Advanced Microprocessors 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Computer Organization
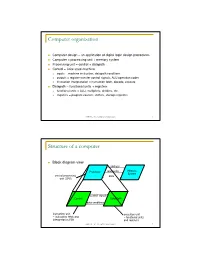
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Soft Machines Targets Ipcbottleneck
SOFT MACHINES TARGETS IPC BOTTLENECK New CPU Approach Boosts Performance Using Virtual Cores By Linley Gwennap (October 27, 2014) ................................................................................................................... Coming out of stealth mode at last week’s Linley Pro- president/CTO Mohammad Abdallah. Investors include cessor Conference, Soft Machines disclosed a new CPU AMD, GlobalFoundries, and Samsung as well as govern- technology that greatly improves performance on single- ment investment funds from Abu Dhabi (Mubdala), Russia threaded applications. The new VISC technology can con- (Rusnano and RVC), and Saudi Arabia (KACST and vert a single software thread into multiple virtual threads, Taqnia). Its board of directors is chaired by Global Foun- which it can then divide across multiple physical cores. dries CEO Sanjay Jha and includes legendary entrepreneur This conversion happens inside the processor hardware Gordon Campbell. and is thus invisible to the application and the software Soft Machines hopes to license the VISC technology developer. Although this capability may seem impossible, to other CPU-design companies, which could add it to Soft Machines has demonstrated its performance advan- their existing CPU cores. Because its fundamental benefit tage using a test chip that implements a VISC design. is better IPC, VISC could aid a range of applications from Without VISC, the only practical way to improve single-thread performance is to increase the parallelism Application (sequential code) (instructions per cycle, or IPC) of the CPU microarchi- Single Thread tecture. Taken to the extreme, this approach results in massive designs such as Intel’s Haswell and IBM’s Power8 OS and Hypervisor that deliver industry-leading performance but waste power Standard ISA and die area. -

Class-Action Lawsuit
Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 1 of 279 Steve D. Larson, OSB No. 863540 Email: [email protected] Jennifer S. Wagner, OSB No. 024470 Email: [email protected] STOLL STOLL BERNE LOKTING & SHLACHTER P.C. 209 SW Oak Street, Suite 500 Portland, Oregon 97204 Telephone: (503) 227-1600 Attorneys for Plaintiffs [Additional Counsel Listed on Signature Page.] UNITED STATES DISTRICT COURT DISTRICT OF OREGON PORTLAND DIVISION BLUE PEAK HOSTING, LLC, PAMELA Case No. GREEN, TITI RICAFORT, MARGARITE SIMPSON, and MICHAEL NELSON, on behalf of CLASS ACTION ALLEGATION themselves and all others similarly situated, COMPLAINT Plaintiffs, DEMAND FOR JURY TRIAL v. INTEL CORPORATION, a Delaware corporation, Defendant. CLASS ACTION ALLEGATION COMPLAINT Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 2 of 279 Plaintiffs Blue Peak Hosting, LLC, Pamela Green, Titi Ricafort, Margarite Sampson, and Michael Nelson, individually and on behalf of the members of the Class defined below, allege the following against Defendant Intel Corporation (“Intel” or “the Company”), based upon personal knowledge with respect to themselves and on information and belief derived from, among other things, the investigation of counsel and review of public documents as to all other matters. INTRODUCTION 1. Despite Intel’s intentional concealment of specific design choices that it long knew rendered its central processing units (“CPUs” or “processors”) unsecure, it was only in January 2018 that it was first revealed to the public that Intel’s CPUs have significant security vulnerabilities that gave unauthorized program instructions access to protected data. 2. A CPU is the “brain” in every computer and mobile device and processes all of the essential applications, including the handling of confidential information such as passwords and encryption keys. -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

Professor Won Woo Ro, School of Electrical and Electronic Engineering Yonsei University the Intel® 4004 Microprocessor, Introdu
Professor Won Woo Ro, School of Electrical and Electronic Engineering Yonsei University The 1st Microprocessor The Intel® 4004 microprocessor, introduced in November 1971 An electronics revolution that changed our world. There were no customer‐ programmable microprocessors on the market before the 4004. It propelled software into the limelight as a key player in the world of digital electronics design. 4004 Microprocessor Display at New Intel Museum A Japanese calculator maker (Busicom) asked to design: A set of 12 custom logic chips for a line of programmable calculators. Marcian E. "Ted" Hoff Recognized the integrated circuit technology (of the day) had advanced enough to build a single chip, general purpose computer. Federico Faggin to turn Hoff's vision into a silicon reality. (In less than one year, Faggin and his team delivered the 4004, which was introduced in November, 1971.) The world's first microprocessor application was this Busicom calculator. (sold about 100,000 calculators.) Measuring 1/8 inch wide by 1/6 inch long, consisting of 2,300 transistors, Intel’s 4004 microprocessor had as much computing power as the first electronic computer, ENIAC. 2 inch 4004 and 12 inch Core™2 Duo wafer ENIAC, built in 1946, filled 3000‐cubic‐ feet of space and contained 18,000 vacuum tubes. The 4004 microprocessor could execute 60,000 operations per second Running frequency: 108 KHz Founders wanted to name their new company Moore Noyce. However the name sounds very much similar to “more noise”. "Only the paranoid survive". Moore received a B.S. degree in Chemistry from the University of California, Berkeley in 1950 and a Ph.D. -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data -

CISC Processor - Intel X86
Architecture of Computers and Parallel Systems Part 4: Intel x86 History Ing. Petr Olivka [email protected] Department of Computer Science FEI VSB-TUO Architecture of Computers and Parallel Systems Part 4: Intel x86 History Ing. Petr Olivka [email protected] Department of Computer Science FEI VSB-TUO Architecture of Computers and Parallel Systems Part 4: Intel x86 History Ing. Petr Olivka [email protected] Department of Computer Science FEI VSB-TUO CISC Processor - Intel x86 This chapter will introduce the CISC processors evolution. We will try to illustrate the history on one typical processor, because the comparison of multiple processors simultaneously would not be clear for readers. But the selection of one typical processor is complicated due to a variety of products and manufactures in the past 30 years. We have decided to describe in this presentation one of the best- known and longest mass-produced processors in existence. We definitely do not want to say that it is the best technology or that these are processors with the highest performance! The Intel x86 processors are the selected product line. Intel 8080 (Year-Technology-Transistors-Frequency-Data bus-Address Bus) Y: 1974 T: NMOS 6μm Tr: 6000 F: 2MHz D: 8b A: 16b This 8 bit processor is not directly the first member of x86 series, but it can not be skipped. It is one of the first commercially successful microprocessors. This microprocessor became the basis for a number of the first single-board computers and its instruction set inspired other manufacturers to develop 8-bit processors. -

Iapx 286 PROGRAMMER's REFERENCE MANUAL
iAPX 286 PROGRAMMER'S REFERENCE MANUAL 1983 -. Additional copies of this manual or other Intel literature may be obtained from: Literature Department Intel Corporation 3065 Bowers Avenue Santa Clara, CA 95051 The information in this document is subject to change without notice. Intel Corporation makes no warranty of any kind with regard to this material, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose. Intel Corporation assumes no responsibility for any errors that may appear in this document. Intel Corporation makes no commitment to update nor to keep current the information contained in this document. Intel Corporation assumes no responsibility for the use of any circuitry other than circuitry embodied in an Intel product. No other circuit patent licenses are implied. Intel software products are copyrighted by and shall remain the property of Intel Corporation. Use, dupli cation or disclosure is subject to restrictions stated in Intel's software license, or as defined in ASPR 7-104.9(a)(9). No part of this document may be copied or reproduced in any form or by any means without the prior written consent of Intel Corporation. The following are trademarks of Intel Corporation and its affiliates and may be used to identify Intel products: AEDIT iDiS Intellink MICROMAINFRAME BITBUS iLBX iOSP MULTIBUS BXP im iPDS MULTICHANNEL COMMputer iMMX iRMX MULTIMODULE CREDIT Insite iSBC Plug-A-Bubble i intel iSBX PROMPT 12ICE intelBOS iSDM Ripplemode iATC Intelevision iSXM RMX/80 ICE inteligent Identifier Library Manager RUPI iCS inteligent Programming MCS System 2000 iDBP Intellec Megachassis UPI Table of Contents CHAPTER 1 Page INTRODUCTION TO iAPX 286 General Attributes ......... -

Performance of a Computer (Chapter 4) Vishwani D
ELEC 5200-001/6200-001 Computer Architecture and Design Fall 2013 Performance of a Computer (Chapter 4) Vishwani D. Agrawal & Victor P. Nelson epartment of Electrical and Computer Engineering Auburn University, Auburn, AL 36849 ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 1 What is Performance? Response time: the time between the start and completion of a task. Throughput: the total amount of work done in a given time. Some performance measures: MIPS (million instructions per second). MFLOPS (million floating point operations per second), also GFLOPS, TFLOPS (1012), etc. SPEC (System Performance Evaluation Corporation) benchmarks. LINPACK benchmarks, floating point computing, used for supercomputers. Synthetic benchmarks. ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 2 Small and Large Numbers Small Large 10-3 milli m 103 kilo k 10-6 micro μ 106 mega M 10-9 nano n 109 giga G 10-12 pico p 1012 tera T 10-15 femto f 1015 peta P 10-18 atto 1018 exa 10-21 zepto 1021 zetta 10-24 yocto 1024 yotta ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 3 Computer Memory Size Number bits bytes 210 1,024 K Kb KB 220 1,048,576 M Mb MB 230 1,073,741,824 G Gb GB 240 1,099,511,627,776 T Tb TB ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 4 Units for Measuring Performance Time in seconds (s), microseconds (μs), nanoseconds (ns), or picoseconds (ps). Clock cycle Period of the hardware clock Example: one clock cycle means 1 nanosecond for a 1GHz clock frequency (or 1GHz clock rate) CPU time = (CPU clock cycles)/(clock rate) Cycles per instruction (CPI): average number of clock cycles used to execute a computer instruction.