Same Role but Different Actors: Genetic Regulation of Post-Translational Modification of Two Distinct Proteins
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
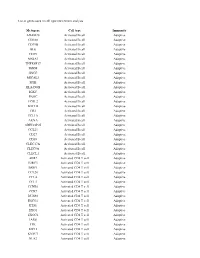
List of Genes Used in Cell Type Enrichment Analysis
List of genes used in cell type enrichment analysis Metagene Cell type Immunity ADAM28 Activated B cell Adaptive CD180 Activated B cell Adaptive CD79B Activated B cell Adaptive BLK Activated B cell Adaptive CD19 Activated B cell Adaptive MS4A1 Activated B cell Adaptive TNFRSF17 Activated B cell Adaptive IGHM Activated B cell Adaptive GNG7 Activated B cell Adaptive MICAL3 Activated B cell Adaptive SPIB Activated B cell Adaptive HLA-DOB Activated B cell Adaptive IGKC Activated B cell Adaptive PNOC Activated B cell Adaptive FCRL2 Activated B cell Adaptive BACH2 Activated B cell Adaptive CR2 Activated B cell Adaptive TCL1A Activated B cell Adaptive AKNA Activated B cell Adaptive ARHGAP25 Activated B cell Adaptive CCL21 Activated B cell Adaptive CD27 Activated B cell Adaptive CD38 Activated B cell Adaptive CLEC17A Activated B cell Adaptive CLEC9A Activated B cell Adaptive CLECL1 Activated B cell Adaptive AIM2 Activated CD4 T cell Adaptive BIRC3 Activated CD4 T cell Adaptive BRIP1 Activated CD4 T cell Adaptive CCL20 Activated CD4 T cell Adaptive CCL4 Activated CD4 T cell Adaptive CCL5 Activated CD4 T cell Adaptive CCNB1 Activated CD4 T cell Adaptive CCR7 Activated CD4 T cell Adaptive DUSP2 Activated CD4 T cell Adaptive ESCO2 Activated CD4 T cell Adaptive ETS1 Activated CD4 T cell Adaptive EXO1 Activated CD4 T cell Adaptive EXOC6 Activated CD4 T cell Adaptive IARS Activated CD4 T cell Adaptive ITK Activated CD4 T cell Adaptive KIF11 Activated CD4 T cell Adaptive KNTC1 Activated CD4 T cell Adaptive NUF2 Activated CD4 T cell Adaptive PRC1 Activated -

Markers of T Cell Senescence in Humans
International Journal of Molecular Sciences Review Markers of T Cell Senescence in Humans Weili Xu 1,2 and Anis Larbi 1,2,3,4,5,* 1 Biology of Aging Program and Immunomonitoring Platform, Singapore Immunology Network (SIgN), Agency for Science Technology and Research (A*STAR), Immunos Building, Biopolis, Singapore 138648, Singapore; [email protected] 2 School of Biological Sciences, Nanyang Technological University, Singapore 637551, Singapore 3 Department of Microbiology, National University of Singapore, Singapore 117597, Singapore 4 Department of Geriatrics, Faculty of Medicine, University of Sherbrooke, Sherbrooke, QC J1K 2R1, Canada 5 Faculty of Sciences, University ElManar, Tunis 1068, Tunisia * Correspondence: [email protected]; Tel.: +65-6407-0412 Received: 31 May 2017; Accepted: 26 July 2017; Published: 10 August 2017 Abstract: Many countries are facing the aging of their population, and many more will face a similar obstacle in the near future, which could be a burden to many healthcare systems. Increased susceptibility to infections, cardiovascular and neurodegenerative disease, cancer as well as reduced efficacy of vaccination are important matters for researchers in the field of aging. As older adults show higher prevalence for a variety of diseases, this also implies higher risk of complications, including nosocomial infections, slower recovery and sequels that may reduce the autonomy and overall quality of life of older adults. The age-related effects on the immune system termed as “immunosenescence” can be exemplified by the reported hypo-responsiveness to influenza vaccination of the elderly. T cells, which belong to the adaptive arm of the immune system, have been extensively studied and the knowledge gathered enables a better understanding of how the immune system may be affected after acute/chronic infections and how this matters in the long run. -

Human Β‑1,3‑Glucuronyltransferase 1/B3GAT1 Antibody Monoclonal Mouse Igg2a Clone # 1002707 Catalog Number: MAB8560
Human β‑1,3‑Glucuronyltransferase 1/B3GAT1 Antibody Monoclonal Mouse IgG2A Clone # 1002707 Catalog Number: MAB8560 DESCRIPTION Species Reactivity Human Specificity Detects human β-1,3-Glucuronyltransferase 1/B3GAT1 in direct ELISAs. Source Monoclonal Mouse IgG2A Clone # 1002707 Purification Protein A or G purified from hybridoma culture supernatant Immunogen Chinese Hamster Ovary cell line, CHO-derived human β‑1,3‑Glucuronyltransferase 1/B3GAT1 His25-Ile334 Accession # Q9P2W7 Formulation Lyophilized from a 0.2 μm filtered solution in PBS with Trehalose. See Certificate of Analysis for details. *Small pack size (-SP) is supplied either lyophilized or as a 0.2 μm filtered solution in PBS. APPLICATIONS Please Note: Optimal dilutions should be determined by each laboratory for each application. General Protocols are available in the Technical Information section on our website. Recommended Sample Concentration Immunohistochemistry 5-25 µg/mL See Below DATA Immunohistochemistry β-1,3-Glucuronyltransferase 1/B3GAT1 in Human Brain. β-1,3-Glucuronyltransferase 1/B3GAT1 was detected in immersion fixed paraffin-embedded sections of human brain (cortex) using Mouse Anti-Human β-1,3- Glucuronyltransferase 1/B3GAT1 Monoclonal Antibody (Catalog # MAB8560) at 5 µg/mL for 1 hour at room temperature followed by incubation with the Anti-Mouse IgG VisUCyte™ HRP Polymer Antibody (Catalog # VC001). Before incubation with the primary antibody, tissue was subjected to heat-induced epitope retrieval using Antigen Retrieval Reagent-Basic (Catalog # CTS013). Tissue was stained using DAB (brown) and counterstained with hematoxylin (blue). Specific staining was localized to cytoplasm in neurons. View our protocol for IHC Staining with VisUCyte HRP Polymer Detection Reagents. PREPARATION AND STORAGE Reconstitution Reconstitute at 0.5 mg/mL in sterile PBS. -

Differential Integrin Adhesome Expression Defines Human Natural
bioRxiv preprint doi: https://doi.org/10.1101/2020.12.01.404806; this version posted December 1, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. Differential integrin adhesome expression defines human natural killer cell residency and developmental stage Everardo Hegewisch Solloa1, Seungmae Seo1, Bethany L. Mundy-Bosse2, Anjali Mishra3,a, Erik Waldman4,b, Sarah Maurrasse4,b, Eli Grunstein4, Thomas J. Connors5, Aharon G. Freud2,6, and Emily M. Mace1 1Department of Pediatrics, Columbia University College of Physicians and Surgeons, New York NY 10032 2Division of Hematology, Department of Internal Medicine, The Ohio State University, Columbus, OH 43210, USA; Comprehensive Cancer Center and The James Cancer Hospital and Solove Research Institute, The Ohio State University, Columbus, OH 43210 33Division of Dermatology, Department of Internal Medicine, The Ohio State University, Columbus, OH 43210, USA; Comprehensive Cancer Center and The James Cancer Hospital and Solove Research Institute, The Ohio State University, Columbus, OH 43210 4Department of Otolaryngology - Head and Neck Surgery, Columbia University Medical Center, New York, New York 10032 5Department of Pediatrics, Division of Pediatric Critical Care and Hospital Medicine, Columbia University Irving Medical Center, New York, NY 10024 6Department of Pathology, The Ohio State University, Columbus, -

(P -Value<0.05, Fold Change≥1.4), 4 Vs. 0 Gy Irradiation
Table S1: Significant differentially expressed genes (P -Value<0.05, Fold Change≥1.4), 4 vs. 0 Gy irradiation Genbank Fold Change P -Value Gene Symbol Description Accession Q9F8M7_CARHY (Q9F8M7) DTDP-glucose 4,6-dehydratase (Fragment), partial (9%) 6.70 0.017399678 THC2699065 [THC2719287] 5.53 0.003379195 BC013657 BC013657 Homo sapiens cDNA clone IMAGE:4152983, partial cds. [BC013657] 5.10 0.024641735 THC2750781 Ciliary dynein heavy chain 5 (Axonemal beta dynein heavy chain 5) (HL1). 4.07 0.04353262 DNAH5 [Source:Uniprot/SWISSPROT;Acc:Q8TE73] [ENST00000382416] 3.81 0.002855909 NM_145263 SPATA18 Homo sapiens spermatogenesis associated 18 homolog (rat) (SPATA18), mRNA [NM_145263] AA418814 zw01a02.s1 Soares_NhHMPu_S1 Homo sapiens cDNA clone IMAGE:767978 3', 3.69 0.03203913 AA418814 AA418814 mRNA sequence [AA418814] AL356953 leucine-rich repeat-containing G protein-coupled receptor 6 {Homo sapiens} (exp=0; 3.63 0.0277936 THC2705989 wgp=1; cg=0), partial (4%) [THC2752981] AA484677 ne64a07.s1 NCI_CGAP_Alv1 Homo sapiens cDNA clone IMAGE:909012, mRNA 3.63 0.027098073 AA484677 AA484677 sequence [AA484677] oe06h09.s1 NCI_CGAP_Ov2 Homo sapiens cDNA clone IMAGE:1385153, mRNA sequence 3.48 0.04468495 AA837799 AA837799 [AA837799] Homo sapiens hypothetical protein LOC340109, mRNA (cDNA clone IMAGE:5578073), partial 3.27 0.031178378 BC039509 LOC643401 cds. [BC039509] Homo sapiens Fas (TNF receptor superfamily, member 6) (FAS), transcript variant 1, mRNA 3.24 0.022156298 NM_000043 FAS [NM_000043] 3.20 0.021043295 A_32_P125056 BF803942 CM2-CI0135-021100-477-g08 CI0135 Homo sapiens cDNA, mRNA sequence 3.04 0.043389246 BF803942 BF803942 [BF803942] 3.03 0.002430239 NM_015920 RPS27L Homo sapiens ribosomal protein S27-like (RPS27L), mRNA [NM_015920] Homo sapiens tumor necrosis factor receptor superfamily, member 10c, decoy without an 2.98 0.021202829 NM_003841 TNFRSF10C intracellular domain (TNFRSF10C), mRNA [NM_003841] 2.97 0.03243901 AB002384 C6orf32 Homo sapiens mRNA for KIAA0386 gene, partial cds. -

Identification of Key Pathways and Genes in Dementia Via Integrated Bioinformatics Analysis
bioRxiv preprint doi: https://doi.org/10.1101/2021.04.18.440371; this version posted July 19, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Identification of Key Pathways and Genes in Dementia via Integrated Bioinformatics Analysis Basavaraj Vastrad1, Chanabasayya Vastrad*2 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karnataka, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India bioRxiv preprint doi: https://doi.org/10.1101/2021.04.18.440371; this version posted July 19, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract To provide a better understanding of dementia at the molecular level, this study aimed to identify the genes and key pathways associated with dementia by using integrated bioinformatics analysis. Based on the expression profiling by high throughput sequencing dataset GSE153960 derived from the Gene Expression Omnibus (GEO), the differentially expressed genes (DEGs) between patients with dementia and healthy controls were identified. With DEGs, we performed a series of functional enrichment analyses. Then, a protein–protein interaction (PPI) network, modules, miRNA-hub gene regulatory network and TF-hub gene regulatory network was constructed, analyzed and visualized, with which the hub genes miRNAs and TFs nodes were screened out. Finally, validation of hub genes was performed by using receiver operating characteristic curve (ROC) analysis. -

MGAT5 Antibody (C-Term) Affinity Purified Rabbit Polyclonal Antibody (Pab) Catalog # Ap13815b
10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 MGAT5 Antibody (C-term) Affinity Purified Rabbit Polyclonal Antibody (Pab) Catalog # AP13815b Specification MGAT5 Antibody (C-term) - Product Information Application WB, FC,E Primary Accession Q09328 Other Accession NP_002401.1 Reactivity Human Host Rabbit Clonality Polyclonal Isotype Rabbit Ig Antigen Region 652-680 MGAT5 Antibody (C-term) - Additional Information Gene ID 4249 Other Names Alpha-1, 6-mannosylglycoprotein All lanes : Anti-MGAT5 Antibody (C-term) at 6-beta-N-acetylglucosaminyltransferase A, 1:1000 dilution Lane 1: HepG2 whole cell Alpha-mannoside beta-1, lysate Lane 2: Jurkat whole cell lysate 6-N-acetylglucosaminyltransferase, Lysates/proteins at 20 µg per lane. GlcNAc-T V, GNT-V, Mannoside Secondary Goat Anti-Rabbit IgG, (H+L), acetylglucosaminyltransferase 5, Peroxidase conjugated at 1/10000 dilution. N-acetylglucosaminyl-transferase V, MGAT5, GGNT5 Predicted band size : 85 kDa Blocking/Dilution buffer: 5% NFDM/TBST. Target/Specificity This MGAT5 antibody is generated from rabbits immunized with a KLH conjugated synthetic peptide between 652-680 amino acids from the C-terminal region of human MGAT5. Dilution WB~~1:1000 FC~~1:10~50 Format Purified polyclonal antibody supplied in PBS with 0.09% (W/V) sodium azide. This antibody is purified through a protein A column, followed by peptide affinity purification. MGAT5 Antibody (C-term) (Cat. #AP13815b) Storage flow cytometric analysis of NCI-H460 cells Maintain refrigerated at 2-8°C for up to 2 (right histogram) compared to a negative weeks. For long term storage store at -20°C control cell (left histogram).FITC-conjugated Page 1/3 10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 in small aliquots to prevent freeze-thaw donkey-anti-rabbit secondary antibodies were cycles. -

B3GAT1 Antibody Cat
B3GAT1 Antibody Cat. No.: 64-189 B3GAT1 Antibody Flow cytometric analysis of K562 cells (right histogram) compared to a negative control cell (left histogram).FITC-conjugated goat-anti- rabbit secondary antibodies were used for the analysis. Specifications HOST SPECIES: Rabbit SPECIES REACTIVITY: Human This B3GAT1 antibody is generated from rabbits immunized with a KLH conjugated IMMUNOGEN: synthetic peptide between 21-48 amino acids from the N-terminal region of human B3GAT1. TESTED APPLICATIONS: Flow, WB For WB starting dilution is: 1:1000 APPLICATIONS: For FACS starting dilution is: 1:10~50 PREDICTED MOLECULAR 38 kDa WEIGHT: September 26, 2021 1 https://www.prosci-inc.com/b3gat1-antibody-64-189.html Properties This antibody is purified through a protein A column, followed by peptide affinity PURIFICATION: purification. CLONALITY: Polyclonal ISOTYPE: Rabbit Ig CONJUGATE: Unconjugated PHYSICAL STATE: Liquid BUFFER: Supplied in PBS with 0.09% (W/V) sodium azide. CONCENTRATION: batch dependent Store at 4˚C for three months and -20˚C, stable for up to one year. As with all antibodies STORAGE CONDITIONS: care should be taken to avoid repeated freeze thaw cycles. Antibodies should not be exposed to prolonged high temperatures. Additional Info OFFICIAL SYMBOL: B3GAT1 Galactosylgalactosylxylosylprotein 3-beta-glucuronosyltransferase 1, Beta-1,3- ALTERNATE NAMES: glucuronyltransferase 1, Glucuronosyltransferase P, GlcAT-P, UDP-GlcUA:glycoprotein beta-1,3-glucuronyltransferase, GlcUAT-P, B3GAT1, GLCATP ACCESSION NO.: Q9P2W7 PROTEIN GI NO.: 205830910 GENE ID: 27087 USER NOTE: Optimal dilutions for each application to be determined by the researcher. Background and References The protein encoded by this gene is a member of the glucuronyltransferase gene family. -

Mouse Mgat5 Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Mgat5 Knockout Project (CRISPR/Cas9) Objective: To create a Mgat5 knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Mgat5 gene (NCBI Reference Sequence: NM_145128 ; Ensembl: ENSMUSG00000036155 ) is located on Mouse chromosome 1. 18 exons are identified, with the ATG start codon in exon 3 and the TAG stop codon in exon 18 (Transcript: ENSMUST00000038361). Exon 3 will be selected as target site. Cas9 and gRNA will be co-injected into fertilized eggs for KO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Mice homozygous for deficiencies in this gene have immune system abnormalities and reduced cancer growth and metastasis. Exon 3 starts from the coding region. Exon 3 covers 10.86% of the coding region. The size of effective KO region: ~383 bp. The KO region does not have any other known gene. Page 1 of 9 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele gRNA region 5' gRNA region 3' 1 3 18 Legends Exon of mouse Mgat5 Knockout region Page 2 of 9 https://www.alphaknockout.com Overview of the Dot Plot (up) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section upstream of Exon 3 is aligned with itself to determine if there are tandem repeats. Tandem repeats are found in the dot plot matrix. The gRNA site is selected outside of these tandem repeats. Overview of the Dot Plot (down) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section downstream of Exon 3 is aligned with itself to determine if there are tandem repeats. -

Efficient Generation of Human Natural Killer Cell Lines by Viral Transformation
Letters to the Editor 192 2 Department of Immunology, Erasmus MC, Erasmus University selected children with hypoplastic refractory cytopenia. Haematologica 2007; 92: Medical Center, Rotterdam, The Netherlands; 397–400. 3Department of Pediatrics and Adolescent Medicine, Division of 4 Dunn DE, Tanawattanacharoen P, Boccuni P, Nagakura S, Green SW, Kirby MR Pediatric Hematology and Oncology, University of Freiburg, et al. Paroxysmal nocturnal hemoglobinuria cells in patients with bone marrow Freiburg, Germany; failure syndromes. Ann Intern Med 1999; 131: 401–408. 4Department of Pathology, Clinical Centre South West, Bo¨blingen 5 Maciejewski JP, Follmann D, Nakamura R, Saunthararajah Y, Rivera CE, Simonis T et al. Increased frequency of HLA-DR2 in patients with paroxysmal nocturnal Clinics, Bo¨blingen, Germany; 5 hemoglobinuria and the PNH/aplastic anemia syndrome. Blood 2001; 98: Department of Clinical Genetics, Erasmus MC, Erasmus University 3513–3519. Medical Center, Rotterdam, The Netherlands; 6 Wang H, Chuhjo T, Yasue S, Omine M, Nakao S. Clinical significance of a minor 6 St. Anna Children’s Hospital and Children’s Cancer Research Institute, population of paroxysmal nocturnal hemoglobinuria-type cells in bone marrow Department of Pediatrics, Medical University of Vienna, failure syndrome. Blood 2002; 100: 3897–3902. Vienna, Austria; 7 Yoshida N, Yagasaki H, Takahashi Y, Yamamoto T, Liang J, Wang Y et al. 7Department of Pediatrics, Aarhus University Hospital Skejby, Clinical impact of HLA-DR15, a minor population of paroxysmal Aarhus, Denmark; nocturnal haemoglobinuria-type cells, and an aplastic anaemia-associated auto- 8Department of Pediatric Hematology-Oncology, IRCCS Ospedale antibody in children with acquired aplastic anaemia. Br J Haematol 2008; 142: 427–435. -

Table S1. Detailed Gene Lists Related with Glaucoma, Sclera and Extracellular Matrix (ECM) Remodeling from Text Mining
Table S1. Detailed gene lists related with Glaucoma, Sclera and Extracellular matrix (ECM) remodeling from text mining. Glaucoma related genes Sclera related genes ECM remodeling related genes Common genes GSTM1 NID1 AKT3 NID1 TAP2 EPRS NID1 TGFB2 LGALS8 TGFB2 ACTA1 HSD11B1 NID1 PROX1 PARP1 CD34 TBCE IRF6 MIXL1 REN MIXL1 HSD11B1 TGFB2 DES LBR PLXNA2 PROX1 MPZ EPRS CD34 HSD11B1 ABCB6 TGFB2 CD46 CD34 FN1 IRF6 CR2 IL10 RPE HSD11B1 CD55 REN SST PLXNA2 REN FMOD KNG1 CD34 FMOD CHI3L1 VCAM1 CD46 PRELP CHIT1 F3 IL10 ADORA1 AGXT SOD2 NFASC CFH GPC1 RHO REN PRG4 PTPRC SHH OPTC MYOC COL6A3 NOS3 CHI3L1 SELE PTGS2 GJA1 RNPEP SLC4A3 LAMC2 TIMP2 LMOD1 DES SOAT1 MKI67 PER2 MPZ FASLG APOA1 PTPRC ABCB6 SERPINE2 CALD1 PRLH USF1 SELP C2 CRB1 CD244 POU2F1 VAMP8 CFH VANGL2 DES MMP3 PTGS2 FN1 DDR2 MMP1 PDC NES MPZ GH1 C1orf27 RPE ABCB6 SLC17A5 DHX9 TFPI ADAMTS4 NOVA2 LAMC1 NBPF14 IHH DMPK SOAT1 SST CYP27A1 NOS1 PSMD1 OLFML3 NHLH1 ACE PRDX6 KNG1 CRP PVR TNFSF4 CRYGS IGFBP5 SERPINE1 FASLG ADORA3 NTRK1 ACHE MYOC GCG FN1 ENG COL4A3 VCAM1 NES BGN SELE F3 RPE CD79A SELL MBNL1 CREB1 GALNS F5 PLG MUC1 TGFB1 SELP SOD2 NRP2 VEGFA ATP1B1 RHO SHC1 HSPA5 DPT VIPR2 BMPR2 COL1A1 SLC4A3 B3GAT1 SUMO1 IGF1 DES NLRP5 CASP8 GSN PBX1 SHH S100A1 COL1A2 MPZ LIMS1 S100A4 DCN ABCB6 NOS3 FLG LUM USF1 HGS CTSK TNC CD244 HGD CTSS GFAP VANGL2 GJA1 ECM1 CDH1 PEX19 TIMP2 TFPI CDKN1A ATP1A2 MKI67 CALCRL PLAU PNKD KLK1 ITGAV MFAP2 CRP APOA1 MFI2 CTNNB1 DARC TFG TTN C10orf27 IGFBP2 CALD1 ATF2 ELN NTRK1 C2 NGF PTCH1 FN1 PAEP TP63 MMP2 LMNA TSPAN33 SST CNOT8 RPE CNTN3 ITGA6 EDN1 MAP2 DBH ADIPOQ -

Genetic and Functional Approaches to Understanding Autoimmune and Inflammatory Pathologies
University of Vermont ScholarWorks @ UVM Graduate College Dissertations and Theses Dissertations and Theses 2020 Genetic And Functional Approaches To Understanding Autoimmune And Inflammatory Pathologies Abbas Raza University of Vermont Follow this and additional works at: https://scholarworks.uvm.edu/graddis Part of the Genetics and Genomics Commons, Immunology and Infectious Disease Commons, and the Pathology Commons Recommended Citation Raza, Abbas, "Genetic And Functional Approaches To Understanding Autoimmune And Inflammatory Pathologies" (2020). Graduate College Dissertations and Theses. 1175. https://scholarworks.uvm.edu/graddis/1175 This Dissertation is brought to you for free and open access by the Dissertations and Theses at ScholarWorks @ UVM. It has been accepted for inclusion in Graduate College Dissertations and Theses by an authorized administrator of ScholarWorks @ UVM. For more information, please contact [email protected]. GENETIC AND FUNCTIONAL APPROACHES TO UNDERSTANDING AUTOIMMUNE AND INFLAMMATORY PATHOLOGIES A Dissertation Presented by Abbas Raza to The Faculty of the Graduate College of The University of Vermont In Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy Specializing in Cellular, Molecular, and Biomedical Sciences January, 2020 Defense Date: August 30, 2019 Dissertation Examination Committee: Cory Teuscher, Ph.D., Advisor Jonathan Boyson, Ph.D., Chairperson Matthew Poynter, Ph.D. Ralph Budd, M.D. Dawei Li, Ph.D. Dimitry Krementsov, Ph.D. Cynthia J. Forehand, Ph.D., Dean of the Graduate College ABSTRACT Our understanding of genetic predisposition to inflammatory and autoimmune diseases has been enhanced by large scale quantitative trait loci (QTL) linkage mapping and genome-wide association studies (GWAS). However, the resolution and interpretation of QTL linkage mapping or GWAS findings are limited.