CHAPTER 6. Clusdm Properties
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
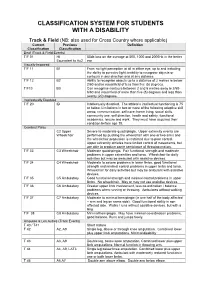
Disability Classification System
CLASSIFICATION SYSTEM FOR STUDENTS WITH A DISABILITY Track & Field (NB: also used for Cross Country where applicable) Current Previous Definition Classification Classification Deaf (Track & Field Events) T/F 01 HI 55db loss on the average at 500, 1000 and 2000Hz in the better Equivalent to Au2 ear Visually Impaired T/F 11 B1 From no light perception at all in either eye, up to and including the ability to perceive light; inability to recognise objects or contours in any direction and at any distance. T/F 12 B2 Ability to recognise objects up to a distance of 2 metres ie below 2/60 and/or visual field of less than five (5) degrees. T/F13 B3 Can recognise contours between 2 and 6 metres away ie 2/60- 6/60 and visual field of more than five (5) degrees and less than twenty (20) degrees. Intellectually Disabled T/F 20 ID Intellectually disabled. The athlete’s intellectual functioning is 75 or below. Limitations in two or more of the following adaptive skill areas; communication, self-care; home living, social skills, community use, self direction, health and safety, functional academics, leisure and work. They must have acquired their condition before age 18. Cerebral Palsy C2 Upper Severe to moderate quadriplegia. Upper extremity events are Wheelchair performed by pushing the wheelchair with one or two arms and the wheelchair propulsion is restricted due to poor control. Upper extremity athletes have limited control of movements, but are able to produce some semblance of throwing motion. T/F 33 C3 Wheelchair Moderate quadriplegia. Fair functional strength and moderate problems in upper extremities and torso. -

Ifds Functional Classification System & Procedures
IFDS FUNCTIONAL CLASSIFICATION SYSTEM & PROCEDURES MANUAL 2009 - 2012 Effective – 1 January 2009 Originally Published – March 2009 IFDS, C/o ISAF UK Ltd, Ariadne House, Town Quay, Southampton, Hampshire, SO14 2AQ, GREAT BRITAIN Tel. +44 2380 635111 Fax. +44 2380 635789 Email: [email protected] Web: www.sailing.org/disabled 1 Contents Page Introduction 5 Part A – Functional Classification System Rules for Sailors A1 General Overview and Sailor Evaluation 6 A1.1 Purpose 6 A1.2 Sailing Functions 6 A1.3 Ranking of Functional Limitations 6 A1.4 Eligibility for Competition 6 A1.5 Minimum Disability 7 A2 IFDS Class and Status 8 A2.1 Class 8 A2.2 Class Status 8 A2.3 Master List 10 A3 Classification Procedure 10 A3.0 Classification Administration Fee 10 A3.1 Personal Assistive Devices 10 A3.2 Medical Documentation 11 A3.3 Sailors’ Responsibility for Classification Evaluation 11 A3.4 Sailor Presentation for Classification Evaluation 12 A3.5 Method of Assessment 12 A3.6 Deciding the Class 14 A4 Failure to attend/Non Co-operation/Misrepresentation 16 A4.1 Sailor Failure to Attend Evaluation 16 A4.2 Non Co-operation during Evaluation 16 A4.3 International Misrepresentation of Skills and/or Abilities 17 A4.4 Consequences for Sailor Support Personnel 18 A4.5 Consequences for Teams 18 A5 Specific Rules for Boat Classes 18 A5.1 Paralympic Boat Classes 18 A5.2 Non-Paralympic Boat Classes 19 Part B – Protest and Appeals B1 Protest 20 B1.1 General Principles 20 B1.2 Class Status and Protest Opportunities 21 B1.3 Parties who may submit a Classification Protest -

Reducts in Multi-Adjoint Concept Lattices
Reducts in Multi-Adjoint Concept Lattices Maria Eugenia Cornejo1, Jes´usMedina2, and Elo´ısa Ram´ırez-Poussa2 1 Department of Statistic and O.R., University of C´adiz.Spain Email: [email protected] 2 Department of Mathematics, University of C´adiz.Spain Email: fjesus.medina,[email protected] Abstract. Removing redundant information in databases is a key issue in Formal Concept Analysis. This paper introduces several results on the attributes that generate the meet-irreducible elements of a multi-adjoint concept lattice, in order to provide different properties of the reducts in this framework. Moreover, the reducts of particular multi-adjoint concept lattices have been computed in different examples. Keywords: attribute reduction, reduct, multi-adjoint concept lattice 1 Introduction Attribute reduction is an important research topic in Formal Concept Analysis (FCA) [1, 4, 10, 15]. Reducts are the minimal subsets of attributes needed in or- der to compute a lattice isomorphic to the original one, that is, that preserve the whole information of the original database. Hence, the computation of these sets is very interesting. For example, they are useful in order to obtain attribute implications and, since the complexity to build concept lattices directly depend on the number of attributes and objects, if a reduct can be detected before com- puting the whole concept lattice, the complexity will significantly be decreased. Different fuzzy extensions of FCA have been introduced [2, 3, 9, 14]. One of the most general is the multi-adjoint concept lattice framework [11, 12]. Based on a characterization of the meet-irreducible elements of a multi-adjoint concept lattice, a suitable attribute reduction method has recently been presented in [6]. -

Recursive Syntactic Pattern Learning by Songbirds
Recursive syntactic pattern learning by songbirds Timothy Q. Gentner, Kimberly M. Fenn, Daniel Margoliash, and Howard C. Nusbaum Supplementary Information Table S1 provides an overview of all the training and testing conditions. Condition Stimulus 1 Baseline Training A2B2 and (AB)2, n=2 2 Transfer 1 Novel A2B2 and (AB)2, n=2 3 Probe Test 1 Familiar A2B2 and (AB)2, n=2 (80% of trials) Novel A2B2 and (AB)2, n=2 (10% of trials) Agrammatical AAAA, BBBB, ABBA, BAAB (10% of trials) 4 Probe Test 2 Familiar A2B2 and (AB)2, n=2 (80% of trials) Novel AnBn and (AB)n, n=3, 4 (20% of trials) 5 Probe Test 3 Familiar A2B2 and (AB)2, n=2 (80% of trials) A*B* (10% of trials) Novel AnBn and (AB)n, n=2,3,4 (10% of trials) Table S1. Overview of the training and testing conditions in order to which subjects were exposed. Stimuli marked with (*) comprised speech syllables instead of starling song motifs. Probe tests with novel A2B2 and (AB)2 stimuli Because the novel transfer stimuli were reinforced with the same response contingencies used in the initial training, the animals’ behaviour was changing (i.e. they were learning) as we measured generalization. To examine generalization without contingent reinforcement and thus without additional learning, we tested subjects using a “probe” procedure. The reinforcement regimen during probe sessions allowed us to measure generalization from the classes defined by the familiar CFG and FSG stimuli to novel stimuli without any direct effects of differential reinforcement learning on the latter (see Additional Methods). -

Classified Activities
Federal Accounting Standards Advisory Board CLASSIFIED ACTIVITIES Statement of Federal Financial Accounting Standards Exposure Draft Written comments are requested by March 16, 2018 December 14, 2017 THE FEDERAL ACCOUNTING STANDARDS ADVISORY BOARD The Secretary of the Treasury, the Director of the Office of Management and Budget (OMB), and the Comptroller General of the United States established the Federal Accounting Standards Advisory Board (FASAB or “the Board”) in October 1990. FASAB is responsible for promulgating accounting standards for the United States government. These standards are recognized as generally accepted accounting principles (GAAP) for the federal government. Accounting standards are typically formulated initially as a proposal after considering the financial and budgetary information needs of citizens (including the news media, state and local legislators, analysts from private firms, academe, and elsewhere), Congress, federal executives, federal program managers, and other users of federal financial information. FASAB publishes the proposed standards in an exposure draft for public comment. In some cases, FASAB publishes a discussion memorandum, invitation for comment, or preliminary views document on a specific topic before an exposure draft. A public hearing is sometimes held to receive oral comments in addition to written comments. The Board considers comments and decides whether to adopt the proposed standards with or without modification. After review by the three officials who sponsor FASAB, the Board publishes adopted standards in a Statement of Federal Financial Accounting Standards. The Board follows a similar process for Statements of Federal Financial Accounting Concepts, which guide the Board in developing accounting standards and formulating the framework for federal accounting and reporting. -

The Prescribed Diseases
Industrial Injuries Benefit Handbook 2 for Healthcare Professionals The Prescribed Diseases MED-IIBHB~002 7th November 2016 INDUSTRIAL INJURIES BENEFIT HANDBOOK 2 FOR HEALTHCARE PROFESSIONALS THE PRESCRIBED DISEASES Foreword This handbook has been produced as part of a training programme for Healthcare Professionals (HCPs) who conduct assessments for the Centre for Health and Disability Assessments on behalf of the Department for Work and Pensions. All HCPs undertaking assessments must be registered practitioners who in addition, have undergone training in disability assessment medicine and specific training in the relevant benefit areas. The training includes theory training in a classroom setting, supervised practical training, and a demonstration of understanding as assessed by quality audit. This handbook must be read with the understanding that, as experienced practitioners, the HCPs will have detailed knowledge of the principles and practice of relevant diagnostic techniques and therefore such information is not contained in this training module. In addition, the handbook is not a stand-alone document, and forms only a part of the training and written documentation that the HCP receives. As disability assessment is a practical occupation, much of the guidance also involves verbal information and coaching. Thus, although the handbook may be of interest to non-medical readers, it must be remembered that some of the information may not be readily understood without background medical knowledge and an awareness of the other training -

GAMES OFFICIALS' GUIDE Equestrian
GAMES OFFICIALS' GUIDE Equestrian July 2021 © The Tokyo Organising Committee of the Olympic and Paralympic Games 21SPT1599000 About this Games Officials’ Guide Published in July 2021, the series of Games Officials’ Guides offer a summary of competition-related material about each sport at the Tokyo 2020 Paralympic Games and provide a variety of information aimed at helping International Federations and their technical officials and classifiers plan and prepare for the Games. All information provided in this Games Officials’ Guide was correct at the time of publication, but some details may change prior to the Games so stakeholders are urged to regularly check with Tokyo 2020 IF Services department and the respective Tokyo 2020 competition management teams for the latest updates. Regarding COVID-19 protocols, updated versions of 'The Playbook International Federations' will be attached to the Games Officials' Guides, and sport-specific COVID-19 countermeasures approved by International Federations and Tokyo 2020 competition management will be made available. The Games Officials’ Guides are designed for internal operational use by Tokyo 2020 stakeholders and should not be publicly shared. Equestrian - Games Officials’ Guide 02 WELCOME On behalf of the Tokyo Organising Committee of the Olympic and Paralympic Games, I am delighted to present the Equestrian Games Officials’ Guide for the Tokyo 2020 Paralympic Games. We have been working diligently to provide facilities, services and procedures which will allow everyone involved in the Games to safely achieve all three of Tokyo 2020’s core concepts: achieving personals bests, unity in diversity, and connecting to tomorrow. Included is information about: • processes relating to competition • key dates and personnel • competition format and rules • venue facilities and services, including maps • information about COVID-19 protocols, heat countermeasures, accreditation, accommodation, Games- time medical services, etc. -

Materials and Welding
Rules for Materials and Welding Part 2 July 2021 RULES FOR MATERIALS AND WELDING JULY 2021 PART 2 American Bureau of Shipping Incorporated by Act of Legislature of the State of New York 1862 © 2021 American Bureau of Shipping. All rights reserved. ABS Plaza 1701 City Plaza Drive Spring, TX 77389 USA PART 2 Foreword (1 July 2021) For the 1996 edition, the “Rules for Building and Classing Steel Vessels – Part 2: Materials and Welding” was re-titled “Rule Requirements for Materials and Welding (Part 2).” The purpose of this generic title was to emphasize the common applicability of the material and welding requirements in “Part 2” to ABS classed vessels, other marine structures and their associated machinery, and thereby make “Part 2” more readily a common “Part” of the various ABS Rules and Guides, as appropriate. Accordingly, the subject booklet, Rules for Materials and Welding (Part 2), is to be considered, for example, as being applicable and comprising a “Part” of the following ABS Rules and Guides: ● Rules for Building and Classing Marine Vessels ● Rules for Building and Classing Steel Vessels for Service on Rivers and Intracoastal Waterways ● Rules for Building and Classing Mobile Offshore Units ● Rules for Building and Classing Steel Barges ● Rules for Building and Classing High-Speed Craft ● Rules for Building and Classing Floating Production Installations ● Rules for Building and Classing Light Warships, Patrol and High-Speed Naval Vessels ● Guide for Building and Classing Liftboats ● Guide for Building and Classing International Naval Ships ● Guide for Building and Classing Yachts In the 2002 edition, Section 4, “Piping” was added to Part 2, Chapter 4, “Welding and Fabrication”. -

Nebraska Highway 12 Niobrara East & West
WWelcomeelcome Nebraska Highway 12 Niobrara East & West Draft Environmental Impact Statement and Section 404 Permit Application Public Open House and Public Hearing PPurposeurpose & NNeedeed What is the purpose of the N-12 project? - Provide a reliable roadway - Safely accommodate current and future traffi c levels - Maintain regional traffi c connectivity Why is the N-12 project needed? - Driven by fl ooding - Unreliable roadway, safety concerns, and interruption in regional traffi c connectivity Photo at top: N-12 with no paved shoulder and narrow lane widths Photo at bottom: Maintenance occurring on N-12 PProjectroject RRolesoles Tribal*/Public NDOR (Applicant) Agencies & County Corps » Provide additional or » Respond to the Corps’ » Provide technical input » Comply with Clean new information requests for information and consultation Water Act » Provide new reasonable » Develop and submit » Make the Section 7(a) » Comply with National alternatives a Section 404 permit decision (National Park Service) Environmental Policy Act application » Question accuracy and » Approvals and reviews » Conduct tribal adequacy of information » Planning, design, and that adhere to federal, consultation construction of Applied- state, or local laws and » Coordinate with NDOR, for Project requirements agencies, and public » Implementation of » Make a decision mitigation on NDOR’s permit application * Conducted through government-to-government consultation. AApplied-forpplied-for PProjectroject (Alternative A7 - Base of Bluff s Elevated Alignment) Attribute -
Requirements for Welding and Brazing Filler Materials
LANL Engineering Standards Manual ISD 341-2 Chapter 13, Welding & Joining GWS 1-07 – Consumable Materials Rev. 1, 10/27/06 Attachment 1, Requirements for Welding & Brazing Filler Materials REQUIREMENTS FOR WELDING AND BRAZING FILLER MATERIALS 1.0 PROCUREMENT Electrodes and filler materials purchased for use at LANL shall be manufactured in accordance with the appropriate ASME SFA or AWS welding filler metal specification. The procurement document shall require the manufacturer or vendor to supply a Certified Material Test Report (CMTR) for the filler materials. It shall further require that the CMTR shall include the actual results of all chemical analyses, mechanical tests, and examinations relative to requirements of the applicable code and the material specification. Filler materials to be used for Safety Significant or Safety Class SSCs (ML-1 & ML-2) shall be procured with a Certified Material Test Report (CMTR) in accordance with ASME SFA or AWS codes with actual chemical composition and mechanical properties along with any additional testing requirements specified in the purchase document. The Certificate of Compliance (C of C) is not sufficient unless LANL WPA approves. A C of C may be substituted for a CMTR if permitted by the engineering specification. The Certificate of Compliance (C of C) shall state that the welding filler material was manufactured in accordance with the requirements of the appropriate filler metal specification for each filler metal type, size, heat, and lot number. This requirement may be fulfilled by the manufacturer or vendor labeling each container with a statement that the material conforms to the appropriate ASME SFA or AWS specification. -

Local Law 152 of 2016: Inspections of Exposed Gas Piping Faqs
September 2020 FREQUENTLY ASKED QUESTIONS LocalJune Law2010 152 of 2016: Inspections of Exposed Gas Piping INSPECTIONS GENERALLY Q1. This inspection is a point in time inspection of a gas system. Assuming the inspection was conducted properly, at what point does the inspector’s liability end? A1. The licensee is responsible for the work performed and the accuracy of any forms completed and submitted to the owner and the Department. Q2. Is it required to prove the legality of an existing gas installation? A2. While the licensee is not required to prove legality of an existing gas installation, the licensee is responsible for identifying illegal connections or any non-Code compliant conditions. Q3. Does the inspection requirement include commercial spaces? A3. The inspection requirement applies to all buildings other than R-3 (ex. 1 & 2 family). The law outlines the scope of the inspection, starting at the point of entry into the building and up to, but not including tenant space. Tenant spaces are not included in the scope, regardless of their occupancy classification. Q4. If there is a boiler room or mechanical room in a tenant space, is it exempt from the inspection and leak survey? A4. Yes, if there is a boiler room or mechanical room in a tenant space, it is exempt from the inspection and leak survey. Q5. Are there any circumstances under which an appliance within any tenant space will be subject to an inspection or survey? A5. No. Appliances within tenant spaces are not subject to an inspection or survey. Q6. What actions must the plumber take if access is not available to all required areas containing the exposed gas piping for the visual inspection or if access is not provided to public spaces, hallways, corridors, and mechanical and boiler rooms for the leak survey? A6. -

Repetitive Strain Injury (RSI) Is the More Commonly Known Term for a Set of Disorders Called Work Related Upper Limb Disorders Or WRULDS
Repetitive Strain Injury Updated April 2010 WHAT IS REPETITIVE STRAIN INJURY? Repetitive Strain Injury (RSI) is the more commonly known term for a set of disorders called Work Related Upper Limb Disorders or WRULDS. It is a serious condition that according to the Health and Safety Executive (HSE) affects up to 500,000 workers each year - with 81,000 new cases in 2007/08 alone. RSI covers a wide range of injuries to muscles, tendons and nerves. Usually hands, wrists, elbows or shoulders are affected but knees and feet can also suffer; especially if a job involves a lot of kneeling or operating foot pedals on equipment. RSI’s must be treated at an early stage or a permanent disability could be caused. There are many different names for RSI injuries, including: Tenosynovitis Carpel tunnel syndrome Tendinitis Dupuytren’s contracture Epicondylitis or ‘tennis elbow’ Bursitis ‘Housemaid’s knee’ or ‘beat conditions’ Overuse injury WHAT CAUSES RSI? RSI is caused, or made worse, by continuous repetitive or pressurised finger, hand or arm movements, twisting movements, squeezing, hammering and pounding, pushing, pulling, lifting or reaching movements, too fast or excessive workloads, long hours, lack of variety or breaks, overuse, awkward grips or positions, using too much force, badly designed equipment and/or poor working environments (including low temperatures and stress). WHO IS AT RISK? Although many of the cases dealt with by UNISON involve keyboard workers, such as secretaries and administrative staff who use computers or other electronic equipment, nearly all work carries some risk. It has also been linked to the use of vibrating equipment.