" Memory hierarchy gives us illusion of large memory space with speed of small memory. –" temporal locality –" spatial locality Register Files ! l" Fastest and most robust memory array l" Largest bit cell size l" Basically an array of large latches l" No sense amps – bits provide full rail data out l" Often multi-ported (i.e. 8 read ports, 2 write ports) l" Often used with ALUs in the CPU as source/destination l" Typically less than 10,000 bits –" 32 32-bit fixed point registers –" 32 60-bit floating point registers SRAM! l" Same process as logic so often combined on one die l" Smaller bit cell than register file – more dense but slower l" Uses sense amp to detect small bit cell output l" Fastest for reads and writes after register file l" Large per bit area costs –" six transistors (single port), eight transistors (dual port) l" L1 and L2 Cache on CPU is always SRAM l" On-chip Buffers – (Ethernet buffer, LCD buffer) l" Typical sizes 16k by 32 Static Memory