A Grammar Checker for Challenging Cases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Representation of Inflected Nouns in the Internal Lexicon
Memory & Cognition 1980, Vol. 8 (5), 415423 Represeritation of inflected nouns in the internal lexicon G. LUKATELA, B. GLIGORIJEVIC, and A. KOSTIC University ofBelgrade, Belgrade, Yugoslavia and M.T.TURVEY University ofConnecticut, Storrs, Connecticut 06268 and Haskins Laboratories, New Haven, Connecticut 06510 The lexical representation of Serbo-Croatian nouns was investigated in a lexical decision task. Because Serbo-Croatian nouns are declined, a noun may appear in one of several gram matical cases distinguished by the inflectional morpheme affixed to the base form. The gram matical cases occur with different frequencies, although some are visually and phonetically identical. When the frequencies of identical forms are compounded, the ordering of frequencies is not the same for masculine and feminine genders. These two genders are distinguished further by the fact that the base form for masculine nouns is an actual grammatical case, the nominative singular, whereas the base form for feminine nouns is an abstraction in that it cannot stand alone as an independent word. Exploiting these characteristics of the Serbo Croatian language, we contrasted three views of how a noun is represented: (1) the independent entries hypothesis, which assumes an independent representation for each grammatical case, reflecting its frequency of occurrence; (2) the derivational hypothesis, which assumes that only the base morpheme is stored, with the individual cases derived from separately stored inflec tional morphemes and rules for combination; and (3) the satellite-entries hypothesis, which assumes that all cases are individually represented, with the nominative singular functioning as the nucleus and the embodiment of the noun's frequency and around which the other cases cluster uniformly. -

Does English Have a Genitive Case? [email protected]
2. Amy Rose Deal – University of Massachusetts, Amherst Does English have a genitive case? [email protected] In written English, possessive pronouns appear without ’s in the same environments where non-pronominal DPs require ’s. (1) a. your/*you’s/*your’s book b. Moore’s/*Moore book What explains this complementarity? Various analyses suggest themselves. A. Possessive pronouns are contractions of a pronoun and ’s. (Hudson 2003: 603) B. Possessive pronouns are inflected genitives (Huddleston and Pullum 2002); a morphological deletion rule removes clitic ’s after a genitive pronoun. Analysis A consists of a single rule of a familiar type: Morphological Merger (Halle and Marantz 1993), familiar from forms like wanna and won’t. (His and its contract especially nicely.) No special lexical/vocabulary items need be postulated. Analysis B, on the other hand, requires a set of vocabulary items to spell out genitive case, as well as a rule to delete the ’s clitic following such forms, assuming ’s is a DP-level head distinct from the inflecting noun. These two accounts make divergent predictions for dialects with complex pronominals such as you all or you guys (and us/them all, depending on the speaker). Since Merger operates under adjacency, Analysis A predicts that intervention by all or guys should bleed the formation of your: only you all’s and you guys’ are predicted. There do seem to be dialects with this property, as witnessed by the American Heritage Dictionary (4th edition, entry for you-all). Call these English 1. Here, we may claim that pronouns inflect for only two cases, and Merger operations account for the rest. -

Book of Abstracts
2 June 5 – 7 2014 Palacký University, Olomouc, Czech Republic http://olinco.upol.cz Book of Abstracts Contents: Invited speakers (p. 17-21) Bas Aarts Investigating spoken English syntax and usage David Adger Constraints on Phrase Structure Ocke-Schwen Bohn L2 speech learning: Do cross-language phonetic relationships provide a full account? Noam Chomsky Problems of Projection: Extensions Linda Polka The development of phonetic perception: a journey guided by speech input and intake. 3 Oral presentations (p. 22-200) Víctor Acedo-Matellán and Cristina Real-Puigdollers Locative prepositions and quantifier scope: evidence from Catalan Sascha Alexeyenko Adverbs as PPs and the Semantics of –ly Manuela Âmbar and Ángel L. Jiménez-Fernández Subjunctives: How much left periphery do you need? Maria Andreou and Ianthi Maria Tsimpli Character Reference: A Study of Greek-German and Greek-English Bilingual Children Amir Anvari Remarks on Bridging Pilar P. Barbosa Pseudoclefts: (echo) questions and answers Jitka Bartošová and Ivona Kučerová Against a unified NP-deletion analysis of pronouns: Evidence from demonstratives in Czech Lucie Benešová, Michal Křen, and Martina Waclawičová ORAL2013: representative corpus of informal spoken Czech Štefan Beňuš, Uwe D. Reichel, and Katalin Mády Modelling accentual phrase intonation in Slovak and Hungarian Lolita Bérard and José Deulofeu On the limit between relative and “consecutive clauses”: the case of [NP Det [- def] N que X] construct in spoken French: a corpus based analysis. Theresa Biberauer Towards a theory of syntactic categories: an emergentist generative perspektive 4 Theresa Biberauer and Ian Roberts Conditional Inversion and Types of Parametric Change Veronika Bláhová and Filip Smolík Early comprehension of verb number morphemes in Czech: evidence for a pragmatic account Anna Bondaruk Three types of predicational clauses in Polish and constrains on their use Karolina Broś Polish voicing assimilation at the phonetics-phonology interface Elena Castroviejo and Berit Gehrke Manner–in–disguise vs. -

The Term Declension, the Three Basic Qualities of Latin Nouns, That
Chapter 2: First Declension Chapter 2 covers the following: the term declension, the three basic qualities of Latin nouns, that is, case, number and gender, basic sentence structure, subject, verb, direct object and so on, the six cases of Latin nouns and the uses of those cases, the formation of the different cases in Latin, and the way adjectives agree with nouns. At the end of this lesson we’ll review the vocabulary you should memorize in this chapter. Declension. As with conjugation, the term declension has two meanings in Latin. It means, first, the process of joining a case ending onto a noun base. Second, it is a term used to refer to one of the five categories of nouns distinguished by the sound ending the noun base: /a/, /ŏ/ or /ŭ/, a consonant or /ĭ/, /ū/, /ē/. First, let’s look at the three basic characteristics of every Latin noun: case, number and gender. All Latin nouns and adjectives have these three grammatical qualities. First, case: how the noun functions in a sentence, that is, is it the subject, the direct object, the object of a preposition or any of many other uses? Second, number: singular or plural. And third, gender: masculine, feminine or neuter. Every noun in Latin will have one case, one number and one gender, and only one of each of these qualities. In other words, a noun in a sentence cannot be both singular and plural, or masculine and feminine. Whenever asked ─ and I will ask ─ you should be able to give the correct answer for all three qualities. -

Introduction to Gothic
Introduction to Gothic By David Salo Organized to PDF by CommanderK Table of Contents 3..........................................................................................................INTRODUCTION 4...........................................................................................................I. Masculine 4...........................................................................................................II. Feminine 4..............................................................................................................III. Neuter 7........................................................................................................GOTHIC SOUNDS: 7............................................................................................................Consonants 8..................................................................................................................Vowels 9....................................................................................................................LESSON 1 9.................................................................................................Verbs: Strong verbs 9..........................................................................................................Present Stem 12.................................................................................................................Nouns 14...................................................................................................................LESSON 2 14...........................................................................................Strong -

Systemic Polyfunctionality and Morphology-Syntax Interdependencies
Systemic polyfunctionality and morphology-syntax interdependencies Farrell Ackerman1 Olivier Bonami2 Irina Nikolaeva3 1University of California, San Diego 2Université Paris-Sorbonne 3SOAS Defaults in Morphological Theory Lexington, May 2012 The basic problem: Systemic Polyfunctionality Cross-linguistically person/number markers (PNMs) in verbal paradigms often exhibit similarities (up to identity) with person/number markers in nominal possessive constructions (Allen 1964, Radics 1980, Siewierska 1998, 2004, among others): When a language has distinct PNM paradigms for verbal subject (S/A) and object (O) indexing, a question arises: Which paradigm does the possessive paradigm align with? (1) Retuarã (Tucanoan) S/A alignment b˜ıre yi-ha¯a-a¯ Psi yi-behoa-pi 2SG 1SG-kill-NEG.IMP 1SG-spear-INSTR ‘(Be careful), lest I kill you with my spear’ (Strom 1992:63) (2) Kilivila (Central-Eastern Malayo-Polynesian) O alignment lube-gu ku-sake-gu buva friend-1SG 2SG-give-1SG betel_nut ‘My friend, do you give me betel nuts?’ (Senft 1986:53) The basic problem: Systemic Polyfunctionality Among the 130 relevant languages in Sierwieska’s (1998) sample she observes that, We see that [...], among the languages in the sample the affinities in form between the possessor affixes and the verbal person markers of the O (41%) are just marginally more common than those with the S/A (39%). (Siewierska 1998:2) There are, by hypothesis, systemic properties of specific grammars, rather than language independent universals, that explain the alignments observed. The languages compared by Siewierska appear to have distinct markers for S/A and O, and the question asked is which paradigm appears in possessive marking. -

Objective and Subjective Genitives
Objective and Subjective Genitives To this point, there have been three uses of the Genitive Case. They are possession, partitive, and description. Many genitives which have been termed possessive, however, actually are not. When a Genitive Case noun is paired with certain special nouns, the Genitive has a special relationship with the other noun, based on the relationship of a noun to a verb. Many English and Latin nouns are derived from verbs. For example, the word “love” can be used either as a verb or a noun. Its context tells us how it is being used. The patriot loves his country. The noun country is the Direct Object of the verb loves. The patriot has a great love of his country. The noun country is still the object of loving, but now loving is expressed as a noun. Thus, the genitive phrase of his country is called an Objective Genitive. You have actually seen a number of Objective Genitives. Another common example is Rex causam itineris docuit. The king explained the cause of the journey (the thing that caused the journey). Because “cause” can be either a noun or a verb, when it is used as a noun its Direct Object must be expressed in the Genitive Case. A number of Latin adjectives also govern Objective Genitives. For example, Vir miser cupidus pecuniae est. A miser is desirous of money. Some special nouns and adjectives in Latin take Objective Genitives which are more difficult to see and to translate. The adjective peritus, -a, - um, meaning “skilled” or “experienced,” is one of these: Nautae sunt periti navium. -
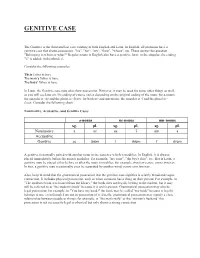
Genitive Case
GENITIVE CASE The Genitive is the third and last case existing in both English and Latin. In English, all pronouns have a genitive case that shows possession: "his", "her", "my", "their", "whose", etc. These answer the question "Belonging to whom or what?" Regular nouns in English also have a genitive form: in the singular, the ending "'s" is added; in the plural, s'. Consider the following examples: Their father is here. The man's father is here. The boys' father is here. In Latin, the Genitive case may also show possession. However, it may be used for some other things as well, as you will see later on. It's ending of course varies depending on the original ending of the noun: for a-nouns, the singular is -ae and the plural is -ārum; for both us- and um-nouns, the singular is -ī and the plural is - ōrum. Consider the following chart: Nominative, Accusative, and Genitive Cases a-nouns us-nouns um-nouns sg. pl. sg. pl. sg. pl. Nominative a ae us ī um a Accusative Genitive ae ārum ī ōrum ī ōrum A genitive is normally paired with another noun in the sentence which it modifies. In English, it is always placed immediately before the noun it modifies: for example, "my soup", "the boy's shirt", etc. But in Latin, a genitive may be placed either before or after the noun it modifies: for example, feminae panes, panes feminae. In fact, a genitive may occasionally even be separated by another word: panes sunt feminae. Also, keep in mind that the grammatical possession that the genitive case signifies is a fairly broad and vague connection. -

SPLIT-ERGATIVITY in HITTITE Petra Goedegebuure (University of Chicago)
Published in: Zeitschrift für Assyriologie und vorderasiatische Archäologie. Volume 102, Issue 2, Pages 270–303, ISSN (Online) 1613-1150, ISSN (Print) 0084-5299, DOI: 10.1515/za- 2012-0015, January 2013 1 SPLIT-ERGATIVITY IN HITTITE Petra Goedegebuure (University of Chicago) “it is possible that all languages show ergativity on some level” (McGregor 2009, 482) 1. Introduction2 As a highly heterogeneous phenomenon ergativity remains a conundrum for linguistic theory. The ergative case has been treated as a structural case, an inherent/lexical case, or rather as a mix (Butt 2006). Split-ergativity is thought to arise as an epiphenomenon, as ‘collateral damage’ of diachronic change after reinterpretation of passive constructions with instrumentals (Dixon 1994) or through reanalysis of transitive null-subject clauses with inanimate instrumentals (Garrett 1990b). Alternatively, case assignment and therefore also split-ergativity ultimately depends on synchronic structural properties of the clause (Merchant 2006). It has been claimed that only 25% of the world’s languages shows ergativity (Van de Visser 2006), or that “all languages show ergativity on some level” (McGregor 2009, 482). Irrespective of the correct ratio, split-ergativity seems to be the norm among languages that show ergativity. When the ergative split is based on semantic features of noun phrases, it is generally assumed that animacy plays a major role. Silverstein (1976) has shown that pronouns and nouns can be hierarchically arranged based on semantic features such as person, number, or grammatical gender. The strength of this hierarchy is that if agent marking is attested for the first time at a certain point in the hierarchy, all nominals lower in the hierarchy will carry agent marking as well. -

AN INTRODUCTORY GRAMMAR of OLD ENGLISH Medieval and Renaissance Texts and Studies
AN INTRODUCTORY GRAMMAR OF OLD ENGLISH MEDievaL AND Renaissance Texts anD STUDies VOLUME 463 MRTS TEXTS FOR TEACHING VOLUme 8 An Introductory Grammar of Old English with an Anthology of Readings by R. D. Fulk Tempe, Arizona 2014 © Copyright 2020 R. D. Fulk This book was originally published in 2014 by the Arizona Center for Medieval and Renaissance Studies at Arizona State University, Tempe Arizona. When the book went out of print, the press kindly allowed the copyright to revert to the author, so that this corrected reprint could be made freely available as an Open Access book. TABLE OF CONTENTS PREFACE viii ABBREVIATIONS ix WORKS CITED xi I. GRAMMAR INTRODUCTION (§§1–8) 3 CHAP. I (§§9–24) Phonology and Orthography 8 CHAP. II (§§25–31) Grammatical Gender • Case Functions • Masculine a-Stems • Anglo-Frisian Brightening and Restoration of a 16 CHAP. III (§§32–8) Neuter a-Stems • Uses of Demonstratives • Dual-Case Prepositions • Strong and Weak Verbs • First and Second Person Pronouns 21 CHAP. IV (§§39–45) ō-Stems • Third Person and Reflexive Pronouns • Verbal Rection • Subjunctive Mood 26 CHAP. V (§§46–53) Weak Nouns • Tense and Aspect • Forms of bēon 31 CHAP. VI (§§54–8) Strong and Weak Adjectives • Infinitives 35 CHAP. VII (§§59–66) Numerals • Demonstrative þēs • Breaking • Final Fricatives • Degemination • Impersonal Verbs 40 CHAP. VIII (§§67–72) West Germanic Consonant Gemination and Loss of j • wa-, wō-, ja-, and jō-Stem Nouns • Dipthongization by Initial Palatal Consonants 44 CHAP. IX (§§73–8) Proto-Germanic e before i and j • Front Mutation • hwā • Verb-Second Syntax 48 CHAP. -

Higher-Order Grammatical Features in Multilingual BERT Isabel Papadimitriou Ethan A
Deep Subjecthood: Higher-Order Grammatical Features in Multilingual BERT Isabel Papadimitriou Ethan A. Chi Stanford University Stanford University [email protected] [email protected] Richard Futrell Kyle Mahowald University of California, Irvine University of California, Santa Barbara [email protected] [email protected] Abstract We investigate how Multilingual BERT (mBERT) encodes grammar by examining how the high-order grammatical feature of morphosyntactic alignment (how different languages define what counts as a “subject”) is manifested across the embedding spaces of different languages. To understand if and how morphosyntactic alignment affects contextual embedding spaces, we train classifiers to recover the subjecthood of mBERT embeddings in transitive sentences (which do not contain overt information about morphosyntactic alignment) and then evaluate Figure 1: Top: Illustration of the difference between them zero-shot on intransitive sentences alignment systems. A (for agent) is notation used for (where subjecthood classification depends on the transitive subject, and O for the transitive ob- alignment), within and across languages. We ject:“The lawyer chased the dog.” S denotes the find that the resulting classifier distributions intransitive subject: “The lawyer laughed.” The blue reflect the morphosyntactic alignment of their circle indicates which roles are marked as “subject” in training languages. Our results demonstrate each system. that mBERT representations are influenced by Bottom: Illustration of the training and test process. high-level grammatical features that are not We train a classifier to distinguish A from O arguments manifested in any one input sentence, and that using the BERT contextual embeddings, and test the this is robust across languages. Further ex- classifier’s behavior on intransitive subjects (S). -

Russian Case Morphology and the Syntactic Categories David Pesetsky (MIT)1 • Terminology: I Will Use the Abbreviations NGEN, DNOM, VACC, PDAT, Etc
Russian case morphology and the syntactic categories David Pesetsky (MIT)1 • Terminology: I will use the abbreviations NGEN, DNOM, VACC, PDAT, etc. to remind us of the traditional names for the cases whose actual nature is simply N, D, V, and 1. Introduction (types of) P. The case-name suffixes to these designations are thus present merely for our convenience. • Case morphology: Russian nouns, adjectives, numerals and demonstratives bear case Genitive: The most unusual aspect of the proposal will be the treatment of genitive as suffixes. The shape of a given case suffix is determined by two factors: N -- with which I will begin the discussion in the next section. 1. its morphological environment (properties of the stem to which the suffix attaches; e.g. declension class, gender, animacy, number) ; and • Syntax: The treatment of case as in (1) will depend on two ideas that are novel in the context of a syntax based on external and internal Merge, but are also revivals of well- 2. its syntactic environment. known older proposals, as well as a third important concept: The traditional cross-classification of case suffixes by declension-class and by case- name (nominative, genitive, etc.) reflects these two factors. 1. Morphology assignment: When [or a projection of ] merges with and assigns an affix, the affix is copied α α β α • Specialness of the standard case names: Traditionally, the cases are called by onto β and realized on the (accessible) lexical items dominated by β. special names (nominative, genitive, etc.) not used outside the description of case- systems. The specialness of case terminology reflects what looks like a complex This proposal revives the notion of case assignment (Vergnaud (2006); Rouveret & relation between syntactic environment and choice of case suffix.