System Automation for Z/OS: User S Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Z/OS ISPF Services Guide COMMAND NAME
z/OS 2.4 ISPF Services Guide IBM SC19-3626-40 Note Before using this information and the product it supports, read the information in “Notices” on page 399. This edition applies to Version 2 Release 4 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2021-06-22 © Copyright International Business Machines Corporation 1980, 2021. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Figures................................................................................................................ xv Tables................................................................................................................xvii Preface...............................................................................................................xix Who should use this document?............................................................................................................... xix What is in this document?......................................................................................................................... xix How to read the syntax diagrams..............................................................................................................xix z/OS information...............................................................................................xxiii How to send your comments to IBM................................................................... -

Introduction to Mainframe Networking TCP/IP Problem Determination
z/OS Basic Skills Information Center Networking on z/OS z/OS Basic Skills Information Center Networking on z/OS Note Before using this information and the product it supports, read the information in “Notices” on page 251. This edition applies to z/OS (product number 5694-A01). We appreciate your comments about this publication. Comment on specific errors or omissions, accuracy, organization, subject matter, or completeness of this book. The comments you send should pertain to only the information in this manual or product and the way in which the information is presented. For technical questions and information about products and prices, please contact your IBM branch office, your IBM business partner, or your authorized remarketer. When you send comments to IBM, you grant IBM a nonexclusive right to use or distribute your comments in any way it believes appropriate without incurring any obligation to you. IBM or any other organizations will only use the personal information that you supply to contact you about the issues that you state on this form. Send your comments through this web site: http://publib.boulder.ibm.com/infocenter/zoslnctr/v1r7/index.jsp?topic=/com.ibm.zcontact.doc/webqs.html © Copyright IBM Corporation 2006, 2010. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Before you begin the topic about Coupling channels ...........40 networking on z/OS .........vii Open Systems Adapter (OSA) .......40 HiperSockets ..............46 The I/O cage ..............48 Part 1. Introduction to networking on the mainframe...........1 Chapter 4. Sample network configuration ............49 Chapter 1. -

Acrobat Distiller, Job 2
A BRIEF HISTORY OF THE IBM ES/9000, SYSTEM/390 AND zSERIES 1990 IBM makes its most comprehensive product announcement in 25 years by introducing the System/390 family consisting of 18 Enterprise System/9000 processors ranging from midrange computers for office environments to the most powerful computers IBM has ever offered. Featuring enhanced function and capability to manage information systems, the System/390 provides increased processing power, better network management, improved communication among multivendor systems and the Enterprise System/9000 processors. In many cases, customers currently using IBM Enterprise System/3090 systems can easily upgrade their systems to System/390 processors. Other 1990 announcements include: several networking products to make it easier for customers to use their midrange, desktop and System/390 computers to communicate with non-IBM computers. 1991 IBM unveils seven new Enterprise System/9000 processors and operating system software — Advanced Interactive Executive/Enterprise System Architecture (AIX/ESA) — for the System/390 family. AIX/ESA is a further step in IBM’s implementation of open-systems computing across its product line and is based on UNIX and the Open Software Foundation’s OSF/1 standards. The company begins shipping in volume and on schedule two top-of-the-line ES/9000 models that were announced in September 1990. IBM Japan says it will supply Enterprise System/9000 processors and operating system software to Mitsubishi Electric Corp. for remarketing. The agreement marks the first time IBM has sold large processors as an original equipment manufacturer for resale. 1992 IBM introduces two entry-level Enterprise System/9000 processors and ships five new Enterprise System/9000 water-cooled processors — Models 520, 640, 660, 740 and 860 — one-to-four months ahead of schedule. -

TSO/E Programming Guide
z/OS Version 2 Release 3 TSO/E Programming Guide IBM SA32-0981-30 Note Before using this information and the product it supports, read the information in “Notices” on page 137. This edition applies to Version 2 Release 3 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2019-02-16 © Copyright International Business Machines Corporation 1988, 2017. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents List of Figures....................................................................................................... ix List of Tables........................................................................................................ xi About this document...........................................................................................xiii Who should use this document.................................................................................................................xiii How this document is organized............................................................................................................... xiii How to use this document.........................................................................................................................xiii Where to find more information................................................................................................................ xiii How to send your comments to IBM......................................................................xv -

IBM Zenterprise BC12 (Zbc12) Enabling Enterprises of All Sizes to Build a Better Customer Experience with IBM Z Systems
IBM Systems and Technology Data Sheet IBM zEnterprise BC12 (zBC12) Enabling enterprises of all sizes to build a better customer experience with IBM z Systems Organizations around the world are recognizing the increasing role that Highlights technology plays in driving change as they shift investments from infra- structure maintenance towards new projects, such as cloud, data analytics ●● ●●Delivers increased performance, flexibility and mobile applications. To remain competitive, they must constantly and scale in a lower cost package adapt and respond with increased speed to deliver new services through ●● ●●Helps save money through consolidation multiple channels to customers, partners and employees. To capitalize on Linux® and an efficient cloud delivery on this opportunity, organizations must be able to tap into their valuable model data and energize applications without going over budget while keeping ●● ●●Enables workloads to be deployed where everything protected and secure to reduce organizational and reputation they run best and cost less with proven risk. This requires an optimized infrastructure that is integrated, agile, hybrid computing trusted and secure. ●● ●●Lets you secure it all with confidence on a trusted and resilient infrastructure The newest member of the IBM® zEnterprise® System family is the IBM zEnterprise BC12 (zBC12). Designed as an entry point for enterprise computing it embodies the same innovation and value, flexible growth options, industry-leading virtualization, trusted resiliency, secure cloud, enterprise mobility and operational analytics capabilities as the massively scalable IBM zEnterprise EC12. The zBC12 delivers a lower and more granular cost structure with significant improvements in pack- aging, performance and total system scalability over prior generations. -

Rising IBM Mainframe Software Costs
Rising IBM Mainframe Software Costs By Kim A. Eckert, Certified IT Architect Rising IBM mainframe software costs started getting the attention of high level executives some years ago. This was partially due to realizing the software inventories analysis was inefficient and limited. In addition, a third party company was hired to review IBM Strategic Outsourcing (SO) account’s inventory. In other words, IBM was paying "green" dollars to save "blue" dollars! In order for the team to become competitive and provide extra value to our Integrated Technology Delivery (ITD) accounts, I architected an automated system that merged data from several sources and made it easy for the technical support teams to verify the inventory. Once the reports were produced, my team would analyze the data and make recommendations for cost take out opportunities. There were several issues surrounding software licensing and validation: 1. IBM only had tools that would report on what was installed on a customer’s machine then that output would be matched up to what was actually licensed. This approach had benefits as in ensuring they are paying for what they use, but did not do the opposite - ensuring they are actually using what they are paying for. 2. The only place to find where a product was superseded by another was either Announcement letters or the Dawn report web page. The Dawn report lists all monthly license type software and their replacement if available. For example, it would show 5647-A01 OS/390 is replaced by 5694-A01 z/OS. 3. End of Support information was only available through Announcement letters or the Lifecycle Support web page. -

Oracle® Database Gateway for APPC Installation and Configuration Guide
Oracle® Database Gateway for APPC Installation and Configuration Guide 19c for IBM AIX on POWER Systems (64-Bit), Linux x86-64, Oracle Solaris on SPARC (64-Bit), and HP- UX Itanium F18241-01 April 2019 Oracle Database Gateway for APPC Installation and Configuration Guide, 19c for IBM AIX on POWER Systems (64-Bit), Linux x86-64, Oracle Solaris on SPARC (64-Bit), and HP-UX Itanium F18241-01 Copyright © 2002, 2019, Oracle and/or its affiliates. All rights reserved. Primary Author: Rhonda Day Contributing Authors: Vira Goorah, Govind Lakkoju, Peter Wong, Juan Pablo Ahues-Vasquez, Peter Castro, Charles Benet This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. -

Audit Report No.: 2007-DP-0004
Issue Date February 22, 2007 Audit Report Number 2007-DP-0004 TO: Lisa Schlosser, Chief Information Officer, Q Joseph A. Neurauter, Chief Procurement Officer, N Keith A. Nelson, Assistant Secretary, Administration, A FROM: Hanh Do, Director, Information Systems Audit Division, GAA SUBJECT: Fiscal Year 2006 Review of Information Systems Controls in Support of the Financial Statements Audit HIGHLIGHTS What We Audited and Why We reviewed general and application controls for selected information systems to assess management controls over HUD’s computing environments as part of the Office of Inspector General’s (OIG) audit of the U.S. Department of Housing and Urban Development’s (HUD) financial statements for fiscal year 2006 under the Chief Financial Officer’s Act of 1990. What We Found HUD did not ensure that its general and application controls over its financial systems conformed to federal requirements and guidelines. Proper configuration management controls for software and document changes are not always employed, and access controls and support for the IBM mainframe operating system console are inadequate. Physical security controls over computing operations facilities are weak, and personnel security practices continue to pose the risk of unauthorized access to HUD systems. As a result, HUD’s financial systems are at risk of compromise. What We Recommend We recommend that the chief information officer, chief procurement officer, and assistant secretary for the Office of Administration ensure that Office of Management and Budget requirements, Federal Information Security Management Act requirements, National Institute of Standards and Technology guidelines, and HUD’s own internal policies and procedures are implemented. For each recommendation without a management decision, please respond and provide status reports in accordance with HUD Handbook 2000.06, REV-3. -
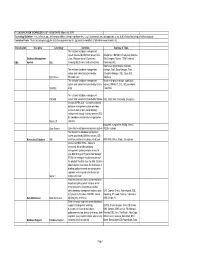
TECHNOLOGY LIST - ISSUE DATE: March 18, 2019 Technology Definition: a Set of Knowledge, Skills And/Or Abilities, Taking a Significant Time (E.G
IT CLASSIFICATION TECHNOLOGY LIST - ISSUE DATE: March 18, 2019 Technology Definition: A set of knowledge, skills and/or abilities, taking a significant time (e.g. 6 months) to learn, and applicable to the defined classification specification assigned. Example of Tools: These are examples only for illustration purposes and are not meant to constitute a full and/or comprehensive list. Classification Discipline Technology Definition Example of Tools The relational database management system provided by IBM that runs on Unix, Omegamon, IBM Admin Tools, Log Analyzer, Database Management Linux, Windows and z/OS platforms DB2 Compare, Nsynch, TSM, Universal DBA System DB2 including DB2 Connect and related tools Command, SQL SQL Server Mgmt Studio, Red Gate, The relational database management Vantage, Tivoli, Snap Manager, Toad, system and related tools provided by Enterprise Manager, SQL, Azure SQL SQL Server Microsoft Corp Database The relational database management Oracle enterprise manager, application system and related tools provided by Oracle express, RMAN, PL SQL, SQL developer, ORACLE Corp Toad, SQL The relational database management SYBASE system and related tools provided by Sybase ASE, OEM, RAC, Partioning, Encryption Cincom SUPRA SQL – Cincom's relational database management system provides access to data in open and proprietary environments through industry-standard SQL for standalone and client/server application Supra 2.X solutions. phpadmin, mysqladmin, MySql, Vertica, Open Source Open Source database management system SQLite, Hadoop The hierarchical database management system provided by IBM that runs on z/OS Hierarchical Database IMS mainframe platform including related tools BMC IMS Utilities, Strobe, Omegamon Cincom SUPRA® PDM – Cincom's networked, hierarchical database management system provides access to your data through a Physical Data Manager (PDM) that manages the data structures of the physical files that store the data. -

Computer Performance Evaluation Users Group (CPEUG)
COMPUTER SCIENCE & TECHNOLOGY: National Bureau of Standards Library, E-01 Admin. Bidg. OCT 1 1981 19105^1 QC / 00 COMPUTER PERFORMANCE EVALUATION USERS GROUP CPEUG 13th Meeting NBS Special Publication 500-18 U.S. DEPARTMENT OF COMMERCE National Bureau of Standards 3-18 NATIONAL BUREAU OF STANDARDS The National Bureau of Standards^ was established by an act of Congress March 3, 1901. The Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research and provides: (1) a basis for the Nation's physical measurement system, (2) scientific and technological services for industry and government, (3) a technical basis for equity in trade, and (4) technical services to pro- mote public safety. The Bureau consists of the Institute for Basic Standards, the Institute for Materials Research, the Institute for Applied Technology, the Institute for Computer Sciences and Technology, the Office for Information Programs, and the Office of Experimental Technology Incentives Program. THE INSTITUTE FOR BASIC STANDARDS provides the central basis within the United States of a complete and consist- ent system of physical measurement; coordinates that system with measurement systems of other nations; and furnishes essen- tial services leading to accurate and uniform physical measurements throughout the Nation's scientific community, industry, and commerce. The Institute consists of the Office of Measurement Services, and the following -

Print Services Facility for Z/OS Version 4, Release 6.0
Print Services Facility for z/OS Version 4, Release 6.0 Introduction IBM G550-0430-05 Note Before using this information and the product it supports, read the information in “Notices” on page 31. This edition applies to the IBM Print Services Facility Version 4 Release 6 Modification 0 for z/OS, Program Number 5655- M32, and to all subsequent releases and modifications until otherwise indicated in new editions. This edition replaces G550-0430-04. © Copyright International Business Machines Corporation 1999, 2017. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents List of Figures........................................................................................................ v List of Tables........................................................................................................vii About this publication...........................................................................................ix Who should read this publication............................................................................................................... ix How this publication is organized............................................................................................................... ix Related information.....................................................................................................................................ix How to send your comments to IBM.......................................................................xi -

Egyptian 1967
Southern Illinois University Carbondale OpenSIUC August 1967 Daily Egyptian 1967 8-11-1967 The aiD ly Egyptian, August 11, 1967 The aiD ly Egyptian Staff Follow this and additional works at: http://opensiuc.lib.siu.edu/de_August1967 Volume 48, Issue 198 Recommended Citation , . "The aiD ly Egyptian, August 11, 1967." (Aug 1967). This Article is brought to you for free and open access by the Daily Egyptian 1967 at OpenSIUC. It has been accepted for inclusion in August 1967 by an authorized administrator of OpenSIUC. For more information, please contact [email protected]. Student Response Computer System - ~ Installed in Lawson Students taking classes in could by used In a lecture when Lawson 121 tbis fall will find a test is not being given, a unique ~l of seven buttons Winsor said. at eacb seat-- all pan of a The system at SID, called sop histlcated computer tbe Student Responder System, response s ystem being com is one ot only a few In tbe pleted tbls week. country, Winsor said. Unlque The seven button panel will features of SID's system w!ll have three basic functions witb many variations, said Donald :e t~~o~;~~~~Ho~~:t~~~~~ 1- L. Winsor, assistant pro cbange answers. fessor in audio-visual ser vices and 'director of the pro Cost of tbe project was est ject. imated at between $30,000 and $40,000, Winsor said. The A student will be able to unit Is bUit by General El answer test questions by push ectric and Is be!t}g-thstalled ing one of tbe numbered buttons by Goldberg....K O'Brien· and change his answer by Electrical/ Co mpa n y of simply pushing a Sf correct" C bicago.