Assessment of Data Rates on the Internal and External Cpu Interfaces and Its Applications for Wireless Network-On-Chip Development
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Great Telecom Meltdown for a Listing of Recent Titles in the Artech House Telecommunications Library, Turn to the Back of This Book
The Great Telecom Meltdown For a listing of recent titles in the Artech House Telecommunications Library, turn to the back of this book. The Great Telecom Meltdown Fred R. Goldstein a r techhouse. com Library of Congress Cataloging-in-Publication Data A catalog record for this book is available from the U.S. Library of Congress. British Library Cataloguing in Publication Data Goldstein, Fred R. The great telecom meltdown.—(Artech House telecommunications Library) 1. Telecommunication—History 2. Telecommunciation—Technological innovations— History 3. Telecommunication—Finance—History I. Title 384’.09 ISBN 1-58053-939-4 Cover design by Leslie Genser © 2005 ARTECH HOUSE, INC. 685 Canton Street Norwood, MA 02062 All rights reserved. Printed and bound in the United States of America. No part of this book may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage and retrieval system, without permission in writing from the publisher. All terms mentioned in this book that are known to be trademarks or service marks have been appropriately capitalized. Artech House cannot attest to the accuracy of this information. Use of a term in this book should not be regarded as affecting the validity of any trademark or service mark. International Standard Book Number: 1-58053-939-4 10987654321 Contents ix Hybrid Fiber-Coax (HFC) Gave Cable Providers an Advantage on “Triple Play” 122 RBOCs Took the Threat Seriously 123 Hybrid Fiber-Coax Is Developed 123 Cable Modems -

Microprocessors in the 1970'S
Part II 1970's -- The Altair/Apple Era. 3/1 3/2 Part II 1970’s -- The Altair/Apple era Figure 3.1: A graphical history of personal computers in the 1970’s, the MITS Altair and Apple Computer era. Microprocessors in the 1970’s 3/3 Figure 3.2: Andrew S. Grove, Robert N. Noyce and Gordon E. Moore. Figure 3.3: Marcian E. “Ted” Hoff. Photographs are courtesy of Intel Corporation. 3/4 Part II 1970’s -- The Altair/Apple era Figure 3.4: The Intel MCS-4 (Micro Computer System 4) basic system. Figure 3.5: A photomicrograph of the Intel 4004 microprocessor. Photographs are courtesy of Intel Corporation. Chapter 3 Microprocessors in the 1970's The creation of the transistor in 1947 and the development of the integrated circuit in 1958/59, is the technology that formed the basis for the microprocessor. Initially the technology only enabled a restricted number of components on a single chip. However this changed significantly in the following years. The technology evolved from Small Scale Integration (SSI) in the early 1960's to Medium Scale Integration (MSI) with a few hundred components in the mid 1960's. By the late 1960's LSI (Large Scale Integration) chips with thousands of components had occurred. This rapid increase in the number of components in an integrated circuit led to what became known as Moore’s Law. The concept of this law was described by Gordon Moore in an article entitled “Cramming More Components Onto Integrated Circuits” in the April 1965 issue of Electronics magazine [338]. -
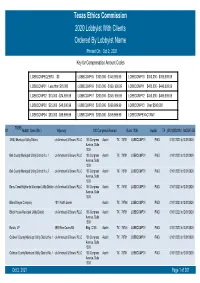
Texas Ethics Commission 2020 Lobbyist with Clients Ordered by Lobbyist Name Printed on Oct 2, 2021 Key for Compensation Amount Codes
Texas Ethics Commission 2020 Lobbyist With Clients Ordered By Lobbyist Name Printed On Oct 2, 2021 Key for Compensation Amount Codes LOBBCOMPEQZERO $0 LOBBCOMP05 $100,000 - $149,999.99 LOBBCOMP10 $350,000 - $399,999.99 LOBBCOMP01 Less than $10,000 LOBBCOMP06 $150,000 - $199, 999.99 LOBBCOMP11 $400,000 - $449,999.99 LOBBCOMP02 $10,000 - $24,999.99 LOBBCOMP07 $200,000 - $249, 999.99 LOBBCOMP12 $450,000 - $499,999.99 LOBBCOMP03 $25,000 - $49,000.99 LOBBCOMP08 $250,000 - $299,999.99 LOBBCOMP13 Over $500,000 LOBBCOMP04 $50,000 - $99,999.99 LOBBCOMP09 $300,000 - $349,999.99 LOBBCOMPEXACTAMT 70358 #1 Abbott, Sean (Mr.) Attorney 100 Congress Avenue Suite 1300 Austin TX (512)4352334 MODIFIED 3 B&J Municipal Utility District c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Bell County Municipal Utility District No. 1 c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Bell County Municipal Utility District No. 2 c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Berry Creek Highlands Municipal Utility District c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Blake Magee Company 1011 North Lamar Austin TX 78704 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Block House Municipal Utility District c/o Armbrust & Brown, PLLC 100 Congress Austin TX 78701 LOBBCOMP01 PAID 01/01/2020 to12/31/2020 Avenue, Suite 1300 Bonzo, LP 3939 Bee Caves Rd. -

Microcomputers: NQS PUBLICATIONS Introduction to Features and Uses
of Commerce Computer Science National Bureau and Technology of Standards NBS Special Publication 500-110 Microcomputers: NQS PUBLICATIONS Introduction to Features and Uses QO IGf) .U57 500-110 NATIONAL BUREAU OF STANDARDS The National Bureau of Standards' was established by an act ot Congress on March 3, 1901. The Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research and provides; (1) a basis for the Nation's physical measurement system, (2) scientific and technological services for industry and government, (3) a technical basis for equity in trade, and (4) technical services to promote public safety. The Bureau's technical work is per- formed by the National Measurement Laboratory, the National Engineering Laboratory, and the Institute for Computer Sciences and Technology. THE NATIONAL MEASUREMENT LABORATORY provides the national system of physical and chemical and materials measurement; coordinates the system with measurement systems of other nations and furnishes essential services leading to accurate and uniform physical and chemical measurement throughout the Nation's scientific community, industry, and commerce; conducts materials research leading to improved methods of measurement, standards, and data on the properties of materials needed by industry, commerce, educational institutions, and Government; provides advisory and research services to other Government agencies; develops, produces, and -
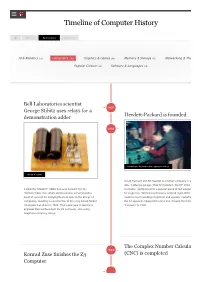
Timeline of Computer History
Timeline of Computer History By Year By Category Search AI & Robotics (55) Computers (145)(145) Graphics & Games (48) Memory & Storage (61) Networking & The Popular Culture (50) Software & Languages (60) Bell Laboratories scientist 1937 George Stibitz uses relays for a Hewlett-Packard is founded demonstration adder 1939 Hewlett and Packard in their garage workshop “Model K” Adder David Packard and Bill Hewlett found their company in a Alto, California garage. Their first product, the HP 200A A Called the “Model K” Adder because he built it on his Oscillator, rapidly became a popular piece of test equipm “Kitchen” table, this simple demonstration circuit provides for engineers. Walt Disney Pictures ordered eight of the 2 proof of concept for applying Boolean logic to the design of model to test recording equipment and speaker systems computers, resulting in construction of the relay-based Model the 12 specially equipped theatres that showed the movie I Complex Calculator in 1939. That same year in Germany, “Fantasia” in 1940. engineer Konrad Zuse built his Z2 computer, also using telephone company relays. The Complex Number Calculat 1940 Konrad Zuse finishes the Z3 (CNC) is completed Computer 1941 The Zuse Z3 Computer The Z3, an early computer built by German engineer Konrad Zuse working in complete isolation from developments elsewhere, uses 2,300 relays, performs floating point binary arithmetic, and has a 22-bit word length. The Z3 was used for aerodynamic calculations but was destroyed in a bombing raid on Berlin in late 1943. Zuse later supervised a reconstruction of the Z3 in the 1960s, which is currently on Operator at Complex Number Calculator (CNC) display at the Deutsches Museum in Munich. -

The Restoration of the Honeywell Questar M Written by Sergio Gervasini for ESOCOP – the European Society for Computer Preservation
European SOciety for COmputer Preservation The restoration of the Honeywell Questar M written by Sergio Gervasini for ESOCOP – The European Society for Computer Preservation http://www.esocop.org The restoration of the Honeywell Questar M In 2018 by the European Society for Computer Preservation http://www.esocop.org 1 European SOciety for COmputer Preservation Table of Contents License..................................................................................................................................................3 References............................................................................................................................................3 History..................................................................................................................................................4 My history............................................................................................................................................5 Visual Check.........................................................................................................................................6 Power supply and motherboard............................................................................................................7 Monitor.................................................................................................................................................9 Keyboard.............................................................................................................................................11 -

The State Board of Education
THE STAte OF the RELIGIOUS RIGht { 2008 } THE STATE BOARD OF EDUCATION: DRAGGING TEXAS SCHOOLS INTO THE CULTURE WARS THE STAte OF the RELIGIOUS RIGht { 2008 } THE STATE BOARD OF EDUCATION: DRAGGING TEXAS SCHOOLS INTO THE CULTURE WARS A R E p ort f ro m the T exas f R E E D O m N etwor k E ducation f U N D kathy miller, TFN president Dan Quinn, TFN communications director Bren Gorman, researcher Judie Niskala, researcher Emily Sentilles, researcher A bout the T f N E ducation f U N D The Texas Freedom Network Education Fund is a 501(c)(3) tax-exempt, nonprofit corporation. Created in 1996, the TFN Education Fund researches the agenda, activities and funding of the religious right. It also educates mainstream people of faith in how to formulate and to advocate a faith-based response to the religious right’s policy agenda. TfN Education fund Board of Directors Rebecca Lightsey, chair Janis pinnelli, treasurer Rev. Dr. Larry Bethune Grace Garcia Diane Ireson Dale Linebarger Table Of Contents Introduction. .2. Watch List: 2008. .5 1: The State Board of Education in Texas. .11 2: A History of Censorship in Texas. .17 3: The Right Ascendant. 21 4: Targeting Curriculum Standards (TEKS). .25 Appendices Appendix A: Who’s Who in Texas Textbook Censorship . .30 Appendix B: Textbook Censorship in Texas: A Timeline. .32 Appendix C: Textbook Censorship in Texas: The Record. .35 Appendix D: They Really Said It: Quoting the Religious Right in 2007 .. .. .. .. .. .. .. ...36 Appendix E: Organizations of the Religious Right in Texas. -

A History of the Personal Computer Index/11
A History of the Personal Computer 6100 CPU. See Intersil Index 6501 and 6502 microprocessor. See MOS Legend: Chap.#/Page# of Chap. 6502 BASIC. See Microsoft/Prog. Languages -- Numerals -- 7000 copier. See Xerox/Misc. 3 E-Z Pieces software, 13/20 8000 microprocessors. See 3-Plus-1 software. See Intel/Microprocessors Commodore 8010 “Star” Information 3Com Corporation, 12/15, System. See Xerox/Comp. 12/27, 16/17, 17/18, 17/20 8080 and 8086 BASIC. See 3M company, 17/5, 17/22 Microsoft/Prog. Languages 3P+S board. See Processor 8514/A standard, 20/6 Technology 9700 laser printing system. 4K BASIC. See Microsoft/Prog. See Xerox/Misc. Languages 16032 and 32032 micro/p. See 4th Dimension. See ACI National Semiconductor 8/16 magazine, 18/5 65802 and 65816 micro/p. See 8/16-Central, 18/5 Western Design Center 8K BASIC. See Microsoft/Prog. 68000 series of micro/p. See Languages Motorola 20SC hard drive. See Apple 80000 series of micro/p. See Computer/Accessories Intel/Microprocessors 64 computer. See Commodore 88000 micro/p. See Motorola 80 Microcomputing magazine, 18/4 --A-- 80-103A modem. See Hayes A Programming lang. See APL 86-DOS. See Seattle Computer A+ magazine, 18/5 128EX/2 computer. See Video A.P.P.L.E. (Apple Pugetsound Technology Program Library Exchange) 386i personal computer. See user group, 18/4, 19/17 Sun Microsystems Call-A.P.P.L.E. magazine, 432 microprocessor. See 18/4 Intel/Microprocessors A2-Central newsletter, 18/5 603/4 Electronic Multiplier. Abacus magazine, 18/8 See IBM/Computer (mainframe) ABC (Atanasoff-Berry 660 computer. -

Low Cost Video for Distance Education Michael J
Nova Southeastern University NSUWorks CEC Theses and Dissertations College of Engineering and Computing 1996 Low Cost Video For Distance Education Michael J. Simpson Nova Southeastern University, [email protected] This document is a product of extensive research conducted at the Nova Southeastern University College of Engineering and Computing. For more information on research and degree programs at the NSU College of Engineering and Computing, please click here. Follow this and additional works at: https://nsuworks.nova.edu/gscis_etd Part of the Computer Sciences Commons Share Feedback About This Item NSUWorks Citation Michael J. Simpson. 1996. Low Cost Video For Distance Education. Doctoral dissertation. Nova Southeastern University. Retrieved from NSUWorks, Graduate School of Computer and Information Sciences. (842) https://nsuworks.nova.edu/gscis_etd/842. This Dissertation is brought to you by the College of Engineering and Computing at NSUWorks. It has been accepted for inclusion in CEC Theses and Dissertations by an authorized administrator of NSUWorks. For more information, please contact [email protected]. Low Cost Video for Distance Education by Michael J. Simpson A Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy School of Computer and Information Sciences Nova Southeastern University 1996 We hereby certify that this dissertation, submitted by Michael J. Simpson, conforms to acceptable standards and is fully adequate in scope and quality to fulfill the dissertation requirements for the degree of Doctor of Philosophy. _______________________________________________________ Jacques C. Levin, Ph.D. Date Chairman of Dissertation Committee _______________________________________________________ John A. Scigliano, Ed.D. Date Dissertation Committee Member _______________________________________________________ Steven R. Terrell, Ed.D. -

Osborne 1 Computer
Osborne 1 computer http://oldcomputers.net/osborne.html Timeline: ( Show Images ) Osborne 1 1970 Datapoint 2200 Introduced: April 1981 1971 Kenbak-1 Price: US $1,795 1972 Weight: 24.5 pounds CPU: Zilog Z80 @ 4.0 MHz 1973 Micral RAM: 64K RAM Scelbi-8H Display: built-in 5" monitor 1974 Mark-8 53 X 24 text 1975 MITS Altair 8800 Ports: parallel / IEEE-488 SwTPC 6800 modem / serial port Sphere Storage: dual 5-1/4 inch, 91K drives OS: CP/M Compucolor IMSAI 8080 IBM 5100 1976 MOS KIM-1 Sol-20 Hewlett-Packard 9825A PolyMorphic Cromemco Z-1 Roma Offerta Coupon www.GROUPON.it/Roma Apple I Ogni giorno sconti esagerati Giá oltre Rockwell AIM 65 319.000.000€ risparmiati. 1977 ELF, SuperELF VideoBrain Family Computer Defend your Privacy www.eurocrypt.pt Apple II Secure Crypto Mobile , 3G, pgp Emails and Wameco QM-1A Computer encryption Vector Graphic Vector-1 RCA COSMAC VIP ThermoTek, Inc. www.thermotekusa.com Commodore PET Solid state recirculating chillers Thermal Radio Shack TRS-80 Management Solutions Atari VCS (2600) NorthStar Horizon Heathkit H8 Heathkit H11 1978 IBM 5110 Exidy Sorcerer Ohio Scientific Superboard II Synertek SYM-1 APF Imagination Machine Cromemco System 3 1979 Interact Model One TRS-80 model II Bell & Howell SwTPC S/09 Heathkit H89 Atari 400 Atari 800 TI-99/4 Sharp MZ 80K 1980 HP-85 MicroAce Released in 1981 by the Osborne Computer Corporation, the Osborne 1 is considered to be the first true portable computer Acorn Atom - it closes-up for protection, and has a carrying handle. -

Datapoint Oral History Panel
Datapoint Oral History Panel Henry Donzis, Lewis Donzis, John Murphy, Jonathan Schmidt Interviewed by: Len Shustek and Harry Saal Recorded: June 3, 2004 San Antonio, Texas CHM Reference number: X2850.2005 © 2004 Computer History Museum Datapoint Oral History Panel Len Shustek: June 3, 2004. We are doing a Computer History Museum world interview. And you’re here with John Murphy, Jonathan Schmidt, Lewis Donzis, and Henry Donzis, all at one time working for Datapoint. And we’ve actually done the individual histories with Jonathan and John. Maybe we should start with giving a little background, getting a little background from the Donzis brothers, find out how they got associated with these characters. In fact any of you can tell that story. Lewis Donzis: We get younger all the time. Henry Donzis: We get younger. Jonathan Schmidt: Henry was four and Lewis was two. Lewis Donzis: And I wasn’t born yet. Jonathan Schmidt: Oh he wasn’t born yet. Yes, we had- Henry was recommended as a brilliant potential computer scientist by his math teacher. Henry Donzis: Forester High School Jonathan Schmidt: Forster. Henry Donzis: Mr. Foster. Well I think it started out with you being- cause I used to- was using Al's basic computer. Lewis Donzis: Wasn’t that because of Gus Roache’s son ? Henry Donzis: It was Arty Roache . Jonathan Schmidt: Forgot about that. Lewis Donzis: Well there you go. Henry Donzis: Well that’s... Jonathan Schmidt: Yes. Henry Donzis: And every time I would lose a program and I called, and Randy or David or Harry or somebody would have to reload the thing. -

Lecture 8: Addendum
Lecture 8: Addendum What Does The MCM/70 Story Tell Us? - It was the introduction of Intel’s first microprocessors that triggered world- wide efforts to commercially develop personal computers (in Canada, France, and the US). - The historical mission of the creation of the first microprocessor-powered PCs was fulfilled by small, obscure electronic firms (such as Micro Computer Machines of Toronto or a small French electronic systems house R´ealisations et Etudes´ Electroniques´ (R2E)) as well as by the computer hobbyists’ move- ment of the mid 1970s – the subject of the next lecture. - From the start, it was clear to the MCM management that the microproces- sor technology would create a new computing paradigm based on individual use and ownership of computers. Fig. 1. The MCM/70 computer designed and manufactured by the Toronto-based Micro Computer Machines (1973). Source: York University Computer Museum; photograph by Paul Stachniak. 1 The microprocessor and the PC The advent of the microprocessor had a profound impact on the consumer electronic market (e.g. pocket calculators and digital watches) and on the creation of the personal computer industry. Mers Kutt’s knowledge about the microprocessor developments at Intel al- lowed his company (Micro Computer Machines) to start its work on the world’s first PC even before the Intel’s chip (the Intel 8008) was available commercially. As the former MCM software engineer Gordon Ramer explained, In designing the MCM/70 we totally bet on the emerging microprocessor technology, we just proceeded, even before the first [8 bit] microprocessor was built. The microprocessor was a radically new electronic device whose effective- ness in implementing computer equipment surprised many engineers.