Managing Correctable Memory Errors on Cisco UCS Servers
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Radiation-Induced Soft Errors in Advanced Semiconductor Technologies Robert C
IEEE TRANSACTIONS ON DEVICE AND MATERIALS RELIABILITY, VOL. 5, NO. 3, SEPTEMBER 2005 305 Radiation-Induced Soft Errors in Advanced Semiconductor Technologies Robert C. Baumann, Fellow, IEEE Invited Paper Abstract—The once-ephemeral radiation-induced soft error has bit upset (SBU). While MBUs are usually a small fraction of become a key threat to advanced commercial electronic compo- the total observed SEU rate, their occurrence has implications nents and systems. Left unchallenged, soft errors have the poten- for memory architecture in systems utilizing error correction tial for inducing the highest failure rate of all other reliability mechanisms combined. This article briefly reviews the types of [3], [4]. Another type of soft error occurs when the bit that failure modes for soft errors, the three dominant radiation mech- is flipped is in a critical system control register such as that anisms responsible for creating soft errors in terrestrial applica- found in field-programmable gate arrays (FPGAs) or dynamic tions, and how these soft errors are generated by the collection of random access memory (DRAM) control circuitry, so that the radiation-induced charge. The soft error sensitivity as a function error causes the product to malfunction [5]. This type of soft of technology scaling for various memory and logic components is then presented with a consideration of which applications are most error, called a single event interrupt (SEFI), obviously impacts likely to require soft error mitigation. the product reliability since each SEFI leads to a direct product malfunction as opposed to typical memory soft errors that may Index Terms—Radiation effects, reliability, single-event effects, soft errors. -

HP Z620 Memory Configurations and Optimization
HP recommends Windows® 7. HP Z620 Memory Configurations and Optimization The purpose of this document is to provide an overview of the memory configuration for the HP Z620 Workstation and to provide recommendations to optimize performance. Supported Memory Modules1 Memory Features The types of memory supported on a HP Z620 are: ECC is supported on all of our supported DIMMs. • 2 GB and 4 GB PC3-12800E 1600MHz DDR3 • Single-bit errors are automatically corrected. Unbuffered ECC DIMMs • Multi-bit errors are detected and will cause the • 4 GB and 8 GB PC3-12800R 1600MHz DDR3 system to immediately reboot and halt with an Registered DIMMs F1 prompt error message. • 1.35V and 1.5V DIMMs are supported, but the Non-ECC memory does not detect or correct system will operate the DIMMs at 1.5V only. single-bit or multi-bit errors which can cause • 2 Gb and 4 Gb based DIMMs are supported. instability, or corruption of data, in the platform. See the Memory Technology White Paper for See the Memory Technology White Paper for additional technical information. additional technical information. Command and Address parity is supported with Platform Capabilities Registered DIMMs. Maximum capacity Optimize Performance • Single processor: 64 GB Generally, maximum memory performance is • Dual processors: 96 GB achieved by evenly distributing total desired memory capacity across all operational Total of 12 memory sockets channels. Proper individual DIMM capacity • 8 sockets on the motherboard: 4 channels per selection is essential to maximizing performance. processor and 2 sockets per channel On the second CPU, installing the same • 4 sockets on the 2nd CPU and memory amount of memory as the first CPU will optimize module: 4 channels per processor and 1 performance. -

MARS-C: Modeling and Reduction of Soft Errors in Combinational Circuits
MARS-C: Modeling and Reduction of Soft Errors in Combinational Circuits Natasa Miskov-Zivanov, Diana Marculescu Department of Electrical and Computer Engineering Carnegie Mellon University {nmiskov,dianam}@ece.cmu.edu ABSTRACT completely masked before it reaches the latch; Due to the shrinking of feature size and reduction in supply voltages, • latching-window masking – only if the glitch reaches the latch nanoscale circuits have become more susceptible to radiation induced and satisfies setup and hold time conditions, it will be latched. transient faults. In this paper, we present a symbolic framework based In this work, we estimate the likelihood that a transient fault will on BDDs and ADDs that enables analysis of combinational circuit lead to a soft error. Our main goal is to allow for symbolic modeling reliability from different aspects: output susceptibility to error, and efficient estimation of the susceptibility of a combinational logic influence of individual gates on individual outputs and overall circuit circuit to soft errors. We further use this framework to reduce the cost reliability, and the dependence of circuit reliability on glitch duration, of radiation hardening techniques by selectively resizing the gates that amplitude, and input patterns. This is demonstrated by the set of have the largest impact on circuit error. experimental results, which show that the mean output error The rest of this paper is organized as follows. In Section 2 we susceptibility can vary from less than 0.1%, for large circuits and outline the contribution of our work. In Section 3 we give an overview small glitches, to about 30% for very small circuits and large enough of related work. -
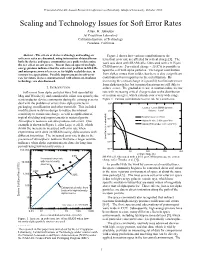
Scaling and Technology Issues for Soft Error Rates Allan
Presented at the 4th Annual Research Conference on Reliability, Stanford University, October 2000 Scaling and Technology Issues for Soft Error Rates Allan. H. Johnston Jet Propulsion Laboratory California Institute of Technology Pasadena, California Abstract - The effects of device technology and scaling on Figure 2 shows how various contributions to the soft error rates are discussed, using information obtained from terrestrial error rate are affected by critical charge [3]. The both the device and space communities as a guide to determine work was done with SRAM cells, fabricated with a 0.35 µm the net effect on soft errors. Recent data on upset from high- CMOS process. For critical charge < 35 fC it is possible to energy protons indicates that the soft-error problem in DRAMs and microprocessors is less severe for highly scaled devices, in upset the cell with alpha particles. The largest contribution contrast to expectations. Possible improvements in soft-error from alphas comes from solder, but there is also a significant rate for future devices, manufactured with silicon-on-insulator contribution from impurities in the metallization. By technology, are also discussed. increasing the critical charge it is possible to eliminate errors from alpha particles, but terrestrial neutrons are still able to I. INTRODUCTION induce errors. The gradual decrease in neutron-induced error Soft-errors from alpha particles were first reported by rate with increasing critical charge is due to the distribution May and Woods [1], and considerable effort was spent by the of neutron energies, which extends over a very wide range. semiconductor device community during the ensuing years to Figure 2. -

Interfacing EPROM to the 8088
Chapter 10: Memory Interface Introduction Simple or complex, every microprocessor-based system has a memory system. Almost all systems contain two main types of memory: read-only memory (ROM) and random access memory (RAM) or read/write memory. This chapter explains how to interface both memory types to the Intel family of microprocessors. MEMORY DEVICES Before attempting to interface memory to the microprocessor, it is essential to understand the operation of memory components. In this section, we explain functions of the four common types of memory: read-only memory (ROM) Flash memory (EEPROM) Static random access memory (SRAM) dynamic random access memory (DRAM) Memory Pin Connections – address inputs – data outputs or input/outputs – some type of selection input – at least one control input to select a read or write operation Figure 10–1 A pseudomemory component illustrating the address, data, and control connections. Address Connections Memory devices have address inputs to select a memory location within the device. Almost always labeled from A0, the least significant address input, to An where subscript n can be any value always labeled as one less than total number of address pins A memory device with 10 address pins has its address pins labeled from A0 to A9. The number of address pins on a memory device is determined by the number of memory locations found within it. Today, common memory devices have between 1K (1024) to 1G (1,073,741,824) memory locations. with 4G and larger devices on the horizon A 1K memory device has 10 address pins. therefore, 10 address inputs are required to select any of its 1024 memory locations It takes a 10-bit binary number to select any single location on a 1024-location device. -

Radiation Hardening Efficiency of Gate Sizing and Transistor Stacking Based on Standard Cells
Radiation hardening efficiency of gate sizing and transistor stacking based on standard cells Y.Q. Aguiar, Frédéric Wrobel, S. Guagliardo, J.-L. Autran, P. Leroux, F. Saigné, A.D. Touboul, V. Pouget To cite this version: Y.Q. Aguiar, Frédéric Wrobel, S. Guagliardo, J.-L. Autran, P. Leroux, et al.. Radiation hardening efficiency of gate sizing and transistor stacking based on standard cells. Microelectronics Reliability, Elsevier, 2019, 100-101, pp.113457. 10.1016/j.microrel.2019.113457. hal-02515096 HAL Id: hal-02515096 https://hal.archives-ouvertes.fr/hal-02515096 Submitted on 24 Mar 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Radiation Hardening Efficiency of Gate Sizing and Transistor Stacking based on Standard Cells Y. Q. Aguiara,*, F. Wrobela, S. Guagliardoa, J-L. Autranb, P. Lerouxc, F. Saignéa, A. D. Touboula and V. Pougeta a Institut d’Electronique et des Systèmes, University of Montpellier, Montpellier, France b Institut Materiaux Microelectronique Nanoscience de Provence, Aix-Marseille University, Marseille, France c Advanced Integrated Sensing Lab, KU Leuven University, Leuven, Belgium Abstract Soft error mitigation schemes inherently lead to penalties in terms of area usage, power consumption and/or performance metrics. -

Itanium-Based Solutions by Hp
Itanium-based solutions by hp an overview of the Itanium™-based hp rx4610 server a white paper from hewlett-packard june 2001 table of contents table of contents 2 executive summary 3 why Itanium is the future of computing 3 rx4610 at a glance 3 rx4610 product specifications 4 rx4610 physical and environmental specifications 4 the rx4610 and the hp server lineup 5 rx4610 architecture 6 64-bit address space and memory capacity 6 I/O subsystem design 7 special features of the rx4610 server 8 multiple upgrade and migration paths for investment protection 8 high availability and manageability 8 advanced error detection, correction, and containment 8 baseboard management controller (BMC) 8 redundant, hot-swap power supplies 9 redundant, hot-swap cooling 9 hot-plug disk drives 9 hot-plug PCI I/O slots 9 internal removable media 10 system control panel 10 ASCII console for hp-ux 10 space-saving rack density 10 complementary design and packaging 10 how hp makes the Itanium transition easy 11 binary compatibility 11 hp-ux operating system 11 seamless transition—even for home-grown applications 12 transition help from hp 12 Itanium quick start service 12 partner technology access centers 12 upgrades and financial incentives 12 conclusion 13 for more information 13 appendix: Itanium advantages in your computing future 14 hp’s CPU roadmap 14 Itanium processor architecture 15 predication enhances parallelism 15 speculation minimizes the effect of memory latency 15 inherent scalability delivers easy expansion 16 what this means in a server 16 2 executive The Itanium™ Processor Family is the next great stride in computing--and it’s here today. -

Design of Robust CMOS Circuits for Soft Error Tolerance
Design of Robust CMOS Circuits for Soft Error Tolerance Debopriyo Chowdhury, Mohammad Amin Arbabian Department of EECS, Univ. of California, Berkeley, CA 94720 Abstract - With the continuous downscaling of technology, take care of the problems and analyze the merits and lowering of supply voltage and increase of operating demerits. Finally, we want to design robust latches and frequency, integrated circuits become increasingly susceptible combinational blocks that have good soft-error tolerance. to single event effects (SEE) caused by high energy particles The report is organized into four sections; section II covers like alpha particles, neutrons from cosmic rays etc. A SEU the background, origin and effect of soft error on may cause a bit flip in some latch or memory element, thereby altering the state of the system, leading to a ‘soft error’. Soft nanometer circuits. Section III is a literature review with an errors in memory have traditionally been a much greater analytical flavor, while section IV outlines the proposed concern than soft errors in logic circuits. However, as process work for the rest of the semester as well as shows some technology scales below 100 nanometers, voltage levels go initial simulation results. down and noise margins reduce, soft errors in logic circuits seem to be a potential threat too. In this work, we propose to analyze the effect of various circuit parameters on soft error susceptibility of logic circuits. Also, we plan to design a robust II. SOFT ERRORS: ORIGIN AND EFFECT ON latch that has simultaneous SET and SEU tolerance. INTEGRATED CIRCUITS Index Terms - Soft Errors, SET, SEU Hardened Latch A soft error occurs when a radiation event causes enough of a charge distribution to reverse or flip the data state of a memory cell, latch, flip-flop or even a node in a I. -

Evaluation of Soft Errors Rate in a Commercial Memory Eeprom
2011 International Nuclear Atlantic Conference - INAC 2011 Belo Horizonte,MG, Brazil, October 24-28, 2011 ASSOCIAÇÃO BRASILEIRA DE ENERGIA NUCLEAR - ABEN ISBN: 978-85-99141-04-5 EVALUATION OF SOFT ERRORS RATE IN A COMMERCIAL MEMORY EEPROM Luiz H. Claro1, A. A. Silva1, José A. Santos1, Suzy F. L. Nogueira2, Ary G. Barrios Jr2. 1 Divisão de Energia Nuclear Instituto de Estudos Avançados , IEAv Caixa Postal 6044 12231-970 São José dos Campos, SP [email protected] 2 Faculdade de Tecnologia São Francisco, FATESF Av. Siqueira Campos, 1174 12307-000 Jacareí, SP [email protected] ABSTRACT Soft errors are transient circuit errors caused by external radiation. When an ion intercepts a p-n region in an electronic component, the ionization produces excess charges along the track. These charges when collected can flip internal values, especially in memory cells. The problem affects not only space application but also terrestrial ones. Neutrons induced by cosmic rays and alpha particles, emitted from traces of radioactive contaminants contained in packaging and chip materials, are the predominant sources of radiation. The soft error susceptibility is different for different memory technology hence the experimental study are very important for Soft Error Rate (SER) evaluation. In this work, the methodology for accelerated tests is presented with the results for SER in a commercial electrically erasable and programmable read-only memory (EEPROM). 1. INTRODUCTION From all possible kinds of radiation damages to electronic components, the soft errors are included in the class of transitory errors induced by a single particle. In the other class, the hard errors, the ionizing radiation permanently changes the structural array in the electronic components. -

Soft Error Modeling and Analysis of the Neutron Intercepting Silicon Chip (NISC) C
Soft Error Modeling and Analysis of the Neutron Intercepting Silicon Chip (NISC) C. Çelik,1,2 K. Ünlü,1,2 N. Vijaykrishnan,3 M. J. Irwin3 Service Provided: Neutron Beam Laboratory Sponsors: National Science Foundation, U. S. Department of Energy, INIE Mini Grant, the Penn State Radiation Science and Engineering Center, and the Penn State Department of Computer Science and Engineering detailed records for particles, including the mother Introduction particle of the particle that causes the soft error. Advances in microelectronic technologies result in semiconductor memories with sub-micrometer NISC Simulation Model transistor dimensions. While the decrease in the dimensions satisfy both the producers’ and consumers’ The semiconductor device node represents the basic requirements, it also leads to a higher susceptibility of data storage unit in a semiconductor memory, and for the NISC design it is chosen to be as simple as possible the integrated circuit designs to temperature, magnetic 10 7 interference, power supply and environmental noise, in order to focus on the B(n,α) Li reaction. A cross and radiation. sectional view of the memory node model is illustrated in Figure 1. The BPSG layer is designed to produce Soft errors are transient circuit errors caused due to energetic α and 7Li particles, hence it acts as a source excess charge carriers induced primarily by external for producing soft errors. In a semiconductor memory, radiations. The Neutron Intercepting Silicon Chip (NISC) depending on the architecture and vendors, there are promises an unconventional, portable, power efficient different layers to produce depletion regions, gates, neutron monitoring and detection system by enhancing and isolation layers. -

IMME128M64D2SOS8AG (Die Revision E) 1Gbyte (128M X 64 Bit)
Product Specification | Rev. 1.0 | 2015 IMME128M64D2SOS8AG (Die Revision E) 1GByte (128M x 64 Bit) 1GB DDR2 Unbuffered SO-DIMM By ECC DRAM RoHS Compliant Product Product Specification 1.0 1 IMME128M64D2SOS8AG www.intelligentmemory.com Version: Rev. 1.0, FEB 2015 1.0 - Initial release ReReRemark:Re mark: Please refer to the last page of the i) Contents ii) List of Table iii) List of Figures . We Listen to Your Comments Any information within this document that you feel is wrong, unclear or missing at all? Your feedback will help us to continuously improve the quality of this document. Please send your proposal (including a reference to this document) to: [email protected] Product Specification 1.0 2 IMME128M64D2SOS8AG www.intelligentmemory.com Features 200-Pin Unbuffered Small Outline Dual-In-Line Memory Module Capacity: 1GB Maximum Data Transfer Rate: 6.40 GB/Sec JEDEC-Standard Built by ECC DRAM Chips Power Supply: VDD, VDDQ =1.8± 0.1 V Bi-directional Differential Data-Strobe (Single-ended data-strobe is an optional feature) 64 Bit Data Bus Width without ECC Programmable CAS Latency (CL): o PC2-6400: 4, 5, 6 o PC2-5300: 4, 5 Programmable Additive Latency (Posted /CAS) : 0, CL-2 or CL-1(Clock) Write Latency (WL) = Read Latency (RL) -1 Posted /CAS On-Die Termination (ODT) Off-Chip Driver (OCD) Impedance Adjustment Burst Type (Sequential & Interleave) Burst Length: 4, 8 Refresh Mode: Auto and Self 8192 Refresh Cycles / 64ms Serial Presence Detect (SPD) with EEPROM SSTL_18 Interface Gold Edge Contacts 100% RoHS-Compliant Standard Module Height: 30.00mm (1.18 inch) Product Specification 1.0 3 IMME128M64D2SOS8AG www.intelligentmemory.com ECC DRAM Introduction Special Features (ECC ––– Functionality) - Embedded error correction code (ECC) functionality corrects single bit errors within each 64 bit memory-word. -

(BEER): Determining DRAM On-Die ECC Functions by Exploiting DRAM Data Retention Characteristics
Bit-Exact ECC Recovery (BEER): Determining DRAM On-Die ECC Functions by Exploiting DRAM Data Retention Characteristics Minesh Pately Jeremie S. Kimzy Taha Shahroodiy Hasan Hassany Onur Mutluyz yETH Zurich¨ zCarnegie Mellon University Increasing single-cell DRAM error rates have pushed DRAM entirely within the DRAM chip [39, 76, 120, 129, 138]. On-die manufacturers to adopt on-die error-correction coding (ECC), ECC is completely invisible outside of the DRAM chip, so ECC which operates entirely within a DRAM chip to improve factory metadata (i.e., parity-check bits, error syndromes) that is used yield. e on-die ECC function and its eects on DRAM relia- to correct errors is hidden from the rest of the system. bility are considered trade secrets, so only the manufacturer Prior works [60, 97, 98, 120, 129, 133, 138, 147] indicate that knows precisely how on-die ECC alters the externally-visible existing on-die ECC codes are 64- or 128-bit single-error cor- reliability characteristics. Consequently, on-die ECC obstructs rection (SEC) Hamming codes [44]. However, each DRAM third-party DRAM customers (e.g., test engineers, experimental manufacturer considers their on-die ECC mechanism’s design researchers), who typically design, test, and validate systems and implementation to be highly proprietary and ensures not to based on these characteristics. reveal its details in any public documentation, including DRAM To give third parties insight into precisely how on-die ECC standards [68,69], DRAM datasheets [63,121,149,158], publi- transforms DRAM error paerns during error correction, we cations [76, 97, 98, 133], and industry whitepapers [120, 147].