A Time-Based Adaptive Hybrid Sorting Algorithm on CPU and GPU with Application to Collision Detection
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

The Analysis and Synthesis of a Parallel Sorting Engine Redacted for Privacy Abstract Approv, John M
AN ABSTRACT OF THE THESIS OF Byoungchul Ahn for the degree of Doctor of Philosophy in Electrical and Computer Engineering, presented on May 3. 1989. Title: The Analysis and Synthesis of a Parallel Sorting Engine Redacted for Privacy Abstract approv, John M. Murray / Thisthesisisconcerned withthe development of a unique parallelsort-mergesystemsuitablefor implementationinVLSI. Two new sorting subsystems, a high performance VLSI sorter and a four-waymerger,werealsorealizedduringthedevelopment process. In addition, the analysis of several existing parallel sorting architectures and algorithms was carried out. Algorithmic time complexity, VLSI processor performance, and chiparearequirementsfortheexistingsortingsystemswere evaluated.The rebound sorting algorithm was determined to be the mostefficientamongthoseconsidered. The reboundsorter algorithm was implementedinhardware asasystolicarraywith external expansion capability. The second phase of the research involved analyzing several parallel merge algorithms andtheirbuffer management schemes. The dominant considerations for this phase of the research were the achievement of minimum VLSI chiparea,design complexity, and logicdelay. Itwasdeterminedthattheproposedmerger architecture could be implemented inseveral ways. Selecting the appropriate microarchitecture for the merger, given the constraints of chip area and performance, was the major problem.The tradeoffs associated with this process are outlined. Finally,apipelinedsort-merge system was implementedin VLSI by combining a rebound sorter -

Optimizing Sorting with Genetic Algorithms ∗
Optimizing Sorting with Genetic Algorithms ∗ Xiaoming Li, Mar´ıa Jesus´ Garzaran´ and David Padua Department of Computer Science University of Illinois at Urbana-Champaign {xli15, garzaran, padua}@cs.uiuc.edu http://polaris.cs.uiuc.edu Abstract 1 Introduction Although compiler technology has been extraordinarily The growing complexity of modern processors has made successful at automating the process of program optimiza- the generation of highly efficient code increasingly difficult. tion, much human intervention is still needed to obtain high- Manual code generation is very time consuming, but it is of- quality code. One reason is the unevenness of compiler im- ten the only choice since the code generated by today’s com- plementations. There are excellent optimizing compilers for piler technology often has much lower performance than some platforms, but the compilers available for some other the best hand-tuned codes. A promising code generation platforms leave much to be desired. A second, and perhaps strategy, implemented by systems like ATLAS, FFTW, and more important, reason is that conventional compilers lack SPIRAL, uses empirical search to find the parameter values semantic information and, therefore, have limited transfor- of the implementation, such as the tile size and instruction mation power. An emerging approach that has proven quite schedules, that deliver near-optimal performance for a par- effective in overcoming both of these limitations is to use ticular machine. However, this approach has only proven library generators. These systems make use of semantic in- successful on scientific codes whose performance does not formation to apply transformations at all levels of abstrac- depend on the input data. -

Bubble Sort, Selection Sort, and Insertion Sort
Data Structures & Algorithms Lecture 3 & 4: Searching and Sorting Algorithm Halabja University Collage of Science /Computer Science Department Karwan Mahdi [email protected] 2020-2021 Objectives Introduction to Search Algorithms which is consist of Linear Search and Binary Search Understand the significance of sorting Distinguish between internal and external sorting Understand the logic behind the simple sorting methods of bubble sort, selection sort, and insertion sort. Introduction to Search Algorithms Search: locate an item in a list of information. Two common algorithms (methods): • Linear search • Binary search Linear search: also called sequential search. Examines all values in an array until it finds a match or reaches the end. • Number of visits for a linear search of an array of n elements: • The average search visits n/2 elements • The maximum visits is n • A linear search locates a value in an array in O(n) steps Example for linear search Example: linear search Algorithm of Linear Search Order in linear search Advantages and Disadvantages • Benefits: • Easy algorithm to understand • Array can be in any order • Disadvantages: • Inefficient (slow): for array of N elements, examines N/2 elements on average for value in array, • N elements for value not in array “Java code for linear search REQUIRE” Binary Search Binary search is a smart algorithm that is much more efficient than the linear search ,the elements in the array must be sorted in order 1. Divides the array into three sections: • middle element • elements on one side of the middle element • elements on the other side of the middle element 2. -

Improving the Performance of Bubble Sort Using a Modified Diminishing Increment Sorting
Scientific Research and Essay Vol. 4 (8), pp. 740-744, August, 2009 Available online at http://www.academicjournals.org/SRE ISSN 1992-2248 © 2009 Academic Journals Full Length Research Paper Improving the performance of bubble sort using a modified diminishing increment sorting Oyelami Olufemi Moses Department of Computer and Information Sciences, Covenant University, P. M. B. 1023, Ota, Ogun State, Nigeria. E- mail: [email protected] or [email protected]. Tel.: +234-8055344658. Accepted 17 February, 2009 Sorting involves rearranging information into either ascending or descending order. There are many sorting algorithms, among which is Bubble Sort. Bubble Sort is not known to be a very good sorting algorithm because it is beset with redundant comparisons. However, efforts have been made to improve the performance of the algorithm. With Bidirectional Bubble Sort, the average number of comparisons is slightly reduced and Batcher’s Sort similar to Shellsort also performs significantly better than Bidirectional Bubble Sort by carrying out comparisons in a novel way so that no propagation of exchanges is necessary. Bitonic Sort was also presented by Batcher and the strong point of this sorting procedure is that it is very suitable for a hard-wired implementation using a sorting network. This paper presents a meta algorithm called Oyelami’s Sort that combines the technique of Bidirectional Bubble Sort with a modified diminishing increment sorting. The results from the implementation of the algorithm compared with Batcher’s Odd-Even Sort and Batcher’s Bitonic Sort showed that the algorithm performed better than the two in the worst case scenario. The implication is that the algorithm is faster. -

Edsger W. Dijkstra: a Commemoration
Edsger W. Dijkstra: a Commemoration Krzysztof R. Apt1 and Tony Hoare2 (editors) 1 CWI, Amsterdam, The Netherlands and MIMUW, University of Warsaw, Poland 2 Department of Computer Science and Technology, University of Cambridge and Microsoft Research Ltd, Cambridge, UK Abstract This article is a multiauthored portrait of Edsger Wybe Dijkstra that consists of testimo- nials written by several friends, colleagues, and students of his. It provides unique insights into his personality, working style and habits, and his influence on other computer scientists, as a researcher, teacher, and mentor. Contents Preface 3 Tony Hoare 4 Donald Knuth 9 Christian Lengauer 11 K. Mani Chandy 13 Eric C.R. Hehner 15 Mark Scheevel 17 Krzysztof R. Apt 18 arXiv:2104.03392v1 [cs.GL] 7 Apr 2021 Niklaus Wirth 20 Lex Bijlsma 23 Manfred Broy 24 David Gries 26 Ted Herman 28 Alain J. Martin 29 J Strother Moore 31 Vladimir Lifschitz 33 Wim H. Hesselink 34 1 Hamilton Richards 36 Ken Calvert 38 David Naumann 40 David Turner 42 J.R. Rao 44 Jayadev Misra 47 Rajeev Joshi 50 Maarten van Emden 52 Two Tuesday Afternoon Clubs 54 2 Preface Edsger Dijkstra was perhaps the best known, and certainly the most discussed, computer scientist of the seventies and eighties. We both knew Dijkstra |though each of us in different ways| and we both were aware that his influence on computer science was not limited to his pioneering software projects and research articles. He interacted with his colleagues by way of numerous discussions, extensive letter correspondence, and hundreds of so-called EWD reports that he used to send to a select group of researchers. -

Parallel Sorting Algorithms + Topic Overview
+ Design of Parallel Algorithms Parallel Sorting Algorithms + Topic Overview n Issues in Sorting on Parallel Computers n Sorting Networks n Bubble Sort and its Variants n Quicksort n Bucket and Sample Sort n Other Sorting Algorithms + Sorting: Overview n One of the most commonly used and well-studied kernels. n Sorting can be comparison-based or noncomparison-based. n The fundamental operation of comparison-based sorting is compare-exchange. n The lower bound on any comparison-based sort of n numbers is Θ(nlog n) . n We focus here on comparison-based sorting algorithms. + Sorting: Basics What is a parallel sorted sequence? Where are the input and output lists stored? n We assume that the input and output lists are distributed. n The sorted list is partitioned with the property that each partitioned list is sorted and each element in processor Pi's list is less than that in Pj's list if i < j. + Sorting: Parallel Compare Exchange Operation A parallel compare-exchange operation. Processes Pi and Pj send their elements to each other. Process Pi keeps min{ai,aj}, and Pj keeps max{ai, aj}. + Sorting: Basics What is the parallel counterpart to a sequential comparator? n If each processor has one element, the compare exchange operation stores the smaller element at the processor with smaller id. This can be done in ts + tw time. n If we have more than one element per processor, we call this operation a compare split. Assume each of two processors have n/p elements. n After the compare-split operation, the smaller n/p elements are at processor Pi and the larger n/p elements at Pj, where i < j. -
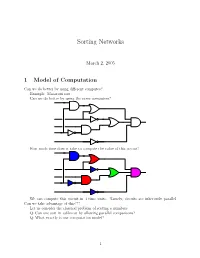
Sorting Networks
Sorting Networks March 2, 2005 1 Model of Computation Can we do better by using different computes? Example: Macaroni sort. Can we do better by using the same computers? How much time does it take to compute the value of this circuit? We can compute this circuit in 4 time units. Namely, circuits are inherently parallel. Can we take advantage of this??? Let us consider the classical problem of sorting n numbers. Q: Can one sort in sublinear by allowing parallel comparisons? Q: What exactly is our computation model? 1 1.1 Computing with a circuit We are going to design a circuit, where the inputs are the numbers, and we compare two numbers using a comparator gate: ¢¤¦© ¡ ¡ Comparator ¡£¢¥¤§¦©¨ ¡ For our drawings, we will draw such a gate as follows: ¢¡¤£¦¥¨§ © ¡£¦ So, circuits would just be horizontal lines, with vertical segments (i.e., gates) between them. A complete sorting network, looks like: The inputs come on the wires on the left, and are output on the wires on the right. The largest number is output on the bottom line. The surprising thing, is that one can generate circuits from a sorting algorithm. In fact, consider the following circuit: Q: What does this circuit does? A: This is the inner loop of insertion sort. Repeating this inner loop, we get the following sorting network: 2 Alternative way of drawing it: Q: How much time does it take for this circuit to sort the n numbers? Running time = how many time clocks we have to wait till the result stabilizes. In this case: 5 1 2 3 4 6 7 8 9 In general, we get: Lemma 1.1 Insertion sort requires 2n − 1 time units to sort n numbers. -

Space-Efficient Data Structures, Streams, and Algorithms
Andrej Brodnik Alejandro López-Ortiz Venkatesh Raman Alfredo Viola (Eds.) Festschrift Space-Efficient Data Structures, Streams, LNCS 8066 and Algorithms Papers in Honor of J. Ian Munro on the Occasion of His 66th Birthday 123 Lecture Notes in Computer Science 8066 Commenced Publication in 1973 Founding and Former Series Editors: Gerhard Goos, Juris Hartmanis, and Jan van Leeuwen Editorial Board David Hutchison Lancaster University, UK Takeo Kanade Carnegie Mellon University, Pittsburgh, PA, USA Josef Kittler University of Surrey, Guildford, UK Jon M. Kleinberg Cornell University, Ithaca, NY, USA Alfred Kobsa University of California, Irvine, CA, USA Friedemann Mattern ETH Zurich, Switzerland John C. Mitchell Stanford University, CA, USA Moni Naor Weizmann Institute of Science, Rehovot, Israel Oscar Nierstrasz University of Bern, Switzerland C. Pandu Rangan Indian Institute of Technology, Madras, India Bernhard Steffen TU Dortmund University, Germany Madhu Sudan Microsoft Research, Cambridge, MA, USA Demetri Terzopoulos University of California, Los Angeles, CA, USA Doug Tygar University of California, Berkeley, CA, USA Gerhard Weikum Max Planck Institute for Informatics, Saarbruecken, Germany Andrej Brodnik Alejandro López-Ortiz Venkatesh Raman Alfredo Viola (Eds.) Space-Efficient Data Structures, Streams, and Algorithms Papers in Honor of J. Ian Munro on the Occasion of His 66th Birthday 13 Volume Editors Andrej Brodnik University of Ljubljana, Faculty of Computer and Information Science Ljubljana, Slovenia and University of Primorska, -

Foundations of Differentially Oblivious Algorithms
Foundations of Differentially Oblivious Algorithms T-H. Hubert Chan Kai-Min Chung Bruce Maggs Elaine Shi August 5, 2020 Abstract It is well-known that a program's memory access pattern can leak information about its input. To thwart such leakage, most existing works adopt the technique of oblivious RAM (ORAM) simulation. Such an obliviousness notion has stimulated much debate. Although ORAM techniques have significantly improved over the past few years, the concrete overheads are arguably still undesirable for real-world systems | part of this overhead is in fact inherent due to a well-known logarithmic ORAM lower bound by Goldreich and Ostrovsky. To make matters worse, when the program's runtime or output length depend on secret inputs, it may be necessary to perform worst-case padding to achieve full obliviousness and thus incur possibly super-linear overheads. Inspired by the elegant notion of differential privacy, we initiate the study of a new notion of access pattern privacy, which we call \(, δ)-differential obliviousness". We separate the notion of (, δ)-differential obliviousness from classical obliviousness by considering several fundamental algorithmic abstractions including sorting small-length keys, merging two sorted lists, and range query data structures (akin to binary search trees). We show that by adopting differential obliv- iousness with reasonable choices of and δ, not only can one circumvent several impossibilities pertaining to full obliviousness, one can also, in several cases, obtain meaningful privacy with little overhead relative to the non-private baselines (i.e., having privacy \almost for free"). On the other hand, we show that for very demanding choices of and δ, the same lower bounds for oblivious algorithms would be preserved for (, δ)-differential obliviousness. -

Lecture 8.Key
CSC 391/691: GPU Programming Fall 2015 Parallel Sorting Algorithms Copyright © 2015 Samuel S. Cho Sorting Algorithms Review 2 • Bubble Sort: O(n ) 2 • Insertion Sort: O(n ) • Quick Sort: O(n log n) • Heap Sort: O(n log n) • Merge Sort: O(n log n) • The best we can expect from a sequential sorting algorithm using p processors (if distributed evenly among the n elements to be sorted) is O(n log n) / p ~ O(log n). Compare and Exchange Sorting Algorithms • Form the basis of several, if not most, classical sequential sorting algorithms. • Two numbers, say A and B, are compared between P0 and P1. P0 P1 A B MIN MAX Bubble Sort • Generic example of a “bad” sorting 0 1 2 3 4 5 algorithm. start: 1 3 8 0 6 5 0 1 2 3 4 5 Algorithm: • after pass 1: 1 3 0 6 5 8 • Compare neighboring elements. • Swap if neighbor is out of order. 0 1 2 3 4 5 • Two nested loops. after pass 2: 1 0 3 5 6 8 • Stop when a whole pass 0 1 2 3 4 5 completes without any swaps. after pass 3: 0 1 3 5 6 8 0 1 2 3 4 5 • Performance: 2 after pass 4: 0 1 3 5 6 8 Worst: O(n ) • 2 • Average: O(n ) fin. • Best: O(n) "The bubble sort seems to have nothing to recommend it, except a catchy name and the fact that it leads to some interesting theoretical problems." - Donald Knuth, The Art of Computer Programming Odd-Even Transposition Sort (also Brick Sort) • Simple sorting algorithm that was introduced in 1972 by Nico Habermann who originally developed it for parallel architectures (“Parallel Neighbor-Sort”). -

Sorting Algorithm 1 Sorting Algorithm
Sorting algorithm 1 Sorting algorithm In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order. Efficient sorting is important for optimizing the use of other algorithms (such as search and merge algorithms) that require sorted lists to work correctly; it is also often useful for canonicalizing data and for producing human-readable output. More formally, the output must satisfy two conditions: 1. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order); 2. The output is a permutation, or reordering, of the input. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement. For example, bubble sort was analyzed as early as 1956.[1] Although many consider it a solved problem, useful new sorting algorithms are still being invented (for example, library sort was first published in 2004). Sorting algorithms are prevalent in introductory computer science classes, where the abundance of algorithms for the problem provides a gentle introduction to a variety of core algorithm concepts, such as big O notation, divide and conquer algorithms, data structures, randomized algorithms, best, worst and average case analysis, time-space tradeoffs, and lower bounds. Classification Sorting algorithms used in computer science are often classified by: • Computational complexity (worst, average and best behaviour) of element comparisons in terms of the size of the list . For typical sorting algorithms good behavior is and bad behavior is . -

Binary Search Algorithm This Article Is About Searching a Finite Sorted Array
Binary search algorithm This article is about searching a finite sorted array. For searching continuous function values, see bisection method. This article may require cleanup to meet Wikipedia's quality standards. No cleanup reason has been specified. Please help improve this article if you can. (April 2011) Binary search algorithm Class Search algorithm Data structure Array Worst case performance O (log n ) Best case performance O (1) Average case performance O (log n ) Worst case space complexity O (1) In computer science, a binary search or half-interval search algorithm finds the position of a specified input value (the search "key") within an array sorted by key value.[1][2] For binary search, the array should be arranged in ascending or descending order. In each step, the algorithm compares the search key value with the key value of the middle element of the array. If the keys match, then a matching element has been found and its index, or position, is returned. Otherwise, if the search key is less than the middle element's key, then the algorithm repeats its action on the sub-array to the left of the middle element or, if the search key is greater, on the sub-array to the right. If the remaining array to be searched is empty, then the key cannot be found in the array and a special "not found" indication is returned. A binary search halves the number of items to check with each iteration, so locating an item (or determining its absence) takes logarithmic time. A binary search is a dichotomic divide and conquer search algorithm.