A Comparison of Sorting Algorithms for the Connection Machine CM-2 Guy E
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Radix Sort Comparison Sort Runtime of O(N*Log(N)) Is Optimal
Radix Sort Comparison sort runtime of O(n*log(n)) is optimal • The problem of sorting cannot be solved using comparisons with less than n*log(n) time complexity • See Proposition I in Chapter 2.2 of the text How can we sort without comparison? • Consider the following approach: • Look at the least-significant digit • Group numbers with the same digit • Maintain relative order • Place groups back in array together • I.e., all the 0’s, all the 1’s, all the 2’s, etc. • Repeat for increasingly significant digits The characteristics of Radix sort • Least significant digit (LSD) Radix sort • a fast stable sorting algorithm • begins at the least significant digit (e.g. the rightmost digit) • proceeds to the most significant digit (e.g. the leftmost digit) • lexicographic orderings Generally Speaking • 1. Take the least significant digit (or group of bits) of each key • 2. Group the keys based on that digit, but otherwise keep the original order of keys. • This is what makes the LSD radix sort a stable sort. • 3. Repeat the grouping process with each more significant digit Generally Speaking public static void sort(String [] a, int W) { int N = a.length; int R = 256; String [] aux = new String[N]; for (int d = W - 1; d >= 0; --d) { aux = sorted array a by the dth character a = aux } } A Radix sort example A Radix sort example A Radix sort example • Problem: How to ? • Group the keys based on that digit, • but otherwise keep the original order of keys. Key-indexed counting • 1. Take the least significant digit (or group of bits) of each key • 2. -

1 Lower Bound on Runtime of Comparison Sorts
CS 161 Lecture 7 { Sorting in Linear Time Jessica Su (some parts copied from CLRS) 1 Lower bound on runtime of comparison sorts So far we've looked at several sorting algorithms { insertion sort, merge sort, heapsort, and quicksort. Merge sort and heapsort run in worst-case O(n log n) time, and quicksort runs in expected O(n log n) time. One wonders if there's something special about O(n log n) that causes no sorting algorithm to surpass it. As a matter of fact, there is! We can prove that any comparison-based sorting algorithm must run in at least Ω(n log n) time. By comparison-based, I mean that the algorithm makes all its decisions based on how the elements of the input array compare to each other, and not on their actual values. One example of a comparison-based sorting algorithm is insertion sort. Recall that insertion sort builds a sorted array by looking at the next element and comparing it with each of the elements in the sorted array in order to determine its proper position. Another example is merge sort. When we merge two arrays, we compare the first elements of each array and place the smaller of the two in the sorted array, and then we make other comparisons to populate the rest of the array. In fact, all of the sorting algorithms we've seen so far are comparison sorts. But today we will cover counting sort, which relies on the values of elements in the array, and does not base all its decisions on comparisons. -

Quicksort Z Merge Sort Z T(N) = Θ(N Lg(N)) Z Not In-Place CSE 680 Z Selection Sort (From Homework) Prof
Sorting Review z Insertion Sort Introduction to Algorithms z T(n) = Θ(n2) z In-place Quicksort z Merge Sort z T(n) = Θ(n lg(n)) z Not in-place CSE 680 z Selection Sort (from homework) Prof. Roger Crawfis z T(n) = Θ(n2) z In-place Seems pretty good. z Heap Sort Can we do better? z T(n) = Θ(n lg(n)) z In-place Sorting Comppgarison Sorting z Assumptions z Given a set of n values, there can be n! 1. No knowledge of the keys or numbers we permutations of these values. are sorting on. z So if we look at the behavior of the 2. Each key supports a comparison interface sorting algorithm over all possible n! or operator. inputs we can determine the worst-case 3. Sorting entire records, as opposed to complexity of the algorithm. numbers,,p is an implementation detail. 4. Each key is unique (just for convenience). Comparison Sorting Decision Tree Decision Tree Model z Decision tree model ≤ 1:2 > z Full binary tree 2:3 1:3 z A full binary tree (sometimes proper binary tree or 2- ≤≤> > tree) is a tree in which every node other than the leaves has two c hildren <1,2,3> ≤ 1:3 >><2,1,3> ≤ 2:3 z Internal node represents a comparison. z Ignore control, movement, and all other operations, just <1,3,2> <3,1,2> <2,3,1> <3,2,1> see comparison z Each leaf represents one possible result (a permutation of the elements in sorted order). -

An Evolutionary Approach for Sorting Algorithms
ORIENTAL JOURNAL OF ISSN: 0974-6471 COMPUTER SCIENCE & TECHNOLOGY December 2014, An International Open Free Access, Peer Reviewed Research Journal Vol. 7, No. (3): Published By: Oriental Scientific Publishing Co., India. Pgs. 369-376 www.computerscijournal.org Root to Fruit (2): An Evolutionary Approach for Sorting Algorithms PRAMOD KADAM AND Sachin KADAM BVDU, IMED, Pune, India. (Received: November 10, 2014; Accepted: December 20, 2014) ABstract This paper continues the earlier thought of evolutionary study of sorting problem and sorting algorithms (Root to Fruit (1): An Evolutionary Study of Sorting Problem) [1]and concluded with the chronological list of early pioneers of sorting problem or algorithms. Latter in the study graphical method has been used to present an evolution of sorting problem and sorting algorithm on the time line. Key words: Evolutionary study of sorting, History of sorting Early Sorting algorithms, list of inventors for sorting. IntroDUCTION name and their contribution may skipped from the study. Therefore readers have all the rights to In spite of plentiful literature and research extent this study with the valid proofs. Ultimately in sorting algorithmic domain there is mess our objective behind this research is very much found in documentation as far as credential clear, that to provide strength to the evolutionary concern2. Perhaps this problem found due to lack study of sorting algorithms and shift towards a good of coordination and unavailability of common knowledge base to preserve work of our forebear platform or knowledge base in the same domain. for upcoming generation. Otherwise coming Evolutionary study of sorting algorithm or sorting generation could receive hardly information about problem is foundation of futuristic knowledge sorting problems and syllabi may restrict with some base for sorting problem domain1. -

Improving the Performance of Bubble Sort Using a Modified Diminishing Increment Sorting
Scientific Research and Essay Vol. 4 (8), pp. 740-744, August, 2009 Available online at http://www.academicjournals.org/SRE ISSN 1992-2248 © 2009 Academic Journals Full Length Research Paper Improving the performance of bubble sort using a modified diminishing increment sorting Oyelami Olufemi Moses Department of Computer and Information Sciences, Covenant University, P. M. B. 1023, Ota, Ogun State, Nigeria. E- mail: [email protected] or [email protected]. Tel.: +234-8055344658. Accepted 17 February, 2009 Sorting involves rearranging information into either ascending or descending order. There are many sorting algorithms, among which is Bubble Sort. Bubble Sort is not known to be a very good sorting algorithm because it is beset with redundant comparisons. However, efforts have been made to improve the performance of the algorithm. With Bidirectional Bubble Sort, the average number of comparisons is slightly reduced and Batcher’s Sort similar to Shellsort also performs significantly better than Bidirectional Bubble Sort by carrying out comparisons in a novel way so that no propagation of exchanges is necessary. Bitonic Sort was also presented by Batcher and the strong point of this sorting procedure is that it is very suitable for a hard-wired implementation using a sorting network. This paper presents a meta algorithm called Oyelami’s Sort that combines the technique of Bidirectional Bubble Sort with a modified diminishing increment sorting. The results from the implementation of the algorithm compared with Batcher’s Odd-Even Sort and Batcher’s Bitonic Sort showed that the algorithm performed better than the two in the worst case scenario. The implication is that the algorithm is faster. -

Data Structures & Algorithms
DATA STRUCTURES & ALGORITHMS Tutorial 6 Questions SORTING ALGORITHMS Required Questions Question 1. Many operations can be performed faster on sorted than on unsorted data. For which of the following operations is this the case? a. checking whether one word is an anagram of another word, e.g., plum and lump b. findin the minimum value. c. computing an average of values d. finding the middle value (the median) e. finding the value that appears most frequently in the data Question 2. In which case, the following sorting algorithm is fastest/slowest and what is the complexity in that case? Explain. a. insertion sort b. selection sort c. bubble sort d. quick sort Question 3. Consider the sequence of integers S = {5, 8, 2, 4, 3, 6, 1, 7} For each of the following sorting algorithms, indicate the sequence S after executing each step of the algorithm as it sorts this sequence: a. insertion sort b. selection sort c. heap sort d. bubble sort e. merge sort Question 4. Consider the sequence of integers 1 T = {1, 9, 2, 6, 4, 8, 0, 7} Indicate the sequence T after executing each step of the Cocktail sort algorithm (see Appendix) as it sorts this sequence. Advanced Questions Question 5. A variant of the bubble sorting algorithm is the so-called odd-even transposition sort . Like bubble sort, this algorithm a total of n-1 passes through the array. Each pass consists of two phases: The first phase compares array[i] with array[i+1] and swaps them if necessary for all the odd values of of i. -

Parallel Sorting Algorithms + Topic Overview
+ Design of Parallel Algorithms Parallel Sorting Algorithms + Topic Overview n Issues in Sorting on Parallel Computers n Sorting Networks n Bubble Sort and its Variants n Quicksort n Bucket and Sample Sort n Other Sorting Algorithms + Sorting: Overview n One of the most commonly used and well-studied kernels. n Sorting can be comparison-based or noncomparison-based. n The fundamental operation of comparison-based sorting is compare-exchange. n The lower bound on any comparison-based sort of n numbers is Θ(nlog n) . n We focus here on comparison-based sorting algorithms. + Sorting: Basics What is a parallel sorted sequence? Where are the input and output lists stored? n We assume that the input and output lists are distributed. n The sorted list is partitioned with the property that each partitioned list is sorted and each element in processor Pi's list is less than that in Pj's list if i < j. + Sorting: Parallel Compare Exchange Operation A parallel compare-exchange operation. Processes Pi and Pj send their elements to each other. Process Pi keeps min{ai,aj}, and Pj keeps max{ai, aj}. + Sorting: Basics What is the parallel counterpart to a sequential comparator? n If each processor has one element, the compare exchange operation stores the smaller element at the processor with smaller id. This can be done in ts + tw time. n If we have more than one element per processor, we call this operation a compare split. Assume each of two processors have n/p elements. n After the compare-split operation, the smaller n/p elements are at processor Pi and the larger n/p elements at Pj, where i < j. -
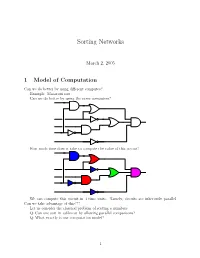
Sorting Networks
Sorting Networks March 2, 2005 1 Model of Computation Can we do better by using different computes? Example: Macaroni sort. Can we do better by using the same computers? How much time does it take to compute the value of this circuit? We can compute this circuit in 4 time units. Namely, circuits are inherently parallel. Can we take advantage of this??? Let us consider the classical problem of sorting n numbers. Q: Can one sort in sublinear by allowing parallel comparisons? Q: What exactly is our computation model? 1 1.1 Computing with a circuit We are going to design a circuit, where the inputs are the numbers, and we compare two numbers using a comparator gate: ¢¤¦© ¡ ¡ Comparator ¡£¢¥¤§¦©¨ ¡ For our drawings, we will draw such a gate as follows: ¢¡¤£¦¥¨§ © ¡£¦ So, circuits would just be horizontal lines, with vertical segments (i.e., gates) between them. A complete sorting network, looks like: The inputs come on the wires on the left, and are output on the wires on the right. The largest number is output on the bottom line. The surprising thing, is that one can generate circuits from a sorting algorithm. In fact, consider the following circuit: Q: What does this circuit does? A: This is the inner loop of insertion sort. Repeating this inner loop, we get the following sorting network: 2 Alternative way of drawing it: Q: How much time does it take for this circuit to sort the n numbers? Running time = how many time clocks we have to wait till the result stabilizes. In this case: 5 1 2 3 4 6 7 8 9 In general, we get: Lemma 1.1 Insertion sort requires 2n − 1 time units to sort n numbers. -

Foundations of Differentially Oblivious Algorithms
Foundations of Differentially Oblivious Algorithms T-H. Hubert Chan Kai-Min Chung Bruce Maggs Elaine Shi August 5, 2020 Abstract It is well-known that a program's memory access pattern can leak information about its input. To thwart such leakage, most existing works adopt the technique of oblivious RAM (ORAM) simulation. Such an obliviousness notion has stimulated much debate. Although ORAM techniques have significantly improved over the past few years, the concrete overheads are arguably still undesirable for real-world systems | part of this overhead is in fact inherent due to a well-known logarithmic ORAM lower bound by Goldreich and Ostrovsky. To make matters worse, when the program's runtime or output length depend on secret inputs, it may be necessary to perform worst-case padding to achieve full obliviousness and thus incur possibly super-linear overheads. Inspired by the elegant notion of differential privacy, we initiate the study of a new notion of access pattern privacy, which we call \(, δ)-differential obliviousness". We separate the notion of (, δ)-differential obliviousness from classical obliviousness by considering several fundamental algorithmic abstractions including sorting small-length keys, merging two sorted lists, and range query data structures (akin to binary search trees). We show that by adopting differential obliv- iousness with reasonable choices of and δ, not only can one circumvent several impossibilities pertaining to full obliviousness, one can also, in several cases, obtain meaningful privacy with little overhead relative to the non-private baselines (i.e., having privacy \almost for free"). On the other hand, we show that for very demanding choices of and δ, the same lower bounds for oblivious algorithms would be preserved for (, δ)-differential obliviousness. -

Lecture 8.Key
CSC 391/691: GPU Programming Fall 2015 Parallel Sorting Algorithms Copyright © 2015 Samuel S. Cho Sorting Algorithms Review 2 • Bubble Sort: O(n ) 2 • Insertion Sort: O(n ) • Quick Sort: O(n log n) • Heap Sort: O(n log n) • Merge Sort: O(n log n) • The best we can expect from a sequential sorting algorithm using p processors (if distributed evenly among the n elements to be sorted) is O(n log n) / p ~ O(log n). Compare and Exchange Sorting Algorithms • Form the basis of several, if not most, classical sequential sorting algorithms. • Two numbers, say A and B, are compared between P0 and P1. P0 P1 A B MIN MAX Bubble Sort • Generic example of a “bad” sorting 0 1 2 3 4 5 algorithm. start: 1 3 8 0 6 5 0 1 2 3 4 5 Algorithm: • after pass 1: 1 3 0 6 5 8 • Compare neighboring elements. • Swap if neighbor is out of order. 0 1 2 3 4 5 • Two nested loops. after pass 2: 1 0 3 5 6 8 • Stop when a whole pass 0 1 2 3 4 5 completes without any swaps. after pass 3: 0 1 3 5 6 8 0 1 2 3 4 5 • Performance: 2 after pass 4: 0 1 3 5 6 8 Worst: O(n ) • 2 • Average: O(n ) fin. • Best: O(n) "The bubble sort seems to have nothing to recommend it, except a catchy name and the fact that it leads to some interesting theoretical problems." - Donald Knuth, The Art of Computer Programming Odd-Even Transposition Sort (also Brick Sort) • Simple sorting algorithm that was introduced in 1972 by Nico Habermann who originally developed it for parallel architectures (“Parallel Neighbor-Sort”). -

Download The
Visit : https://hemanthrajhemu.github.io Join Telegram to get Instant Updates: https://bit.ly/VTU_TELEGRAM Contact: MAIL: [email protected] INSTAGRAM: www.instagram.com/hemanthraj_hemu/ INSTAGRAM: www.instagram.com/futurevisionbie/ WHATSAPP SHARE: https://bit.ly/FVBIESHARE File Structures An Object-Oriented Approach with C++ Michael J. Folk University of Illinois Bill Zoellick CAP Ventures Greg Riccardi Florida State University yyA ADDISON-WESLEY Addison-Wesley is an imprint of Addison Wesley Longman,Inc.. Reading, Massachusetts * Harlow, England Menlo Park, California Berkeley, California * Don Mills, Ontario + Sydney Bonn + Amsterdam « Tokyo * Mexico City https://hemanthrajhemu.github.io Contents VIE Chapter 7 Indexing 247 7.1 What is anIndex? 248 7.2 A Simple Index for Entry-SequencedFiles 249 7.3 Using Template Classes in C++ for Object !/O 253 7.4 Object-Oriented Support for Indexed, Entry-SequencedFiles of Data Objects 255 . 7.4.1 Operations Required to Maintain an Indexed File 256 7.4.2 Class TextIndexedFile 260 7.4.3 Enhancementsto Class TextIndexedFile 261 7.5 Indexes That Are Too Large to Holdin Memory 264 7.6 Indexing to Provide Access by Multiple Keys 265 7.7 Retrieval Using Combinations of Secondary Keys 270 7.8. Improving the SecondaryIndex Structure: Inverted Lists 272 7.8.1 A First Attempt at a Solution” 272 7.8.2 A Better Solution: Linking the List of References 274 “7.9 Selective Indexes 278 7.10 Binding 279 . Summary 280 KeyTerms 282 FurtherReadings 283 Exercises 284 Programming and Design Exercises 285 Programming -

Tutorial 2: Heapsort, Quicksort, Counting Sort, Radix Sort
Tutorial 2: Heapsort, Quicksort, Counting Sort, Radix Sort Mayank Saksena September 20, 2006 1 Heapsort We review Heapsort, and prove some loop invariants for it. For further information, see Chapter 6 of Introduction to Algorithms. HEAPSORT(A) 1 BUILD-MAX-HEAP(A) Ð eÒg Øh A 2 for i = ( ) downto 2 A i 3 swap A[1] and [ ] ×iÞ e A heaÔ ×iÞ e A 4 heaÔ- ( )= - ( ) 1 5 MAX-HEAPIFY(A; 1) BUILD-MAX-HEAP(A) ×iÞ e A Ð eÒg Øh A 1 heaÔ- ( )= ( ) Ð eÒg Øh A = 2 for i = ( ) 2 downto 1 3 MAX-HEAPIFY(A; i) MAX-HEAPIFY(A; i) i 1 Ð =LEFT( ) i 2 Ö =RIGHT( ) heaÔ ×iÞ e A A Ð > A i Ð aÖ g e×Ø Ð 3 if Ð - ( ) and ( ) ( ) then = i 4 else Ð aÖ g e×Ø = heaÔ ×iÞ e A A Ö > A Ð aÖ g e×Ø Ð aÖ g e×Ø Ö 5 if Ö - ( ) and ( ) ( ) then = i 6 if Ð aÖ g e×Ø = i A Ð aÖ g e×Ø 7 swap A[ ] and [ ] 8 MAX-HEAPIFY(A; Ð aÖ g e×Ø) 1 Loop invariants First, assume that MAX-HEAPIFY(A; i) is correct, i.e., that it makes the subtree with A root i a max-heap. Under this assumption, we prove that BUILD-MAX-HEAP( ) is correct, i.e., that it makes A a max-heap. A We show: at the start of iteration i of the for-loop of BUILD-MAX-HEAP( ) (line ; i ;:::;Ò 2), each of the nodes i +1 +2 is the root of a max-heap.