A Database Integrating Genomic Indel Polymorphisms That Distinguish Mouse Strains Keiko Akagi1,2, Robert M
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Functional Annotation of Exon Skipping Event in Human Pora Kim1,*,†, Mengyuan Yang1,†,Keyiya2, Weiling Zhao1 and Xiaobo Zhou1,3,4,*
D896–D907 Nucleic Acids Research, 2020, Vol. 48, Database issue Published online 23 October 2019 doi: 10.1093/nar/gkz917 ExonSkipDB: functional annotation of exon skipping event in human Pora Kim1,*,†, Mengyuan Yang1,†,KeYiya2, Weiling Zhao1 and Xiaobo Zhou1,3,4,* 1School of Biomedical Informatics, The University of Texas Health Science Center at Houston, Houston, TX 77030, USA, 2College of Electronics and Information Engineering, Tongji University, Shanghai, China, 3McGovern Medical School, The University of Texas Health Science Center at Houston, Houston, TX 77030, USA and 4School of Dentistry, The University of Texas Health Science Center at Houston, Houston, TX 77030, USA Received August 13, 2019; Revised September 21, 2019; Editorial Decision October 03, 2019; Accepted October 03, 2019 ABSTRACT been used as therapeutic targets (3–8). For example, MET has lost the binding site of E3 ubiquitin ligase CBL through Exon skipping (ES) is reported to be the most com- exon 14 skipping event (9), resulting in an enhanced expres- mon alternative splicing event due to loss of func- sion level of MET. MET amplification drives the prolifera- tional domains/sites or shifting of the open read- tion of tumor cells. Multiple tyrosine kinase inhibitors, such ing frame (ORF), leading to a variety of human dis- as crizotinib, cabozantinib and capmatinib, have been used eases and considered therapeutic targets. To date, to treat patients with MET exon 14 skipping (10). Another systematic and intensive annotations of ES events example is the dystrophin gene (DMD) in Duchenne mus- based on the skipped exon units in cancer and cular dystrophy (DMD), a progressive neuromuscular dis- normal tissues are not available. -

Pathway in Protective Immunity Jeremy Manry, Guillaume Laval, Etienne Patin, Simona Fornarino, Christiane Bouchier, Magali Tichit, Luis Barreiro, Lluis Quintana-Murci
Evolutionary genetics evidence of an essential, non-redundant role of the IFN-γ pathway in protective immunity Jeremy Manry, Guillaume Laval, Etienne Patin, Simona Fornarino, Christiane Bouchier, Magali Tichit, Luis Barreiro, Lluis Quintana-Murci To cite this version: Jeremy Manry, Guillaume Laval, Etienne Patin, Simona Fornarino, Christiane Bouchier, et al.. Evo- lutionary genetics evidence of an essential, non-redundant role of the IFN-γ pathway in protective immunity. Human Mutation, Wiley, 2011, 32 (6), pp.633-42. 10.1002/humu.21484. hal-00627541 HAL Id: hal-00627541 https://hal.archives-ouvertes.fr/hal-00627541 Submitted on 29 Sep 2011 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Human Mutation Evolutionary genetics evidence of an essential, non- redundant role of the IFN-γ pathway in protective immunity For Peer Review Journal: Human Mutation Manuscript ID: humu-2010-0462.R1 Wiley - Manuscript type: Research Article Date Submitted by the 23-Jan-2011 Author: Complete List of Authors: Manry, Jeremy; Institut Pasteur Laval, Guillaume; Institut Pasteur Patin, Etienne; Institut Pasteur Fornarino, Simona; Institut Pasteur Bouchier, Christiane; Institut Pasteur Tichit, Magali; Institut Pasteur Barreiro, Luis; University of Chicago Quintana-Murci, Lluis; Institut Pasteur, EEMI IFNG, IFNGR1, IFNGR2, natural selection, polymorphism, Key Words: population genetics John Wiley & Sons, Inc. -
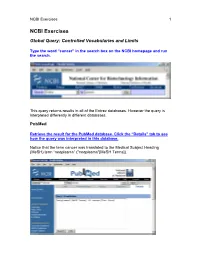
NCBI Exercises 1
NCBI Exercises 1 NCBI Exercises Global Query: Controlled Vocabularies and Limits Type the word “cancer” in the search box on the NCBI homepage and run the search. This query returns results in all of the Entrez databases. However the query is interpreted differently in different databases. PubMed Retrieve the result for the PubMed database. Click the “Details” tab to see how the query was interpreted in this database. Notice that the term cancer was translated to the Medical Subject Heading (MeSH) term “neoplasms” ("neoplasms"[MeSH Terms]). NCBI Exercises 2 MeSH is a controlled vocabulary that is used to index all articles in PubMed. In the details box, edit the query to remove the portion that searched for cancer as a text word and run the search. Notice that the number of articles retrieved has changed. These will be a more relevant set of results. You can force the PubMed engine to only search the MeSH vocabulary or specify any other indexed field through the “Limits” tab. Use the Web browser’s back button to return to the Global query page and retrieve the PubMed results again. Now click on the “Limits” tab. Select “MeSH terms” from the first drop-down menu, the one headed by “All Fields”. Now run the search with the limit in place and check the “Details” tab to verify that only the MeSH term translation was used. Nucleotide Use the Web browser’s back button to return to the Global query page. Retrieve the results for the nucleotide database. Click the “Details” tab to see how the query was interpreted for this molecular database. -

New Insights in Lumbosacral Plexopathy
New Insights in Lumbosacral Plexopathy Kerry H. Levin, MD Gérard Said, MD, FRCP P. James B. Dyck, MD Suraj A. Muley, MD Kurt A. Jaeckle, MD 2006 COURSE C AANEM 53rd Annual Meeting Washington, DC Copyright © October 2006 American Association of Neuromuscular & Electrodiagnostic Medicine 2621 Superior Drive NW Rochester, MN 55901 PRINTED BY JOHNSON PRINTING COMPANY, INC. C-ii New Insights in Lumbosacral Plexopathy Faculty Kerry H. Levin, MD P. James. B. Dyck, MD Vice-Chairman Associate Professor Department of Neurology Department of Neurology Head Mayo Clinic Section of Neuromuscular Disease/Electromyography Rochester, Minnesota Cleveland Clinic Dr. Dyck received his medical degree from the University of Minnesota Cleveland, Ohio School of Medicine, performed an internship at Virginia Mason Hospital Dr. Levin received his bachelor of arts degree and his medical degree from in Seattle, Washington, and a residency at Barnes Hospital and Washington Johns Hopkins University in Baltimore, Maryland. He then performed University in Saint Louis, Missouri. He then performed fellowships at a residency in internal medicine at the University of Chicago Hospitals, the Mayo Clinic in peripheral nerve and electromyography. He is cur- where he later became the chief resident in neurology. He is currently Vice- rently Associate Professor of Neurology at the Mayo Clinic. Dr. Dyck is chairman of the Department of Neurology and Head of the Section of a member of several professional societies, including the AANEM, the Neuromuscular Disease/Electromyography at Cleveland Clinic. Dr. Levin American Academy of Neurology, the Peripheral Nerve Society, and the is also a professor of medicine at the Cleveland Clinic College of Medicine American Neurological Association. -

(12) Patent Application Publication (10) Pub. No.: US 2008/0085284 A1 Patell Et Al
US 20080O85284A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2008/0085284 A1 Patell et al. (43) Pub. Date: Apr. 10, 2008 (54) CONSTRUCTION OF A COMPARATIVE (52) U.S. Cl. ............................. 424/184.1; 435/6: 514/44; DATABASE AND IDENTIFICATION OF 536/23.7:536/24.33: 707/102 VIRULENCE FACTORS COMPARISON OF POLYMORPHC REGIONS IN CLINICAL (57) ABSTRACT SOLATES OF INFECTIOUS ORGANISMS The present invention is directed to novel nucleotide (76) Inventors: Villoo Morawala Patell, Bangalore sequences to be used for diagnosis, identification of the (IN); K.R. Rajyashri, Bangalore (IN); strain, typing of the strain and giving orientation to its Marc Rodrigue, Marcy (FR); Guy potential degree of virulence, infectivity and/or latency for Vernet, Marcy (FR) all infectious diseases more particularly tuberculosis. The present invention also includes method for the identification Correspondence Address: and selection of polymorphisms associated with the viru SALWANCHIK LLOYD & SALWANCHK lence and/or infectivity in infectious diseases more particu A PROFESSIONAL ASSOCATION larly in tuberculosis by a comparative genomic analysis of PO BOX 142950 the sequences of different clinical isolates/strains of infec GAINESVILLE, FL 32614-2950 (US) tious organisms. The regions of polymorphisms, can also act (21) Appl. No.: 11/632,108 as potential drug targets and vaccine targets. More particu larly, the invention also relates to identifying virulence (22) Filed: Apr. 9, 2007 factors of M. tuberculosis strains and other infectious organ isms to be included in a diagnostic DNA chip allowing Publication Classification identification of the strain, typing of the strain and finally (51) Int. Cl. -

A Universal Method for Automated Gene Mapping Comment Peder Zipperlen¤*, Knud Nairz¤†, Ivo Rimann†, Konrad Basler*, Ernst Hafen†, Michael Hengartner* and Alex Hajnal†
Open Access Method2005ZipperlenetVolume al. 6, Issue 2, Article R19 A universal method for automated gene mapping comment Peder Zipperlen¤*, Knud Nairz¤†, Ivo Rimann†, Konrad Basler*, Ernst Hafen†, Michael Hengartner* and Alex Hajnal† Addresses: *Institute of Molecular Biology, University of Zürich, Winterthurerstrasse 190, CH-8057 Zürich, Switzerland. †Institute of Zoology, University of Zürich, Winterthurerstrasse 190, CH-8057 Zürich, Switzerland. ¤ These authors contributed equally to this work. reviews Correspondence: Peder Zipperlen. E-mail: [email protected]. Knud Nairz. E-mail: [email protected] Published: 17 January 2005 Received: 9 September 2004 Revised: 15 November 2004 Genome Biology 2005, 6:R19 Accepted: 9 December 2004 The electronic version of this article is the complete one and can be found online at http://genomebiology.com/2005/6/2/R19 reports © 2005 Zipperlen et al.; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Mapping<p>Amaps forhigh-throughput DrosophilaInDel sequence and method C.polymorphisms. elegans.</p> for genotyping by mapping InDels. This method has been used to create fragment-length polymorphism deposited research Abstract Small insertions or deletions (InDels) constitute a ubiquituous class of sequence polymorphisms found in eukaryotic genomes. Here, we present an automated high-throughput genotyping method that relies on the detection of fragment-length polymorphisms (FLPs) caused by InDels. The protocol utilizes standard sequencers and genotyping software. We have established genome-wide FLP maps for both Caenorhabditis elegans and Drosophila melanogaster that facilitate genetic mapping with a minimum of manual input and at comparatively low cost. -

Adriana Antônia Da Cruz Furini Malária Vivax No Estado
Faculdade de Medicina de São José do Rio Preto Programa de Pós-graduação em Ciências da Saúde Adriana Antônia da Cruz Furini Malária vivax no Estado do Pará: influência de polimorfismos nos genes TNFA, IFNG e IL10 associados à resposta imune humoral e ancestralidade genômica. São José do Rio Preto 2016 Adriana Antônia da Cruz Furini Malária vivax no Estado do Pará: influência de polimorfismos nos genes TNFA, IFNG e IL10 associados à resposta imune humoral e ancestralidade genômica. Tese apresentada à Faculdade de Medicina de São José do Rio Preto para obtenção do Título de Doutor no Programa de Pós Graduação em Ciências da Saúde, Eixo Temático: Medicina e Ciências Correlatas. Orientador: Prof. Dr. Ricardo Luiz Dantas Machado São José do Rio Preto 2016 Furini, Adriana Antônia da Cruz Malária vivax no Estado do Pará: influência de polimorfismos nos genes TNFA, IFNG e IL10 associados à resposta imune humoral e ancestralidade genômica./ Adriana Antônia da Cruz Furini São José do Rio Preto, 2016. 124p. Tese (Doutorado) – Faculdade de Medicina de São José do Rio Preto – FAMERP Eixo Temático: Medicina e Ciências Correlatas Orientador: Prof. Dr. Ricardo Luiz Dantas Machado 1.Ancestralidade; 2. Anticorpos; 3. Citocinas; 4. Malária; 5.Plasmodium vivax. ADRIANA ANTÔNIA DA CRUZ FURINI Malária vivax no Estado do Pará: influência de polimorfismos nos genes TNFA, IFNG e IL10 associados à resposta imune humoral e ancestralidade genômica. BANCA EXAMINADORA TESE PARA OBTENÇÃO DO GRAU DE DOUTOR Presidente/Orientador: Prof. Dr. Ricardo Luiz Dantas Machado 2º Examinador:Prof. Dr. Carlos Eugênio Cavasini 3º Examinador: Profa. Dra. Heloísa da Silveira Paro Pedro 4º Examinador: Profa. -

Downloaded from NLM and Some from the Pyysalo Et Al
Arguello Casteleiro et al. Journal of Biomedical Semantics (2018) 9:13 https://doi.org/10.1186/s13326-018-0181-1 RESEARCH Open Access Deep learning meets ontologies: experiments to anchor the cardiovascular disease ontology in the biomedical literature Mercedes Arguello Casteleiro1, George Demetriou1, Warren Read1, Maria Jesus Fernandez Prieto2, Nava Maroto3, Diego Maseda Fernandez4, Goran Nenadic1,5, Julie Klein6,7, John Keane1,5 and Robert Stevens1* Abstract Background: Automatic identification of term variants or acceptable alternative free-text terms for gene and protein names from the millions of biomedical publications is a challenging task. Ontologies, such as the Cardiovascular Disease Ontology (CVDO), capture domain knowledge in a computational form and can provide context for gene/protein names as written in the literature. This study investigates: 1) if word embeddings from Deep Learning algorithms can provide a list of term variants for a given gene/protein of interest; and 2) if biological knowledge from the CVDO can improve such a list without modifying the word embeddings created. Methods: We have manually annotated 105 gene/protein names from 25 PubMed titles/abstracts and mapped them to 79 unique UniProtKB entries corresponding to gene and protein classes from the CVDO. Using more than 14 M PubMed articles (titles and available abstracts), word embeddings were generated with CBOW and Skip-gram. We setup two experiments for a synonym detection task, each with four raters, and 3672 pairs of terms (target term and candidate term) from the word embeddings created. For Experiment I, the target terms for 64 UniProtKB entries were those that appear in the titles/abstracts; Experiment II involves 63 UniProtKB entries and the target terms are a combination of terms from PubMed titles/abstracts with terms (i.e. -

(12) United States Patent (10) Patent No.: US 6,686,163 B2 Allen Et Al
US006686163B2 (12) United States Patent (10) Patent No.: US 6,686,163 B2 Allen et al. (45) Date of Patent: Feb. 3, 2004 (54) CODING SEQUENCE HAPLOTYPE OF THE 5,912,127 A 6/1999 Narod et al. ................... 435/6 HUMAN BRCA1 GENE 5.948,643 A 9/1999 Rubinfeld et al. ......... 435/69.1 5,965,377 A 10/1999 Adams et al. ............. 435/7.23 (75) Inventors: Antonette C. P. Allen, Severn, MD 6,033,857 A 3/2000 Tavtigian et al. .............. 435/6 (US); Tracy S. Angelly, Gaithersburg, 6,045,997 A 4/2000 Futreal et al. - - - - - - - - - - 435/6 MD (US); Tammy Lawrence, Laurel, 6,051,379 A 4/2000 Lescallett et al. .............. 435/6 6,083,698 A 7/2000 Olson et al. ................... 435/6 MD (US); Sheri J.Olson, Falls 6,124,104 A 9/2000 Tavtigian et al. ............ 435/7.2 Church, VA (US); Mark B. Rabin, 6,130,322 A * 10/2000 Murphy et al. ................ 435/6 Rockville, MD (US) FOREIGN PATENT DOCUMENTS (73) Assignee: Gene Logic Inc., Gaithersburg, MD EP O705902 A1 4/1996 (US) EP O705903 A1 4/1996 EP O699.754 A1 6/1996 (*) Notice: Subject to any disclaimer, the term of this GB 2307477 A 5/1997 patent is extended or adjusted under 35 WO WO9304200 3/1993 U.S.C. 154(b) by 0 days. WO WO9519369 7/1995 WO WO9722689 6/1997 WO WO973O108 8/1997 (21) Appl. No.: 10/022,819 WO WO9815654 4/1998 (22) Filed: Dec. 20, 2001 OTHER PUBLICATIONS (65) Prior Publication Data Abeliovich et al. -

Transition Bias Influences the Evolution of Antibiotic Resistance in Mycobacterium
bioRxiv preprint doi: https://doi.org/10.1101/421651; this version posted September 20, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Transition bias influences the evolution of antibiotic resistance in Mycobacterium 2 tuberculosis 3 Joshua L. Payne1,2π*, Fabrizio Menardo3,4 π, Andrej Trauner3,4, Sonia Borrell3,4, Sebastian M. 4 Gygli3,4, Chloe Loiseau3,4, Sebastien Gagneux3,4†, Alex R. Hall1† 5 1. Institute of Integrative Biology, ETH Zurich, Switzerland 6 2. Swiss Institute of Bioinformatics, Lausanne, Switzerland 7 3. Swiss Tropical and Public Health Institute, Basel, Switzerland 8 4. University of Basel, Basel, Switzerland 9 *Correspondence: [email protected] 10 π, These authors contributed equally. 11 †These authors also contributed equally. 12 13 1 bioRxiv preprint doi: https://doi.org/10.1101/421651; this version posted September 20, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 14 Abstract 15 Transition bias, an overabundance of transitions relative to transversions, has been widely 16 reported among studies of mutations spreading under relaxed selection. However, demonstrating 17 the role of transition bias in adaptive evolution remains challenging. We addressed this challenge 18 by analyzing adaptive antibiotic-resistance mutations in the major human pathogen 19 Mycobacterium tuberculosis. -

The Peppered Moth: Decline of a Darwinian Disciple Michael E.N
The Peppered moth: decline of a Darwinian disciple Michael E.N. Majerus Reader in Evolution, Department of Genetics, University of Cambridge Delivered to the British Humanist Association, at the London School of Economics, on Darwin Day, 12th February 2004. {Text links to powerpoint presentation, with slides indicated by PP numbers} PP1 Introduction The rise of the melanic moth The rise of the black, carbonaria form of the peppered moth, Biston betularia, in response to changes in the environment caused by the industrial revolution in Britain, is probably the best known example of evolution in action. The reasons for the prominence of this example are three-fold. First, the rise was spectacular, occurred in the recent and well-documented past, and was timely, the first record of an individual of carbonaria being published by Edelston (1864), just five years after the Origin of Species (Darwin, 1859). Second, the difference in the forms had visual impact. Third, the major mechanism through which carbonaria rose is easy to both relate and understand. The story, in brief, is this. The non-melanic peppered moth is a white moth, liberally speckled with black scales (PP2). In 1848, a black form, f. carbonaria (PP3), was recorded in Manchester, and by 1895, 98% of the Mancunian population were black (PP4). The carbonaria form spread to many other parts of Britain, reaching high frequencies in industrial centres and regions downwind. In 1896, the Lepidopterist, J.W. Tutt, hypothesized that the increase in carbonaria, was the result of differential bird predation in polluted regions. Bernard Kettlewell obtained evidence in support of this hypothesis in the 1950s, with his predation experiments in polluted and unpolluted woodlands. -

Genetic Associations of 115 Polymorphisms with Cancers of the Upper Aerodigestive Tract Across 10 European Countries: the ARCAGE Project
Research Article Genetic Associations of 115 Polymorphisms with Cancers of the Upper Aerodigestive Tract across 10 European Countries: The ARCAGE Project Cristina Canova,1 Mia Hashibe,2 Lorenzo Simonato,1 Mari Nelis,3 Andres Metspalu,3,4 Pagona Lagiou,5,6 Dimitrios Trichopoulos,5,6 Wolfgang Ahrens,7 Iris Pigeot,7 Franco Merletti,8 Lorenzo Richiardi,8 Renato Talamini,9 Luigi Barzan,10 Gary J. Macfarlane,11 Tatiana V. Macfarlane,11 Ivana Holca´tova´,12 Vladimir Bencko,12 Simone Benhamou,13,14 Christine Bouchardy,15 Kristina Kjaerheim,16 Ray Lowry,17 Antonio Agudo,18 Xavier Castellsague´,18 David I. Conway,19,20 Patricia A. McKinney,20,21 Ariana Znaor,22 Bernard E. McCartan,23 Claire M. Healy,23 Manuela Marron,2 and Paul Brennan2 1Department of Environmental Medicine and Public Health, University of Padova, Padova, Italy; 2IARC, Lyon, France; 3University of Tartu, Institute of Molecular and Cell Biology/Estonian Biocentre; 4The Estonian Genome Project of the University of Tartu, Tartu, Estonia; 5University of Athens School of Medicine, Athens, Greece; 6Harvard School of Public Health, Boston, Massachusetts; 7Bremen Institute for Prevention Research and Social Medicine, University of Bremen, Bremen, Germany; 8Unit of Cancer Epidemiology, Center for Experimental Research and Medical Studies and University of Turin, Turin, Italy; 9Aviano Cancer Centre, Aviano, Italy; 10General Hospital of Pordenone, Pordenone, Italy; 11University of Aberdeen School of Medicine, Aberdeen, United Kingdom; 12Charles University in Prague, 1st Faculty of Medicine,