Computer Performance Evaluation Users Group (CPEUG)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Z/OS ISPF Services Guide COMMAND NAME
z/OS 2.4 ISPF Services Guide IBM SC19-3626-40 Note Before using this information and the product it supports, read the information in “Notices” on page 399. This edition applies to Version 2 Release 4 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2021-06-22 © Copyright International Business Machines Corporation 1980, 2021. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Figures................................................................................................................ xv Tables................................................................................................................xvii Preface...............................................................................................................xix Who should use this document?............................................................................................................... xix What is in this document?......................................................................................................................... xix How to read the syntax diagrams..............................................................................................................xix z/OS information...............................................................................................xxiii How to send your comments to IBM................................................................... -

A Scalable Provenance Evaluation Strategy
Debugging Large-scale Datalog: A Scalable Provenance Evaluation Strategy DAVID ZHAO, University of Sydney 7 PAVLE SUBOTIĆ, Amazon BERNHARD SCHOLZ, University of Sydney Logic programming languages such as Datalog have become popular as Domain Specific Languages (DSLs) for solving large-scale, real-world problems, in particular, static program analysis and network analysis. The logic specifications that model analysis problems process millions of tuples of data and contain hundredsof highly recursive rules. As a result, they are notoriously difficult to debug. While the database community has proposed several data provenance techniques that address the Declarative Debugging Challenge for Databases, in the cases of analysis problems, these state-of-the-art techniques do not scale. In this article, we introduce a novel bottom-up Datalog evaluation strategy for debugging: Our provenance evaluation strategy relies on a new provenance lattice that includes proof annotations and a new fixed-point semantics for semi-naïve evaluation. A debugging query mechanism allows arbitrary provenance queries, constructing partial proof trees of tuples with minimal height. We integrate our technique into Soufflé, a Datalog engine that synthesizes C++ code, and achieve high performance by using specialized parallel data structures. Experiments are conducted with Doop/DaCapo, producing proof annotations for tens of millions of output tuples. We show that our method has a runtime overhead of 1.31× on average while being more flexible than existing state-of-the-art techniques. CCS Concepts: • Software and its engineering → Constraint and logic languages; Software testing and debugging; Additional Key Words and Phrases: Static analysis, datalog, provenance ACM Reference format: David Zhao, Pavle Subotić, and Bernhard Scholz. -

TSO/E Programming Guide
z/OS Version 2 Release 3 TSO/E Programming Guide IBM SA32-0981-30 Note Before using this information and the product it supports, read the information in “Notices” on page 137. This edition applies to Version 2 Release 3 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2019-02-16 © Copyright International Business Machines Corporation 1988, 2017. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents List of Figures....................................................................................................... ix List of Tables........................................................................................................ xi About this document...........................................................................................xiii Who should use this document.................................................................................................................xiii How this document is organized............................................................................................................... xiii How to use this document.........................................................................................................................xiii Where to find more information................................................................................................................ xiii How to send your comments to IBM......................................................................xv -

Implementing a Vau-Based Language with Multiple Evaluation Strategies
Implementing a Vau-based Language With Multiple Evaluation Strategies Logan Kearsley Brigham Young University Introduction Vau expressions can be simply defined as functions which do not evaluate their argument expressions when called, but instead provide access to a reification of the calling environment to explicitly evaluate arguments later, and are a form of statically-scoped fexpr (Shutt, 2010). Control over when and if arguments are evaluated allows vau expressions to be used to simulate any evaluation strategy. Additionally, the ability to choose not to evaluate certain arguments to inspect the syntactic structure of unevaluated arguments allows vau expressions to simulate macros at run-time and to replace many syntactic constructs that otherwise have to be built-in to a language implementation. In principle, this allows for significant simplification of the interpreter for vau expressions; compared to McCarthy's original LISP definition (McCarthy, 1960), vau's eval function removes all references to built-in functions or syntactic forms, and alters function calls to skip argument evaluation and add an implicit env parameter (in real implementations, the name of the environment parameter is customizable in a function definition, rather than being a keyword built-in to the language). McCarthy's Eval Function Vau Eval Function (transformed from the original M-expressions into more familiar s-expressions) (define (eval e a) (define (eval e a) (cond (cond ((atom e) (assoc e a)) ((atom e) (assoc e a)) ((atom (car e)) ((atom (car e)) (cond (eval (cons (assoc (car e) a) ((eq (car e) 'quote) (cadr e)) (cdr e)) ((eq (car e) 'atom) (atom (eval (cadr e) a))) a)) ((eq (car e) 'eq) (eq (eval (cadr e) a) ((eq (caar e) 'vau) (eval (caddr e) a))) (eval (caddar e) ((eq (car e) 'car) (car (eval (cadr e) a))) (cons (cons (cadar e) 'env) ((eq (car e) 'cdr) (cdr (eval (cadr e) a))) (append (pair (cadar e) (cdr e)) ((eq (car e) 'cons) (cons (eval (cadr e) a) a)))))) (eval (caddr e) a))) ((eq (car e) 'cond) (evcon. -

Comparative Studies of Programming Languages; Course Lecture Notes
Comparative Studies of Programming Languages, COMP6411 Lecture Notes, Revision 1.9 Joey Paquet Serguei A. Mokhov (Eds.) August 5, 2010 arXiv:1007.2123v6 [cs.PL] 4 Aug 2010 2 Preface Lecture notes for the Comparative Studies of Programming Languages course, COMP6411, taught at the Department of Computer Science and Software Engineering, Faculty of Engineering and Computer Science, Concordia University, Montreal, QC, Canada. These notes include a compiled book of primarily related articles from the Wikipedia, the Free Encyclopedia [24], as well as Comparative Programming Languages book [7] and other resources, including our own. The original notes were compiled by Dr. Paquet [14] 3 4 Contents 1 Brief History and Genealogy of Programming Languages 7 1.1 Introduction . 7 1.1.1 Subreferences . 7 1.2 History . 7 1.2.1 Pre-computer era . 7 1.2.2 Subreferences . 8 1.2.3 Early computer era . 8 1.2.4 Subreferences . 8 1.2.5 Modern/Structured programming languages . 9 1.3 References . 19 2 Programming Paradigms 21 2.1 Introduction . 21 2.2 History . 21 2.2.1 Low-level: binary, assembly . 21 2.2.2 Procedural programming . 22 2.2.3 Object-oriented programming . 23 2.2.4 Declarative programming . 27 3 Program Evaluation 33 3.1 Program analysis and translation phases . 33 3.1.1 Front end . 33 3.1.2 Back end . 34 3.2 Compilation vs. interpretation . 34 3.2.1 Compilation . 34 3.2.2 Interpretation . 36 3.2.3 Subreferences . 37 3.3 Type System . 38 3.3.1 Type checking . 38 3.4 Memory management . -
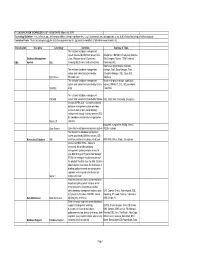
TECHNOLOGY LIST - ISSUE DATE: March 18, 2019 Technology Definition: a Set of Knowledge, Skills And/Or Abilities, Taking a Significant Time (E.G
IT CLASSIFICATION TECHNOLOGY LIST - ISSUE DATE: March 18, 2019 Technology Definition: A set of knowledge, skills and/or abilities, taking a significant time (e.g. 6 months) to learn, and applicable to the defined classification specification assigned. Example of Tools: These are examples only for illustration purposes and are not meant to constitute a full and/or comprehensive list. Classification Discipline Technology Definition Example of Tools The relational database management system provided by IBM that runs on Unix, Omegamon, IBM Admin Tools, Log Analyzer, Database Management Linux, Windows and z/OS platforms DB2 Compare, Nsynch, TSM, Universal DBA System DB2 including DB2 Connect and related tools Command, SQL SQL Server Mgmt Studio, Red Gate, The relational database management Vantage, Tivoli, Snap Manager, Toad, system and related tools provided by Enterprise Manager, SQL, Azure SQL SQL Server Microsoft Corp Database The relational database management Oracle enterprise manager, application system and related tools provided by Oracle express, RMAN, PL SQL, SQL developer, ORACLE Corp Toad, SQL The relational database management SYBASE system and related tools provided by Sybase ASE, OEM, RAC, Partioning, Encryption Cincom SUPRA SQL – Cincom's relational database management system provides access to data in open and proprietary environments through industry-standard SQL for standalone and client/server application Supra 2.X solutions. phpadmin, mysqladmin, MySql, Vertica, Open Source Open Source database management system SQLite, Hadoop The hierarchical database management system provided by IBM that runs on z/OS Hierarchical Database IMS mainframe platform including related tools BMC IMS Utilities, Strobe, Omegamon Cincom SUPRA® PDM – Cincom's networked, hierarchical database management system provides access to your data through a Physical Data Manager (PDM) that manages the data structures of the physical files that store the data. -

Needed Reduction and Spine Strategies for the Lambda Calculus
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector INFORMATION AND COMPUTATION 75, 191-231 (1987) Needed Reduction and Spine Strategies for the Lambda Calculus H. P. BARENDREGT* University of Ngmegen, Nijmegen, The Netherlands J. R. KENNAWAY~ University qf East Anglia, Norwich, United Kingdom J. W. KLOP~ Cenfre for Mathematics and Computer Science, Amsterdam, The Netherlands AND M. R. SLEEP+ University of East Anglia, Norwich, United Kingdom A redex R in a lambda-term M is called needed if in every reduction of M to nor- mal form (some residual of) R is contracted. Among others the following results are proved: 1. R is needed in M iff R is contracted in the leftmost reduction path of M. 2. Let W: MO+ M, + Mz --t .._ reduce redexes R,: M, + M,, ,, and have the property that Vi.3j> i.R, is needed in M,. Then W is normalising, i.e., if M, has a normal form, then Ye is finite and terminates at that normal form. 3. Neededness is an undecidable property, but has several efhciently decidable approximations, various versions of the so-called spine redexes. r 1987 Academic Press. Inc. 1. INTRODUCTION A number of practical programming languages are based on some sugared form of the lambda calculus. Early examples are LISP, McCarthy et al. (1961) and ISWIM, Landin (1966). More recent exemplars include ML (Gordon etal., 1981), Miranda (Turner, 1985), and HOPE (Burstall * Partially supported by the Dutch Parallel Reduction Machine project. t Partially supported by the British ALVEY project. -

Typology of Programming Languages E Evaluation Strategy E
Typology of programming languages e Evaluation strategy E Typology of programming languages Evaluation strategy 1 / 27 Argument passing From a naive point of view (and for strict evaluation), three possible modes: in, out, in-out. But there are different flavors. Val ValConst RefConst Res Ref ValRes Name ALGOL 60 * * Fortran ? ? PL/1 ? ? ALGOL 68 * * Pascal * * C*?? Modula 2 * ? Ada (simple types) * * * Ada (others) ? ? ? ? ? Alphard * * * Typology of programming languages Evaluation strategy 2 / 27 Table of Contents 1 Call by Value 2 Call by Reference 3 Call by Value-Result 4 Call by Name 5 Call by Need 6 Summary 7 Notes on Call-by-sharing Typology of programming languages Evaluation strategy 3 / 27 Call by Value – definition Passing arguments to a function copies the actual value of an argument into the formal parameter of the function. In this case, changes made to the parameter inside the function have no effect on the argument. def foo(val): val = 1 i = 12 foo(i) print (i) Call by value in Python – output: 12 Typology of programming languages Evaluation strategy 4 / 27 Pros & Cons Safer: variables cannot be accidentally modified Copy: variables are copied into formal parameter even for huge data Evaluation before call: resolution of formal parameters must be done before a call I Left-to-right: Java, Common Lisp, Effeil, C#, Forth I Right-to-left: Caml, Pascal I Unspecified: C, C++, Delphi, , Ruby Typology of programming languages Evaluation strategy 5 / 27 Table of Contents 1 Call by Value 2 Call by Reference 3 Call by Value-Result 4 Call by Name 5 Call by Need 6 Summary 7 Notes on Call-by-sharing Typology of programming languages Evaluation strategy 6 / 27 Call by Reference – definition Passing arguments to a function copies the actual address of an argument into the formal parameter. -

HPP) Cooperative Agreement
Hospital Preparedness Program (HPP) Cooperative Agreement FY 12 Budget Period Hospital Preparedness Program (HPP) Performance Measure Manual Guidance for Using the New HPP Performance Measures July 1, 2012 — June 30, 2013 Version: 1.0 — This Page Intentionally Left Blank — U.S. DEPARTMENT OF HEALTH AND HUMAN SERVICES ASSISTANT SECRETARY FOR PREPAREDNESS AND RESPONSE Hospital Preparedness Program (HPP) Performance Measure Manual Guidance for Using the New HPP Performance Measures July 1, 2012 — June 30, 2013 The Hospital Preparedness Program (HPP) Performance Measure Manual, Guidance for Using the New HPP Performance Measures (hereafter referred to as Performance Measure Manual) is a highly iterative document. Subsequent versions will be subject to ongoing updates and changes as reflected in HPP policies and direction. CONTENTS Contents Contents Preface: How to Use This Manual .................................................................................................................. iii Document Organization .................................................................................................................... iii Measures Structure: HPP-PHEP Performance Measures ............................................................................... iv Definitions: HPP Performance Measures ........................................................................................................v Data Element Responses: HPP Performance Measures ..................................................................................v -

Design Patterns for Functional Strategic Programming
Design Patterns for Functional Strategic Programming Ralf Lammel¨ Joost Visser Vrije Universiteit CWI De Boelelaan 1081a P.O. Box 94079 NL-1081 HV Amsterdam 1090 GB Amsterdam The Netherlands The Netherlands [email protected] [email protected] Abstract 1 Introduction We believe that design patterns can be an effective means of con- The notion of a design pattern is well-established in object-oriented solidating and communicating program construction expertise for programming. A pattern systematically names, motivates, and ex- functional programming, just as they have proven to be in object- plains a common design structure that addresses a certain group of oriented programming. The emergence of combinator libraries that recurring program construction problems. Essential ingredients in develop a specific domain or programming idiom has intensified, a pattern are its applicability conditions, the trade-offs of applying rather than reduced, the need for design patterns. it, and sample code that demonstrates its application. In previous work, we introduced the fundamentals and a supporting We contend that design patterns can be an effective means of con- combinator library for functional strategic programming. This is solidating and communicating program construction expertise for an idiom for (general purpose) generic programming based on the functional programming just as they have proven to be in object- notion of a functional strategy: a first-class generic function that oriented programming. One might suppose that the powerful ab- can not only be applied to terms of any type, but which also allows straction mechanisms of functional programming obviate the need generic traversal into subterms and can be customised with type- for design patterns, since many pieces of program construction specific behaviour. -

A Guide to Evaluation in Health Research Prepared By: Sarah
A Guide to Evaluation in Health Research Prepared by: Sarah Bowen, PhD Associate Professor Department of Public Health Sciences, School of Public Health University of Alberta [email protected] INTRODUCTION……..……… ...................................................................................... 1 Purpose and Objectives of Module ............................................................................... 1 Scope and Limitations of the Module ............................................................................ 1 How this Module is Organized……………. ................................................................. 2 Case Studies Used in the Module ................................................................................ 3 SECTION 1: EVALUATION: A BRIEF OVERVIEW ..................................................... 4 Similarities and Differences between Research and Evaluation ................................... 4 Why is it Important that Researchers Understand How to Conduct an Evaluation? ...... 5 Defining Evaluation..……. ............................................................................................ 6 Common Misconceptions about Evaluation .................................................................. 6 Evaluation Approaches…. ............................................................................................ 8 SECTION 2: GETTING STARTED ............................................................................. 11 Step 1: Consider the Purpose(s) of the Evaluation .................................................. -

Resource Measurement Facility User's Guide
z/OS Version 2 Release 3 Resource Measurement Facility User's Guide IBM SC34-2664-30 Note Before using this information and the product it supports, read the information in “Notices” on page 381. This edition applies to Version 2 Release 3 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2019-02-16 © Copyright International Business Machines Corporation 1990, 2017. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents List of Figures..................................................................................................... xiii List of Tables........................................................................................................xv About this document.......................................................................................... xvii Who should use this document................................................................................................................xvii How this document is organized.............................................................................................................. xvii z/OS information...................................................................................................................................... xviii How to read syntax diagrams.................................................................................................................. xviii Symbols................................................................................................................................................xix