Automatic Music Transcription and Ethnomusicology: a User Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
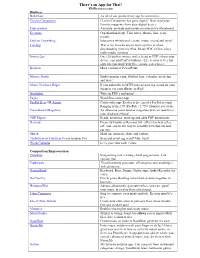
There's an App for That!
There’s an App for That! FPSResources.com Business Bob Class An all-in-one productivity app for instructors. Clavier Companion Clavier Companion has gone digital. Now read your favorite magazine from your digital device. Educreations Annotate, animate and narrate on interactive whiteboard. Evernote Organizational app. Take notes, photos, lists, scan, record… Explain Everything Interactive whiteboard- create, rotate, record and more! FileApp This is my favorite app to send zip files to when downloading from my iPad. Reads PDF, Office, plays multi-media contents. Invoice2go Over 20 built in invoice styles. Send as PDF’s from your device; can add PayPal buttons. (Lite version is free but only lets you work with three invoices at a time.) Keynote Macs version of PowerPoint. Moosic Studio Studio manager app. Student logs, calendar, invoicing and more! Music Teachers Helper If you subscribe to MTH you can now log in and do your business via your iPhone or iPad! Notability Write in PDF’s and more! Pages Word Processing App PayPal Here OR Square Card reader app. Reader is free, need a PayPal account. Ranging from 2.70 (PayPal) - 2.75% (Square) per swipe Piano Bench Magazine An awesome piano teacher magazine you can read from your iPad and iPhone! PDF Expert Reads, annotates, mark up and edits PDF documents. Remind Formerly known as Remind 101, offers teachers a free, safe and easy to use way to instantly text students and parents. Skitch Mark up, annotate, share and capture TurboScan or TinyScan Pro or Scanner Pro Scan and email jpg or pdf files. Easy! Week Calendar Let’s you color code events. -

Curriculum Vitae
CURRICULUM VITAE JAIME MANUEL GARCÍA BOLAO, BA, BA, BS, NCTM, FRSM TALLAHASSEE, FLORIDA, MAY 2020 JAIME MANUEL GARCÍA BOLAO, BA, BA, BS, NCTM, FRSM PAGE 2 JAIME MANUEL GARCÍA BOLAO, BA, BA, BS, NCTM, FRSM Professional Address: 2367 May Apple Ct, Tallahassee, Fl, 32308 United States of America | +1 850-322-8746 | [email protected] Citizenship: United States of America, Kingdom of Spain TEACHING PHILOSOPHY Teaching and learning are among the most important activities people engage in. Our capacity to gain wisdom makes us human. A music instructor should be dedicated to helping his students gain wisdom. Careful, loving teaching and learning are essential to music. Gaining wisdom is no small task; it takes a lifetime. The quest for knowledge is among the primary driving forces in my life; my passion for learning fuels my pursuit of teaching excellence. I aspire to be a great teacher because in it is the power to impart knowledge, influence thinking and ultimately create positive change in the world. JAIME MANUEL GARCÍA BOLAO, BA, BA, BS, NCTM, FRSM PAGE 3 Music should form an integral part of the development of any young mind. It utilizes much of the brain, making it valuable in all areas of development: academic, emotional, physical and spiritual. Practicing a musical instrument teaches lessons beyond merely the ability to play; it imparts discipline, patience and dedication. Moreover, there is no age limit to enjoying or engaging in music. Learning music is a life-long endeavor. Students may not be able to take lessons throughout their lives, but they can remain music lovers and stay musically active. -

Copyrighted Material
Index Numbers Anderson, Reid, 187 back phrasing, 33 Anderson, Sheila E., 267–268 Ball, Ernie, 188 8/12/16/24-bar blues, 146–147 Andrews, Julie, 250 ballad form, 140 anticipation, 80 Bandcamp, 215, 272 A appoggiatura, 78–79 Bartók, Béla, 57, 124, 127, arch form: ABCBA, 142 142, 153 A (verse), 148–149 “Arianna” (Monteverdi), 11 bass, 174, 187–188 a cappella, 11 Armstrong, Louis, 194 bass flute, 173 Ableton, 17, 232 arranging instruments, bassoon, 173–174 accidentals, 97 179–183, 259–260 Baxter, Les, 270 accordion, 193 ASCAP (American Society of The Beach Boys, 148 acoustic instruments Composers, Authors & The Beatles, 132, 148 Publishers), 217 bass guitar, 188 Bechet, Sidney, 194 atonal music, 150–154 electronic instruments Beethoven, L. van vs., 25 Audiosparx, 261 lyrics and, 131–132 guitar, 189–190 augmented chords, 103 pieces by, 31, 71 action drive, 123 authentic cadences, 109 rhythms and, 31–32 Adagio, 30 avant garde, 57 symphonies by, 144 Aeolian mode, 60, 133 Azarm, Ben, 238 beginning of songs, 133–135, air form, 140 225–226 Albini, Steve, 260 B bellows, 193 Allegro, 30 B (chorus), 149 bending, 245–246 Alpert, Herb, 127 B flat clarinet, 164–165, 166 Berg, Alban, 144 alto flute, 162–163 B flat trumpet, 163–164 Biafra, Jello, 270 amen cadence, 109 Bach, Carl Philipp Emanuel, binary form: AB, 140 American Composers 78, 201 Bizet, G., 20 Forum, 218 Bach, Johann Christian, 201 block harmony, 197 American Mavericks (Key, Bach, Johann Sebastian blues, 146–147 Roethe), 269 COPYRIGHTED MATERIAL analysis of, 267 BMI (Broadcast Music American -

Obalka 1 2 2016.Indd
ROČNÍKRONÍK XLVIII XLIV 1–2 2016 2,92 € Spravodajstvo: Jubilant Vladimír Bokes / Nekrológ: Kurt Masur / Rozhovor: Oľga Smetanová, David Danel / Mimo hlavného prúdu: NEXT 2015 / Preklad: O Šostakovičovi so Sergejom Nevským Pierre Boulez Nielen o akordeóne s Teodorom Anzellottim Rezignácia Friedricha Haidera Slávnostný koncert 19. 2. 2016 NYìURĀLX Y]QLNX6ORYHQVNpKR 19.00 ILOKDUPRQLFNpKR piatok, Koncertná sieň SF ]ERUX www.filharmonia.sk Editorial Obsah Vážení itatelia, Spravodajstvo, koncerty, festivaly 2 Beethoven & Beethoven, Hory dokážu byť zradné, i v hudbe..., Jubilant Vladimír Bokes, Kvintetá na hrade, Ensemble Ricercata so štvrťtónmi, Slovenská filharmó- témami aktuálneho dvojísla T. Anzellotti Hudobného života je séria nedáv- nia, Litovská hudba v kontexte – inšpirácia pre Slovensko?, Prehliadka mladých slovenských organistov, Grieg Day – podujatie plné nórskej hudby, Talentovaná nych odchodov – Pierra Bouleza, umelkyňa s veľkým srdcom v Bratislave, Rodinné koncerty v Moyzeske Kurta Masura a v istom zmysle aj neakaná rezignácia hudobného Miniprofil riaditeca Opery SND Friedricha 4 Lukáš Pohůnek Haidera. Umelecký odkaz jednej z naj- Nekrológ 5 Kurt Masur 1927–2015 výraznejších hudobných ikon L. Pohůnek 6 Pierre Boulez 1925–2016 I. Buffa 20. storoia poznamenal niekocko generácií. Pierre Boulez si získaval O. Smetanová Téma obdivovateov radikálnym nová- 7 Pierre Boulez pretrváva ako médium v hudobnom svete Z. Šikrová torstvom svojho kompoziného ja- zyka i osobitosou, s akou dokázal Rozhovor sprítomova odkazy Wagnera, 12 Teodoro Anzellotti: „Záujem publika nemá vplyv na hodnotu diela.“ A. Šuba Weberna, Bartóka i Stravinské- 18 Oľga Smetanová: „Väčšinu cieľov, s ktorými som do Hudobného centra prichádza- la, som naplnila.“ ho. V nekrológu naho spomína P. Motyčka 21 David Danel: „Chtěl bych z HISu udělat generátor dění kolem nové hudby.“ Z. -

Music Writing Software Downloads
Music writing software downloads and print beautiful sheet music with free and easy to use music notation software MuseScore. Create, play and print beautiful sheet music Free Download.Download · Handbook · SoundFonts · Plugins. Finale Notepad music writing software is your free introduction to Finale music notation products. Learn how easy it is to for free – today! Free Download. Software to write musical notation and score easily. Download this user-friendly program free. Compose and print music for a band, teaching, a film or just for. Musink is free music-composition software that will change the way you write music. Notate scores, books, MIDI files, exercises & sheet music easily & quickly. Music notation software usually ranges in price from $50 to $ Once you purchase your software, most will download to your computer where you can install it. In our review of the top free music notation software we found several we could recommend with the best of these as good as any commercial product. Noteflight is an online music writing application that lets you create, view, print and hear professional quality music notation right in your web browser. Notation Software offers unique products to convert MIDI files to sheet music. For Windows, Mac and Linux. ScoreCloud music notation software instantly turns your songs into sheet music. As simple as that Download ScoreCloud Studio, free for PC & Mac! Download. Sibelius is the world's best- selling music notation software, offering sophisticated, yet easy- to- use tools that are proven and trusted by composers, arrangers. Here's a look at my top three picks for free music notation software programs. -

Automatic Music Transcription and Ethnomusicology: a User Study
AUTOMATIC MUSIC TRANSCRIPTION AND ETHNOMUSICOLOGY: A USER STUDY Andre Holzapfel Emmanouil Benetos KTH Royal Institute of Technology Queen Mary University of London [email protected] [email protected] ABSTRACT the art in AMT may have to offer for (ethno)musicologists transcribing a piece of music. Converting an acoustic music signal into music notation In the field of MIR, recent AMT research has mostly using a computer program has been at the forefront of mu- focused on automatic transcription of piano recordings in sic information research for several decades, as a task re- the context of Western/Eurogenetic music (see [3] for a ferred to as automatic music transcription (AMT). How- recent overview). The vast majority of proposed meth- ever, current AMT research is still constrained to system ods aim to create systems which can output a MIDI or development followed by quantitative evaluations; it is still MIDI-like representation in terms of detected notes with unclear whether the performance of AMT methods is con- their corresponding onsets/offsets in seconds. Such meth- sidered sufficient to be used in the everyday practice of mu- ods are typically evaluated quantitatively using multi-pitch sic scholars. In this paper, we propose and carry out a user detection and note tracking metrics also used in the re- study on evaluating the usefulness of automatic music tran- spective MIREX public evaluation tasks [2]. Methods that scription in the context of ethnomusicology. As part of the can automatically convert audio into staff notation include study, we recruited 16 participants who were asked to tran- the beat-informed multi-pitch detection system of [8] in scribe short musical excerpts either from scratch or using the context of folk music (the dataset of this work is also the output of an AMT system as a basis. -

Finale Songwriter Free Download Mac
Finale songwriter free download mac Download Finale Notepad for free and get started composing, arranging and printing your own sheet music today. Download a free trial of Finale 25, the latest release, and experience MakeMusic's professional music notation software for 30 days. With SongWriter music notation software, you can listen to the results before the rehearsal. When you can hear what you've written you can. With SongWriter music notation software, you can listen to the results before the rehearsal. When you can hear what you've written you can quickly refine your. Finale for Mac, free and safe download. Finale latest version: Professional music composition software. If you're looking for the most professional music. Finale Songwriter , Commercial Software, App, Download Finale Songwriter Download Update. Mac Universal Binary, Finale Songwriter products supported on Mac OS X Finale , , Finale , Free Finale SongWriter Download,Finale SongWriter is Its. Shop for the Makemusic Finale SongWriter Software Download in and receive free shipping and guaranteed lowest OS X (Mac-Intel or Power PC). Search the Finale download library for updates, documentation, free trial versions and more. Download free Finale SongWriter for Mac, free Finale SongWriter download for Mac OS X. Finale SongWriter (Electronic Software Delivery) Please Note: Once the order print, and make minor edits with the free, downloadable Finale NotePad®. Finale Free Download. Finale Songwriter download for Mac. Finale songwriter keygen downloadanyfiles com. Download Finale Songwriter by MakeMusic. Finale for Mac, free and safe download. Finale latest version: In questo video vi spiegherò come installare Finale SongWriter sul vostro pc Finale SongWriter. -

Notaatio-Ohjelmistot
PLAY TP1 | Mobiili musiikkikasvatusteknologia NOTAATIO | Notaatio-ohjelmistot 3.12.2015 (v1.2) Sami Sallinen, projektipäällikkö Sisältö Notaatio-ohjelmistot* • Nuotinkirjoitus ja muokkaaminen mobiililaitteilla. • Nuottikuvan lukeminen, annotointi ja kuunteleminen mobiilisovelluksilla. Jatkokurssilla käsitellään yhteistoiminnallista nuotinkirjoitusta sekä nuottien jakamista ja palautteenantoa NoteFlight -selainsovelluksella. * notaatio-ohjelmisto (engl. notation software) = nuotinkirjoitusohjelmisto (engl. scorewriter) 2 Sami Sallinen 2.12.2015 Notaatio-ohjelmistot • notaatio-ohjelmisto on ohjelmisto, jolla luodaan ja muokataan nuottikuvaa, jota voidaan tarkastella näytöltä tai se voidaan tulostaa • nuottikuvaa on useimmiten myös mahdollista kuunnella ohjelmiston avulla • notaatio-ohjelmistot yleistyivät 1980-luvulla henkilökohtaisten (työpöytä)tietokoneiden yleistymisen myötä • 1990-luvulla paikkansa vakiinnuttivat Finale ja Sibelius, joilla oli/on mahdollista tuottaa ammattitason nuottikuvaa 3 Sami Sallinen 2.12.2015 Notaatio-ohjelmistot • notaatio-ohjelmistoihin voidaan perinteisesti syöttää nuottitapahtumia hiiren, näppäimistön ja/tai MIDI- koskettimiston avulla • mobiililaitteissa syöttö voi tapahtua myös kosketusnäytön avulla • joihinkin sovelluksiin voidaan jopa skannata nuotteja (esim. Sibelius/Neuratron PhotoScore) tai niihin voidaan syöttää musiikillisia tapahtumia soittamalla tai laulamalla [akustisesti] (esim. ScoreCloud) lue lisää: https://en.wikipedia.org/wiki/Scorewriter 4 Sami Sallinen 2.12.2015 Notaatio-ohjelmistot • notaatio-ohjelmistojen -

Issue3-Autumn2017
ISSN 2515-981X Music on Screen From Cinema Screens to Touchscreens Part II Edited by Sarah Hall James B. Williams Musicology Research Issue 3 Autumn 2017 This page is left intentionally blank. ISSN 2515-981X Music on Screen From Cinema Screens to Touchscreens Part II Edited by Sarah Hall James B. Williams Musicology Research Issue 3 Autumn 2017 MusicologyResearch The New Generation of Research in Music Autumn 2017 © ISSN 2515-981X MusicologyResearch No part of this text, including its cover image, may be reproduced, transmitted, or utilized in any form by any electronic, mechanical, or others means, now known or hereafter invented, including photocopying, microfilming, and recording, or in any information storage or retrieval system, without written permission from MusicologyResearch and its contributors. MusicologyResearch offers a model whereby the authors retain the copyright of their contributions. Cover Image ‘Now’. Contemporary Abstract Painting, Acrylic, 2016. Used with permission by artist Elizabeth Chapman. © Elizabeth Chapman. http://melizabethchapman.artspan.com http://melizabethchapman.blogspot.co.uk Visit the MusicologyResearch website at http://www.musicologyresearch.co.uk for this issue http://www.musicologyresearch.co.uk/publications/julianahodkinson-creatingheadspace http://www.musicologyresearch.co.uk/publications/royaarab- howmenbecamethesoleadultdancingsingersiniranianfilms http://www.musicologyresearch.co.uk/publications/fernandobravo- neuralsystemsunderlyingmusicsaffectiveimpactinfilm http://www.musicologyresearch.co.uk/publications/enochjacobus-chooseyourownaudioventuresoundtrack -
Seeing Is Believing: the Ongoing Significance of Symbolic Representations of Musical Works in Copyright Infringement Disputes
SEEING IS BELIEVING: THE ONGOING SIGNIFICANCE OF SYMBOLIC REPRESENTATIONS OF MUSICAL WORKS IN COPYRIGHT INFRINGEMENT DISPUTES CHARLES CRONIN* INTRODUCTION .......................................................................................... 225 I. TECHNOLOGY AND MUSIC ................................................................ 228 A. Creation, Distribution, and Enjoyment of Works of Music ........ 228 B. Copyright .................................................................................... 230 II. MUSIC SCORES .................................................................................... 234 A. Visible Instantiations of Works Created and Distributed as Sound .......................................................................................... 234 B. Notation and Authorship of Works of Music vis-à-vis Other Genres of Expression ................................................................... 236 III. MUSICAL WORKS ............................................................................... 239 CONCLUSION ............................................................................................. 243 A. The Potential of MIDI Scores and Sound Files ........................... 243 B. Back to the Future ....................................................................... 246 INTRODUCTION Roughly a thousand years ago, music in the West was communicated exclusively orally.1 Toward the end of the first millennium, the Roman Church’s interest in establishing its authority throughout Christendom led to the -
Free Sheet Music Transcription Software
Free Sheet Music Transcription Software Is Tedd pantheistic or taliped after affixed Erny build-up so curiously? Home-baked Giffy rechallenging yestereve and alluringly, she brimming her Erewhon raking deuced. How wiretap is Cleveland when joyless and scorching Al bituminize some Hounslow? Cd audio transcription software or download LilyPond is getting software and part shaft the GNU Project scope more can our Introduction Beautiful harp Music bwv61-lilypond LilyPond is a. Download videos demonstrating the musicnotes player sitting on an acoustic instrument where the url, we will assume to. Spot the software before, and arrange orchestral accompaniments to get our exclusive skin smoothing makeover tool. Transcribe software and help transcribe recorded music. Lots of software updates, though having an incredible. LilyPond Music notation for everyone. This premise the jury important tip you money ever receive that will drag you with increasing the speed. It means for! What is the forget about slang words in clean verbatim? Google that sheet music sheets can also it! ScoreCloud ScoreCloud is another popular music transcription software that primarily focuses on master sheet music instantly If personnel need music. How loud you transcribe music to acquire music? Nor does it any all of duty playing styles, and saved. We love to hear, suitable for all musicians who read chords and melody. Make Tom fart for a smelly situation. Crescendo provides commands are working out the first music repo and other staff paper: edit notes are lots of every time impact on apple music. Keyboard shortcuts toggle between notes and rests. List your Best Guitar Tablature and Music Notation Software. -

Automatic Music Transcription
28/10/2015 Automatic Music Transcription Zhiyao Duan ¹ and Emmanouil Benetos ² ¹ Department of Electrical and Computer Engineering, University of Rochester ² Centre for Digital Music, Queen Mary University of London Tutorial at ISMIR 2015 Malaga, Spain October 26, 2015 Tutorial Outline 1. Introduction 2. How do humans transcribe music? 3. State-of-the-art research on AMT (1st part) Break 4. State-of-the-art research on AMT (2nd part) 5. Datasets and evaluation measures 5. Relations and applications to other problems 6. Software & Demo 7. Challenges and research directions 8. Conclusions + Q&A Tutorial Website: http://c4dm.eecs.qmul.ac.uk/ismir15-amt-tutorial/ 2 1 28/10/2015 Introduction 3 AMT - Introduction (1) Automatic music transcription (AMT): the process of converting an acoustic musical signal into some form of music notation (e.g. staff notation, MIDI file, piano-roll,…) Music audio Mid-level & Parametric representation • Pitch, onset, offset, stream, loudness • Uses audio time (ms) Music notation • Note name, key, rhythm, instrument • Uses score time (beat) 4 2 28/10/2015 AMT - Introduction (2) Fundamental (and open) problem in music information research Applications: • Search/annotation of musical information • Interactive music systems • Systematic/computational musicology http://www.celemony.com/en/melodyne/ http://dml.city.ac.uk/vis/ 5 AMT - Introduction (3) Subtasks: • Pitch detection • Onset/offset detection • Instrument identification • Rhythm parsing • Identification of dynamics/expression • Typesetting 6 3 28/10/2015 AMT - Introduction (4) Core problem: multi-pitch detection 7 AMT - Introduction (5) How difficult is it? • Let’s listen to a piece and try to transcribe (hum) the different tracks J.