Stable-V20.07
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Trident Development Framework
Trident Development Framework Tom MacAdam Jim Covill Kathleen Svendsen Martec Limited Prepared By: Martec Limited 1800 Brunswick Street, Suite 400 Halifax, Nova Scotia B3J 3J8 Canada Contractor's Document Number: TR-14-85 (Control Number: 14.28008.1110) Contract Project Manager: David Whitehouse, 902-425-5101 PWGSC Contract Number: W7707-145679/001/HAL CSA: Malcolm Smith, Warship Performance, 902-426-3100 x383 The scientific or technical validity of this Contract Report is entirely the responsibility of the Contractor and the contents do not necessarily have the approval or endorsement of the Department of National Defence of Canada. Contract Report DRDC-RDDC-2014-C328 December 2014 © Her Majesty the Queen in Right of Canada, as represented by the Minister of National Defence, 2014 © Sa Majesté la Reine (en droit du Canada), telle que représentée par le ministre de la Défense nationale, 2014 Working together for a safer world Trident Development Framework Martec Technical Report # TR-14-85 Control Number: 14.28008.1110 December 2014 Prepared for: DRDC Atlantic 9 Grove Street Dartmouth, Nova Scotia B2Y 3Z7 Martec Limited tel. 902.425.5101 1888 Brunswick Street, Suite 400 fax. 902.421.1923 Halifax, Nova Scotia B3J 3J8 Canada email. [email protected] www.martec.com REVISION CONTROL REVISION REVISION DATE Draft Release 0.1 10 Nov 2014 Draft Release 0.2 2 Dec 2014 Final Release 10 Dec 2014 PROPRIETARY NOTICE This report was prepared under Contract W7707-145679/001/HAL, Defence R&D Canada (DRDC) Atlantic and contains information proprietary to Martec Limited. The information contained herein may be used and/or further developed by DRDC Atlantic for their purposes only. -

Understanding the Attack Surface and Attack Resilience of Project Spartan’S (Edge) New Edgehtml Rendering Engine
Understanding the Attack Surface and Attack Resilience of Project Spartan’s (Edge) New EdgeHTML Rendering Engine Mark Vincent Yason IBM X-Force Advanced Research yasonm[at]ph[dot]ibm[dot]com @MarkYason [v2] © 2015 IBM Corporation Agenda . Overview . Attack Surface . Exploit Mitigations . Conclusion © 2015 IBM Corporation 2 Notes . Detailed whitepaper is available . All information is based on Microsoft Edge running on 64-bit Windows 10 build 10240 (edgehtml.dll version 11.0.10240.16384) © 2015 IBM Corporation 3 Overview © 2015 IBM Corporation Overview > EdgeHTML Rendering Engine © 2015 IBM Corporation 5 Overview > EdgeHTML Attack Surface Map & Exploit Mitigations © 2015 IBM Corporation 6 Overview > Initial Recon: MSHTML and EdgeHTML . EdgeHTML is forked from Trident (MSHTML) . Problem: Quickly identify major code changes (features/functionalities) from MSHTML to EdgeHTML . One option: Diff class names and namespaces © 2015 IBM Corporation 7 Overview > Initial Recon: Diffing MSHTML and EdgeHTML (Method) © 2015 IBM Corporation 8 Overview > Initial Recon: Diffing MSHTML and EdgeHTML (Examples) . Suggests change in image support: . Suggests new DOM object types: © 2015 IBM Corporation 9 Overview > Initial Recon: Diffing MSHTML and EdgeHTML (Examples) . Suggests ported code from another rendering engine (Blink) for Web Audio support: © 2015 IBM Corporation 10 Overview > Initial Recon: Diffing MSHTML and EdgeHTML (Notes) . Further analysis needed –Renamed class/namespace results into a new namespace plus a deleted namespace . Requires availability -

Nessus 8.3 User Guide
Nessus 8.3.x User Guide Last Updated: September 24, 2021 Table of Contents Welcome to Nessus 8.3.x 12 Get Started with Nessus 15 Navigate Nessus 16 System Requirements 17 Hardware Requirements 18 Software Requirements 22 Customize SELinux Enforcing Mode Policies 25 Licensing Requirements 26 Deployment Considerations 27 Host-Based Firewalls 28 IPv6 Support 29 Virtual Machines 30 Antivirus Software 31 Security Warnings 32 Certificates and Certificate Authorities 33 Custom SSL Server Certificates 35 Create a New Server Certificate and CA Certificate 37 Upload a Custom Server Certificate and CA Certificate 39 Trust a Custom CA 41 Create SSL Client Certificates for Login 43 Nessus Manager Certificates and Nessus Agent 46 Install Nessus 48 Copyright © 2021 Tenable, Inc. All rights reserved. Tenable, Tenable.io, Tenable Network Security, Nessus, SecurityCenter, SecurityCenter Continuous View and Log Correlation Engine are registered trade- marks of Tenable,Inc. Tenable.sc, Tenable.ot, Lumin, Indegy, Assure, and The Cyber Exposure Company are trademarks of Tenable, Inc. All other products or services are trademarks of their respective Download Nessus 49 Install Nessus 51 Install Nessus on Linux 52 Install Nessus on Windows 54 Install Nessus on Mac OS X 56 Install Nessus Agents 58 Retrieve the Linking Key 59 Install a Nessus Agent on Linux 60 Install a Nessus Agent on Windows 64 Install a Nessus Agent on Mac OS X 70 Upgrade Nessus and Nessus Agents 74 Upgrade Nessus 75 Upgrade from Evaluation 76 Upgrade Nessus on Linux 77 Upgrade Nessus on Windows 78 Upgrade Nessus on Mac OS X 79 Upgrade a Nessus Agent 80 Configure Nessus 86 Install Nessus Home, Professional, or Manager 87 Link to Tenable.io 88 Link to Industrial Security 89 Link to Nessus Manager 90 Managed by Tenable.sc 92 Manage Activation Code 93 Copyright © 2021 Tenable, Inc. -
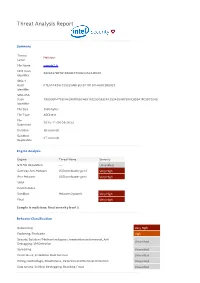
Sample2.Js Malware Summary
Threat Analysis Report Summary Threat Malicious Level File Name sample2.js MD5 Hash 580E637B97B16698CC750B445223D5C0 Identifier SHA-1 Hash 07E507426F72522DABFECF91181D7F64DC3B8D23 Identifier SHA-256 Hash 790999F47B2FA4396FF6B0A6916E295D832A12B3495A87590C859A1FE9D73245 Identifier File Size 3586 bytes File Type ASCII text File 2015-11-06 09:26:23 Submitted Duration 38 seconds Sandbox 27 seconds Replication Engine Analysis Engine Threat Name Severity GTI File Reputation --- Unverified Gateway Anti-Malware JS/Downloader.gen.f Very High Anti-Malware JS/Downloader.gen.f Very High YARA Custom Rules Sandbox Malware.Dynamic Very High Final Very High Sample is malicious: f inal severit y level 5 Behavior Classif icat ion Networking Very High Exploiting, Shellcode High Security Solution / Mechanism bypass, termination and removal, Anti Unverified Debugging, VM Detection Spreading Unverified Persistence, Installation Boot Survival Unverified Hiding, Camouflage, Stealthiness, Detection and Removal Protection Unverified Data spying, Sniffing, Keylogging, Ebanking Fraud Unverified Dynamic Analysis Action Severity Malware behavior: networking activities from non-executable file Very High ATTENTION: connection made to a malicious website (see Web/URL Very High reputation for details) Detected suspicious Java Script content High Downloaded data from a webserver Low Modified INTERNET_OPTION_CONNECT_RETRIES: number of times that Low WinInet attempts to resolve and connect to a host Connected to a specific service provider Low Cracks a URL into its component -

The Impact of Operating Systems and Environments on Build Results
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by PolyPublie UNIVERSITÉ DE MONTRÉAL THE IMPACT OF OPERATING SYSTEMS AND ENVIRONMENTS ON BUILD RESULTS MAHDIS ZOLFAGHARINIA DÉPARTEMENT DE GÉNIE INFORMATIQUE ET GÉNIE LOGICIEL ÉCOLE POLYTECHNIQUE DE MONTRÉAL MÉMOIRE PRÉSENTÉ EN VUE DE L’OBTENTION DU DIPLÔME DE MAÎTRISE ÈS SCIENCES APPLIQUÉES (GÉNIE INFORMATIQUE) DÉCEMBRE 2017 c Mahdis Zolfagharinia, 2017. UNIVERSITÉ DE MONTRÉAL ÉCOLE POLYTECHNIQUE DE MONTRÉAL Ce mémoire intitulé : THE IMPACT OF OPERATING SYSTEMS AND ENVIRONMENTS ON BUILD RESULTS présenté par : ZOLFAGHARINIA Mahdis en vue de l’obtention du diplôme de : Maîtrise ès sciences appliquées a été dûment accepté par le jury d’examen constitué de : M. QUINTERO Alejandro, Doctorat, président M. ADAMS Bram, Doctorat, membre et directeur de recherche M. GUÉHÉNEUC Yann-Gaël, Doctorat, membre et codirecteur de recherche M. KHOMH Foutse, Ph. D., membre iii DEDICATION To my grandma, Who always inspired me to achieve my goals And to my parents, Who always support and encourage me iv ACKNOWLEDGEMENTS I believe changing my program to a research based master was one of the best decisions for my academic life. It gave me the opportunity to meet new people and attend amazing conferences, which all are now part of this thesis. A especial thanks to my supervisor, Dr.Bram Adams for his kind guidance, great support and boundless patience all along the way. I learned a lot from working with a humble, talented and hard working supervisor like you. I would also like to thank my co-supervisor Dr.Yann-Gaël Guéhéneuc for his kindness, mo- tivation and immense knowledge. -

Automated Malware Analysis Report For
ID: 310931 Sample Name: 44S5D444F55G8222Y55UU44S4S.vbs Cookbook: default.jbs Time: 07:32:12 Date: 07/11/2020 Version: 31.0.0 Red Diamond Table of Contents Table of Contents 2 Analysis Report 44S5D444F55G8222Y55UU44S4S.vbs 4 Overview 4 General Information 4 Detection 4 Signatures 4 Classification 4 Startup 4 Malware Configuration 4 Yara Overview 4 Sigma Overview 4 Signature Overview 4 AV Detection: 5 Data Obfuscation: 5 Persistence and Installation Behavior: 5 Malware Analysis System Evasion: 5 HIPS / PFW / Operating System Protection Evasion: 5 Mitre Att&ck Matrix 5 Behavior Graph 6 Screenshots 6 Thumbnails 6 Antivirus, Machine Learning and Genetic Malware Detection 7 Initial Sample 7 Dropped Files 7 Unpacked PE Files 7 Domains 7 URLs 7 Domains and IPs 8 Contacted Domains 8 Contacted URLs 8 URLs from Memory and Binaries 8 Contacted IPs 8 Public 9 General Information 9 Simulations 10 Behavior and APIs 10 Joe Sandbox View / Context 10 IPs 10 Domains 10 ASN 10 JA3 Fingerprints 11 Dropped Files 11 Created / dropped Files 11 Static File Info 11 General 11 File Icon 12 Network Behavior 12 TCP Packets 12 HTTP Request Dependency Graph 12 HTTP Packets 12 Code Manipulations 13 Statistics 13 Behavior 13 System Behavior 14 Analysis Process: wscript.exe PID: 6124 Parent PID: 3388 14 Copyright null 2020 Page 2 of 15 General 14 File Activities 14 File Created 14 File Written 14 Registry Activities 15 Analysis Process: wscript.exe PID: 5560 Parent PID: 6124 15 General 15 File Activities 15 Disassembly 15 Code Analysis 15 Copyright null 2020 Page 3 of -

1.3 Energy Consumption
JAIST Repository https://dspace.jaist.ac.jp/ Comparative analysis of overall energy Title consumption of storage architectures in home media players Author(s) ウィ, クリスティアント Citation Issue Date 2011-09 Type Thesis or Dissertation Text version author URL http://hdl.handle.net/10119/9928 Rights Supervisor: Associate Professor Xavier Defago, 情 Description 報科学研究科, 修士 Japan Advanced Institute of Science and Technology Comparative analysis of overall energy consumption of storage architectures in home media players By Christianto Oeij A thesis submitted to School of Information Science, Japan Advanced Institute of Science and Technology, in partial fulfillment of the requirements for the degree of Master of Information Science Graduate Program in Information Science Written under the direction of Associate Professor Xavier D´efago September, 2011 Comparative analysis of overall energy consumption of storage architectures in home media players By Christianto Oeij (9210202) A thesis submitted to School of Information Science, Japan Advanced Institute of Science and Technology, in partial fulfillment of the requirements for the degree of Master of Information Science Graduate Program in Information Science Written under the direction of Associate Professor Xavier D´efago and approved by Associate Professor Xavier D´efago Professor Mizuhito Ogawa Associate Professor Kiyofumi Tanaka August, 2011 (Submitted) Copyright c 2011 by Christianto Oeij Abstract In home entertainment, reducing energy is highly desirable. Our motivations stem from the important factors like the running cost, noise, heat, and energy consumption from the storage as the main component of it. Home theater PC is a good choice of home entertainment since it can provide high quality video output and be affordable in term of cost. -

Download “The Spy Who Encrypted Me” Case Study
April, 2020 APT41 The Spy Who Encrypted Me Contents APT41 – A spy who steals or a thief who spies ......................................................... 3 The investigation .................................................................................................. 3 The base .......................................................................................................... 4 The toolkit ........................................................................................................ 5 The point of entry .............................................................................................. 6 The initial vector of compromise .......................................................................... 8 Indicators of Compromise .................................................................................... 10 References ......................................................................................................... 11 244 Fifth Avenue, Suite 2035, New York, NY 10001 LIFARS.com (212) 222-7061 [email protected] APT41 – A SPY WHO STEALS OR A THIEF WHO SPIES An advanced persistent threat (“APT”) is, typically, either a nation-state actor and aims at benefiting its state through sabotage, espionage, or industrial espionage; or a cybercriminal and its aims are to steal money through theft, fraud, ransom or blackmail. The Chinese-based threat actor APT41 blurs the lines: known to have run financially- motivated operations against the videogame industry as early as 2012, it got its notoriety in 2013 when -
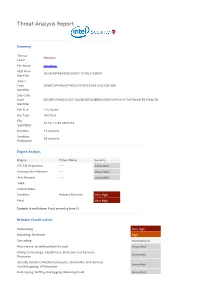
Resume.Js Malware Summary
Threat Analysis Report Summary Threat Malicious Level File Name resume.js MD5 Hash 3823D4BFB62D6D25A2D1101B23129B5A Identifier SHA-1 Hash BF981E3F4D820F7A9C0767DCC09241A301E813B6 Identifier SHA-256 Hash EE2CBF07FA62C05DF732CBD6E53A3E86602EE510EFD01670979008FE61F9A078 Identifier File Size 1163 bytes File Type ASCII text File 2015-11-06 09:25:54 Submitted Duration 43 seconds Sandbox 28 seconds Replication Engine Analysis Engine Threat Name Severity GTI File Reputation --- Unverified Gateway Anti-Malware --- Unverified Anti-Malware --- Unverified YARA Custom Rules Sandbox Malware.Dynamic Very High Final Very High Sample is malicious: f inal severit y level 5 Behavior Classif icat ion Networking Very High Exploiting, Shellcode High Spreading Informational Persistence, Installation Boot Survival Unverified Hiding, Camouflage, Stealthiness, Detection and Removal Unverified Protection Security Solution / Mechanism bypass, termination and removal, Unverified Anti Debugging, VM Detection Data spying, Sniffing, Keylogging, Ebanking Fraud Unverified Dynamic Analysis Action Severity Malware behavior: networking activities from non-executable file Very High ATTENTION: connection made to a malicious website (see Web/URL Very High reputation for details) Detected suspicious Java Script content High Attempted to download an active content from the internet High Connected to a specific service provider Low Modified INTERNET_OPTION_CONNECT_RETRIES: number of times that Low WinInet attempts to resolve and connect to a host Cracks a URL into its component -

April 17, 2018 Minutes
MINUTES CITY COUNCIL MEETING APRIL 17, 2018 CALL TO ORDER – Roll Call and Determination of a Quorum The Parker City Council met in a regular meeting on the above date at Parker City Hall, 5700 E. Parker Road, Parker, Texas, 75002. Mayor Z Marshall called the meeting to order at 7:00 p.m. Councilmembers Scott Levine, Cindy Meyer, Lee Pettle, Cleburne Raney, and Ed Standridge were present. Staff Present: City Administrator Jeff Flanigan, Finance/H.R. Manager Johnna Boyd, City Secretary Patti Scott Grey, City Attorney Brandon Shelby, Fire Chief Mike Sheff, and Police Chief Richard Brooks PLEDGE OF ALLEGIANCE AMERICAN PLEDGE: Terry Lynch led the pledge. TEXAS PLEDGE: Elvis Nelson led the pledge. PUBLIC COMMENTS The City Council invites any person with business before the Council to speak. No formal action may be taken on these items at this meeting. Please keep comments to 3 minutes. None PROCLAMATION Mayor Marshall presented a proclamation, recognizing Southfork Ranch in Parker, Texas, for the 40th year reunion of the TV Show DALLAS and their many outstanding achievements and events, to Forever Resorts Regional Director of Sales and Marketing Janna Timm. The Mayor, City Council, City Staff, and audience applauded. Ms. Timm accepted the proclamation and thanked everyone for their support. CONSENT AGENDA Routine Council business. Consent Agenda is approved by a single majority vote. Items may be removed for open discussion by a request from a Councilmember or member of staff. 1. APPROVAL OF MEETING MINUTES FOR APRIL 3, 2018. [SCOTT GREY] 2. CITY INVESTMENT QUARTERLY REPORT. [MARSHALL] 3. CONSIDERATION AND/OR ANY APPROPRIATE ACTION ON ADVERTISING REQUEST FOR QUALIFICATIONS (RFQs) FOR AUDITOR SERVICES. -

Internet Explorer and Firefox: Web Browser Features Comparision and Their Future
https://doi.org/10.48009/2_iis_2007_478-483 INTERNET EXPLORER AND FIREFOX: WEB BROWSER FEATURES COMPARISION AND THEIR FUTURE Siwat Saibua, Texas A&M University-Kingsville, [email protected] Joon-Yeoul Oh, Texas A&M University-Kingsville, [email protected] Richard A. Aukerman, Texas A&M University-Kingsville, [email protected] ABSTRACT Next to Netscape, which was introduced to the Internet technology is one of the utmost inventions of market in 1998, Mozilla Firefox was released in 2004 our era and has contributed significantly in to compete with IE. The software codes of Firefox distributing and collecting data and information. are in the open source format, and any software Effectiveness and efficiency of the process depends developers around the world can put their own ideas on the performance of the web browser. Internet into this browser. As a result, Firefox’s performance Explorer is the leader of the competitive browser effectiveness and efficiency improved every day and market with Mozzilla Fox as its strongest rival, which gained popularity rapidly. has been and is gaining a substantial level of popularity among internet users. Choosing the 100.00% superlative web browser is a difficult task due to the considerably large selection of browser programs and lack of tangible comparison data. This paper 90.00% describes and compares vital features of Internet Firefox Explorer and Mozzilla Firefox, which represent over 90% of the browser market. The performance of each 80.00% IE browser is evaluated based on the general features, operating system support, browser features, protocol 70.00% support and language support. -

X41 D-SEC Gmbh Dennewartstr
Browser Security White PAPER Final PAPER 2017-09-19 Markus VERVIER, Michele Orrù, Berend-Jan WEVER, Eric Sesterhenn X41 D-SEC GmbH Dennewartstr. 25-27 D-52068 Aachen Amtsgericht Aachen: HRB19989 Browser Security White PAPER Revision History Revision Date Change Editor 1 2017-04-18 Initial Document E. Sesterhenn 2 2017-04-28 Phase 1 M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 3 2017-05-19 Phase 2 M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 4 2017-05-25 Phase 3 M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 5 2017-06-05 First DrAFT M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 6 2017-06-26 Second DrAFT M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 7 2017-07-24 Final DrAFT M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 8 2017-08-25 Final PAPER M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 9 2017-09-19 Public Release M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER X41 D-SEC GmbH PAGE 1 OF 196 Contents 1 ExECUTIVE Summary 7 2 Methodology 10 3 Introduction 12 3.1 Google Chrome . 13 3.2 Microsoft Edge . 14 3.3 Microsoft Internet Explorer (IE) . 16 4 Attack Surface 18 4.1 Supported Standards . 18 4.1.1 WEB TECHNOLOGIES . 18 5 Organizational Security Aspects 21 5.1 Bug Bounties . 21 5.1.1 Google Chrome . 21 5.1.2 Microsoft Edge . 22 5.1.3 Internet Explorer . 22 5.2 Exploit Pricing . 22 5.2.1 ZERODIUM . 23 5.2.2 Pwn2Own .