Chap01: Computer Abstractions and Technology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -
Three-Dimensional Integrated Circuit Design: EDA, Design And
Integrated Circuits and Systems Series Editor Anantha Chandrakasan, Massachusetts Institute of Technology Cambridge, Massachusetts For other titles published in this series, go to http://www.springer.com/series/7236 Yuan Xie · Jason Cong · Sachin Sapatnekar Editors Three-Dimensional Integrated Circuit Design EDA, Design and Microarchitectures 123 Editors Yuan Xie Jason Cong Department of Computer Science and Department of Computer Science Engineering University of California, Los Angeles Pennsylvania State University [email protected] [email protected] Sachin Sapatnekar Department of Electrical and Computer Engineering University of Minnesota [email protected] ISBN 978-1-4419-0783-7 e-ISBN 978-1-4419-0784-4 DOI 10.1007/978-1-4419-0784-4 Springer New York Dordrecht Heidelberg London Library of Congress Control Number: 2009939282 © Springer Science+Business Media, LLC 2010 All rights reserved. This work may not be translated or copied in whole or in part without the written permission of the publisher (Springer Science+Business Media, LLC, 233 Spring Street, New York, NY 10013, USA), except for brief excerpts in connection with reviews or scholarly analysis. Use in connection with any form of information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed is forbidden. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. Printed on acid-free paper Springer is part of Springer Science+Business Media (www.springer.com) Foreword We live in a time of great change. -

Soft Machines Targets Ipcbottleneck
SOFT MACHINES TARGETS IPC BOTTLENECK New CPU Approach Boosts Performance Using Virtual Cores By Linley Gwennap (October 27, 2014) ................................................................................................................... Coming out of stealth mode at last week’s Linley Pro- president/CTO Mohammad Abdallah. Investors include cessor Conference, Soft Machines disclosed a new CPU AMD, GlobalFoundries, and Samsung as well as govern- technology that greatly improves performance on single- ment investment funds from Abu Dhabi (Mubdala), Russia threaded applications. The new VISC technology can con- (Rusnano and RVC), and Saudi Arabia (KACST and vert a single software thread into multiple virtual threads, Taqnia). Its board of directors is chaired by Global Foun- which it can then divide across multiple physical cores. dries CEO Sanjay Jha and includes legendary entrepreneur This conversion happens inside the processor hardware Gordon Campbell. and is thus invisible to the application and the software Soft Machines hopes to license the VISC technology developer. Although this capability may seem impossible, to other CPU-design companies, which could add it to Soft Machines has demonstrated its performance advan- their existing CPU cores. Because its fundamental benefit tage using a test chip that implements a VISC design. is better IPC, VISC could aid a range of applications from Without VISC, the only practical way to improve single-thread performance is to increase the parallelism Application (sequential code) (instructions per cycle, or IPC) of the CPU microarchi- Single Thread tecture. Taken to the extreme, this approach results in massive designs such as Intel’s Haswell and IBM’s Power8 OS and Hypervisor that deliver industry-leading performance but waste power Standard ISA and die area. -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
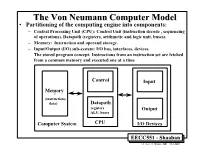
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Understanding Performance Numbers in Integrated Circuit Design Oprecomp Summer School 2019, Perugia Italy 5 September 2019
Understanding performance numbers in Integrated Circuit Design Oprecomp summer school 2019, Perugia Italy 5 September 2019 Frank K. G¨urkaynak [email protected] Integrated Systems Laboratory Introduction Cost Design Flow Area Speed Area/Speed Trade-offs Power Conclusions 2/74 Who Am I? Born in Istanbul, Turkey Studied and worked at: Istanbul Technical University, Istanbul, Turkey EPFL, Lausanne, Switzerland Worcester Polytechnic Institute, Worcester MA, USA Since 2008: Integrated Systems Laboratory, ETH Zurich Director, Microelectronics Design Center Senior Scientist, group of Prof. Luca Benini Interests: Digital Integrated Circuits Cryptographic Hardware Design Design Flows for Digital Design Processor Design Open Source Hardware Integrated Systems Laboratory Introduction Cost Design Flow Area Speed Area/Speed Trade-offs Power Conclusions 3/74 What Will We Discuss Today? Introduction Cost Structure of Integrated Circuits (ICs) Measuring performance of ICs Why is it difficult? EDA tools should give us a number Area How do people report area? Is that fair? Speed How fast does my circuit actually work? Power These days much more important, but also much harder to get right Integrated Systems Laboratory The performance establishes the solution space Finally the cost sets a limit to what is possible Introduction Cost Design Flow Area Speed Area/Speed Trade-offs Power Conclusions 4/74 System Design Requirements System Requirements Functionality Functionality determines what the system will do Integrated Systems Laboratory Finally the cost sets a limit -

Atmega165p Datasheet
Features • High Performance, Low Power Atmel® AVR® 8-Bit Microcontroller • Advanced RISC Architecture – 130 Powerful Instructions – Most Single Clock Cycle Execution – 32 × 8 General Purpose Working Registers – Fully Static Operation – Up to 16 MIPS Throughput at 16 MHz – On-Chip 2-cycle Multiplier • High Endurance Non-volatile Memory segments – 16 Kbytes of In-System Self-programmable Flash program memory – 512 Bytes EEPROM – 1 Kbytes Internal SRAM 8-bit – Write/Erase cyles: 10,000 Flash/100,000 EEPROM(1)(3) – Data retention: 20 years at 85°C/100 years at 25°C(2)(3) Microcontroller – Optional Boot Code Section with Independent Lock Bits In-System Programming by On-chip Boot Program with 16K Bytes True Read-While-Write Operation – Programming Lock for Software Security In-System • JTAG (IEEE std. 1149.1 compliant) Interface – Boundary-scan Capabilities According to the JTAG Standard Programmable – Extensive On-chip Debug Support – Programming of Flash, EEPROM, Fuses, and Lock Bits through the JTAG Interface Flash • Peripheral Features – Two 8-bit Timer/Counters with Separate Prescaler and Compare Mode – One 16-bit Timer/Counter with Separate Prescaler, Compare Mode, and Capture Mode – Real Time Counter with Separate Oscillator –Four PWM Channels ATmega165P – 8-channel, 10-bit ADC – Programmable Serial USART ATmega165PV – Master/Slave SPI Serial Interface – Universal Serial Interface with Start Condition Detector – Programmable Watchdog Timer with Separate On-chip Oscillator – On-chip Analog Comparator Preliminary – Interrupt and Wake-up -

Declustering Spatial Databases on a Multi-Computer Architecture
Declustering spatial databases on a multi-computer architecture 1 2 ? 3 Nikos Koudas and Christos Faloutsos and Ibrahim Kamel 1 Computer Systems Research Institute University of Toronto 2 AT&T Bell Lab oratories Murray Hill, NJ 3 Matsushita Information Technology Lab oratory Abstract. We present a technique to decluster a spatial access metho d + on a shared-nothing multi-computer architecture [DGS 90]. We prop ose a software architecture with the R-tree as the underlying spatial access metho d, with its non-leaf levels on the `master-server' and its leaf no des distributed across the servers. The ma jor contribution of our work is the study of the optimal capacity of leaf no des, or `chunk size' (or `striping unit'): we express the resp onse time on range queries as a function of the `chunk size', and we show how to optimize it. We implemented our metho d on a network of workstations, using a real dataset, and we compared the exp erimental and the theoretical results. The conclusion is that our formula for the resp onse time is very accurate (the maximum relative error was 29%; the typical error was in the vicinity of 10-15%). We illustrate one of the p ossible ways to exploit such an accurate formula, by examining several `what-if ' scenarios. One ma jor, practical conclusion is that a chunk size of 1 page gives either optimal or close to optimal results, for a wide range of the parameters. Keywords: Parallel data bases, spatial access metho ds, shared nothing ar- chitecture. 1 Intro duction One of the requirements for the database management systems (DBMSs) of the future is the ability to handle spatial data. -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data -

Performance of a Computer (Chapter 4) Vishwani D
ELEC 5200-001/6200-001 Computer Architecture and Design Fall 2013 Performance of a Computer (Chapter 4) Vishwani D. Agrawal & Victor P. Nelson epartment of Electrical and Computer Engineering Auburn University, Auburn, AL 36849 ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 1 What is Performance? Response time: the time between the start and completion of a task. Throughput: the total amount of work done in a given time. Some performance measures: MIPS (million instructions per second). MFLOPS (million floating point operations per second), also GFLOPS, TFLOPS (1012), etc. SPEC (System Performance Evaluation Corporation) benchmarks. LINPACK benchmarks, floating point computing, used for supercomputers. Synthetic benchmarks. ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 2 Small and Large Numbers Small Large 10-3 milli m 103 kilo k 10-6 micro μ 106 mega M 10-9 nano n 109 giga G 10-12 pico p 1012 tera T 10-15 femto f 1015 peta P 10-18 atto 1018 exa 10-21 zepto 1021 zetta 10-24 yocto 1024 yotta ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 3 Computer Memory Size Number bits bytes 210 1,024 K Kb KB 220 1,048,576 M Mb MB 230 1,073,741,824 G Gb GB 240 1,099,511,627,776 T Tb TB ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 4 Units for Measuring Performance Time in seconds (s), microseconds (μs), nanoseconds (ns), or picoseconds (ps). Clock cycle Period of the hardware clock Example: one clock cycle means 1 nanosecond for a 1GHz clock frequency (or 1GHz clock rate) CPU time = (CPU clock cycles)/(clock rate) Cycles per instruction (CPI): average number of clock cycles used to execute a computer instruction. -

Arch2030: a Vision of Computer Architecture Research Over
Arch2030: A Vision of Computer Architecture Research over the Next 15 Years This material is based upon work supported by the National Science Foundation under Grant No. (1136993). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. Arch2030: A Vision of Computer Architecture Research over the Next 15 Years Luis Ceze, Mark D. Hill, Thomas F. Wenisch Sponsored by ARCH2030: A VISION OF COMPUTER ARCHITECTURE RESEARCH OVER THE NEXT 15 YEARS Summary .........................................................................................................................................................................1 The Specialization Gap: Democratizing Hardware Design ..........................................................................................2 The Cloud as an Abstraction for Architecture Innovation ..........................................................................................4 Going Vertical ................................................................................................................................................................5 Architectures “Closer to Physics” ................................................................................................................................5 Machine Learning as a Key Workload ..........................................................................................................................6 About this -

Computer Architecture Techniques for Power-Efficiency
MOCL005-FM MOCL005-FM.cls June 27, 2008 8:35 COMPUTER ARCHITECTURE TECHNIQUES FOR POWER-EFFICIENCY i MOCL005-FM MOCL005-FM.cls June 27, 2008 8:35 ii MOCL005-FM MOCL005-FM.cls June 27, 2008 8:35 iii Synthesis Lectures on Computer Architecture Editor Mark D. Hill, University of Wisconsin, Madison Synthesis Lectures on Computer Architecture publishes 50 to 150 page publications on topics pertaining to the science and art of designing, analyzing, selecting and interconnecting hardware components to create computers that meet functional, performance and cost goals. Computer Architecture Techniques for Power-Efficiency Stefanos Kaxiras and Margaret Martonosi 2008 Chip Mutiprocessor Architecture: Techniques to Improve Throughput and Latency Kunle Olukotun, Lance Hammond, James Laudon 2007 Transactional Memory James R. Larus, Ravi Rajwar 2007 Quantum Computing for Computer Architects Tzvetan S. Metodi, Frederic T. Chong 2006 MOCL005-FM MOCL005-FM.cls June 27, 2008 8:35 Copyright © 2008 by Morgan & Claypool All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means—electronic, mechanical, photocopy, recording, or any other except for brief quotations in printed reviews, without the prior permission of the publisher. Computer Architecture Techniques for Power-Efficiency Stefanos Kaxiras and Margaret Martonosi www.morganclaypool.com ISBN: 9781598292084 paper ISBN: 9781598292091 ebook DOI: 10.2200/S00119ED1V01Y200805CAC004 A Publication in the Morgan & Claypool Publishers -

RAMP: Research Accelerator for Multiple Processors
Technical Report UCB//CSD-05-1412, September 2005 RAMP: Research Accelerator for Multiple Processors - A Community Vision for a Shared Experimental Parallel HW/SW Platform Arvind (MIT), Krste Asanovic´ (MIT), Derek Chiou (UT Austin), James C. Hoe (CMU), Christoforos Kozyrakis (Stanford), Shih-Lien Lu (Intel), Mark Oskin (U Washington), David Patterson (UC Berkeley), Jan Rabaey (UC Berkeley), and John Wawrzynek (UC Berkeley) Project Summary Desktop processor architectures have crossed a critical threshold. Manufactures have given up attempting to extract ever more performance from a single core and instead have turned to multi-core designs. While straightforward approaches to the architecture of multi-core processors are sufficient for small designs (2–4 cores), little is really known how to build, program, or manage systems of 64 to 1024 processors. Unfortunately, the computer architecture community lacks the basic infrastructure tools required to carry out this research. While simulation has been adequate for single-processor research, significant use of simplified modeling and statistical sampling is required to work in the 2–16 processing core space. Invention is required for architecture research at the level of 64–1024 cores. Fortunately, Moore’s law has not only enabled these dense multi-core chips, it has also enabled extremely dense FPGAs. Today, for a few hundred dollars, undergraduates can work with an FPGA prototype board with almost as many gates as a Pentium. Given the right support, the research community can capitalize on this opportunity too. Today, one to two dozen cores can be programmed into a single FPGA. With multiple FPGAs on a board and multiple boards in a system, large complex architectures can be explored.