Identifying Effective Features and Classifiers for Short Term Rainfall Forecast Using Rough Sets Maximum Frequency Weighted Feature Reduction Technique
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Disability Classification System
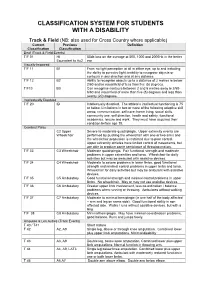
CLASSIFICATION SYSTEM FOR STUDENTS WITH A DISABILITY Track & Field (NB: also used for Cross Country where applicable) Current Previous Definition Classification Classification Deaf (Track & Field Events) T/F 01 HI 55db loss on the average at 500, 1000 and 2000Hz in the better Equivalent to Au2 ear Visually Impaired T/F 11 B1 From no light perception at all in either eye, up to and including the ability to perceive light; inability to recognise objects or contours in any direction and at any distance. T/F 12 B2 Ability to recognise objects up to a distance of 2 metres ie below 2/60 and/or visual field of less than five (5) degrees. T/F13 B3 Can recognise contours between 2 and 6 metres away ie 2/60- 6/60 and visual field of more than five (5) degrees and less than twenty (20) degrees. Intellectually Disabled T/F 20 ID Intellectually disabled. The athlete’s intellectual functioning is 75 or below. Limitations in two or more of the following adaptive skill areas; communication, self-care; home living, social skills, community use, self direction, health and safety, functional academics, leisure and work. They must have acquired their condition before age 18. Cerebral Palsy C2 Upper Severe to moderate quadriplegia. Upper extremity events are Wheelchair performed by pushing the wheelchair with one or two arms and the wheelchair propulsion is restricted due to poor control. Upper extremity athletes have limited control of movements, but are able to produce some semblance of throwing motion. T/F 33 C3 Wheelchair Moderate quadriplegia. Fair functional strength and moderate problems in upper extremities and torso. -

Ifds Functional Classification System & Procedures
IFDS FUNCTIONAL CLASSIFICATION SYSTEM & PROCEDURES MANUAL 2009 - 2012 Effective – 1 January 2009 Originally Published – March 2009 IFDS, C/o ISAF UK Ltd, Ariadne House, Town Quay, Southampton, Hampshire, SO14 2AQ, GREAT BRITAIN Tel. +44 2380 635111 Fax. +44 2380 635789 Email: [email protected] Web: www.sailing.org/disabled 1 Contents Page Introduction 5 Part A – Functional Classification System Rules for Sailors A1 General Overview and Sailor Evaluation 6 A1.1 Purpose 6 A1.2 Sailing Functions 6 A1.3 Ranking of Functional Limitations 6 A1.4 Eligibility for Competition 6 A1.5 Minimum Disability 7 A2 IFDS Class and Status 8 A2.1 Class 8 A2.2 Class Status 8 A2.3 Master List 10 A3 Classification Procedure 10 A3.0 Classification Administration Fee 10 A3.1 Personal Assistive Devices 10 A3.2 Medical Documentation 11 A3.3 Sailors’ Responsibility for Classification Evaluation 11 A3.4 Sailor Presentation for Classification Evaluation 12 A3.5 Method of Assessment 12 A3.6 Deciding the Class 14 A4 Failure to attend/Non Co-operation/Misrepresentation 16 A4.1 Sailor Failure to Attend Evaluation 16 A4.2 Non Co-operation during Evaluation 16 A4.3 International Misrepresentation of Skills and/or Abilities 17 A4.4 Consequences for Sailor Support Personnel 18 A4.5 Consequences for Teams 18 A5 Specific Rules for Boat Classes 18 A5.1 Paralympic Boat Classes 18 A5.2 Non-Paralympic Boat Classes 19 Part B – Protest and Appeals B1 Protest 20 B1.1 General Principles 20 B1.2 Class Status and Protest Opportunities 21 B1.3 Parties who may submit a Classification Protest -

Reducts in Multi-Adjoint Concept Lattices
Reducts in Multi-Adjoint Concept Lattices Maria Eugenia Cornejo1, Jes´usMedina2, and Elo´ısa Ram´ırez-Poussa2 1 Department of Statistic and O.R., University of C´adiz.Spain Email: [email protected] 2 Department of Mathematics, University of C´adiz.Spain Email: fjesus.medina,[email protected] Abstract. Removing redundant information in databases is a key issue in Formal Concept Analysis. This paper introduces several results on the attributes that generate the meet-irreducible elements of a multi-adjoint concept lattice, in order to provide different properties of the reducts in this framework. Moreover, the reducts of particular multi-adjoint concept lattices have been computed in different examples. Keywords: attribute reduction, reduct, multi-adjoint concept lattice 1 Introduction Attribute reduction is an important research topic in Formal Concept Analysis (FCA) [1, 4, 10, 15]. Reducts are the minimal subsets of attributes needed in or- der to compute a lattice isomorphic to the original one, that is, that preserve the whole information of the original database. Hence, the computation of these sets is very interesting. For example, they are useful in order to obtain attribute implications and, since the complexity to build concept lattices directly depend on the number of attributes and objects, if a reduct can be detected before com- puting the whole concept lattice, the complexity will significantly be decreased. Different fuzzy extensions of FCA have been introduced [2, 3, 9, 14]. One of the most general is the multi-adjoint concept lattice framework [11, 12]. Based on a characterization of the meet-irreducible elements of a multi-adjoint concept lattice, a suitable attribute reduction method has recently been presented in [6]. -

Cam Switches
Cam switches 10 Cam operated switches 11 General characteristics 12 Reference system 13 Technical data 14 Dimensions 18 Auxiliary contacts 19 Mounting possibilities 20 Mounting schemes 22 Special mountings 25 Accessories 31 Enclosures 32 Standard electrical schemes 46 Special diagrams 48 Main switches with undervoltage release 50 Discrepancy switches Cam switches Cam operated switches A5 cam operated switches have General characteristics been designed to operate as switch-disconnectors, main • Permits any electrical diagrams oxidation of their ferrous switches, load break switches, and makes the number of components. changeover switches, motor possible diagrams limitless. • High number of mechanical control switches,… • Abrupt breaking mechanism operations. with 30, 45, 60 o 90° positions, • According to RoHS standard. According to Standards according to diagram and requirements. • IEC 60947-3 • Contact decks made of self- • UL 508 extinguishing polyester reinforced with glass fi ber. • Silver alloy low resistance contacts with high arcing and welding characteristics. • Connection with protected cable clamps until 125A. • Electrolytic treatment against 10 low voltage electrical material Serie A5 low voltage electrical material General characteristics Simple "click" front plate fi xing Front plate designed for Internal and easy fi xing by simple push-in on the external links mounting plate Factory assembled links. Insulated external links protect against direct contact on live parts Metalic shaft Marking Optimal mechanical eff ort transmission -

Classified Activities
Federal Accounting Standards Advisory Board CLASSIFIED ACTIVITIES Statement of Federal Financial Accounting Standards Exposure Draft Written comments are requested by March 16, 2018 December 14, 2017 THE FEDERAL ACCOUNTING STANDARDS ADVISORY BOARD The Secretary of the Treasury, the Director of the Office of Management and Budget (OMB), and the Comptroller General of the United States established the Federal Accounting Standards Advisory Board (FASAB or “the Board”) in October 1990. FASAB is responsible for promulgating accounting standards for the United States government. These standards are recognized as generally accepted accounting principles (GAAP) for the federal government. Accounting standards are typically formulated initially as a proposal after considering the financial and budgetary information needs of citizens (including the news media, state and local legislators, analysts from private firms, academe, and elsewhere), Congress, federal executives, federal program managers, and other users of federal financial information. FASAB publishes the proposed standards in an exposure draft for public comment. In some cases, FASAB publishes a discussion memorandum, invitation for comment, or preliminary views document on a specific topic before an exposure draft. A public hearing is sometimes held to receive oral comments in addition to written comments. The Board considers comments and decides whether to adopt the proposed standards with or without modification. After review by the three officials who sponsor FASAB, the Board publishes adopted standards in a Statement of Federal Financial Accounting Standards. The Board follows a similar process for Statements of Federal Financial Accounting Concepts, which guide the Board in developing accounting standards and formulating the framework for federal accounting and reporting. -

Surgical and Non-Surgical Management Strategies for Lateral Epicondylitis
J Orthop Spine Trauma. 2021 March; 7(1): 1-7. DOI: http://dx.doi.org/10.18502/jost.v7i1.5958 Review Article Surgical and Non-Surgical Management Strategies for Lateral Epicondylitis Meisam Jafari Kafiabadi 1, Amir Sabaghzadeh1, Farsad Biglari2, Amin Karami3, Mehrdad Sadighi 1,*, Adel Ebrahimpour4 1 Assistant Professor, Department of Orthopedic Surgery, Shohada Tajrish Hospital, Shahid Beheshti University of Medical Sciences, Tehran, Iran 2 Orthopedic Surgeon, Department of Orthopedic Surgery, Shohada Tajrish Hospital, Shahid Beheshti University of Medical Sciences, Tehran, Iran 3 Resident, Department of Orthopedic Surgery, Shohada Tajrish Hospital, Shahid Beheshti University of Medical Sciences, Tehran, Iran 4 Professor, Department of Orthopedic Surgery, Shohada Tajrish Hospital, Shahid Beheshti University of Medical Sciences, Tehran, Iran *Corresponding author: Mehrdad Sadighi; Department of Orthopedic Surgery, Shohada Tajrish Hospital, Shahid Beheshti University of Medical Sciences, Tehran, Iran. Tel: +98-9125754616, Email: [email protected] Received: 14 September 2020; Revised: 01 December 2020; Accepted: 12 January 2021 Abstract Lateral epicondylitis (LE) is one of the major causes of elbow pain. Despite being a self-limiting condition, its high incidence can cause a significant socioeconomic burden. Many treatment modalities have been proposed for the treatment, but the optimal strategy is still unknown. In this article, we discuss surgical and non-surgical strategies for the treatment of LE and address the research gaps. Keywords: Exercise Therapy; Lateral Epicondylitis; Tennis Elbow; Treatment Citation: Jafari Kafiabadi M, Sabaghzadeh A, Biglari F, Karami A, Sadighi M, Ebrahimpour A. Surgical and Non-Surgical Management Strategies for Lateral Epicondylitis. J Orthop Spine Trauma 2021; 7(1): 1-7. Background I-A. -

Nebraska Highway 12 Niobrara East & West
WWelcomeelcome Nebraska Highway 12 Niobrara East & West Draft Environmental Impact Statement and Section 404 Permit Application Public Open House and Public Hearing PPurposeurpose & NNeedeed What is the purpose of the N-12 project? - Provide a reliable roadway - Safely accommodate current and future traffi c levels - Maintain regional traffi c connectivity Why is the N-12 project needed? - Driven by fl ooding - Unreliable roadway, safety concerns, and interruption in regional traffi c connectivity Photo at top: N-12 with no paved shoulder and narrow lane widths Photo at bottom: Maintenance occurring on N-12 PProjectroject RRolesoles Tribal*/Public NDOR (Applicant) Agencies & County Corps » Provide additional or » Respond to the Corps’ » Provide technical input » Comply with Clean new information requests for information and consultation Water Act » Provide new reasonable » Develop and submit » Make the Section 7(a) » Comply with National alternatives a Section 404 permit decision (National Park Service) Environmental Policy Act application » Question accuracy and » Approvals and reviews » Conduct tribal adequacy of information » Planning, design, and that adhere to federal, consultation construction of Applied- state, or local laws and » Coordinate with NDOR, for Project requirements agencies, and public » Implementation of » Make a decision mitigation on NDOR’s permit application * Conducted through government-to-government consultation. AApplied-forpplied-for PProjectroject (Alternative A7 - Base of Bluff s Elevated Alignment) Attribute -
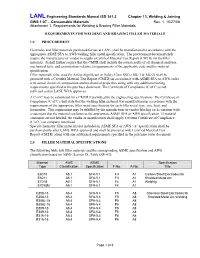
Requirements for Welding and Brazing Filler Materials
LANL Engineering Standards Manual ISD 341-2 Chapter 13, Welding & Joining GWS 1-07 – Consumable Materials Rev. 1, 10/27/06 Attachment 1, Requirements for Welding & Brazing Filler Materials REQUIREMENTS FOR WELDING AND BRAZING FILLER MATERIALS 1.0 PROCUREMENT Electrodes and filler materials purchased for use at LANL shall be manufactured in accordance with the appropriate ASME SFA or AWS welding filler metal specification. The procurement document shall require the manufacturer or vendor to supply a Certified Material Test Report (CMTR) for the filler materials. It shall further require that the CMTR shall include the actual results of all chemical analyses, mechanical tests, and examinations relative to requirements of the applicable code and the material specification. Filler materials to be used for Safety Significant or Safety Class SSCs (ML-1 & ML-2) shall be procured with a Certified Material Test Report (CMTR) in accordance with ASME SFA or AWS codes with actual chemical composition and mechanical properties along with any additional testing requirements specified in the purchase document. The Certificate of Compliance (C of C) is not sufficient unless LANL WPA approves. A C of C may be substituted for a CMTR if permitted by the engineering specification. The Certificate of Compliance (C of C) shall state that the welding filler material was manufactured in accordance with the requirements of the appropriate filler metal specification for each filler metal type, size, heat, and lot number. This requirement may be fulfilled by the manufacturer or vendor labeling each container with a statement that the material conforms to the appropriate ASME SFA or AWS specification. -

At Least Seven Distinct Rotavirus Genotype Constellations in Bats with Evidence Of
bioRxiv preprint doi: https://doi.org/10.1101/2020.08.13.250464; this version posted October 26, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 At least seven distinct rotavirus genotype constellations in bats with evidence of 2 reassortment and zoonotic transmissions 3 4 Ceren Simseka; Victor Max Cormanb,o; Hermann Ulrich Everlingc; Alexander N. 5 Lukashevd; Andrea Rascheb,o; Gael Darren Magangae,f; Tabea Bingeri; Daan Jansena; 6 Leen Bellera; Ward Debouttea; Florian Gloza-Rauschg; Antje Seebens-Hoyerg; Stoian 7 Yordanovh; Augustina Sylverkeni,j; Samuel Oppongj; Yaw Adu Sarkodiej; Peter Vallok; 8 Eric M. Leroyl; Mathieu Bourgarelm,n,; Kwe Claude Yindaa*; Marc Van Ransta; Christian 9 Drostenb,o; Jan Felix Drexlerb,o; Jelle Matthijnssensa 10 11 a KU Leuven - University of Leuven, Department of Microbiology, Immunology and 12 Transplantation, Rega Institute for Medical Research, Leuven, Belgium 13 b Charité-Universitätsmedizin Berlin, corporate member 14 of Freie Universität Berlin, Humbolt-Universität zu Berlin and Berlin Institute of Health, 15 Institute of Virology, 10117 Berlin, Germany 16 c Institute of Virology, University of Bonn Medical Centre, Bonn, Germany 17 d Sechenov University, Moscow, Russia 18 e Centre International de Recherches Médicales de Franceville, Franceville, Gabon 19 f Université des Sciences et Technique de Masuku, Institut National d’Agronomie et de 20 Biotechnologies, Franceville, Gabon 21 g Noctalis, Centre for Bat Protection and Information, Bad Segeberg, Germany 22 h Forestry Board Directorate of Strandja Natural Park, Malko Tarnovo, Bulgaria 23 i Kumasi Centre for Collaborative Research in Tropical Medicine (KCCR), Kumasi, 24 Ghana 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.08.13.250464; this version posted October 26, 2020. -

Document Owner Suela Kodra Data Classification Confidential
Document Classification: Public Statement of Applicability, Version 2.0, 4 May 2021 Legend for Reasons for Controls Selection LR: Legal Requirements,CO: Contractual Obligations,BR/BP: Business Requirements/Adopted Best Practices,RRA: Results of Risk Assessment Section Information security control Reference Applicable A5 Information security policies A5.1 Management direction for information security Information_Security_Policy; ISMS Yes A5.1.1 Policies for information security Manual; Security Concept A5.1.2 Review of the policies for information security Document_and_Policy Management Yes A6 Organization of information security A6.1 Internal organization ISMS Manual; Information_Security_Policy; Job Yes A6.1.1 Information security roles and responsibilities descriptions ISMS Manual; Information_Security_Policy; Yes A6.1.2 Segregation of duties Access_Control_Policy Computer_Security_Incident_Respon Yes A6.1.3 Contact with authorities se_Plan (Annex II) Computer_Security_Incident_Respon Yes A6.1.4 Contact with special interest groups se_Plan (Annex II) Information Security Risk Management Policy; Software Yes A6.1.5 Information security in project management Development Process A6.2 Mobile devices and teleworking A6.2.1 Mobile device policy Mobile_Device_Policy Yes A6.2.2 Teleworking Teleworking_Policy Yes A7 Human resource security A7.1 Prior to employment A7.1.1 Screening On_Off Boarding Checkliste Yes A7.1.2 Terms and conditions of employment Safety io Arbeitsvertrag_AT Yes A7.2 During employment Information_Security_Policy; ISMS Yes -

Temporary Assignment in Higher Classification
Commonwealth of Pennsylvania Governor's Office Subject: Number: Temporary Assignment in Higher 525.4 Amended Classification Date: By Direction of: May 3, 2013 Kelly Powell Logan, Secretary of Administration Contact Agency: Office of Administration, Office for Human Resources Management, Bureau of Classification and Compensation, Telephone 717.787.8838 This directive establishes policy, responsibilities, and procedures for controlling the use of temporary assignments in higher classifications and for processing payments to compensate employees who receive such assignments. Marginal dots are excluded due to major changes. 1. PURPOSE. To establish policy, responsibilities, and procedures for controlling the use of temporary assignments in higher classifications. 2. SCOPE. This directive applies to all employees in departments, boards, commissions, and councils (hereinafter referred to as “agencies”) under the Governor's jurisdiction temporarily assigned to the work of a position in a higher classification. 3. OBJECTIVES. a. Provide policy for the assignment of employees to temporarily work in a higher classification. b. Set forth eligibility criteria for receiving out-of-classification pay. c. Promulgate out-of-classification pay rules. d. Authorize the pay for employees temporarily working in a higher classification. Management Directive 525.4 Amended Page 1 of 8 4. DEFINITIONS. a. Employees' Regular Biweekly Salary/Hourly Rate. The biweekly salary/hourly rate the employee earns in his/her regular classification/position. b. Full day. Seven and one-half or eight hour day. Note that this may be any continuous seven and one-half or eight hour period including both hours within or outside of an employee’s regularly scheduled workday, or any combination thereof. -

US SAILING FUNCTIONAL CLASSIFICATION SYSTEM & PROCEDURES MANUAL 2013—2016 Effective—1 January 2013
[Type text ] [Type text ] [Type text ] US SAILING FUNCTIONAL CLASSIFICATION SYSTEM & PROCEDURES MANUAL 2013—2016 Effective—1 January 2013 Originally Published—May 2013 US Sailing Member of the PO Box 1260 15 Maritime Drive Portsmouth, RI 02871-0907 Phone: 1-401-683-0800 / Toll free: 1-800-USSAIL - (1-800-877-2451) Fax: 401-683-0840 E-Mail: [email protected] International Paralympic Committee Roger H S trube, MD – A pril 20 13 1 ROGE R H STRUBE, MD – APRIL 2013 [Type text ] [Type text ] [Type text ] Contents Introduction .................................................................................................................................................... 6 Appendix to Introduction – Glossary of Medical Terminology .......................................................................... 7 Joint Movement Definitions: ........................................................................................................................... 7 Neck ........................................................................................................................................................ 7 Shoulder .................................................................................................................................................. 7 Elbow ...................................................................................................................................................... 7 Wrist ......................................................................................................................................................