Can a Troubled Political Era Be Detected by Machine Learning Methods? an Application on the End of Year Speeches of the Italian Presidents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Carlo Azeglio Ciampi
Carlo Azeglio Ciampi Italia, Primer ministro (1993-1994) y presidente de la República (1999-2006) Duración del mandato: 18 de Maig de 1999 - de de Nacimiento: Livorno, provincia de Livorno, región de Toscana, 09 de Desembre de 1920 Defunción: Roma, región de Lacio, 16 de Setembre de 2016</p> Partido político: sin filiación Professió: Funcionario de banca Resumen http://www.cidob.org 1 of 3 Biografía Cursó estudios en Pisa en su Escuela Normal Superior, por la que se diplomó en 1941, y en su Universidad, por la que en 1946 obtuvo una doble licenciatura en Derecho y Letras. Durante la Segunda Guerra Mundial sirvió en el Ejército italiano y tras la caída de Mussolini en 1943 estuvo con los partisanos antinazis. En 1945 militó en el Partido de Acción de Ferruccio Parri, pero pronto se desvinculó de cualquier organización política. En 1946 entró a trabajar por la vía de oposiciones en el Banco de Italia, institución donde desarrolló toda su carrera hasta la cúspide. Sucesivamente fue técnico en el departamento de investigación económica (1960-1970), jefe del departamento (1970-1973), secretario general del Banco (1973-1976), vicedirector general (1976-1978), director general (1978-1979) y, finalmente, gobernador (1979-1993). Considerado un economista de formación humanista, Ciampi salvaguardó la independencia del banco del Estado y se labró una imagen de austeridad y apego al trabajo. Como titular representó a Italia en las juntas de gobernadores de diversas instituciones financieras internacionales. Con su elección el 26 de abril de 1993 por el presidente de la República Oscar Luigi Scalfaro (por primera vez sin consultar a los partidos) para reemplazar a Giuliano Amato, Ciampi se convirtió en el primer jefe de Gobierno técnico, esto es, no adscrito a ninguna formación, desde 1945, si bien algunos líderes políticos insistieron en sus simpatías democristianas. -

The Transformation of Italian Democracy
Bulletin of Italian Politics Vol. 1, No. 1, 2009, 29-47 The Transformation of Italian Democracy Sergio Fabbrini University of Trento Abstract: The history of post-Second World War Italy may be divided into two distinct periods corresponding to two different modes of democratic functioning. During the period from 1948 to 1993 (commonly referred to as the First Republic), Italy was a consensual democracy; whereas the system (commonly referred to as the Second Republic) that emerged from the dramatic changes brought about by the end of the Cold War functions according to the logic of competitive democracy. The transformation of Italy’s political system has thus been significant. However, there remain important hurdles on the road to a coherent institutionalisation of the competitive model. The article reconstructs the transformation of Italian democracy, highlighting the socio-economic and institutional barriers that continue to obstruct a competitive outcome. Keywords: Italian politics, Models of democracy, Parliamentary government, Party system, Interest groups, Political change. Introduction As a result of the parliamentary elections of 13-14 April 2008, the Italian party system now ranks amongst the least fragmented in Europe. Only four party groups are represented in the Senate and five in the Chamber of Deputies. In comparison, in Spain there are nine party groups in the Congreso de los Diputados and six in the Senado; in France, four in the Assemblée Nationale an d six in the Sénat; and in Germany, six in the Bundestag. Admittedly, as is the case for the United Kingdom, rather fewer parties matter in those democracies in terms of the formation of governments: generally not more than two or three. -

October 22, 1962 Amintore Fanfani Diaries (Excepts)
Digital Archive digitalarchive.wilsoncenter.org International History Declassified October 22, 1962 Amintore Fanfani Diaries (excepts) Citation: “Amintore Fanfani Diaries (excepts),” October 22, 1962, History and Public Policy Program Digital Archive, Italian Senate Historical Archives [the Archivio Storico del Senato della Repubblica]. Translated by Leopoldo Nuti. http://digitalarchive.wilsoncenter.org/document/115421 Summary: The few excerpts about Cuba are a good example of the importance of the diaries: not only do they make clear Fanfani’s sense of danger and his willingness to search for a peaceful solution of the crisis, but the bits about his exchanges with Vice-Minister of Foreign Affairs Carlo Russo, with the Italian Ambassador in London Pietro Quaroni, or with the USSR Presidium member Frol Kozlov, help frame the Italian position during the crisis in a broader context. Credits: This document was made possible with support from the Leon Levy Foundation. Original Language: Italian Contents: English Translation The Amintore Fanfani Diaries 22 October Tonight at 20:45 [US Ambassador Frederick Reinhardt] delivers me a letter in which [US President] Kennedy announces that he must act with an embargo of strategic weapons against Cuba because he is threatened by missile bases. And he sends me two of the four parts of the speech which he will deliver at midnight [Rome time; 7 pm Washington time]. I reply to the ambassador wondering whether they may be falling into a trap which will have possible repercussions in Berlin and elsewhere. Nonetheless, caught by surprise, I decide to reply formally tomorrow. I immediately called [President of the Republic Antonio] Segni in Sassari and [Foreign Minister Attilio] Piccioni in Brussels recommending prudence and peace for tomorrow’s EEC [European Economic Community] meeting. -

Lista Location English.Xlsx
LOCATIONS LIST Postal City Name Address Code ABANO TERME 35031 DIBRA KLODIANA VIA GASPARE GOZZI 3 ABBADIA SAN SALVATORE 53021 FABBRINI CARLO PIAZZA GRAMSCI 15 ABBIATEGRASSO 20081 BANCA DI LEGNANO VIA MENTANA ACCADIA 71021 NIGRO MADDALENA VIA ROMA 54 ACI CATENA 95022 PRINTEL DI STIMOLO PRINCIPATO VIA NIZZETI 43 ACIREALE 95024 LANZAFAME ALESSANDRA PIAZZA MARCONI 12 ACIREALE 95024 POLITI WALTER VIA DAFNICA 104 102 ACIREALE 95024 CERRA DONATELLA VIA VITTORIO EMANUELE 143 ACIREALE 95004 RIV 6 DI RIGANO ANGELA MARIA VIA VITTORIO EMANUELE II 69 ACQUAPENDENTE 01021 BONAMICI MANUELA VIA CESARE BATTISTI 1 ACQUASPARTA 05021 LAURETI ELISA VIA MARCONI 40 ACQUEDOLCI 98076 MAGGIORE VINCENZO VIA RICCA SALERNO 43 ACQUI TERME 15011 DOC SYSTEM VIA CARDINAL RAIMONDI 3 ACQUI TERME 15011 RATTO CLAUDIA VIA GARIBALDI 37 ACQUI TERME 15011 CASSA DI RISPARMIO DI ALESSAND CORSO BAGNI 102 106 ACQUI TERME 15011 CASSA DI RISPARMIO DI ALESSAND VIA AMENDOLA 31 ACRI 87041 MARCHESE GIUSEPPE ALDO MORO 284 ADRANO 95031 LA NAIA NICOLA VIA A SPAMPINATO 13 ADRANO 95031 SANTANGELO GIUSEPPA PIAZZA UMBERTO 8 ADRANO 95031 GIULIANO CARMELA PIAZZA SANT AGOSTINO 31 ADRIA 45011 ATTICA S R L RIVIERA GIACOMO MATTEOTTI 5 ADRIA 45011 SANTINI DAVIDE VIA CHIEPPARA 67 ADRIA 45011 FRANZOSO ENRICO CORSO GIUSEPPE MAZZINI 73 AFFI 37010 NIBANI DI PAVONE GIULIO AND C VIA DANZIA 1 D AGEROLA 80051 CUOMO SABATO VIA PRINCIPE DI PIEMONTE 11 AGIRA 94011 BIONDI ANTONINO PIAZZA F FEDELE 19 AGLIANO TERME 14041 TABACCHERIA DELLA VALLE VIA PRINCIPE AMEDEO 27 29 AGNA 35021 RIVENDITA N 7 VIA MURE 35 AGRIGENTO -

13273 PSA Conf Programme 2011 PRINT
Transforming Politics: New Synergies 61st Annual International Conference 18 – 21 April 2011 Novotel London West, London, UK PSA 61st Annual International Conference London, 18 –21 April 2011 www.psa.ac.uk/2011 A Word of Welcome Dear Conference delegate You are extremely welcome to this 61st Conference of the Political Studies Association, held in the UK capital. The recently refurbished Hammersmith Novotel hotel offers high quality conference facilities all under one roof. We are expecting well over 500 delegates, representing over 50 different countries. There are more than 190 panels, as well as the workshops on Monday, building on last year’s innovation, and as a new addition, dedicated posters sessions. There are also three receptions. The Conference theme is ‘Transforming Politics: New Synergies’. Keynote speakers include Professor Carole Pateman, President of APSA, revisiting the concept of participatory democracy and Professor Iain McLean giving the Government and Opposition-sponsored Leonard Schapiro lecture on the subject of coalition and minority government. On Wednesday, our after-dinner speaker is Professor Tony Wright, (UCL and Birkbeck College) former MP and Chair of the Public Administration Select Committee. Amongst other highlights, Professor Vicente Palermo will discuss Anglo-Argentine relations and John Denham MP will talk on ‘English questions’ and the Labour Party’ and Sir Michael Aaronson, former Director General of Save the Children, will be drawing on his experience working in crisis situations to reflect on whether we had a choice in Libya today. Despite the worsening economic and policy environment, this has been a particularly active and successful year for the Association. Overall membership figures, including those for the new Teachers’ Section, continue to rise. -

Piersanti Mattarella
Piersanti Mattarella Piersanti Mattarella nacque a Castellammare del Golfo il 24 maggio 1935. Secondogenito di Bernardo Mattarella, uomo politico della Democrazia Cristiana e fratello di Sergio, 12° Presidente della Repubblica Italiana. Piersanti si trasferì a Roma con la famiglia nel 1948. Studiò al San Leone Magno, retto dai Fratelli maristi, e militò nell’Azione cattolica mostrandosi battagliero sostenitore della dottrina sociale della Chiesa che si andava affermando. Si laureò a pieni voti in Giurisprudenza alla Sapienza con una tesi in economia politica, sui problemi dell’integrazione economica europea. Tornò in Sicilia nel 1958 per sposarsi. Divenne assistente ordinario di diritto privato all'Università di Palermo. Ebbe due figli: Bernardo e Maria. Entrò nella Dc tra il 1962 e il 1963 e nel novembre del 1964 si candidò nella relativa lista alle elezioni comunali di Palermo ottenendo più di undicimila preferenze, divenendo consigliere comunale nel pieno dello scandalo del “Sacco di Palermo”. Erano, infatti, gli anni della crisi della Dc in Sicilia, c’era una spaccatura, si stavano affermando Lima e Ciancimino e si preparava il tempo in cui una colata di cemento avrebbe spazzato via le ville liberty di Palermo. Nel 1967 entrò nell’Assemblea Regionale. In politica adottò uno stile tutto suo: parlò di trasparenza, proponendo di ridurre gli incarichi (taglio degli assessorati da dodici ad otto e delle commissioni legislative da sette a cinque e per l'ufficio di presidenza la nomina di soli due vice, un segretario ed un questore) e battendosi per la rotazione delle persone nei centri di potere con dei limiti temporali, in modo da evitare il radicarsi di consorterie pericolose. -

Modello Per Schede Indice Repertorio
PROCEDIMENTI RELATIVI AI REATI PREVISTI DALL'ARTICOLO 96 DELLA COSTITUZIONE Trasmissione di decreti di archiviazione: 2 Domande di autorizzazione a procedere in giudizio ai sensi dell'articolo 96 della costituzione: 4 TRASMISSIONE DI DECRETI DI ARCHIVIAZIONE atti relativi ad ipotesi di responsabilità nei confronti di Lamberto Dini, nella sua qualità di Ministro degli affari esteri pro tempore e di altri, sed. 13; atti relativi ad ipotesi di responsabilità nei confronti di Oscar Luigi Scalfaro, nella sua qualità di Ministro dell'interno pro tempore e di altri, sed. 16; atti relativi ad ipotesi di responsabilità nei confronti di Gianni De Michelis, nella sua qualità di Vice Presidente del Consiglio e Ministro degli affari esteri pro tempore e di altri, sed. 94; atti relativi ad ipotesi di responsabilità nei confronti di Edoardo Ronchi, nella sua qualità di Ministro dell'ambiente pro tempore, sed. 94; atti relativi ad ipotesi di responsabilità nei confronti di Roberto Castelli, nella sua qualità di Ministro della giustizia, sed. 94; atti relativi ad ipotesi di responsabilità nei confronti di Ottaviano Del Turco, nella sua qualità di Ministro dell'economia e delle finanze pro tempore, sed. 96; atti relativi ad ipotesi di responsabilità nei confronti di Roberto Castelli, nella sua qualità di Ministro della giustizia, sed. 113; atti relativi ad ipotesi di responsabilità nei confronti di Giovanni Fontana, nella sua qualità di Ministro dell'agricoltura e delle foreste pro tempore e di altri, sed. 130; atti relativi ad ipotesi di responsabilità nei confronti di Gianni De Michelis, nella sua qualità di Ministro del lavoro pro tempore, sed. 134; atti relativi ad ipotesi di responsabilità nei confronti di Giuliano Amato, nella sua qualità di Presidente del Consiglio pro tempore, Piero Barucci, nella sua qualità di Ministro del tesoro pro tempore, e Francesco Reviglio della Veneria, nella sua qualità di Ministro del bilancio e programmazione economica pro tempore, sed. -

Fascicolo De Nicola
Ufficio comunicazione istituzionale 1 1 0 2 e l Italiani i r chehannofattol’Italia: p a - 0 1 . EnricoDeNicola n , a i r e r b i L n i i r t n o c n i A cura dell’Ufficio comunicazione istituzionale del Senato della Repubblica. © 2011 Senato della Repubblica Finito di stampare nel mese di aprile 2011 presso il Centro riproduzione documenti. La presente pubblicazione è edita dal Senato della Repubblica. Non è destinata alla vendita ed è utilizzata solo per scopi di comunicazione istituzionale. Incontri in Libreria 2011 3 Italianichehannofattol’Italia Nell'ambito delle manifestazioni per i 150 anni dell'unità d'Italia l’Ufficio comunicazione istituzio - nale del Senato organizza presso la Libreria in via della Maddalena 27 un programma di incontri dal titolo “Italiani che hanno fatto l'Italia". L'iniziativa ha l'obiettivo di far conoscere alle nuove generazioni importanti personalità del nostro Paese protagoniste dei lavori dell'Aula di Palazzo Madama. Le personalità a cui sono dedicati gli incontri sono state scelte tra quelle che hanno ricoperto il ruolo di senatori a vita o di Presidenti del Senato e fanno riferimento oltre che al mondo della politica, anche a quelli della cultura, dello spettacolo e delle attività produttive. Agli incontri partecipano le scuole secondarie di II grado che visitano il Senato. L’appuntamento del mese di aprile 2011, a 60 anni dall’elezione alla Presidenza del Senato della Repubblica, è dedicato a Enrico De Nicola. Per ricordarne la figura questa pubblicazione contiene il messaggio del Capo provvisorio dello 4 Incontri in Libreria 2011 Stato letto durante i lavori dell’Assemblea costituen - te (15 luglio 1946), il discorso di insediamento a Pre - sidente del Senato del 5 maggio 1951 e un interven - to durante i lavori dell’Assemblea di Palazzo Mada - ma sul disegno di legge Provvedimenti a favore della città di Napoli (3 marzo 1953). -
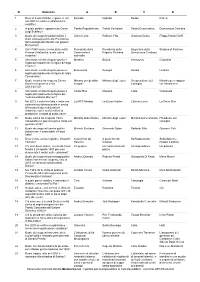
Documento Scaricato Dal Sito Mininterno.Net - Il Portale Per La Preparazione Ai Concorsi Pubblici - Esercitati GRATIS On-Line! N
N. Domanda A B C D 1 Dove si trova il Darfur, regione in cui Somalia Uganda Sudan Eritrea nel 2003 è iniziato un drammatico conflitto? 2 A quale partito è appartenuto Oscar Partito Repubblicano Partito Socialista Partito Democratico Democrazia Cristiana Luigi Scalfaro? 3 Quale dei seguenti politici italiani è Gianni Letta Raffaele Fitto Graziano Delrio Filippo Patroni Griffi stato sottosegretario alla Presidenza del Consiglio dei Ministri, nei governi Berlusconi? 4 Il 6/1/1980 venne ucciso dalla mafia Presidente della Presidente della Segretario della Sindaco di Palermo Piersanti Mattarella: quale carica Commissione Regione Siciliana Democrazia Cristiana ricopriva? antimafia 5 Alla storia recente di quale paese è Messico Bolivia Venezuela Colombia legata principalmente la figura di Hugo Chavez? 6 Alla storia recente di quale paese è Bielorussia Georgia Russia Ucraina legata principalmente la figura di Julija Tymosenko? 7 Quale incarico ha ricoperto Emma Ministro per gli affari Ministro degli esteri Vicepresidente del Ministro per i rapporti Bonino nel governo Letta europei Consiglio col Parlamento (2013-2014)? 8 Alla storia recente di quale paese è Costa Rica Messico Cuba Venezuela legata principalmente la figura del "subcomandante Marcos"? 9 Nel 2012 è sorta fra Italia e India una La MCS Melody La Exxon Valdez L'Enrica Lexie La Sirius Star controversia internazionale in merito all'arresto di due marò italiani imbarcati, come nuclei militari di protezione, a bordo di quale nave? 10 Quale carica ha ricoperto Yanis Ministro delle finanze -

December 21, 1960 Report to Minister of Foreign Affairs Antonio Segni
Digital Archive digitalarchive.wilsoncenter.org International History Declassified December 21, 1960 Report to Minister of Foreign Affairs Antonio Segni Citation: “Report to Minister of Foreign Affairs Antonio Segni,” December 21, 1960, History and Public Policy Program Digital Archive, Istituto Luigi Sturzo, Archivio Giulio Andreotti, NATO Series, Box 160, Subseries 1, Folder 012.1. https://digitalarchive.wilsoncenter.org/document/155271 Summary: Praise for Paul-Henri Spaak in helping NATO unify Western Europe and integrate the Allied states’ economic, political, and military objectives in their ongoing struggle against the Soviet Union. Credits: This document was made possible with support from the MacArthur Foundation, Carnegie Corporation of New York (CCNY), and Istituto Luigi Sturzo. Original Language: Italian Contents: Scan of Original Document i&& 16l�7 11 ._ to& Henù4 Mbane aerane olla la rlral.one alaS8'8rlah a'1e.tlt1ca s1 Il cblua aa UD& "Dota ot �· Wlllfd'te U �.IOJlàe•· acrl•e oJl8 essa tt wrml.D:i.t.f� 8ll uaa ''note utaalMl8tfe-. a i• .. m 1•LJ.t.ra espressione aecllbrane det1DSra corret.�1iallt.e 11 corso e la concl'181oaa del ct11»a1 Uta Cbe. a1 sono S'VDltl a Parlgt u·urante 1 g1omt soorst. Per glaagere ad 11118. valut.z:�z1one U p1ù posulblla eaat.ta. è uceooario ��1.re da alcum .Pl9m8Ua e tormulare �cmae J;lr8C1aaz2on1. La concezlQtle eatet:aslva, e lt\ co� res\rlt.t.1V-d, aell.'Alleanza. ea1aWDU tiD dal4' f 011\.i&Zione della &Te (tl ùa r1cor�a.re 006 u r� moao art.tcolo 2 tu 1DGQJ1.t.o mm aenza uUrlcoltA nel trrat.t.at.o) al eoao p1il a»er�n:t.a rlvelat. -

Addresses to Members of Both Houses of Parliament
PARLIAMENTARY INFORMATION LIST Number 04092, 25 October 2018 Addresses to members of Compiled by both Houses of Sarah Priddy Parliament This note lists heads of state and dignitaries who have addressed MPs and members of the House of Lords. Occasions that are not formal addresses are marked with an asterisk. Links to the speeches and any images are provided where available. A comprehensive list of State visits during The Queen's reign is available on the official website of the British Monarchy. Feedback Please send comments or corrections to the Parliament and Constitution Centre. Suggestions for new lists welcomed. www.parliament.uk/commons-library | intranet.parliament.uk/commons-library | [email protected] | @commonslibrary Addresses to both Houses of Parliament since 1939 Date Speaker Title of Speaker / Occasion Location 23 October 2918 King Willem-Alexander King of the Netherlands Royal Gallery 12 July 2017 King Felipe VI King of Spain Royal Gallery 01 November 2016 Juan Manuel Santos Calderón President of the Republic of Colombia Queen's Robing Room 19 April 2016 Mr Joko Widodo Indonesian President Queen's Robing Room 12 November 2015 Mr Narendra Modi Prime Minister of India Royal Gallery 20 October 2015 Mr Xi Jinping President of The People’s Republic of China Royal Gallery 21 October 2014 Dr Tony Tan Keng Yam President of the Republic of Singapore Queen's Robing Room 03 March 2015 Enrique Peña Nieto President of the United Mexican States Queen's Robing Room 08 April 2014 Michael D. Higgins President of Ireland Royal Gallery -

Italy's Atlanticism Between Foreign and Internal
UNISCI Discussion Papers, Nº 25 (January / Enero 2011) ISSN 1696-2206 ITALY’S ATLANTICISM BETWEEN FOREIGN AND INTERNAL POLITICS Massimo de Leonardis 1 Catholic University of the Sacred Heart Abstract: In spite of being a defeated country in the Second World War, Italy was a founding member of the Atlantic Alliance, because the USA highly valued her strategic importance and wished to assure her political stability. After 1955, Italy tried to advocate the Alliance’s role in the Near East and in Mediterranean Africa. The Suez crisis offered Italy the opportunity to forge closer ties with Washington at the same time appearing progressive and friendly to the Arabs in the Mediterranean, where she tried to be a protagonist vis a vis the so called neo- Atlanticism. This link with Washington was also instrumental to neutralize General De Gaulle’s ambitions of an Anglo-French-American directorate. The main issues of Italy’s Atlantic policy in the first years of “centre-left” coalitions, between 1962 and 1968, were the removal of the Jupiter missiles from Italy as a result of the Cuban missile crisis, French policy towards NATO and the EEC, Multilateral [nuclear] Force [MLF] and the revision of the Alliance’ strategy from “massive retaliation” to “flexible response”. On all these issues the Italian government was consonant with the United States. After the period of the late Sixties and Seventies when political instability, terrorism and high inflation undermined the Italian role in international relations, the decision in 1979 to accept the Euromissiles was a landmark in the history of Italian participation to NATO.