Application of Next-Generation Sequencing for the Genomic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Differences for Ectopic Versus Eutopic Cells
556 RBMO VOLUME 39 ISSUE 4 2019 ARTICLE Chemosensitivity and chemoresistance in endometriosis – differences for ectopic versus eutopic cells BIOGRAPHY Andres Salumets is Professor of Reproductive Medicine at the University of Tartu, and Scientific Head at the Competence Centre on Health Technologies, Tartu, Estonia. He has been involved in assisted reproduction for 20 years, first as an embryologist and later as a researcher. His major interests are endometriosis, endometrial biology and implantation. Darja Lavogina1,2,*, Külli Samuel1, Arina Lavrits1,3, Alvin Meltsov1, Deniss Sõritsa1,4,5, Ülle Kadastik6, Maire Peters1,4, Ago Rinken2, Andres Salumets1,4,7, 8 KEY MESSAGE Akt/PKB inhibitor GSK690693, CK2 inhibitor ARC-775, MAPK pathway inhibitor sorafenib, proteasome inhibitor bortezomib, and microtubule-depolymerizing toxin MMAE showed higher cytotoxicity in eutopic cells. In contrast, 10 µmol/l of the anthracycline toxin doxorubicin caused cellular death in ectopic cells more effectively than in eutopic cells, underlining the potential of doxorubicin in endometriosis research. ABSTRACT Research question: Endometriosis is a common gynaecological disease defined by the presence of endometrium-like tissue outside the uterus. This complex disease, often accompanied by severe pain and infertility, causes a significant medical and socioeconomic burden; hence, novel strategies are being sought for the treatment of endometriosis. Here, we set out to explore the cytotoxic effects of a panel of compounds to find toxins with different efficiency in eutopic versus ectopic cells, thus highlighting alterations in the corresponding molecular pathways. Design: The effect on cellular viability of 14 compounds was established in a cohort of paired eutopic and ectopic endometrial stromal cell samples from 11 patients. -

DNA Methylation Changes in Down Syndrome Derived Neural Ipscs Uncover Co-Dysregulation of ZNF and HOX3 Families of Transcription
Laan et al. Clinical Epigenetics (2020) 12:9 https://doi.org/10.1186/s13148-019-0803-1 RESEARCH Open Access DNA methylation changes in Down syndrome derived neural iPSCs uncover co- dysregulation of ZNF and HOX3 families of transcription factors Loora Laan1†, Joakim Klar1†, Maria Sobol1, Jan Hoeber1, Mansoureh Shahsavani2, Malin Kele2, Ambrin Fatima1, Muhammad Zakaria1, Göran Annerén1, Anna Falk2, Jens Schuster1 and Niklas Dahl1* Abstract Background: Down syndrome (DS) is characterized by neurodevelopmental abnormalities caused by partial or complete trisomy of human chromosome 21 (T21). Analysis of Down syndrome brain specimens has shown global epigenetic and transcriptional changes but their interplay during early neurogenesis remains largely unknown. We differentiated induced pluripotent stem cells (iPSCs) established from two DS patients with complete T21 and matched euploid donors into two distinct neural stages corresponding to early- and mid-gestational ages. Results: Using the Illumina Infinium 450K array, we assessed the DNA methylation pattern of known CpG regions and promoters across the genome in trisomic neural iPSC derivatives, and we identified a total of 500 stably and differentially methylated CpGs that were annotated to CpG islands of 151 genes. The genes were enriched within the DNA binding category, uncovering 37 factors of importance for transcriptional regulation and chromatin structure. In particular, we observed regional epigenetic changes of the transcription factor genes ZNF69, ZNF700 and ZNF763 as well as the HOXA3, HOXB3 and HOXD3 genes. A similar clustering of differential methylation was found in the CpG islands of the HIST1 genes suggesting effects on chromatin remodeling. Conclusions: The study shows that early established differential methylation in neural iPSC derivatives with T21 are associated with a set of genes relevant for DS brain development, providing a novel framework for further studies on epigenetic changes and transcriptional dysregulation during T21 neurogenesis. -

Download Download
Supplementary Figure S1. Results of flow cytometry analysis, performed to estimate CD34 positivity, after immunomagnetic separation in two different experiments. As monoclonal antibody for labeling the sample, the fluorescein isothiocyanate (FITC)- conjugated mouse anti-human CD34 MoAb (Mylteni) was used. Briefly, cell samples were incubated in the presence of the indicated MoAbs, at the proper dilution, in PBS containing 5% FCS and 1% Fc receptor (FcR) blocking reagent (Miltenyi) for 30 min at 4 C. Cells were then washed twice, resuspended with PBS and analyzed by a Coulter Epics XL (Coulter Electronics Inc., Hialeah, FL, USA) flow cytometer. only use Non-commercial 1 Supplementary Table S1. Complete list of the datasets used in this study and their sources. GEO Total samples Geo selected GEO accession of used Platform Reference series in series samples samples GSM142565 GSM142566 GSM142567 GSM142568 GSE6146 HG-U133A 14 8 - GSM142569 GSM142571 GSM142572 GSM142574 GSM51391 GSM51392 GSE2666 HG-U133A 36 4 1 GSM51393 GSM51394 only GSM321583 GSE12803 HG-U133A 20 3 GSM321584 2 GSM321585 use Promyelocytes_1 Promyelocytes_2 Promyelocytes_3 Promyelocytes_4 HG-U133A 8 8 3 GSE64282 Promyelocytes_5 Promyelocytes_6 Promyelocytes_7 Promyelocytes_8 Non-commercial 2 Supplementary Table S2. Chromosomal regions up-regulated in CD34+ samples as identified by the LAP procedure with the two-class statistics coded in the PREDA R package and an FDR threshold of 0.5. Functional enrichment analysis has been performed using DAVID (http://david.abcc.ncifcrf.gov/) -

The UVB-Induced Gene Expression Profile of Human Epidermis in Vivo Is Different from That of Cultured Keratinocytes
Oncogene (2006) 25, 2601–2614 & 2006 Nature Publishing Group All rights reserved 0950-9232/06 $30.00 www.nature.com/onc ORIGINAL ARTICLE The UVB-induced gene expression profile of human epidermis in vivo is different from that of cultured keratinocytes CD Enk1, J Jacob-Hirsch2, H Gal3, I Verbovetski4, N Amariglio2, D Mevorach4, A Ingber1, D Givol3, G Rechavi2 and M Hochberg1 1Department of Dermatology, The Hadassah-Hebrew University Medical Center, Jerusalem, Israel; 2Department of Pediatric Hemato-Oncology and Functional Genomics, Safra Children’s Hospital, Sheba Medical Center and Sackler School of Medicine, Tel-Aviv University,Tel Aviv, Israel; 3Department of Molecular Cell Biology, Weizmann Institute of Science, Rehovot, Israel and 4The Laboratory for Cellular and Molecular Immunology, Department of Medicine, The Hadassah-Hebrew University Medical Center, Jerusalem, Israel In order to obtain a comprehensive picture of the radiation. UVB, with a wavelength range between 290 molecular events regulating cutaneous photodamage of and 320 nm, represents one of the most important intact human epidermis, suction blister roofs obtained environmental hazards affectinghuman skin (Hahn after a single dose of in vivo ultraviolet (UV)B exposure and Weinberg, 2002). To protect itself against the were used for microarray profiling. We found a changed DNA-damaging effects of sunlight, the skin disposes expression of 619 genes. Half of the UVB-regulated genes over highly complicated cellular programs, including had returned to pre-exposure baseline levels at 72 h, cell-cycle arrest, DNA repair and apoptosis (Brash et al., underscoring the transient character of the molecular 1996). Failure in selected elements of these defensive cutaneous UVB response. -

Anti-Histone H2B Antibody (ARG41373)
Product datasheet [email protected] ARG41373 Package: 100 μl anti-Histone H2B antibody Store at: -20°C Summary Product Description Rabbit Polyclonal antibody recognizes Histone H2B Tested Reactivity Hu, Ms, Rat Tested Application FACS, ICC/IF, IHC-P, IP, WB Host Rabbit Clonality Polyclonal Isotype IgG Target Name Histone H2B Antigen Species Human Immunogen Synthetic peptide derived from Human Histone H2B. Conjugation Un-conjugated Alternate Names Histone H2B type 1-K; H2BFAiii; H2BFT; H2B/S; H2B K; H2BK; HIRA-interacting protein 1 Application Instructions Application table Application Dilution FACS 1:50 ICC/IF 1:50 - 1:200 IHC-P 1:50 - 1:200 IP 1:30 WB 1:5000 - 1:20000 Application Note * The dilutions indicate recommended starting dilutions and the optimal dilutions or concentrations should be determined by the scientist. Calculated Mw 14 kDa Observed Size ~ 14 kDa Properties Form Liquid Purification Affinity purified. Buffer PBS (pH 7.4), 150 mM NaCl, 0.02% Sodium azide and 50% Glycerol. Preservative 0.02% Sodium azide Stabilizer 50% Glycerol Storage instruction For continuous use, store undiluted antibody at 2-8°C for up to a week. For long-term storage, aliquot www.arigobio.com 1/2 and store at -20°C. Storage in frost free freezers is not recommended. Avoid repeated freeze/thaw cycles. Suggest spin the vial prior to opening. The antibody solution should be gently mixed before use. Note For laboratory research only, not for drug, diagnostic or other use. Bioinformation Gene Symbol HIST1H2BK Gene Full Name histone cluster 1, H2bk Background Histones are basic nuclear proteins that are responsible for the nucleosome structure of the chromosomal fiber in eukaryotes. -

A Yeast Phenomic Model for the Influence of Warburg Metabolism on Genetic Buffering of Doxorubicin Sean M
Santos and Hartman Cancer & Metabolism (2019) 7:9 https://doi.org/10.1186/s40170-019-0201-3 RESEARCH Open Access A yeast phenomic model for the influence of Warburg metabolism on genetic buffering of doxorubicin Sean M. Santos and John L. Hartman IV* Abstract Background: The influence of the Warburg phenomenon on chemotherapy response is unknown. Saccharomyces cerevisiae mimics the Warburg effect, repressing respiration in the presence of adequate glucose. Yeast phenomic experiments were conducted to assess potential influences of Warburg metabolism on gene-drug interaction underlying the cellular response to doxorubicin. Homologous genes from yeast phenomic and cancer pharmacogenomics data were analyzed to infer evolutionary conservation of gene-drug interaction and predict therapeutic relevance. Methods: Cell proliferation phenotypes (CPPs) of the yeast gene knockout/knockdown library were measured by quantitative high-throughput cell array phenotyping (Q-HTCP), treating with escalating doxorubicin concentrations under conditions of respiratory or glycolytic metabolism. Doxorubicin-gene interaction was quantified by departure of CPPs observed for the doxorubicin-treated mutant strain from that expected based on an interaction model. Recursive expectation-maximization clustering (REMc) and Gene Ontology (GO)-based analyses of interactions identified functional biological modules that differentially buffer or promote doxorubicin cytotoxicity with respect to Warburg metabolism. Yeast phenomic and cancer pharmacogenomics data were integrated to predict differential gene expression causally influencing doxorubicin anti-tumor efficacy. Results: Yeast compromised for genes functioning in chromatin organization, and several other cellular processes are more resistant to doxorubicin under glycolytic conditions. Thus, the Warburg transition appears to alleviate requirements for cellular functions that buffer doxorubicin cytotoxicity in a respiratory context. -

HIST1H2BH/HIST1H2BK/HIST3H2BB Antibody (Center) Affinity Purified Rabbit Polyclonal Antibody (Pab) Catalog # Ap18559c
10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 HIST1H2BH/HIST1H2BK/HIST3H2BB Antibody (Center) Affinity Purified Rabbit Polyclonal Antibody (Pab) Catalog # AP18559c Specification HIST1H2BH/HIST1H2BK/HIST3H2BB Antibody (Center) - Product Information Application WB,E Primary Accession Q93079 Other Accession P57053, Q9PSW9, P0C1H5, P0C1H4, Q6PC60, Q8CGP0, Q8N257, Q9D2U9, Q5QNW6, Q64524, Q16778, Q64525, Q00715, Q5BJA5, P0C1H3, P62808, Q8CGP2, P23527, Q99877, Q32L48, P10854, Q99879, Q99880, Q8CGP1, O60814, Q2M2T1, HIST1H2BH/HIST1H2BK/HIST3H2BB Antibody P06899, Q64478, (Center) (Cat. #AP18559c) western blot P10853, P58876, analysis in MCF-7 cell line lysates Q6ZWY9, P62807 (35ug/lane).This demonstrates the Reactivity Human HIST1H2BH/HIST1H2BK/HIST3H2BB antibody Predicted Xenopus, Mouse, detected the Bovine, Chicken, HIST1H2BH/HIST1H2BK/HIST3H2BB protein Zebrafish, Rat (arrow). Host Rabbit Clonality Polyclonal Isotype Rabbit Ig HIST1H2BH/HIST1H2BK/HIST3H2BB Calculated MW 13892 Antibody (Center) - Background Antigen Region 26-52 Histones are basic nuclear proteins that are HIST1H2BH/HIST1H2BK/HIST3H2BB Antibody responsible (Center) - Additional Information for the nucleosome structure of the chromosomal fiber in Gene ID 8345 eukaryotes. Two molecules of each of the four core histones (H2A, Other Names H2B, H3, and H4) form an octamer, around Histone H2B type 1-H, Histone H2Bj, H2B/j, which approximately 146 bp HIST1H2BH, H2BFJ of DNA is wrapped in repeating units, called nucleosomes. The Target/Specificity linker histone, H1, interacts with linker DNA This HIST1H2BH/HIST1H2BK/HIST3H2BB between nucleosomes antibody is generated from rabbits and functions in the compaction of chromatin immunized with a KLH conjugated synthetic into higher order peptide between 26-52 amino acids from structures. This gene is intronless and encodes the Central region of human a member of the HIST1H2BH/HIST1H2BK/HIST3H2BB. -

Peripherally Generated Foxp3+ Regulatory T Cells Mediate the Immunomodulatory Effects of Ivig in Allergic Airways Disease
Published February 20, 2017, doi:10.4049/jimmunol.1502361 The Journal of Immunology Peripherally Generated Foxp3+ Regulatory T Cells Mediate the Immunomodulatory Effects of IVIg in Allergic Airways Disease Amir H. Massoud,*,†,1 Gabriel N. Kaufman,* Di Xue,* Marianne Be´land,* Marieme Dembele,* Ciriaco A. Piccirillo,‡ Walid Mourad,† and Bruce D. Mazer* IVIg is widely used as an immunomodulatory therapy. We have recently demonstrated that IVIg protects against airway hyper- responsiveness (AHR) and inflammation in mouse models of allergic airways disease (AAD), associated with induction of Foxp3+ regulatory T cells (Treg). Using mice carrying a DTR/EGFP transgene under the control of the Foxp3 promoter (DEREG mice), we demonstrate in this study that IVIg generates a de novo population of peripheral Treg (pTreg) in the absence of endogenous Treg. IVIg-generated pTreg were sufficient for inhibition of OVA-induced AHR in an Ag-driven murine model of AAD. In the absence of endogenous Treg, IVIg failed to confer protection against AHR and airway inflammation. Adoptive transfer of purified IVIg-generated pTreg prior to Ag challenge effectively prevented airway inflammation and AHR in an Ag-specific manner. Microarray gene expression profiling of IVIg-generated pTreg revealed upregulation of genes associated with cell cycle, chroma- tin, cytoskeleton/motility, immunity, and apoptosis. These data demonstrate the importance of Treg in regulating AAD and show that IVIg-generated pTreg are necessary and sufficient for inhibition of allergen-induced AAD. The ability of IVIg to generate pure populations of highly Ag-specific pTreg represents a new avenue to study pTreg, the cross-talk between humoral and cellular immunity, and regulation of the inflammatory response to Ags. -

Supplementary Information
Supplementary Information Table S1. Gene Ontology analysis of affected biological processes/pathways/themes in H1 hESCs based on sets of statistically significant differentially expressed genes. Exposures Overrepresented Categories (Upregulation) EASE Score Negative regulation of cell differentiation 0.0049 Lipid biosynthetic process 0.015 Negative regulation of cell proliferation 0.02 5 cGy, 2 h Transcription factor binding 0.037 Regulation of apoptosis 0.038 Positive regulation of anti-apoptosis 0.048 P53 signaling pathway 4.2 × 10−10 Positive regulation of apoptosis 7.5 × 10−8 Response to DNA damage stimulus 1.5 × 10−6 Cellular response to stress 9.6 × 10−6 1 Gy, 2 h Negative regulation of cell proliferation 9.8 × 10−6 Cell cycle arrest 7.0 × 10−4 Negative regulation of cell differentiation 1.5 × 10−3 Regulation of protein kinase activity 0.011 I-kappaB kinase/NF-kappaB cascade 0.025 Metallothionein superfamily 9.9 × 10−18 Induction of apoptosis 8.8 × 10−5 DNA damage response 2.6 × 10−4 1 Gy, 16 h Positive regulation of anti-apoptosis 0.001 Positive regulation of cell death 0.005 Cellular response to stress 0.012 Exposures Overrepresented Categories (Downregulation) EASE Score Alternative splicing 0.016 1 Gy, 2 h Chromatin organization 0.020 Chromatin assembly 2.0 × 10−6 Cholesterol biosynthesis 5.1 × 10−5 Macromolecular complex assembly 9.3 × 10−4 1 Gy, 16 h PPAR signaling pathway 0.007 Hemopoietic organ development 0.033 Immune system development 0.040 S2 Table S2. Gene Ontology analysis of affected biological processes/pathways/themes in H7 based on sets of statistically significant differentially expressed genes. -
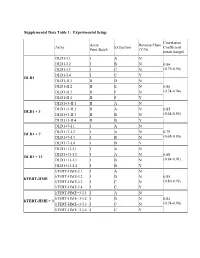
Table 3: Average Gene Expression Profiles by Chromosome
Supplemental Data Table 1: Experimental Setup Correlation Array Reverse Fluor Array Extraction Coefficient Print Batch (Y/N) mean (range) DLD1-I.1 I A N DLD1-I.2 I B N 0.86 DLD1-I.3 I C N (0.79-0.90) DLD1-I.4 I C Y DLD1 DLD1-II.1 II D N DLD1-II.2 II E N 0.86 DLD1-II.3 II F N (0.74-0.94) DLD1-II.4 II F Y DLD1+3-II.1 II A N DLD1+3-II.2 II A N 0.85 DLD1 + 3 DLD1+3-II.3 II B N (0.64-0.95) DLD1+3-II.4 II B Y DLD1+7-I.1 I A N DLD1+7-I.2 I A N 0.79 DLD1 + 7 DLD1+7-I.3 I B N (0.68-0.90) DLD1+7-I.4 I B Y DLD1+13-I.1 I A N DLD1+13-I.2 I A N 0.88 DLD1 + 13 DLD1+13-I.3 I B N (0.84-0.91) DLD1+13-I.4 I B Y hTERT-HME-I.1 I A N hTERT-HME-I.2 I B N 0.85 hTERT-HME hTERT-HME-I.3 I C N (0.80-0.92) hTERT-HME-I.4 I C Y hTERT-HME+3-I.1 I A N hTERT-HME+3-I.2 I B N 0.84 hTERT-HME + 3 hTERT-HME+3-I.3 I C N (0.74-0.90) hTERT-HME+3-I.4 I C Y Supplemental Data Table 2: Average gene expression profiles by chromosome arm DLD1 hTERT-HME Ratio.7 Ratio.1 Ratio.3 Ratio.3 Chrom. -

HIRA Orchestrates a Dynamic Chromatin Landscape in Senescence and Is Required for Suppression of Neoplasia
Downloaded from genesdev.cshlp.org on September 25, 2021 - Published by Cold Spring Harbor Laboratory Press HIRA orchestrates a dynamic chromatin landscape in senescence and is required for suppression of neoplasia Taranjit Singh Rai,1,2,3 John J. Cole,1,2,5 David M. Nelson,1,2,5 Dina Dikovskaya,1,2 William J. Faller,1 Maria Grazia Vizioli,1,2 Rachael N. Hewitt,1,2 Orchi Anannya,1 Tony McBryan,1,2 Indrani Manoharan,1,2 John van Tuyn,1,2 Nicholas Morrice,1 Nikolay A. Pchelintsev,1,2 Andre Ivanov,1,2,4 Claire Brock,1,2 Mark E. Drotar,1,2 Colin Nixon,1 William Clark,1 Owen J. Sansom,1 Kurt I. Anderson,1 Ayala King,1 Karen Blyth,1 and Peter D. Adams1,2 1Beatson Institute for Cancer Research, Bearsden, Glasgow G61 1BD, United Kingdom; 2Institute of Cancer Sciences, College of Medical, Veterinary, and Life Sciences, University of Glasgow, Glasgow G61 1BD, United Kingdom; 3Institute of Biomedical and Environmental Health Research, University of West of Scotland, Paisley PA1 2BE, United Kingdom Cellular senescence is a stable proliferation arrest that suppresses tumorigenesis. Cellular senescence and associated tumor suppression depend on control of chromatin. Histone chaperone HIRA deposits variant histone H3.3 and histone H4 into chromatin in a DNA replication-independent manner. Appropriately for a DNA replication-independent chaperone, HIRA is involved in control of chromatin in nonproliferating senescent cells, although its role is poorly defined. Here, we show that nonproliferating senescent cells express and incorporate histone H3.3 and other canonical core histones into a dynamic chromatin landscape. -

A Multiprotein Occupancy Map of the Mrnp on the 3 End of Histone
Downloaded from rnajournal.cshlp.org on October 6, 2021 - Published by Cold Spring Harbor Laboratory Press A multiprotein occupancy map of the mRNP on the 3′ end of histone mRNAs LIONEL BROOKS III,1 SHAWN M. LYONS,2 J. MATTHEW MAHONEY,1 JOSHUA D. WELCH,3 ZHONGLE LIU,1 WILLIAM F. MARZLUFF,2 and MICHAEL L. WHITFIELD1 1Department of Genetics, Dartmouth Geisel School of Medicine, Hanover, New Hampshire 03755, USA 2Integrative Program for Biological and Genome Sciences, University of North Carolina, Chapel Hill, North Carolina 27599, USA 3Department of Computer Science, University of North Carolina, Chapel Hill, North Carolina 27599, USA ABSTRACT The animal replication-dependent (RD) histone mRNAs are coordinately regulated with chromosome replication. The RD-histone mRNAs are the only known cellular mRNAs that are not polyadenylated. Instead, the mature transcripts end in a conserved stem– loop (SL) structure. This SL structure interacts with the stem–loop binding protein (SLBP), which is involved in all aspects of RD- histone mRNA metabolism. We used several genomic methods, including high-throughput sequencing of cross-linked immunoprecipitate (HITS-CLIP) to analyze the RNA-binding landscape of SLBP. SLBP was not bound to any RNAs other than histone mRNAs. We performed bioinformatic analyses of the HITS-CLIP data that included (i) clustering genes by sequencing read coverage using CVCA, (ii) mapping the bound RNA fragment termini, and (iii) mapping cross-linking induced mutation sites (CIMS) using CLIP-PyL software. These analyses allowed us to identify specific sites of molecular contact between SLBP and its RD-histone mRNA ligands. We performed in vitro crosslinking assays to refine the CIMS mapping and found that uracils one and three in the loop of the histone mRNA SL preferentially crosslink to SLBP, whereas uracil two in the loop preferentially crosslinks to a separate component, likely the 3′hExo.