Arxiv:1812.03318V1 [Cs.SE] 8 Dec 2018 Rived from Merge Sort and Insertion Sort, Designed to Work Well on Many Kinds of Real-World Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sorting Algorithm 1 Sorting Algorithm
Sorting algorithm 1 Sorting algorithm In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order. Efficient sorting is important for optimizing the use of other algorithms (such as search and merge algorithms) that require sorted lists to work correctly; it is also often useful for canonicalizing data and for producing human-readable output. More formally, the output must satisfy two conditions: 1. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order); 2. The output is a permutation, or reordering, of the input. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement. For example, bubble sort was analyzed as early as 1956.[1] Although many consider it a solved problem, useful new sorting algorithms are still being invented (for example, library sort was first published in 2004). Sorting algorithms are prevalent in introductory computer science classes, where the abundance of algorithms for the problem provides a gentle introduction to a variety of core algorithm concepts, such as big O notation, divide and conquer algorithms, data structures, randomized algorithms, best, worst and average case analysis, time-space tradeoffs, and lower bounds. Classification Sorting algorithms used in computer science are often classified by: • Computational complexity (worst, average and best behaviour) of element comparisons in terms of the size of the list . For typical sorting algorithms good behavior is and bad behavior is . -

How to Sort out Your Life in O(N) Time
How to sort out your life in O(n) time arel Číže @kaja47K funkcionaklne.cz I said, "Kiss me, you're beautiful - These are truly the last days" Godspeed You! Black Emperor, The Dead Flag Blues Everyone, deep in their hearts, is waiting for the end of the world to come. Haruki Murakami, 1Q84 ... Free lunch 1965 – 2022 Cramming More Components onto Integrated Circuits http://www.cs.utexas.edu/~fussell/courses/cs352h/papers/moore.pdf He pays his staff in junk. William S. Burroughs, Naked Lunch Sorting? quicksort and chill HS 1964 QS 1959 MS 1945 RS 1887 quicksort, mergesort, heapsort, radix sort, multi- way merge sort, samplesort, insertion sort, selection sort, library sort, counting sort, bucketsort, bitonic merge sort, Batcher odd-even sort, odd–even transposition sort, radix quick sort, radix merge sort*, burst sort binary search tree, B-tree, R-tree, VP tree, trie, log-structured merge tree, skip list, YOLO tree* vs. hashing Robin Hood hashing https://cs.uwaterloo.ca/research/tr/1986/CS-86-14.pdf xs.sorted.take(k) (take (sort xs) k) qsort(lotOfIntegers) It may be the wrong decision, but fuck it, it's mine. (Mark Z. Danielewski, House of Leaves) I tell you, my man, this is the American Dream in action! We’d be fools not to ride this strange torpedo all the way out to the end. (HST, FALILV) Linear time sorting? I owe the discovery of Uqbar to the conjunction of a mirror and an Encyclopedia. (Jorge Luis Borges, Tlön, Uqbar, Orbis Tertius) Sorting out graph processing https://github.com/frankmcsherry/blog/blob/master/posts/2015-08-15.md Radix Sort Revisited http://www.codercorner.com/RadixSortRevisited.htm Sketchy radix sort https://github.com/kaja47/sketches (thinking|drinking|WTF)* I know they accuse me of arrogance, and perhaps misanthropy, and perhaps of madness. -

Gsoc 2018 Project Proposal
GSoC 2018 Project Proposal Description: Implement the project idea sorting algorithms benchmark and implementation (2018) Applicant Information: Name: Kefan Yang Country of Residence: Canada University: Simon Fraser University Year of Study: Third year Major: Computing Science Self Introduction: I am Kefan Yang, a third-year computing science student from Simon Fraser University, Canada. I have rich experience as a full-stack web developer, so I am familiar with different kinds of database, such as PostgreSQL, MySQL and MongoDB. I have a much better understand of database system other than how to use it. In the database course I took in the university, I implemented a simple SQL database. It supports basic SQL statements like select, insert, delete and update, and uses a B+ tree to index the records by default. The size of each node in the B+ tree is set the disk block size to maximize performance of disk operation. Also, 1 several kinds of merging algorithms are used to perform a cross table query. More details about this database project can be found here. Additionally, I have very solid foundation of basic algorithms and data structure. I’ve participated in division 1 contest of 2017 ACM-ICPC Pacific Northwest Regionals as a representative of Simon Fraser University, which clearly shows my talents in understanding and applying different kinds of algorithms. I believe the contest experience will be a big help for this project. Benefits to the PostgreSQL Community: Sorting routine is an important part of many modules in PostgreSQL. Currently, PostgreSQL is using median-of-three quicksort introduced by Bentley and Mcllroy in 1993 [1], which is somewhat outdated. -

View Publication
Patience is a Virtue: Revisiting Merge and Sort on Modern Processors Badrish Chandramouli and Jonathan Goldstein Microsoft Research {badrishc, jongold}@microsoft.com ABSTRACT In particular, the vast quantities of almost sorted log-based data The vast quantities of log-based data appearing in data centers has appearing in data centers has generated this interest. In these generated an interest in sorting almost-sorted datasets. We revisit scenarios, data is collected from many servers, and brought the problem of sorting and merging data in main memory, and show together either immediately, or periodically (e.g. every minute), that a long-forgotten technique called Patience Sort can, with some and stored in a log. The log is then typically sorted, sometimes in key modifications, be made competitive with today’s best multiple ways, according to the types of questions being asked. If comparison-based sorting techniques for both random and almost those questions are temporal in nature [7][17][18], it is required that sorted data. Patience sort consists of two phases: the creation of the log be sorted on time. A widely-used technique for sorting sorted runs, and the merging of these runs. Through a combination almost sorted data is Timsort [8], which works by finding of algorithmic and architectural innovations, we dramatically contiguous runs of increasing or decreasing value in the dataset. improve Patience sort for both random and almost-ordered data. Of Our investigation has resulted in some surprising discoveries about particular interest is a new technique called ping-pong merge for a mostly-ignored 50-year-old sorting technique called Patience merging sorted runs in main memory. -

Sorting Algorithm 1 Sorting Algorithm
Sorting algorithm 1 Sorting algorithm A sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order. Efficient sorting is important for optimizing the use of other algorithms (such as search and merge algorithms) which require input data to be in sorted lists; it is also often useful for canonicalizing data and for producing human-readable output. More formally, the output must satisfy two conditions: 1. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order); 2. The output is a permutation (reordering) of the input. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement. For example, bubble sort was analyzed as early as 1956.[1] Although many consider it a solved problem, useful new sorting algorithms are still being invented (for example, library sort was first published in 2006). Sorting algorithms are prevalent in introductory computer science classes, where the abundance of algorithms for the problem provides a gentle introduction to a variety of core algorithm concepts, such as big O notation, divide and conquer algorithms, data structures, randomized algorithms, best, worst and average case analysis, time-space tradeoffs, and upper and lower bounds. Classification Sorting algorithms are often classified by: • Computational complexity (worst, average and best behavior) of element comparisons in terms of the size of the list (n). For typical serial sorting algorithms good behavior is O(n log n), with parallel sort in O(log2 n), and bad behavior is O(n2). -

From Merge Sort to Timsort Nicolas Auger, Cyril Nicaud, Carine Pivoteau
Merge Strategies: from Merge Sort to TimSort Nicolas Auger, Cyril Nicaud, Carine Pivoteau To cite this version: Nicolas Auger, Cyril Nicaud, Carine Pivoteau. Merge Strategies: from Merge Sort to TimSort. 2015. hal-01212839v2 HAL Id: hal-01212839 https://hal-upec-upem.archives-ouvertes.fr/hal-01212839v2 Preprint submitted on 9 Dec 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Merge Strategies: from Merge Sort to TimSort Nicolas Auger, Cyril Nicaud, and Carine Pivoteau Universit´eParis-Est, LIGM (UMR 8049), F77454 Marne-la-Vall´ee,France fauger,nicaud,[email protected] Abstract. The introduction of TimSort as the standard algorithm for sorting in Java and Python questions the generally accepted idea that merge algorithms are not competitive for sorting in practice. In an at- tempt to better understand TimSort algorithm, we define a framework to study the merging cost of sorting algorithms that relies on merges of monotonic subsequences of the input. We design a simpler yet competi- tive algorithm in the spirit of TimSort based on the same kind of ideas. As a benefit, our framework allows to establish the announced running time of TimSort, that is, O(n log n). -

On the Worst-Case Complexity of Timsort Nicolas Auger, Vincent Jugé, Cyril Nicaud, Carine Pivoteau
On the Worst-Case Complexity of TimSort Nicolas Auger, Vincent Jugé, Cyril Nicaud, Carine Pivoteau To cite this version: Nicolas Auger, Vincent Jugé, Cyril Nicaud, Carine Pivoteau. On the Worst-Case Complexity of TimSort. 26th Annual European Symposium on Algorithms (ESA 2018), Aug 2018, Helsinki, Finland. pp.4:1–4:13, 10.4230/LIPIcs.ESA.2018.4. hal-01798381 HAL Id: hal-01798381 https://hal.archives-ouvertes.fr/hal-01798381 Submitted on 23 May 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. On the Worst-Case Complexity of TimSort Nicolas Auger Université Paris-Est, LIGM (UMR 8049), UPEM, F77454 Marne-la-Vallée, France Vincent Jugé Université Paris-Est, LIGM (UMR 8049), UPEM, F77454 Marne-la-Vallée, France Cyril Nicaud Université Paris-Est, LIGM (UMR 8049), UPEM, F77454 Marne-la-Vallée, France Carine Pivoteau Université Paris-Est, LIGM (UMR 8049), UPEM, F77454 Marne-la-Vallée, France Abstract TimSort is an intriguing sorting algorithm designed in 2002 for Python, whose worst-case com- plexity was announced, but not proved until our recent preprint. In fact, there are two slightly different versions of TimSort that are currently implemented in Python and in Java respec- tively. -

A Comparative Study of Sorting Algorithms with FPGA Acceleration by High Level Synthesis
A Comparative Study of Sorting Algorithms with FPGA Acceleration by High Level Synthesis Yomna Ben Jmaa1,2, Rabie Ben Atitallah2, David Duvivier2, Maher Ben Jemaa1 1 NIS University of Sfax, ReDCAD, Tunisia 2 Polytechnical University Hauts-de-France, France [email protected], fRabie.BenAtitallah, [email protected], [email protected] Abstract. Nowadays, sorting is an important operation the risk of accidents, the traffic jams and pollution. for several real-time embedded applications. It is one Also, ITS improve the transport efficiency, safety of the most commonly studied problems in computer and security of passengers. They are used in science. It can be considered as an advantage for various domains such as railways, avionics and some applications such as avionic systems and decision automotive technology. At different steps, several support systems because these applications need a applications need to use sorting algorithms such sorting algorithm for their implementation. However, as decision support systems, path planning [6], sorting a big number of elements and/or real-time de- cision making need high processing speed. Therefore, scheduling and so on. accelerating sorting algorithms using FPGA can be an attractive solution. In this paper, we propose an efficient However, the complexity and the targeted hardware implementation for different sorting algorithms execution platform(s) are the main performance (BubbleSort, InsertionSort, SelectionSort, QuickSort, criteria for sorting algorithms. Different platforms HeapSort, ShellSort, MergeSort and TimSort) from such as CPU (single or multi-core), GPU (Graphics high-level descriptions in the zynq-7000 platform. In Processing Unit), FPGA (Field Programmable addition, we compare the performance of different Gate Array) [14] and heterogeneous architectures algorithms in terms of execution time, standard deviation can be used. -

Parallelization of Tim Sort Algorithm Using Mpi and Cuda
JOURNAL OF CRITICAL REVIEWS ISSN- 2394-5125 VOL 7, ISSUE 09, 2020 PARALLELIZATION OF TIM SORT ALGORITHM USING MPI AND CUDA Siva Thanagaraja1, Keshav Shanbhag2, Ashwath Rao B3[0000-0001-8528-1646], Shwetha Rai4[0000-0002-5714-2611], and N Gopalakrishna Kini5 Department of Computer Science & Engineering Manipal Institute Of Technology Manipal Academy Of Higher Education Manipal, Karnataka, India-576104 Abstract— Tim Sort is a sorting algorithm developed in 2002 by Tim Peters. It is one of the secure engineered algorithms, and its high-level principle includes the sequence S is divided into monotonic runs (i.e., non- increasing or non-decreasing subsequence of S), which should be sorted and should be combined pairwise according to some specific rules. To interpret and examine the merging strategy (meaning that the order in which merge and merge runs are performed) of Tim Sort, we have implemented it in MPI and CUDA environment. Finally, it can be seen the difference in the execution time between serial Tim Sort and parallel Tim sort run in O (n log n) time . Index Terms— Hybrid algorithm, Tim sort algorithm, Parallelization, Merge sort algorithm, Insertion sort algorithm. I. INTRODUCTION Sorting algorithm Tim Sort [1] was designed in 2002 by Tim Peters. It is a hybrid parallel sorting algorithm that combines two different sorting algorithms. This includes insertion sort and merge sort. This algorithm is an effective method for well-defined instructions. The algorithm is concealed as a finite list for evaluating Tim sort function. Starting from an initial state and its information the guidelines define a method that when execution continues through a limited number of next states. -

On the Worst-Case Complexity of Timsort
On the Worst-Case Complexity of TimSort Nicolas Auger Université Paris-Est, LIGM (UMR 8049), UPEM, F77454 Marne-la-Vallée, France Vincent Jugé Université Paris-Est, LIGM (UMR 8049), UPEM, F77454 Marne-la-Vallée, France Cyril Nicaud Université Paris-Est, LIGM (UMR 8049), UPEM, F77454 Marne-la-Vallée, France Carine Pivoteau Université Paris-Est, LIGM (UMR 8049), UPEM, F77454 Marne-la-Vallée, France Abstract TimSort is an intriguing sorting algorithm designed in 2002 for Python, whose worst-case com- plexity was announced, but not proved until our recent preprint. In fact, there are two slightly different versions of TimSort that are currently implemented in Python and in Java respec- tively. We propose a pedagogical and insightful proof that the Python version runs in O(n log n). The approach we use in the analysis also applies to the Java version, although not without very involved technical details. As a byproduct of our study, we uncover a bug in the Java implemen- tation that can cause the sorting method to fail during the execution. We also give a proof that Python’s TimSort running time is in O(n+n log ρ), where ρ is the number of runs (i.e. maximal monotonic sequences), which is quite a natural parameter here and part of the explanation for the good behavior of TimSort on partially sorted inputs. 2012 ACM Subject Classification Theory of computation → Sorting and searching Keywords and phrases Sorting algorithms, Merge sorting algorithms, TimSort, Analysis of al- gorithms Digital Object Identifier 10.4230/LIPIcs.ESA.2018.4 1 Introduction TimSort is a sorting algorithm designed in 2002 by Tim Peters [9], for use in the Python programming language. -

Partitioning - the Heart of Quicksort
Announcements Last normal lecture for 3 weeks. ・Sign up for Coursera if you have not already. ・Next week’s video lectures will be available tomorrow at 2 PM. – Exercises also posted (so you can test comprehension). ・Watch Priority Queues lecture before Monday. – 52 minutes. Can be watched at anywhere from 0.5x to 2x speed. – If you don’t, you will be lost. ・No new material during flipped lecture. – Mini-lecture on big picture issues. – Solve interesting problems (including old exam problems). – Any questions under pinned post on Piazza will be answered. 1 Survey says... 2 Survey says... 3 Survey says... 4 Algorithms ROBERT SEDGEWICK | KEVIN WAYNE 2.3 QUICKSORT ‣ quicksort ‣ selection Algorithms ‣ duplicate keys FOURTH EDITION ‣ system sorts ROBERT SEDGEWICK | KEVIN WAYNE http://algs4.cs.princeton.edu Two classic sorting algorithms Critical components in the world’s computational infrastructure. ・Full scientific understanding of their properties has enabled us to develop them into practical system sorts. ・Quicksort honored as one of top 10 algorithms of 20th century in science and engineering. Mergesort: 4 Quicksort: 4 Mergesort. last lecture ・Java sort for objects. ・Perl, C++ stable sort, Python stable sort, Firefox JavaScript, ... Quicksort. this lecture ・Java sort for primitive types. ・C qsort, Unix, Visual C++, Python, Matlab, Chrome JavaScript, ... 6 Quicksort t-shirt Mergesort: 4 Quicksort: 5 7 2.3 QUICKSORT ‣ quicksort ‣ selection Algorithms ‣ duplicate keys ‣ system sorts ROBERT SEDGEWICK | KEVIN WAYNE http://algs4.cs.princeton.edu Partitioning - the heart of Quicksort Partitioning. ・To Partition an array a[] on element x=a[i] is to rearrange it such that – x moves to position j (may be the same as i) – All entries to the left of x are <= x. -
Big-O Algorithm Complexity Cheat Sheet
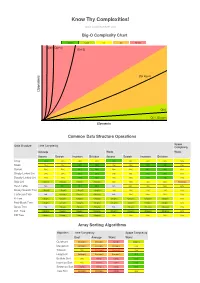
Know Thy Complexities! www.bigocheatsheet.com Big-O Complexity Chart Excellent Good Fair Bad Horrible O(n!) O(2^n) O(n^2) s O(n log n) n o i t a r e p O O(n) O(1), O(log n) Elements Common Data Structure Operations Space Data Structure Time Complexity Complexity Average Worst Worst Access Search Insertion Deletion Access Search Insertion Deletion Array O(1) O(n) O(n) O(n) O(1) O(n) O(n) O(n) O(n) Stack O(n) O(n) O(1) O(1) O(n) O(n) O(1) O(1) O(n) Queue O(n) O(n) O(1) O(1) O(n) O(n) O(1) O(1) O(n) Singly-Linked List O(n) O(n) O(1) O(1) O(n) O(n) O(1) O(1) O(n) Doubly-Linked List O(n) O(n) O(1) O(1) O(n) O(n) O(1) O(1) O(n) Skip List O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) O(n) O(n) O(n) O(n log(n)) Hash Table N/A O(1) O(1) O(1) N/A O(n) O(n) O(n) O(n) Binary Search Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) O(n) O(n) O(n) O(n) Cartesian Tree N/A O(log(n)) O(log(n)) O(log(n)) N/A O(n) O(n) O(n) O(n) B-Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) Red-Black Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) Splay Tree N/A O(log(n)) O(log(n)) O(log(n)) N/A O(log(n)) O(log(n)) O(log(n)) O(n) AVL Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) KD Tree O(log(n)) O(log(n)) O(log(n)) O(log(n)) O(n) O(n) O(n) O(n) O(n) Array Sorting Algorithms Algorithm Time Complexity Space Complexity Best Average Worst Worst Quicksort O(n log(n)) O(n log(n)) O(n^2) O(log(n)) Mergesort O(n log(n)) O(n log(n)) O(n log(n)) O(n)