Conference on Empirical Methods in Natural Language Processing, Pages 1–9, Edinburgh, Scotland, UK, July 27–31, 2011
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Irish Antropoly Journal.Indd
Irish Journal of Anthropology Volume 13(2) 2010 1 Irish Journal of Anthropology Volume 13(2) 2010 Special Section: Health, Care, and Death Winning Essay: AAI Annual Postgraduate Essay Prize ‘Genocide site and memorial, Ntarama church, Rwanda (Photo: Eadaoin O’Brien) Volume 13(2) 2010 ISSN: 1393-8592 Irish Journal of Anthropology !e Irish Journal of Anthropology is the organ of the Anthropological Association of Ireland. As such, it aims to promote the discipline of anthropology on the island of Ireland, north and south. It seeks to provide coverage of Irish-related matters and of issues in general anthropology and to be of interest to anthropologists inside and outside academia, as well as to colleagues in a range of other disciplines, such as Archaeology, Cultural Studies, Development Studies, Ethnology and Folk Studies, Gaeilge, Irish Studies, and Sociology. Editor: Dr Séamas Ó Síocháin, Department of Anthropology, NUI Maynooth. [email protected] Associate Editor: Dr Fiona Magowan, School of History and Anthropology, !e Queen’s University of Belfast. f.magowan@ qub.ac.uk Editorial Advisory Board: Dr Dominic Bryan, School of History and Anthropology, !e Queen’s University of Belfast Dr Anthony Buckley, Ulster Folk and Transport Museum, Cultra, Co. Down Dr Maurna Crozier, Northern Ireland Community Relations Council, Belfast Dr Fiona Larkan, Department of Anthropology, NUI Maynooth Dr John Nagle, Lecturer in Anthropology, University of East London Dr Carles Salazar, University of Lleida, Spain Professor Elizabeth Tonkin, Oxford, England Book Review Editors: Dr Chandana Mathur, Department of Anthropology, NUI Maynooth. [email protected]; Professor Máiréad Nic Craith, University of Ulster, Magee Campus. -

The$Irish$Language$And$Everyday$Life$ In#Derry!
The$Irish$language$and$everyday$life$ in#Derry! ! ! ! Rosa!Siobhan!O’Neill! ! A!thesis!submitted!in!partial!fulfilment!of!the!requirements!for!the!degree!of! Doctor!of!Philosophy! The!University!of!Sheffield! Faculty!of!Social!Science! Department!of!Sociological!Studies! May!2019! ! ! i" " Abstract! This!thesis!explores!the!use!of!the!Irish!language!in!everyday!life!in!Derry!city.!I!argue!that! representations!of!the!Irish!language!in!media,!politics!and!academic!research!have! tended!to!overKidentify!it!with!social!division!and!antagonistic!cultures!or!identities,!and! have!drawn!too!heavily!on!political!rhetoric!and!a!priori!assumptions!about!language,! culture!and!groups!in!Northern!Ireland.!I!suggest!that!if!we!instead!look!at!the!mundane! and!the!everyday!moments!of!individual!lives,!and!listen!to!the!voices!of!those!who!are! rarely!heard!in!political!or!media!debate,!a!different!story!of!the!Irish!language!emerges.! Drawing!on!eighteen!months!of!ethnographic!research,!together!with!document!analysis! and!investigation!of!historical!statistics!and!other!secondary!data!sources,!I!argue!that! learning,!speaking,!using,!experiencing!and!relating!to!the!Irish!language!is!both!emotional! and!habitual.!It!is!intertwined!with!understandings!of!family,!memory,!history!and! community!that!cannot!be!reduced!to!simple!narratives!of!political!difference!and! constitutional!aspirations,!or!of!identity!as!emerging!from!conflict.!The!Irish!language!is! bound!up!in!everyday!experiences!of!fun,!interest,!achievement,!and!the!quotidian!ebbs! and!flows!of!daily!life,!of!getting!the!kids!to!school,!going!to!work,!having!a!social!life!and! -

Arcana & Curiosa
ARCANA & CURIOSA MY PERSONAL LIBRARY * Notes: * The data listed here have been exported from an .fp5 file and they may contain some formatting glitch. Any ambiguities however may be solved by consulting the websites quoted in the records of downloaded materials and/or the main online OPACs, especially the University of Manchester’s COPAC (http://copac.ac.uk/) and OPALE, the online catalogue of the Bibliothèque Nationale de France (http://catalogue.bnf.fr/). * This catalogue included printed materials as well as electronic resources published online; there is no separation of the two in sections, but all are recorded in the same database for quick reference, because I don’t always remember whether my copy of a certain work is printed or electronic. * The records are listed A-Z by surname of first author and first word in the title (articles included). * A passage to the Afterworld, http://www.knowth.com/newgrange.htm, download aprile 2003, ripubblicato da «The World of Hibernia», Cultura materiale e archeologia A Proper newe Booke of Cokerye (mid-16th c.), http://www.staff.uni- marburg.de/~gloning/bookecok.htm, download maggio 2004, Cultura materiale e archeologia Ad fontes: gnostic sources in the BPH, J.R. Ritman Library -- Bibliotheca Philosophica Hermetica. The Library of Hermetic Philosophy in Amsterdam, http://www.xs4all.nl/~bph/, download agosto 2002, Alchimia Aesch-Mezareph, traduzione inglese di W. Wynn Westcott, The Alchemy Web, http://www.levity.com/alchemy, download ottobre 2001, Adam McLean, Alchimia Alchemical and chemical -

Irish Parents and Gaelic- Medium Education in Scotland
Irish parents and Gaelic- medium education in Scotland A Report for Soillse 2015 Wilson McLeod Bernadette O’Rourke Table of content 1. Introduction ............................................................................................................................ 2 2. Setting the scene ................................................................................................................... 3 3. Previous research .................................................................................................................. 4 4. Profile of Irish parent group ................................................................................................... 5 5. Relationship to Irish: socialisation, acquisition and use ......................................................... 6 6. Moving to Scotland: when and why? ................................................................................... 12 7. GME: awareness, motivations and experiences .................................................................. 14 8. The Gaelic language learning experience and use of Gaelic .............................................. 27 9. Sociolinguistic perceptions of Gaelic ................................................................................... 32 10. Current connections with Ireland ...................................................................................... 35 11. Conclusions ...................................................................................................................... 38 Acknowledgements -

A Revitalization Study of the Irish Language
TAKING THE IRISH PULSE: A REVITALIZATION STUDY OF THE IRISH LANGUAGE Donna Cheryl Roloff Thesis Prepared for the Degree of MASTER OF ARTS UNIVERSITY OF NORTH TEXAS December 2015 APPROVED: John Robert Ross, Committee Chair Kalaivahni Muthiah, Committee Member Willem de Reuse, Committee Member Patricia Cukor-Avila, Director of the Linguistics Program Greg Jones, Interim Dean of College of Information Costas Tsatsoulis, Interim Dean of the Toulouse Graduate School Roloff, Donna Cheryl. Taking the Irish Pulse: A Revitalization Study of the Irish Language. Master of Arts (Linguistics), December 2015, 60 pp., 22 tables, 3 figures, references, 120 titles. This thesis argues that Irish can and should be revitalized. Conducted as an observational case study, this thesis focuses on interviews with 72 participants during the summer of 2013. All participants live in the Republic of Ireland or Northern Ireland. This thesis investigates what has caused the Irish language to lose power and prestige over the centuries, and which Irish language revitalization efforts have been successful. Findings show that although, all-Irish schools have had a substantial growth rate since 1972, when the schools were founded, the majority of Irish students still get their education through English- medium schools. This study concludes that Irish will survive and grow in the numbers of fluent Irish speakers; however, the government will need to further support the growth of the all-Irish schools. In conclusion, the Irish communities must take control of the promotion of the Irish language, and intergenerational transmission must take place between parents and their children. Copyright 2015 by Donna Cheryl Roloff ii TABLE OF CONTENTS Page CHAPTER 1 INTRODUCTION 1 CHAPTER 2 HISTORICAL BACKGROUND AND THE DETERIORATION 13 OF THE IRISH LANGUAGE CHAPTER 3 IRISH SHOULD BE REVIVED 17 CHAPTER 4 IRISH CAN BE REVIVED 28 CHAPTER 5 CONCLUSION 44 REFERENCES 53 iii LIST OF TABLES Page 1. -
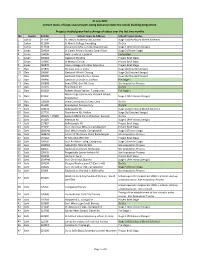
31 July 2021 Current Status of Large-Scale Projects Being Delivered Under the School Building Programme
31 July 2021 Current status of large-scale projects being delivered under the school building programme. Projects shaded green had a change of status over the last two months No. County Roll No School Name & Address School Project Status 1 Carlow 61120E St. Mary's Academy CBS, Carlow Stage 2a (Developed Sketch Scheme) 2 Carlow 61130H St Mary's College, Knockbeg On Site 3 Carlow 61150N Presentation/De La Salle, Bagnelstown Stage 1 (Preliminary Design) 4 Cavan 08490N St Clare's Primary School, Cavan Town Stage 3 (Tender Stage) 5 Cavan 19439B Holy Family SS, Cootehill Completed 6 Cavan 20026G Gaelscoil Bhreifne Project Brief Stage 7 Cavan 70360C St Mogues College Project Brief Stage 8 Cavan 76087R Cavan College of Further Education Project Brief Stage 9 Clare 17583V SN Cnoc an Ein, Ennis Stage 2b (Detailed Design) 10 Clare 19838P Gaelscoil Mhichil Chiosog Stage 2b (Detailed Design) 11 Clare 19849U Gaelscoil Donncha Rua, Sionna Stage 2b (Detailed Design) 12 Clare 19999Q Gaelscoil Ui Choimin, Cill Rois Pre Stage 1 13 Clare 20086B Ennis ETNS, Gort Rd, Ennis Site Acquisition Process 14 Clare 20245S Ennistymon NS On Site 15 Clare 20312H Raheen Wood Steiner, Tuamgraney Pre Stage 1 Mol an Óige Community National School, 16 Clare 20313J Stage 1 (Preliminary Design) Ennistymon 17 Clare 70830N Ennis Community College, Ennis On Site 18 Clare 91518F Ennistymon Post primary On Site 19 Cork 00467B Ballinspittle NS Stage 2a (Developed Sketch Scheme) 20 Cork 13779S Dromahane NS, Mallow Stage 2b (Detailed Design) 21 Cork 14052V / 17087J Kanturk BNS & SN -

A1a13os Mo1je3 A11110 1Eujnor
§Gllt,I IISSI Nlltllf NPIIII eq:101Jeq1eq3.epueas uuewnq3 Jeqqea1s1JI A1a13os Mo1Je3 PIO a11110 1euJnor SPONSORS ROYAL HOTEL - 9-13 DUBLIN STREET SOTHERN AUCTIONEERS LTD A Personal Hotel ofQuality Auctioneers. Valuers, Insurance Brokers, 30 Bedrooms En Suite, choice ofthree Conference Rooms. 37 DUBLIN STREET, CARLOW. Phone: 0503/31218. Fax.0503 43765 Weddings, functions, Dinner Dances, Private Parties. District Office: Irish Nationwide Building Society Food Served ALL Day. Phone: 0503/31621 FLY ONTO ED. HAUGHNEY & SON, LTD O'CONNOR'S GREEN DRAKE INN, BORRIS Fuel Merchant, Authorised Ergas Stockists Lounge and Restaurant - Lunches and Evening Meals POLLERTON ROAD, CARLOW. Phone: 0503/31367 Weddings and Parties catered for. GACH RATH AR CARLOVIANA IRISH PERMANENT PLC. ST. MARY'S ACADEMY 122/3 TULLOW STREET, CARLOW CARLOW Phone:0503/43025,43690 Seamus Walker - Manager Carlow DEERPARK SERVICE STATION FIRST NATIONAL BUILDING SOCIETY MARKET CROSS, CARLOW Tyre Service and Accessories Phone: 0503/42925, 42629 DUBLIN ROAD, CARLOW. Phone: 0503/31414 THOMAS F. KEHOE MULLARKEY INSURANCES Specialist Lifestock Auctioneer and Valuer, Farm Sales and Lettings COURT PLACE, CARLOW Property and Estate Agent Phone: 0503/42295, 42920 Agent for the Irish Civil Service Building Society General Insurance - Life and Pensions - Investment Bonds 57 DUBLIN STREET CARLOW. Telephone: 0503/31378/31963 Jones Business Systems GIFTS GALORE FROM Sales and Service GILLESPIES Photocopiers * Cash Registers * Electronic Weighing Scales KENNEDY AVENUE, CARLOW Car Phones * Fax Machines * Office Furniture* Computer/Software Burrin Street, Carlow. Tel: (0503) 32595 Fax (0503) 43121 Phone: 0503/31647, 42451 CARLOW PRINTING CO. LTD DEVOY'S GARAGE STRAWHALL INDUSTRIAL ESTATE, CARLOW TULLOW ROAD, CARLOW For ALL your Printing Requirements. -

Xerox University Microfilms 900 North Zaab Road Ann Arbor, Michigan 49100 Ll I!
INFORMATION TO USERS This material was produced from a microfilm copy of the original document. While the most advanced technological means to photograph and reproduce this document have been used, the quality Is heavily dependent upon the quality of the original submitted. The following explanation of techniques is provided to help you understand markings or patterns which may appear on this reproduction. 1.The sign or "target" for pages apparently lacking from the document photographed is "Missing Page(s)". If it was possible to obtain the missing page(s) or section, they are spliced into the film along with adjacent pages. This may have necessitated cutting thru an image and duplicating adjacent pages to insure you complete continuity. 2. When an image on the film is obliterated with a large round black mark, it is an indication that the photographer suspected that the copy may have moved during exposure and thus cause a blurred image. You will find a good (mage of the page in the adjacent frame. 3. When a map, drawing or chart, etc., was part of the material being photographed the photographer followed a definite method in "sectioning" the material. It is customary to begin photoing at the upper left hand corner of a large sheet and to continue photoing from left to right in equal sections with a small overlap. If necessary, sectioning is continued again — beginning below the first row and continuing on until complete. 4. The majority of users indicate that the textual content is of greatest value, however, a somewhat higher quality reproduction could be made from "photographs" if essential to the understanding of the dissertation. -

Shopkindly That Has Been Missed, Notify the Business and Give Them the Opportunity to Remedy It Rather Than Posting on Social Media
SPECIAL FEATURE: Life Less Ordinary Living in a pandemic People from around West Cork share their experiences. www.westcorkpeople.ie & www.westcorkfridayad.ie October 2 – October 30, 2020, Vol XVI, Edition 218 FREE Old Town Hall, McCurtain Hill, Clonakilty, Co. Cork. E: [email protected] P: 023 8835698 SILENCE IS GOLDEN. NEW PEUGEOT e-208 FULL ELECTRIC From Direct Provision to Cork Persons of the Month: Izzeddeen and wife Eman Alkarajeh left direct provision in Cork and, together with their four children, overcame all odds to build a new life and successful Palestinian food business in Cork. They are pictured at their Cork Persons of Month award presentation with (l-r) Manus O’Callaghan and award organiser, George Duggan, Cork Crystal. Picture: Tony O’Connell Photography. *Offer valid until the end of August. CLARKE BROS LTD Main Peugeot Dealer, Clonakilty Road, Bandon, Co. Cork. Clune calls on Government to “mind our air routes” Tel: 023-8841923CLARKE BROS Web: www.clarkebrosgroup.ie ction is needed on the Avia- Irish Aviation Sector to recover from but also to onward flights through the to Ireland’s economy and its economic (BANDON) LTD tion Recovery Taskforce Re- the impact of Covid 19. One of the international airline hubs as well as recovery. Main Peugeot Dealers port to ensure we have strong recommendations of the Aviation excellent train access across Europe. The report said that a stimulus Clonakilty Road, Aregional airports post-Covid. This Recovery Taskforce Report was to MEP Clune added: “This is a very package should be put in place con- is according to Ireland South MEP provide a subvention per passenger difficult time for our airlines and air- currently for each of Cork, Shannon, Bandon Deirdre Clune who said it should be at Cork, Shannon and other Regional ports but we must ensure that they get Ireland West, Kerry and Donegal Co. -

Research Bibliography:Resources on the Study of the Healing Cultures In
Research Bibliography SOURCES ON THE STUDY OF THE HEALING CULTURES IN IRELAND AND THE BRITISH ISLES Stephany Hoffelt | BA HAS | May 11, 2016 Contents Introduction ........................................................................................................................................................................................ 3 General Reference ............................................................................................................................................................................ 5 Prehistory ............................................................................................................................................................................................ 6 Women and Healing .......................................................................................................... Error! Bookmark not defined. Digital Receipt Book Collections ................................................................................................................................................. 8 Irish Reference ................................................................................................................................................................................... 8 Scottish Reference ......................................................................................................................................................................... 16 Anglo Saxon Reference ............................................................................................................................................................... -

The Irish Language and the Irish Legal System:- 1922 to Present
The Irish Language and The Irish Legal System:- 1922 to Present By Seán Ó Conaill, BCL, LLM Submitted for the Award of PhD at the School of Welsh at Cardiff University, 2013 Head of School: Professor Sioned Davies Supervisor: Professor Diarmait Mac Giolla Chríost Professor Colin Williams 1 DECLARATION This work has not been submitted in substance for any other degree or award at this or any other university or place of learning, nor is being submitted concurrently in candidature for any degree or other award. Signed ………………………………………… (candidate) Date………………………… STATEMENT 1 This thesis is being submitted in partial fulfillment of the requirements for the degree of …………………………(insert MCh, MD, MPhil, PhD etc, as appropriate) Signed ………………………………………… (candidate) Date ………………………… STATEMENT 2 This thesis is the result of my own independent work/investigation, except where otherwise stated. Other sources are acknowledged by explicit references. The views expressed are my own. Signed ………………………………………… (candidate) Date ………………………… 2 STATEMENT 3 I hereby give consent for my thesis, if accepted, to be available for photocopying and for inter-library loan, and for the title and summary to be made available to outside organisations. Signed ………………………………………… (candidate) Date ………………………… STATEMENT 4: PREVIOUSLY APPROVED BAR ON ACCESS I hereby give consent for my thesis, if accepted, to be available for photocopying and for inter-library loans after expiry of a bar on access previously approved by the Academic Standards & Quality Committee. Signed ………………………………………… -

I IRISH MEDIUM EDUCATION
IRISH MEDIUM EDUCATION: COGNITIVE SKILLS, LINGUISTIC SKILLS, AND ATTITUDES TOWARDS IRISH. IVAN ANTHONY KENNEDY PhD COLLEGE OF EDUCATION AND LIFELONG LEARNING, BANGOR UNIVERSITY 2012 i In memory of Tony. No one speaks English, and everything's broken, and my Stacys are soaking wet. ~Tom Waits, Tom Traubert's Blues ii There’s a ghost of another language shadow-dancing under my words. A phantom tongue that unravels like liquor, inspires like song. ~Sharanya Manivannann, First Language Education is simply the soul of a society as it passes from one generation to another. ~G.K. Chesterton iii Acknowledgements First, and foremost, I thank my supervisor, Dr. Enlli Thomas, for all the guidance over the years. Thank you Enlli for all your constructive and friendly support and for helping me to find and embark upon the right paths throughout this project. Your immense diligence, encouragement, and support went beyond measure and I will be forever grateful for the opportunities that you gave me. From start to finish, working with you on this project was an absolute pleasure. I also thank An Chomhairle um Oideachas Gaeltachta & Gaelscolaíochta for their financial support in funding this project which made its undertaking possible. Thank you Pól Ó Cainin and Muireann Ní Mhóráin for your help. I thank Siân Wyn Lloyd-Williams for all the moral and academic support throughout the project. Your input is truly valued, helped to keep me grounded, and made the project more fun and less stressful than it might otherwise have been. Additionally, I thank Dave Lane for his expertise in creating the Flanker tasks and the Sustained Attention to Response Task computer programs, Gwyn Lewis and Jean Ware for academic assistance and feedback, Beth Lye and Mirain Rhys for scoring children’s written tests, and Raymond Byrne and Ross Byrne for helping to create and pilot the Irish vocabulary tests.