Optimal Sorting Circuits for Short Keys*
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Parallel Sorting Algorithms + Topic Overview
+ Design of Parallel Algorithms Parallel Sorting Algorithms + Topic Overview n Issues in Sorting on Parallel Computers n Sorting Networks n Bubble Sort and its Variants n Quicksort n Bucket and Sample Sort n Other Sorting Algorithms + Sorting: Overview n One of the most commonly used and well-studied kernels. n Sorting can be comparison-based or noncomparison-based. n The fundamental operation of comparison-based sorting is compare-exchange. n The lower bound on any comparison-based sort of n numbers is Θ(nlog n) . n We focus here on comparison-based sorting algorithms. + Sorting: Basics What is a parallel sorted sequence? Where are the input and output lists stored? n We assume that the input and output lists are distributed. n The sorted list is partitioned with the property that each partitioned list is sorted and each element in processor Pi's list is less than that in Pj's list if i < j. + Sorting: Parallel Compare Exchange Operation A parallel compare-exchange operation. Processes Pi and Pj send their elements to each other. Process Pi keeps min{ai,aj}, and Pj keeps max{ai, aj}. + Sorting: Basics What is the parallel counterpart to a sequential comparator? n If each processor has one element, the compare exchange operation stores the smaller element at the processor with smaller id. This can be done in ts + tw time. n If we have more than one element per processor, we call this operation a compare split. Assume each of two processors have n/p elements. n After the compare-split operation, the smaller n/p elements are at processor Pi and the larger n/p elements at Pj, where i < j. -
Sorting Networks
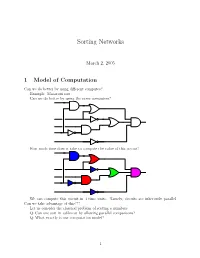
Sorting Networks March 2, 2005 1 Model of Computation Can we do better by using different computes? Example: Macaroni sort. Can we do better by using the same computers? How much time does it take to compute the value of this circuit? We can compute this circuit in 4 time units. Namely, circuits are inherently parallel. Can we take advantage of this??? Let us consider the classical problem of sorting n numbers. Q: Can one sort in sublinear by allowing parallel comparisons? Q: What exactly is our computation model? 1 1.1 Computing with a circuit We are going to design a circuit, where the inputs are the numbers, and we compare two numbers using a comparator gate: ¢¤¦© ¡ ¡ Comparator ¡£¢¥¤§¦©¨ ¡ For our drawings, we will draw such a gate as follows: ¢¡¤£¦¥¨§ © ¡£¦ So, circuits would just be horizontal lines, with vertical segments (i.e., gates) between them. A complete sorting network, looks like: The inputs come on the wires on the left, and are output on the wires on the right. The largest number is output on the bottom line. The surprising thing, is that one can generate circuits from a sorting algorithm. In fact, consider the following circuit: Q: What does this circuit does? A: This is the inner loop of insertion sort. Repeating this inner loop, we get the following sorting network: 2 Alternative way of drawing it: Q: How much time does it take for this circuit to sort the n numbers? Running time = how many time clocks we have to wait till the result stabilizes. In this case: 5 1 2 3 4 6 7 8 9 In general, we get: Lemma 1.1 Insertion sort requires 2n − 1 time units to sort n numbers. -

Foundations of Differentially Oblivious Algorithms
Foundations of Differentially Oblivious Algorithms T-H. Hubert Chan Kai-Min Chung Bruce Maggs Elaine Shi August 5, 2020 Abstract It is well-known that a program's memory access pattern can leak information about its input. To thwart such leakage, most existing works adopt the technique of oblivious RAM (ORAM) simulation. Such an obliviousness notion has stimulated much debate. Although ORAM techniques have significantly improved over the past few years, the concrete overheads are arguably still undesirable for real-world systems | part of this overhead is in fact inherent due to a well-known logarithmic ORAM lower bound by Goldreich and Ostrovsky. To make matters worse, when the program's runtime or output length depend on secret inputs, it may be necessary to perform worst-case padding to achieve full obliviousness and thus incur possibly super-linear overheads. Inspired by the elegant notion of differential privacy, we initiate the study of a new notion of access pattern privacy, which we call \(, δ)-differential obliviousness". We separate the notion of (, δ)-differential obliviousness from classical obliviousness by considering several fundamental algorithmic abstractions including sorting small-length keys, merging two sorted lists, and range query data structures (akin to binary search trees). We show that by adopting differential obliv- iousness with reasonable choices of and δ, not only can one circumvent several impossibilities pertaining to full obliviousness, one can also, in several cases, obtain meaningful privacy with little overhead relative to the non-private baselines (i.e., having privacy \almost for free"). On the other hand, we show that for very demanding choices of and δ, the same lower bounds for oblivious algorithms would be preserved for (, δ)-differential obliviousness. -

Visvesvaraya Technological University a Project Report
` VISVESVARAYA TECHNOLOGICAL UNIVERSITY “Jnana Sangama”, Belagavi – 590 018 A PROJECT REPORT ON “PREDICTIVE SCHEDULING OF SORTING ALGORITHMS” Submitted in partial fulfillment for the award of the degree of BACHELOR OF ENGINEERING IN COMPUTER SCIENCE AND ENGINEERING BY RANJIT KUMAR SHA (1NH13CS092) SANDIP SHAH (1NH13CS101) SAURABH RAI (1NH13CS104) GAURAV KUMAR (1NH13CS718) Under the guidance of Ms. Sridevi (Senior Assistant Professor, Dept. of CSE, NHCE) DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING NEW HORIZON COLLEGE OF ENGINEERING (ISO-9001:2000 certified, Accredited by NAAC ‘A’, Permanently affiliated to VTU) Outer Ring Road, Panathur Post, Near Marathalli, Bangalore – 560103 ` NEW HORIZON COLLEGE OF ENGINEERING (ISO-9001:2000 certified, Accredited by NAAC ‘A’ Permanently affiliated to VTU) Outer Ring Road, Panathur Post, Near Marathalli, Bangalore-560 103 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING CERTIFICATE Certified that the project work entitled “PREDICTIVE SCHEDULING OF SORTING ALGORITHMS” carried out by RANJIT KUMAR SHA (1NH13CS092), SANDIP SHAH (1NH13CS101), SAURABH RAI (1NH13CS104) and GAURAV KUMAR (1NH13CS718) bonafide students of NEW HORIZON COLLEGE OF ENGINEERING in partial fulfillment for the award of Bachelor of Engineering in Computer Science and Engineering of the Visvesvaraya Technological University, Belagavi during the year 2016-2017. It is certified that all corrections/suggestions indicated for Internal Assessment have been incorporated in the report deposited in the department library. The project report has been approved as it satisfies the academic requirements in respect of Project work prescribed for the Degree. Name & Signature of Guide Name Signature of HOD Signature of Principal (Ms. Sridevi) (Dr. Prashanth C.S.R.) (Dr. Manjunatha) External Viva Name of Examiner Signature with date 1. -

I. Sorting Networks Thomas Sauerwald
I. Sorting Networks Thomas Sauerwald Easter 2015 Outline Outline of this Course Introduction to Sorting Networks Batcher’s Sorting Network Counting Networks I. Sorting Networks Outline of this Course 2 Closely follow the book and use the same numberring of theorems/lemmas etc. I. Sorting Networks (Sorting, Counting, Load Balancing) II. Matrix Multiplication (Serial and Parallel) III. Linear Programming (Formulating, Applying and Solving) IV. Approximation Algorithms: Covering Problems V. Approximation Algorithms via Exact Algorithms VI. Approximation Algorithms: Travelling Salesman Problem VII. Approximation Algorithms: Randomisation and Rounding VIII. Approximation Algorithms: MAX-CUT Problem (Tentative) List of Topics Algorithms (I, II) Complexity Theory Advanced Algorithms I. Sorting Networks Outline of this Course 3 Closely follow the book and use the same numberring of theorems/lemmas etc. (Tentative) List of Topics Algorithms (I, II) Complexity Theory Advanced Algorithms I. Sorting Networks (Sorting, Counting, Load Balancing) II. Matrix Multiplication (Serial and Parallel) III. Linear Programming (Formulating, Applying and Solving) IV. Approximation Algorithms: Covering Problems V. Approximation Algorithms via Exact Algorithms VI. Approximation Algorithms: Travelling Salesman Problem VII. Approximation Algorithms: Randomisation and Rounding VIII. Approximation Algorithms: MAX-CUT Problem I. Sorting Networks Outline of this Course 3 (Tentative) List of Topics Algorithms (I, II) Complexity Theory Advanced Algorithms I. Sorting Networks (Sorting, Counting, Load Balancing) II. Matrix Multiplication (Serial and Parallel) III. Linear Programming (Formulating, Applying and Solving) IV. Approximation Algorithms: Covering Problems V. Approximation Algorithms via Exact Algorithms VI. Approximation Algorithms: Travelling Salesman Problem VII. Approximation Algorithms: Randomisation and Rounding VIII. Approximation Algorithms: MAX-CUT Problem Closely follow the book and use the same numberring of theorems/lemmas etc. -

An 11-Step Sorting Network for 18 Elements
An 11-Step Sorting Network for 18 Elements Sherenaz W. Al-Haj Baddar, Kenneth E. Batcher Kent State University Department of Computer Science Kent, Ohio 44240 [email protected] [email protected] output set must be a permutation of the input set {I1,I2,…,IN}. Abstract— Sorting Networks are cost-effective multistage Moreover, for every two elements of the output set Oj and Ok, interconnection networks with sorting capabilities. These Oj must be less than or equal to Ok whenever j ≤ k. networks theoretically consume Θ(NlogN) comparisons. However, Sorting networks are constructed using stages (steps) of the fastest implementable sorting networks built so far consume basic cells called Comparator Exchange(CE) modules. A CE is Θ(Nlog2N) comparisons, and generally, use the Merge-sorting a 2-element sorting circuit. It accepts two inputs via two input strategy to sort the input. An 18-element network using the Merge-sorting strategy needs at least 12 steps-here we show a lines, compares them and outputs the larger element on its high network that sorts 18 elements in only 11 steps. output line, whereas the smaller is output on its low output line. It is assumed that two comparators with disjoint inputs can operate in parallel. A typical CE is depicted in Figure 1[2]. Index Terms—Sorting Networks, Partial Ordering, 0/1 cases. I. INTRODUCTION Parallel processors are fast and powerful computing systems Figure 1. A comparator exchange module[2] that have been developed to help undertake computationally challenging problems. Deploying parallelism for solving a An optimal N-element sorting network requires θ(NlogN) given problem implies splitting the problem into subtasks. -

Selection O. Best Sorting Algorithm
International Journal of Intelligent Information Processing © Serials Publications 2(2) July-December 2008; pp. 363-368 SELECTION O BEST SORTING ALGORITHM ADITYA DEV MISHRA* & DEEPAK GARG** The problem of sorting is a problem that arises frequently in computer programming. Many different sorting algorithms have been developed and improved to make sorting fast. As a measure of performance mainly the average number of operations or the average execution times of these algorithms have been investigated and compared. There is no one sorting method that is best for every situation. Some of the factors to be considered in choosing a sorting algorithm include the size of the list to be sorted, the programming effort, the number of words of main memory available, the size of disk or tape units, the extent to which the list is already ordered, and the distribution of values. Keywords: Sorting, complexity lists, comparisons, movement sorting algorithms, methods, stable, unstable, internal sorting 1. INTRODUCTION Sorting is one of the most important and well-studied problems in computer science. Many good algorithms are known which offer various trade-offs in efficiency, simplicity, memory use, and other factors. However, these algorithms do not take into account features of modern computer architectures that significantly influence performance. A large number of sorting algorithms have been proposed and their asymptotic complexity, in terms of the number of comparisons or number of iterations, has been carefully analyzed [1]. In the recent past, there has been a growing interest on improvements to sorting algorithms that do not affect their asymptotic complexity but nevertheless improve performance by enhancing data locality [3,6]. -

Goodrich: Randomized Shellsort: a Simple Oblivious Sorting Algorithm
Randomized Shellsort: A Simple Oblivious Sorting Algorithm Michael T. Goodrich Dept. of Computer Science University of California, Irvine http://www.ics.uci.edu/∼goodrich/ Abstract of the Pratt sequence. Moreover, Plaxton and Suel [35] es- Ω(n log2 n/(log log n)2) In this paper, we describe a randomized Shellsort algorithm. tablish a lower bound of for the This algorithm is a simple, randomized, data-oblivious ver- worst-case running time of Shellsort with any input sequence et al. sion of the Shellsort algorithm that always runs in O(n log n) (see also [11]) and Jiang [23] establish a lower bound Ω(pn1+1/p) time and succeeds in sorting any given input permutation of for the average-case running time of Shell- O(n log n) with very high probability. Taken together, these properties sort. Thus, the only way to achieve an average- imply applications in the design of new efficient privacy- time bound for Shellsort is to use an offset sequence of Θ(log n) preserving computations based on the secure multi-party length , and, even then, the problem of proving O(n log n) computation (SMC) paradigm. In addition, by a trivial con- an average running-time bound for a version of version of this Monte Carlo algorithm to its Las Vegas equiv- Shellsort is a long-standing open problem [42]. alent, one gets the first version of Shellsort with a running The approach we take in this paper is to consider a time that is provably O(n log n) with very high probability. -

GPU-Quicksort: a Practical Quicksort Algorithm for Graphics Processors
GPU-Quicksort: A Practical Quicksort Algorithm for Graphics Processors DANIEL CEDERMAN and PHILIPPAS TSIGAS Chalmers University of Technology In this paper we describe GPU-Quicksort, an e±cient Quicksort algorithm suitable for highly par- allel multi-core graphics processors. Quicksort has previously been considered an ine±cient sorting solution for graphics processors, but we show that in CUDA, NVIDIA's programming platform for general purpose computations on graphical processors, GPU-Quicksort performs better than the fastest known sorting implementations for graphics processors, such as radix and bitonic sort. Quicksort can thus be seen as a viable alternative for sorting large quantities of data on graphics processors. Categories and Subject Descriptors: F.2.2 [Nonnumerical Algorithms and Problems]: Sort- ing and searching; G.4 [MATHEMATICAL SOFTWARE]: Parallel and vector implementa- tions General Terms: Algorithms, Design, Experimentation, Performance Additional Key Words and Phrases: Sorting, Multi-Core, CUDA, Quicksort, GPGPU 1. INTRODUCTION In this paper, we describe an e±cient parallel algorithmic implementation of Quick- sort, GPU-Quicksort, designed to take advantage of the highly parallel nature of graphics processors (GPUs) and their limited cache memory. Quicksort has long been considered one of the fastest sorting algorithms in practice for single processor systems and is also one of the most studied sorting algorithms, but until now it has not been considered an e±cient sorting solution for GPUs [Sengupta et al. 2007]. We show that GPU-Quicksort presents a viable sorting alternative and that it can outperform other GPU-based sorting algorithms such as GPUSort and radix sort, considered by many to be two of the best GPU-sorting algorithms. -

Copyright by Waqas Akram 2011 the Dissertation Committee for Waqas Akram Certifies That This Is the Approved Version of the Following Dissertation
Copyright by Waqas Akram 2011 The Dissertation Committee for Waqas Akram certifies that this is the approved version of the following dissertation: Tunable Mismatch Shaping for Bandpass Delta-Sigma Data Converters Committee: Earl E. Swartzlander, Jr., Supervisor Mircea D. Driga Michael E. Orshansky Vivek Telang Nur A. Touba Tunable Mismatch Shaping for Bandpass Delta-Sigma Data Converters by Waqas Akram, B.S.E.E.; B.A.; M.S.E. DISSERTATION Presented to the Faculty of the Graduate School of The University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY THE UNIVERSITY OF TEXAS AT AUSTIN May 2011 Dedicated to the memory of my loving parents, Zakia and Muhammad Akram. My mother was a mathematician and my father an engineer. Together, they ignited my passion to explore and encouraged my tenacity to succeed, but above all else, they nurtured me with patience and showed me how to persevere. Acknowledgments My deepest gratitude to my adviser, Dr. Earl E. Swartzlander, Jr., for his limitless patience and the thoughtful guidance he has generously provided, as a mentor and as a friend, throughout the course of my graduate studies. My sincere thanks to all the members of my dissertation committee for their support and kindness in sharing their precious time. I remain truly indebted to Melanie Gulick for always being willing to help; no matter how busy the moment, or how vexing the issue, her cheerfulness never failed to brighten the day. Most importantly, none of this would be possible without the encouragement and support of my family. -

Engineering Faster Sorters for Small Sets of Items
ARTICLE Engineering Faster Sorters for Small Sets of Items Timo Bingmann* | Jasper Marianczuk | Peter Sanders 1Institute of Theoretical Informatics, Karlsruhe Institute of Technology, Summary Karlsruhe, Germany Sorting a set of items is a task that can be useful by itself or as a building block for Correspondence more complex operations. That is why a lot of effort has been put into finding sorting *Timo Bingmann, Karlsruhe Institute of Technology, Am Fasanengarten 5, 76131 algorithms that sort large sets as efficiently as possible. But the more sophisticated Karlsruhe, Germany. Email: and fast the algorithms become asymptotically, the less efficient they are for small [email protected] sets of items due to large constant factors. A relatively simple sorting algorithm that is often used as a base case sorter is inser- tion sort, because it has small code size and small constant factors influencing its execution time. We aim to determine if there is a faster way to sort small sets of items to provide an efficient base case sorter. We looked at sorting networks, at how they can improve the speed of sorting few elements, and how to implement them in an efficient manner using conditional moves. Since sorting networks need to be implemented explicitly for each set size, providing networks for larger sizes becomes less efficient due to increased code sizes. To also enable the sorting of slightly larger base cases, we adapted sample sort to Register Sample Sort, to break down those larger sets into sizes that can in turn be sorted by sorting networks. From our experiments we found that when sorting only small sets of integers, the sort- ing networks outperform insertion sort by a factor of at least 1.76 for any array size between six and sixteen, and by a factor of 2.72 on average across all machines and array sizes. -

Studies on Sorting Networks and Expanders
I STUDIES ON SORTING NETWORKS AND EXPANDERS A Thesis Presented to The Faculty of the School of Electrical Engineering and Computer Science and Fritz J. and Dolores H. Russ College of Engineering and Technology Ohio University In Partial Fulfillment of the Requirement for the Degree Master of Science Hang Xie August, 1998 Acknowledgment I would like to express my special thanks to my advisor, Dr. David W. Juedes, for the insights he has provided to accomplish this thesis and the guidance given to me. Without this, it is impossible for me to accomplish this thesis. I would like to thank Dr. Dennis Irwin, Dr. Gene Kaufman, and Dr. Liming Cai for agreeing to be members of my thesis committee and giving valuable suggestions. I would also like to thank Mr. Dana Carroll for taking time to review my thesis. Finally, I would like to thank my wife and family for the help, support, and encouragement. Contents 1 Introduction 1 1.1 Sorting Networks ..... 2 1.2 Contributions . ..... 5 1.3 Structure of this Thesis .. 6 2 Expander Graphs and Related Constructions 8 2.1 Expander Graphs .... 8 2.2 Explicit Constructions 12 3 The Construction of e -halvers 16 3.1 e-halvers . ....... 17 3.2 Matching ..... 20 3.3 Explicit Construction .. ...... 24 4 Separators 31 4.1 (,x, f, fO)- separators ........ 31 4.2 Construction of the New Separator 34 4.3 Parameter of the New Separator .. ..... 36 ii 5 Paterson's Algorithm 39 5.1 A Tree-sort Metaphor . ........ ...... 40 5.2 The Parameters and Constraints. 41 5.3 On the Boundary ....